📌 데이터마이닝
데이터 마이닝의 이해
- 데이터마이닝(data mining)은 대용량의 데이터로부터 자동 또는 반자동적인 방법으로 의미있는 패턴, 규칙, 관계를 찾아내는 것
- 데이터 자체의 분석 단계를 넘어 패턴 추출
- 수작업의 어려움 -> 데이터마이닝의 발달
데이터 마이닝의 특징
- 데이터(베이스)의 내용을 및 결과를 단순 활용에서 벗어나 데이터에 내재해 있는 패턴 추출
- 데이터의 양이 방대해지면서 수작업이 어려움
- 데이터 마이닝의 필요성 대두
- 데이터 마이닝은 사용자의 경험이나 편견을 배제하고 전적으로 데이터에 기반하여 패턴 추출
활용분야
- 카드사의 사기 발견 프로세스
- 금융권의 대출 승인
- 투자 분석
- 기업의 마케팅
- 순수 과학 분야의 자료 분석
기법
- 군집분석
- 의사결정나무
- 연관관계 분석 기법
- 인공신경망 기법
- 회귀분석
- 사례 기반 추론
- 텍스트 마이닝
- 오피니언 마이닝
💻 패키지
library(GGally)
library(factoextra)
library(rpart)
library(rpart.plot)
library(caret)
library(KoNLP)
library(wordcloud)
📌 군집분석(Cluster Analysis)
변수 또는 개체(item)들이 속한 모집단 또는 범주에 대한 사전정보가 없는 경우에 관측값들 사이의 거리(또는 유사성)를 이용하여 변수 또는 개체들을 자연스럽게 몇 개의 그룹 또는 군집(cluster)으로 나누는 분석법
📌 K-means Clustering
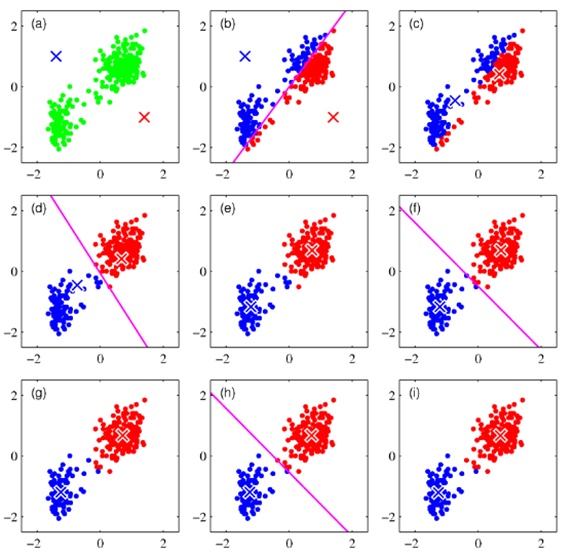
집단을 K 개의 그룹으로 나누는 방법
📌 유사도
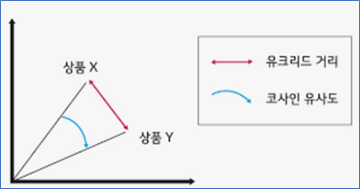
-
유클리드 거리
2차원: 두 점 (𝑥1,𝑥_2 ), (𝑦_1, 𝑦_2) 사이의 거리 √((𝑦_1−𝑥_1 )^2+(𝑦_2−𝑥_2 )^2 )
n차원: 두 점 (𝑥_1,⋯, 𝑥𝑛 ), (𝑦1, ⋯, 𝑦𝑛) 사이의 거리 (∑▒(𝑦𝑖−𝑥𝑖 )^𝑛 )^(1/𝑛) -
코사인(cosine) 유사도
두 벡터(vector)가 이루는 각의 코사인 값 cos(𝑥,𝑦)=(𝑥⋅𝑦)/(|(|𝑥|)| ||𝑦||)
💻 실습 데이터 - iris
 | 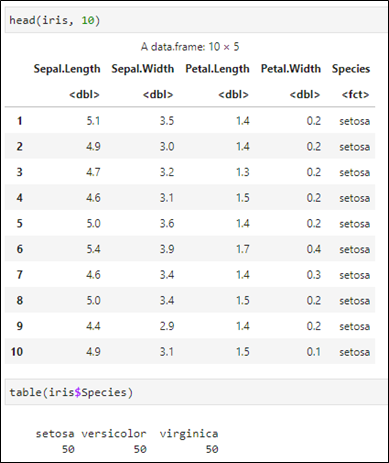 |
|---|
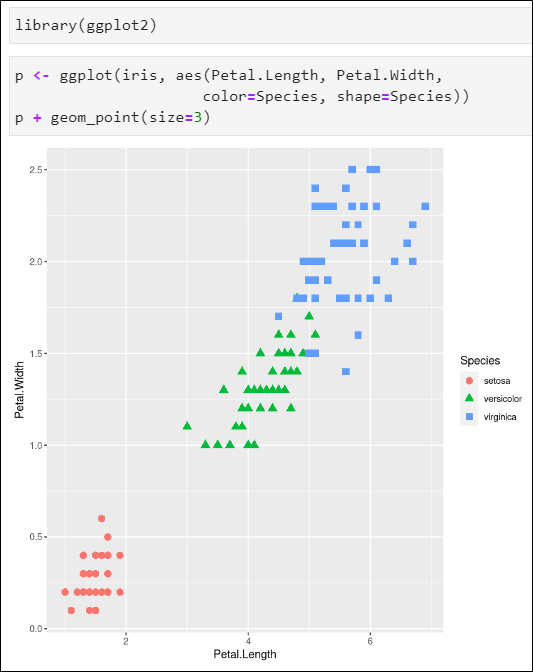
꽃잎의 너비와 길이의 산점도
- 색상을 종(Species)에 따라 다르게
- 점 모양도 종에 따라 다르게
- 크게 3개의 그룹으로 나뉘어짐
📌 petal 자료만 사용하여 분류 - kmeans()
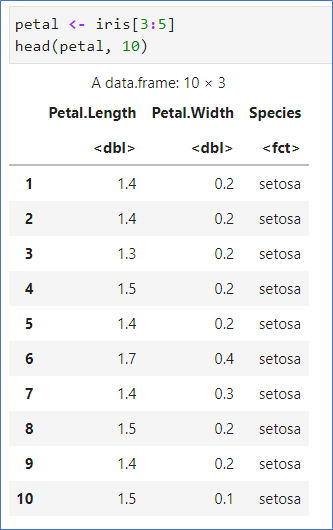
- petal 자료만 추출
- 원데이터 알고 있음
- Length와 Width를 이용하여 Species를 분류하고 그 결과를 비교할 예정
- kmeans(데이터, centers=n, iter.max=회수)
- petal[1:2]로 Length와 Width만 사용
- centers=3: 3개의 중심
- iter.max: 반복횟수
- 결과는 실행시 마다 다르게 나타날 수 있음
 |  |
|---|
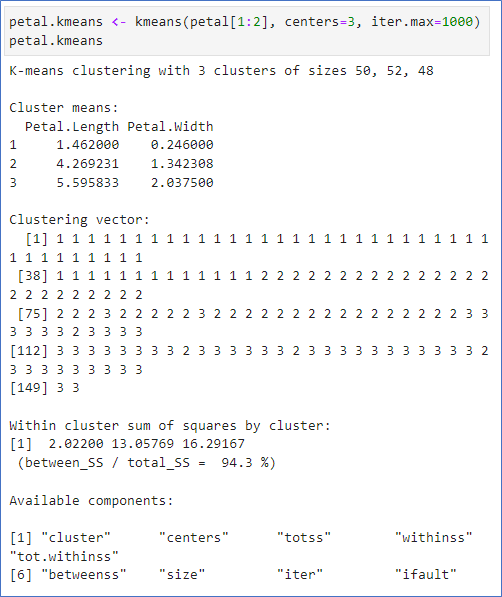
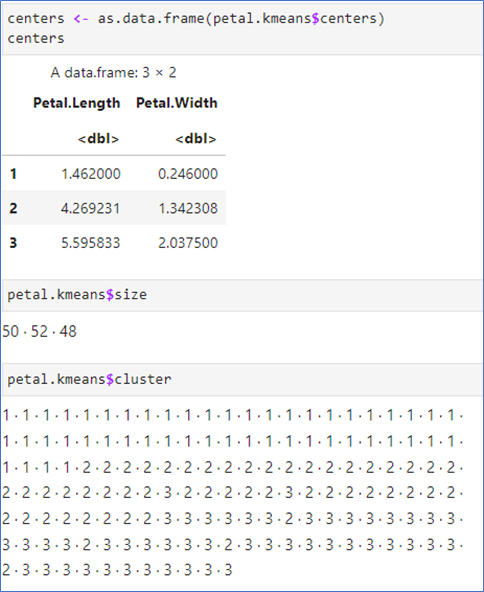
kmean 결과는 리스트
- 3개의 중심 좌표 확인
- 3개의 그룹에 각각 50, 52, 48개로 분류
- 분류 그룹은 cluster에 저장됨
📌 petal 자료만 사용
- 이차원표 결과:
- setosa는 정확히 분류
- versicolor는 2개 오분류
- virginica는 4개 오분류
- 결과는 실행시마다 달라질 수 있음
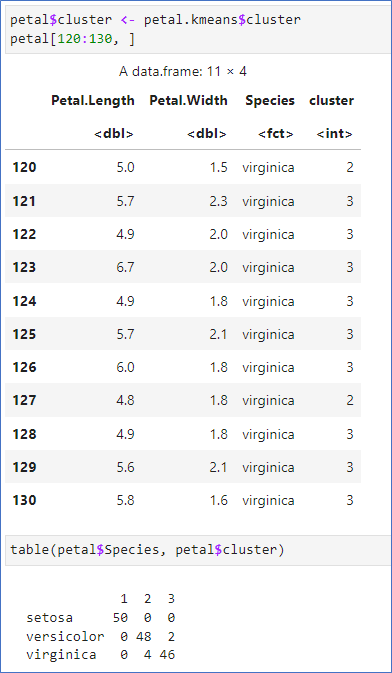
중심 확인
- 각 군집(cluster)의 중심(center)도 그림에 추가
- centers를 data frame으로 저장한 후 그래프를 그림.
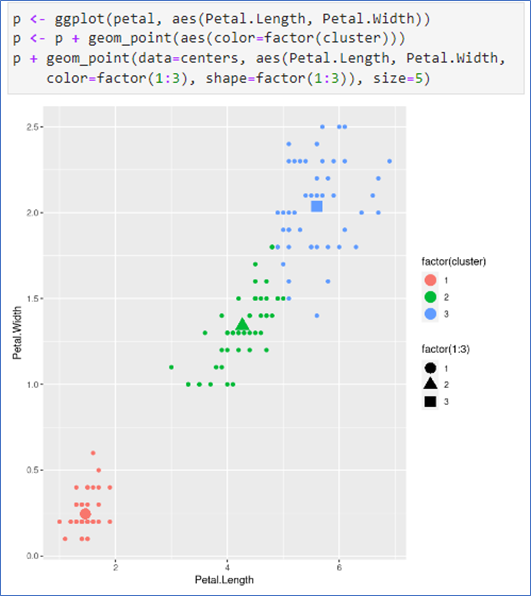
군집별 평행 좌표 그림, 타원그림
- 패키지 GGally 필요
- 데이터는 petal
- 사용 키는 1, 2 열
- 각 자료들이 어떻게 분류되어 있는지 확인 가능
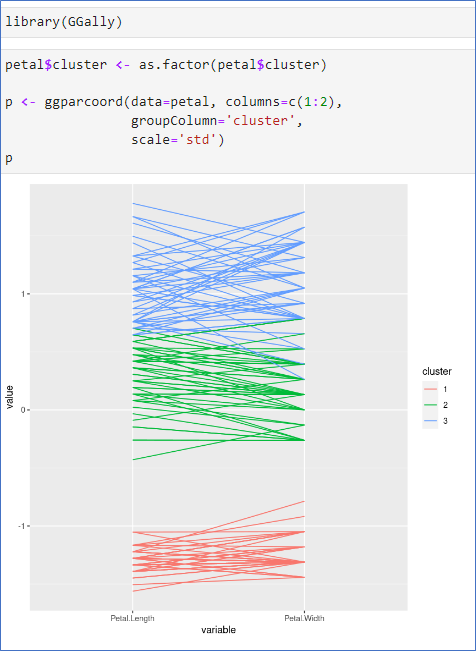
- 패키지 factoextra 필요
- 군집별 타원으로 visualization
 |  |
|---|
📌 의사결정 나무(decision tree)
- 의사결정나무는 데이터마이닝의 주요 기법 중 하나
- 분류 및 예측에 사용되는 기법
- 사용이 용이하고 결과 해석 수월
- 규칙 셋(set)으로 표현 가능
주요 변수의 선정이 용이
| 특징 | 설명 |
|---|---|
| 주요 변수의 선정이 용이 | 중요한 변수만 선별하여 의사결정나무를 구성 |
| 교호 효과의 해석 | 두 개 이상의 변수가 결합하여 목표 변수에 어떻게 영향을 주는지 쉽게 알 수 있다. |
| 비모수적 모형 | 선형성, 정규성, 등분산성 등의 가정 불필요 |
| 해석 용이 | 결과를 해석하기 용이 |
| 지식 추출 | 의사결정나무를 룰로 변환 가능 |
비연속성 및 나무형성의 한계
| 특징 | 설명 |
|---|---|
| 비연속성 | 연속형 변수(비율척도)를 비연속적인 값으로 취급하여 분리의 경계에서 오차 가능성 |
| 선형성 또는 주효과의 결여 | 선형 또는 주효과 모형에서와 같은 결과를 얻을 수 없다 |
| 비안정성 | 분석용 자료에만 의존하여 새로운 자료의 예측 불안정 가능성 |
| 나무형성 시 컴퓨팅 비용 증가 | 나무형성 시 많은 컴퓨팅 비용이 소요됨 |
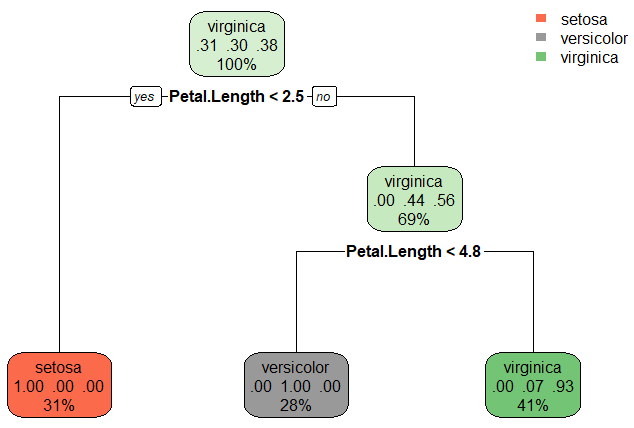
💻 실습_iris 데이터
의사결정나무 규칙 구하기
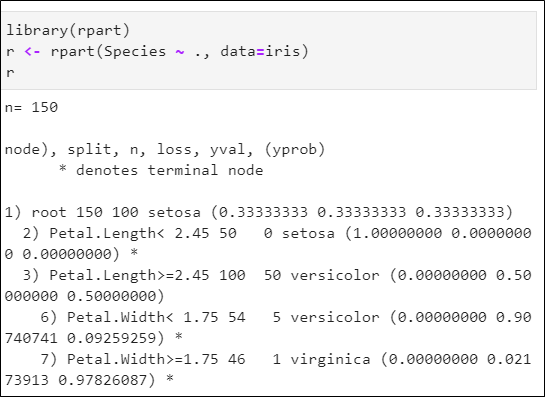
- 라이브러리 rpart 사용
- 150개의 데이터를 훈련 데이터로 모두사용
- Species ~ .: 에서 종(Species)는 알고 있는 결과, .은 모든 변수 사용하라는 뜻
- 주어진 결과는 규칙
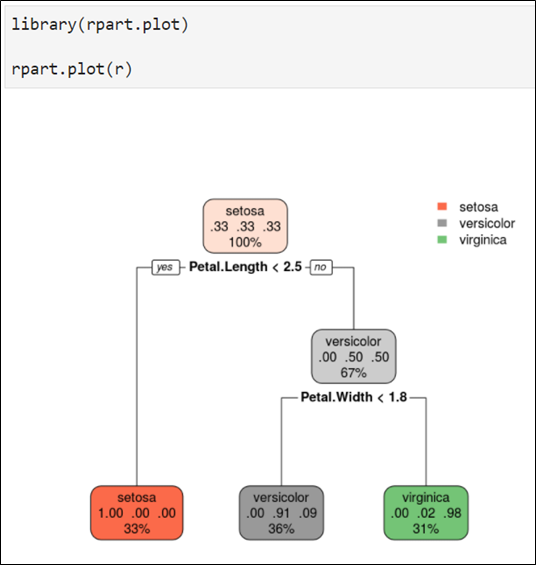
- 라이브러리 rpart.plot 사용
 |  |
|---|
의사결정나무로 예측하기
- sample() 함수를 이용하여 10개를 랜덤하게 추출
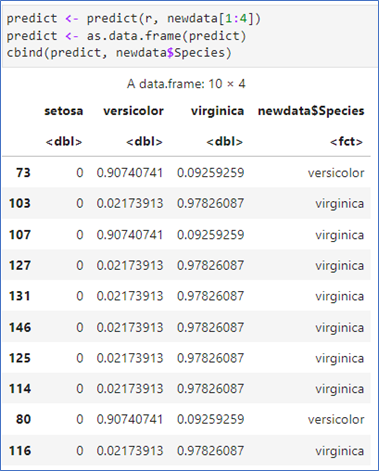
- predict(r, newdata=…) newdata에는 데이터프레임으로 4개의 변수만.
- predict()는 확률로 표시
- predict(r, newdata=…, type=‘class’) 옵션을 추가하여 가장 높은 확률의 class로 예측
- table()로 확인해보면 1개의 오분류가 있음.
- 샘플 10개가 추출될 때마다 결과가 다를 수 있음
 |  |  |
|---|
기계 학습에서는 어떻게 활용하나?
데이터를 훈련데이터(training)와 테스트 데이터(testing)으로 분류
훈련데이터로 군집분류 규칙을 찾고, 테스트데이터로 정확도 확인
패키지: caret(Classification And REgression Training)
createDataPartition(데이터, p=비율) 사용
📌 데이터 파티션 – 훈련 & 테스트
- iris 데이터 중 70%를 훈련 데이터(training)로
- 30%를 테스트 데이터(testing)로
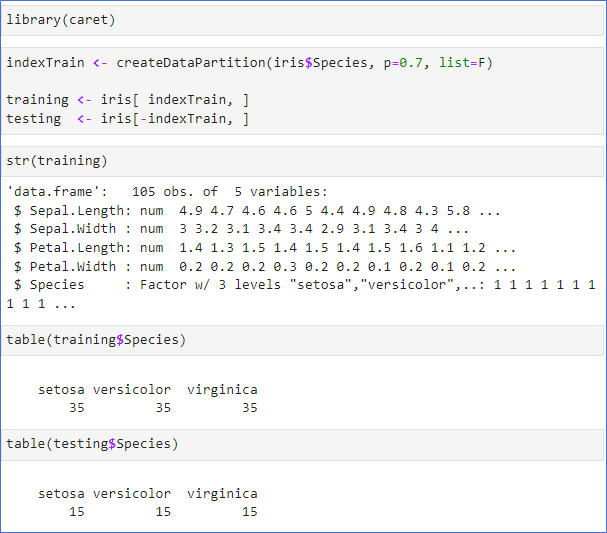
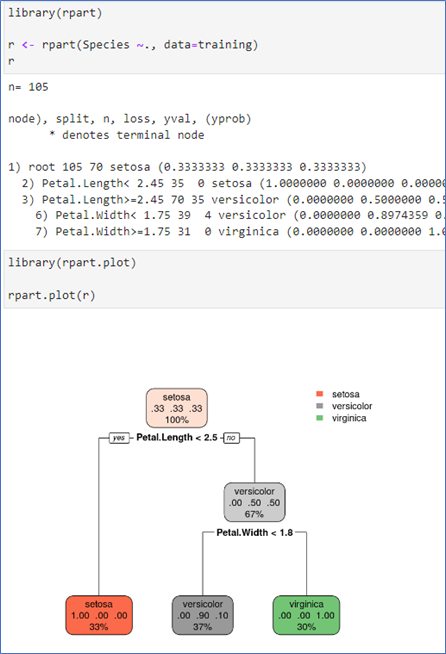
의사결정 나무 규칙 구하기
- 훈련 데이터(training)를 이용하여 분류 규칙 찾기
- 변수 1~4까지 모두 사용
- 분류 규칙에는 Patal.Length와 Petal.Width 2개만으로
테스트 데이터로 확인
- 규칙 r로 예측한 결과를 testing의 새로운 변수 predict로 저장
- table로 예측의 정확도 확인
- testingpredict는 규칙에 의한 분류
- 1개가 오분류됨
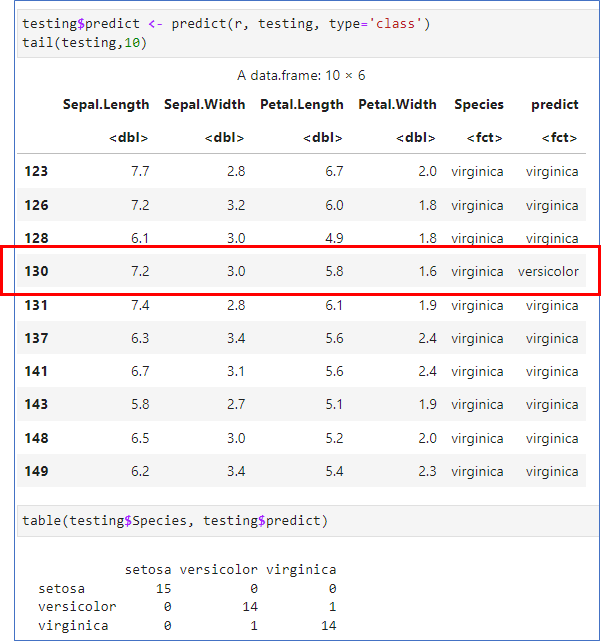
🎯 정확도 확인
- 정확도는 95.56%
워드 클라우드
- KoNLP
한국어 형태소 분석 패키지
CRAN에서 제외되어 수동 설치- wordcloud 패키지
워드클라드를 그려주는 패키지- 설치시 마다 매우 많은 시행 착오.
- 2024년에는 서버실 학생들이 cslab 서버에 설치함.
KoNLP 설치
출처: https://e-datanews.tistory.com/155
jdk 설치
install.packages("multilinguer")
library(multilinguer)
install_jdk()KoNLP 설치
install.packages("remotes")
remotes::install_github("haven-jeon/KoNLP", force = T, upgrade = "never",
INSTALL_opts = c("--no-multiarch"))샘플 코드
library(KoNLP)
extractNoun("KoNLP 설치 정말 어렵네요!")
