앞으로의 목표 👍
- javascript 능력 및 고난도 알고리즘 풀이 능력
- Nest, Graphql등 최신 기술 스택 활용 능력
- 기초 미니프로젝트 포트폴리오
- 로그인, 결제기반 심화프로젝트 포트폴리오
- 배포를 위한 네트워크 및 CI/CD 배포자동화 능력
- 120% 백엔드 개발 지식
오늘부터 꾸준히 해야할 일 👍
- 영타실력 늘리기
- 단축키 사용 익숙해지기
- 코드리딩 실력 키우기
- 데일리 퀴즈
- 포트폴리오 작성
- 독스에 친숙해지기
- MDN 보는 연습하기
오늘의 수업 👍
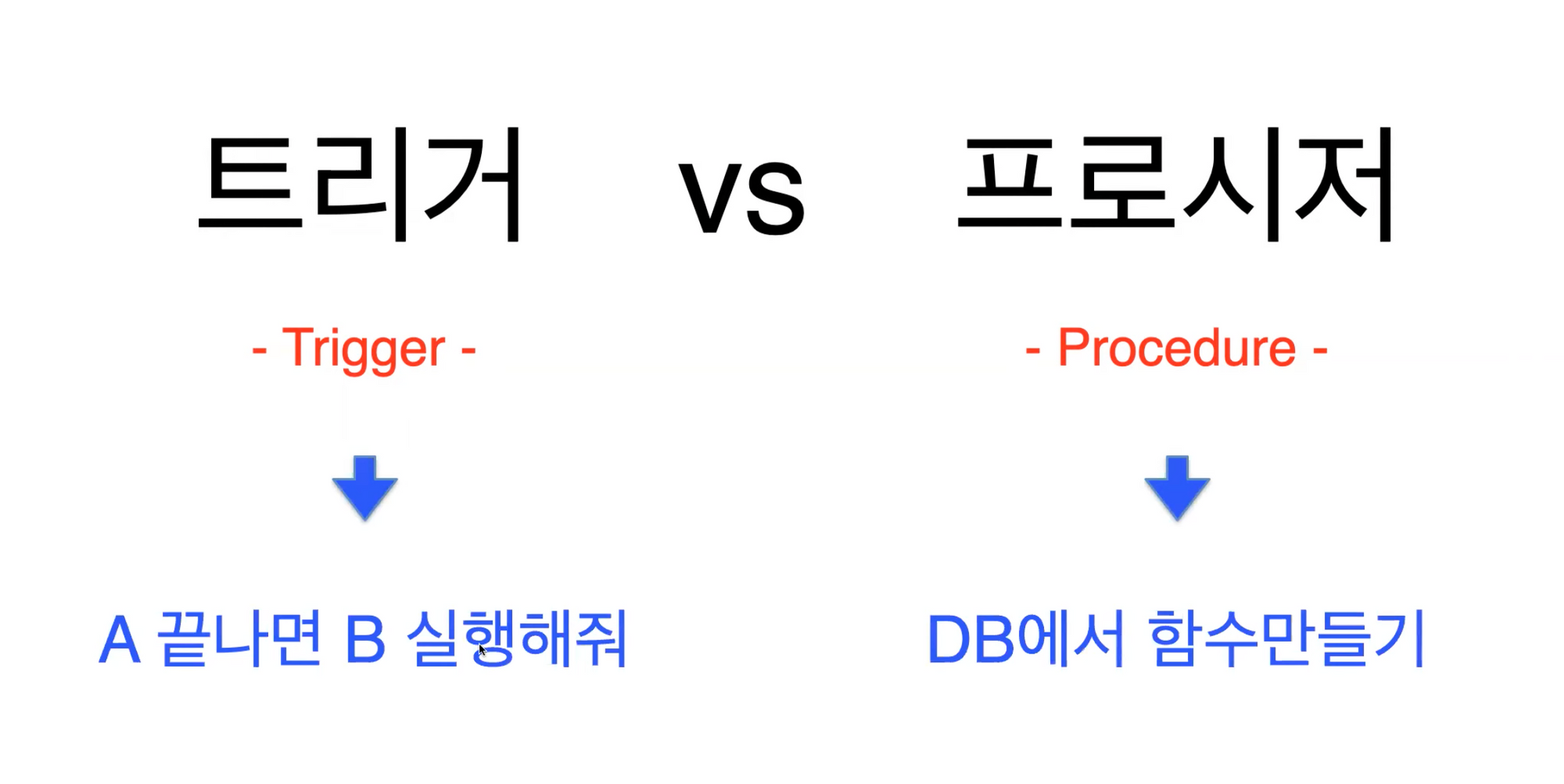
📝 Trigger
- 영어로 방아쇠라는 뜻인데, 방아쇠를 당기면 그로 인해 총기 내부에서 알아서 일련의 작업을 실행하고 총알이 날아간다.
- 특정 테이블에 INSERT, DELETE, UPDATE 같은 DML 문이 수행되었을 때, 데이터베이스에서 자동으로 동작하도록 작성된 프로그램이다.
- 사용자가 직접 호출하는 것이 아니라, 데이터베이스에서 자동적으로 호출하는 것이 가장 큰 특징이다
▷ Trigger 특징
- 가급적이면 Javascript단에서 적용하는 편이 좋다.
- 트랜잭션으로 연결된 중요한 내용들은 사용하면 안된다.
- 메인 로직에 별로 중요하지 않은데, 적기 귀찮은 것들은 사용하면 좋다.
- ex) 통계 계산하기, 로그 쌓아놓기
📝 PROCEDURE
- trigger와 마찬가지로 요즘은 Procedure를 DB에서 직접 적용하기보다는 가급적이면 Javascript단에서 적용하는 편이다.
📝 Index
- 인덱스(= 책갈피)는 테이블을 빨리 조회하기 위해 테이블 데이터에 포인터를 주는 검색 방법이다.
- 인덱스를 다시 건다는 것 => 등록/ 수정시에 책갈피에 맞게 데이터를 정렬해야 한다.
- 등록 / 수정의 속도를 포기하고 조회 속도를 빠르게 한다.
▷ Explain명령어로 옵티마이저의 실행계획 분석
- 옵티마이저: 검색을 효율적으로 해주는 DB 내장기능
- 실행계획: 효율적인 검색 계획
- Explain 명령어: 옵티마이저가 결정한 실행결과를 볼 수 있는 명령어
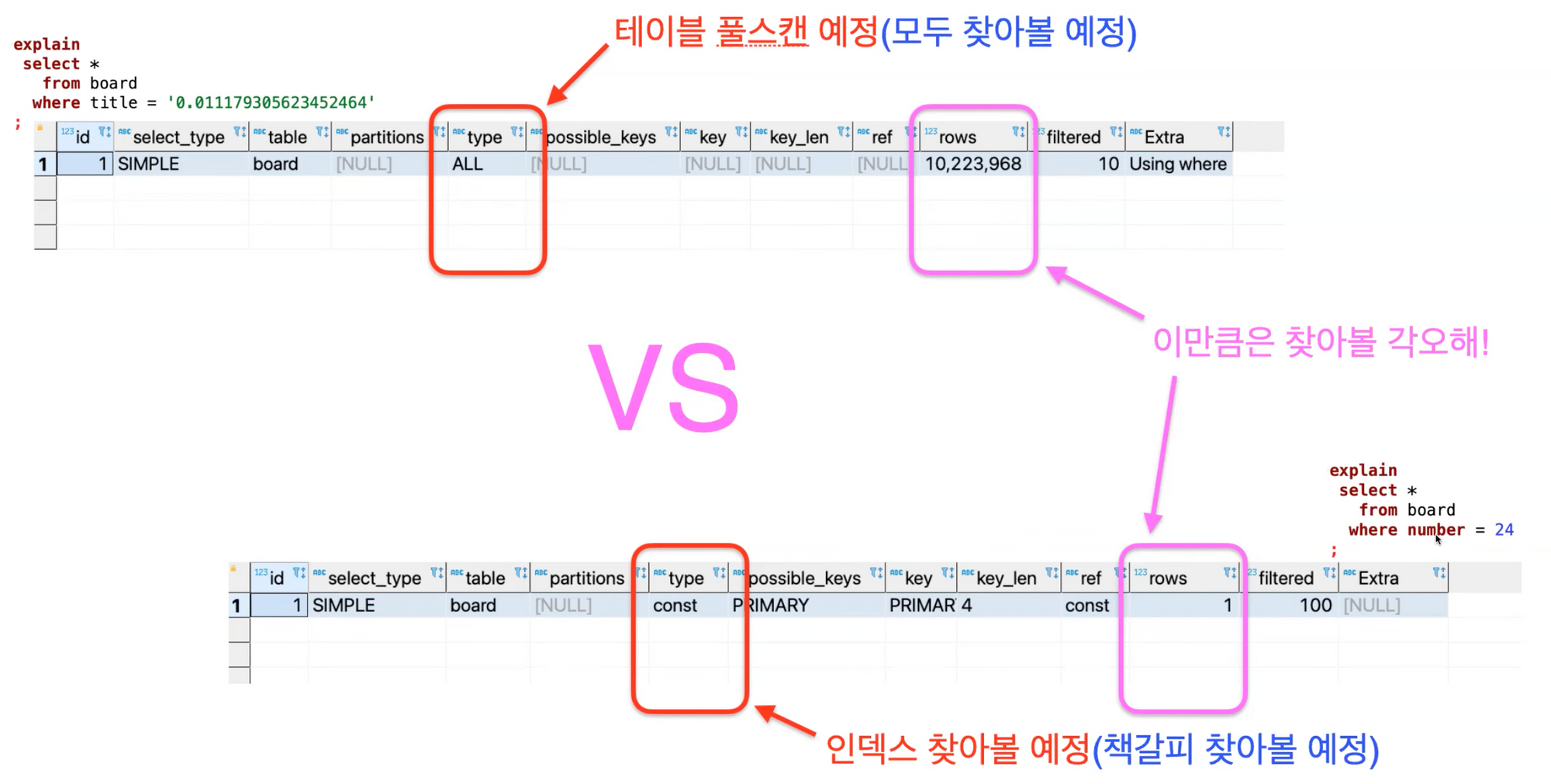
-
type은 데이터를 찾을 방식(ALL - 풀스캔, const - 인덱스), rows는 검색할 양을 나타냅니다.
-
같은 테이블내에서의 검색인데 두 쿼리의 실행계획이 다르다.
-
그 이유는 PK,FK,UNIQUE가 자동으로 인덱스를 생성하기 때문이다.
▷ 직접 다른 컬럼에서 인덱스 생성
-
create index [인덱스 이름] on [테이블명(컬럼명)]를 이용하면 인덱스를 직접 생성할 수 있다. -
인덱스 이름은 자유롭게 지정할 수 있다.

- type의 대표적인 유형
- ALL : 인덱스 안찾고 하나하나 다 찾아볼 예정
- const : 인덱스 찾아볼 예정(PK, FK, UNIQUE 중에서)
- ref : 인덱스 찾아볼 예정(내가 만든 인덱스 중에서)
- range : 인덱스 찾아볼 예정(크다 “<”, 작다">” 등 범위 검색 중에서)
▷ 주의점
- 빠른 검색을 위해 모든 컬럼에 인덱스를 적용하게 되면
데이터를 등록, 수정할 때 마다 정렬을 시도하기 때문에 속도가 느려지게 된다. - 따라서, 검색에 자주 사용되는 컬럼에 인덱스를 적용하는 것이 좋다.
📝 Redis
-
Memcached와 비슷한 캐시 시스템으로서 동일한 기능을 제공하면서 영속성, 다양한 데이터 구조와 같은 부가적인 기능을 지원하고 있다.
-
모든 데이터를 메모리에 저장하고 조회한다. (인메모리 데이터베이스)
-
다른 인메모리 디비들과의 가장 큰 차이점은 레디스의 다양한 자료구조이다.
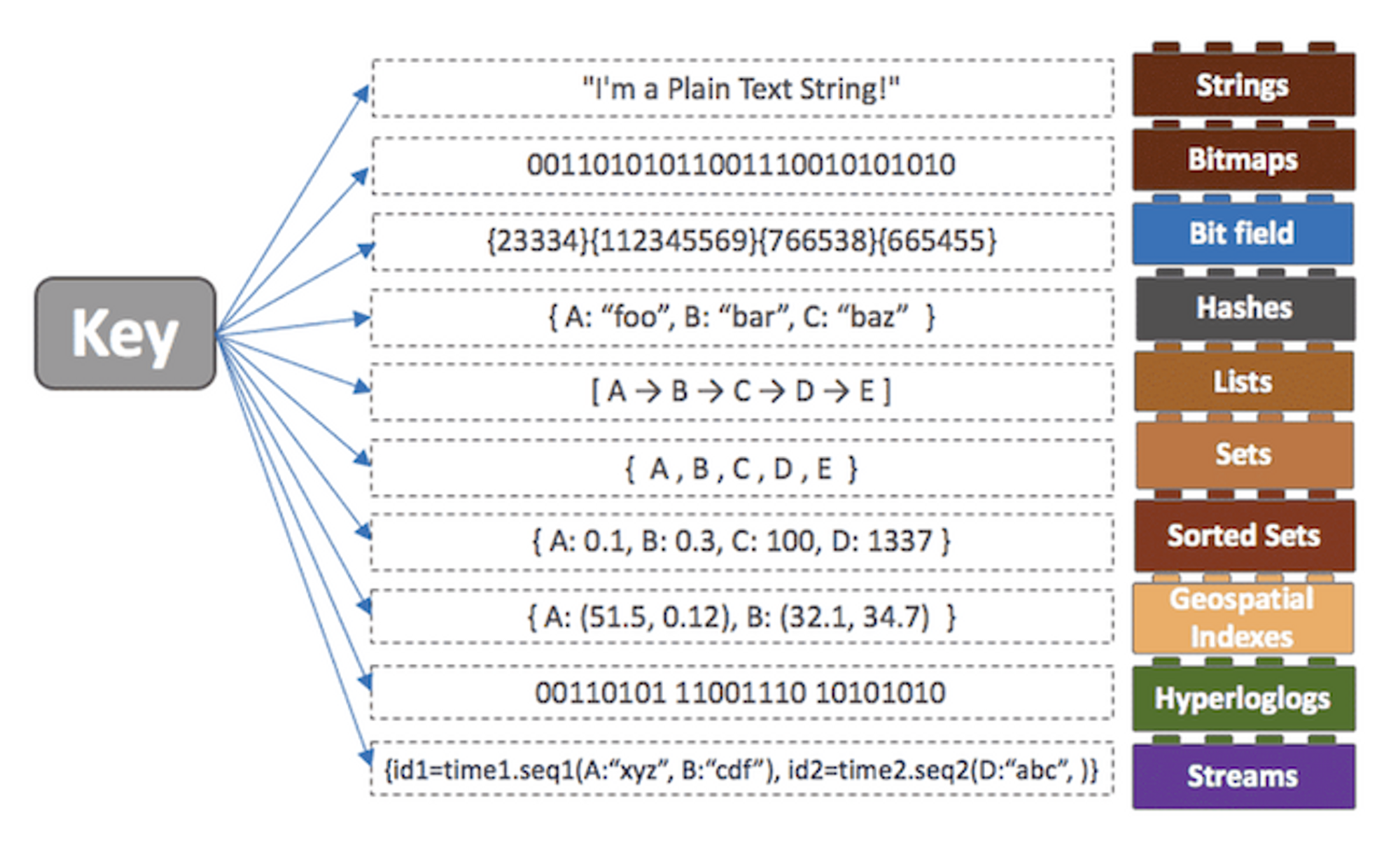
-
다양한 자료구조를 지원하게 되면 개발의 편의성이 좋아지고 난이도가 낮아진다는 장점이 있다.
-
어떤 데이터를 정렬 할 때, DBMS를 이용한다면 DB에 데이터를 저장하고, 저장된 데이터를 정렬하여 다시 읽어오는 과정은 디스크에 직접 접근을 해야하기 때문에 시간이 더 걸린다는 단점이 있다.
-
하지만 이 때 In-Memory 데이터베이스인 Redis를 이용하고 레디스에서 제공하는 Sorted-Set이라는 자료구조를 사용하면 더 빠르고 간단하게 데이터를 정렬할 수 있다.
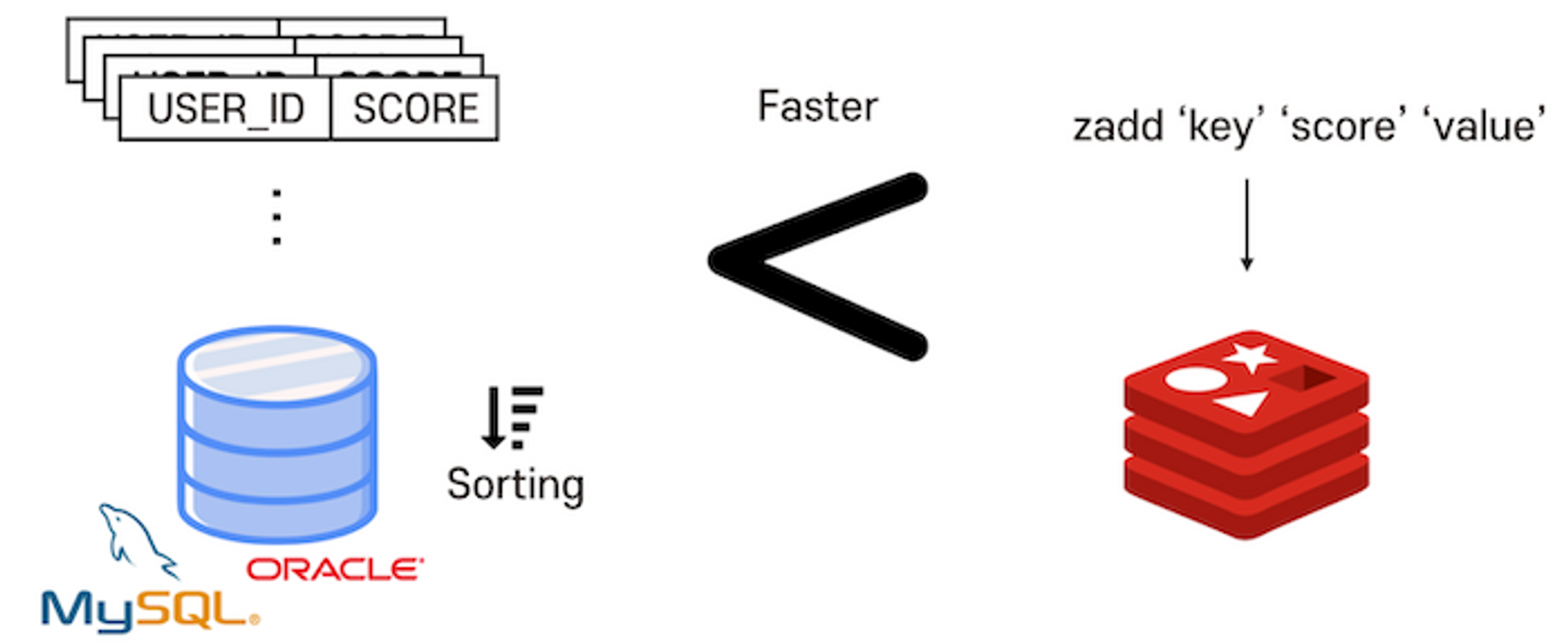
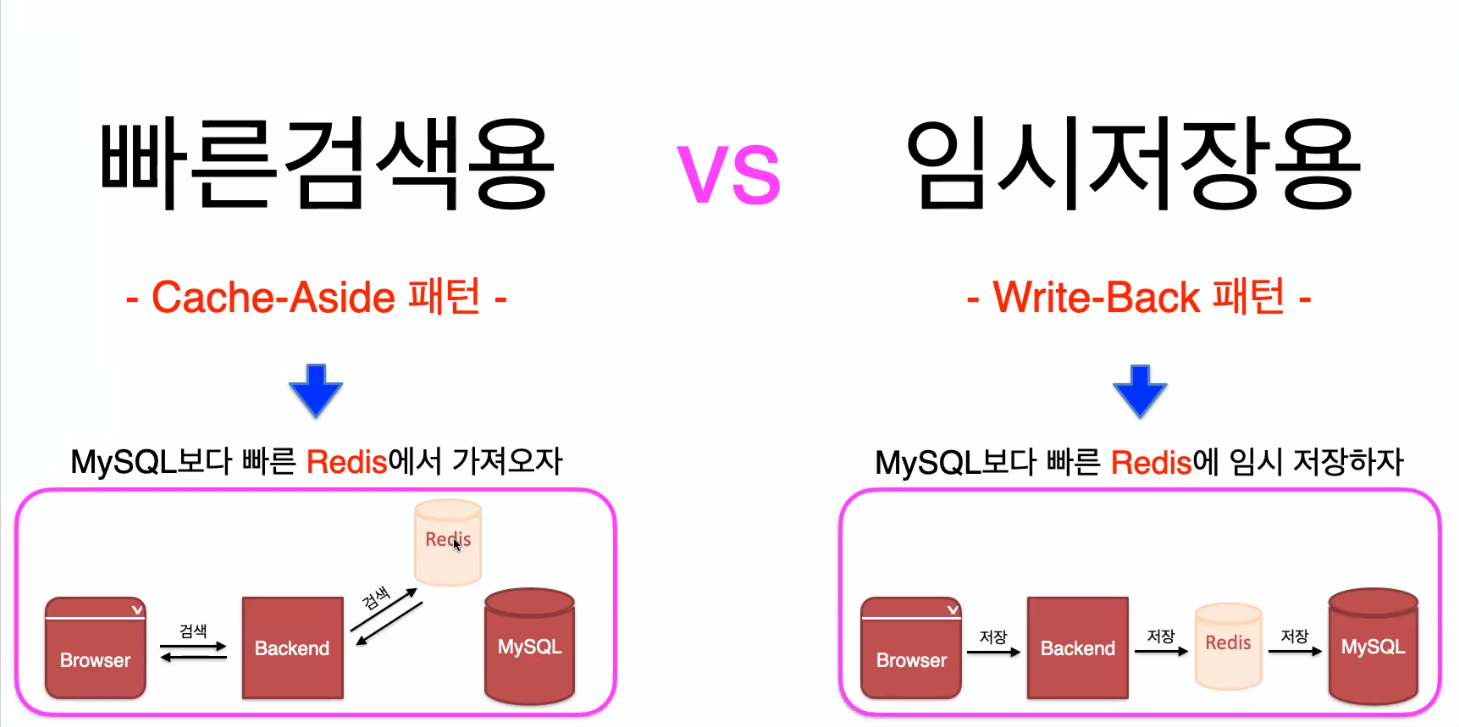
Redis에서 자주 사용되는 Cache-Aside패턴과 Write-Back패턴에 대해 알아보겠다.
▷ Redis만의 특징
▶ 1. 더욱 다양한 데이터 구조
문자열 뿐만 아니라 List, Set, 정렬된 Set, Hash, Bit 배열, hyperloglogs (매우 적은 메모리로 집합의 개수를 추정할 수 있는 방법)을 지원합니다. 프로그램에서 위의 다양한 자료구조를 사용할 수 있습니다. 예를 들어, Sorted Set을 활용하여 게임유저의 상위랭크 정보를 쉽게 제공할 수 있습니다.
▶ 2. Snapshots
레디스는 특정시점에 데이터를 디스크에 저장하여 파일 보관이 가능합니다. 또한, 장애 상황시 복구에 사용할 수 있습니다.
▶ 3. 복제
Master — Salves 구조로, 여러개의 복제본을 만들 수 있습니다. 따라서 데이터베이스 읽기를 확장할 수 있기 때문에 높은 가용성(오랜 시간동안 고장나지 않음) 클러스터를 제공합니다.
▶ 4. 트랜젝션
트렌젝션이란 데이터베이스 상태를 변경시키는 작업 단위를 의미하고, 원자성, 일관성, 독립성, 지속성의 특징을 가지고 있습니다. Redis는 이러한 특징을 지원합니다.
▶ 5. Pub / Sub messaging
Publish(발행)과 Sub(구독)방식의 메시지를 패턴 검색이 가능합니다. 따라서 높은 성능을 요구하는 채팅, 실시간 스트리밍, SNS 피드 그리고 서버상호통신에 사용할 수 있습니다.
▶ 6. 루아 스크립트 지원
매우 경량화된 절차스크립트 언어인 루아를 지원합니다. eval 명령어를 사용하여 루아스크립트를 실행시킬 수 있습니다. 따라서, 프로그램을 명료하게하고 성능을 높일 수 있습니다.
▶ 7. 위치기반 데이터 타입 지원
Redis는 실시간 위치기반데이터를 지원합니다. 따라서, 두 위치의 거리를 찾거나, 사이에 있는 요소 찾기등의 작업을 수행할 수 있습니다. 이를 활용하여 맛집, 길찾기 그리고 지도기반의 고성능 서비스를 제공할 수 있습니다.
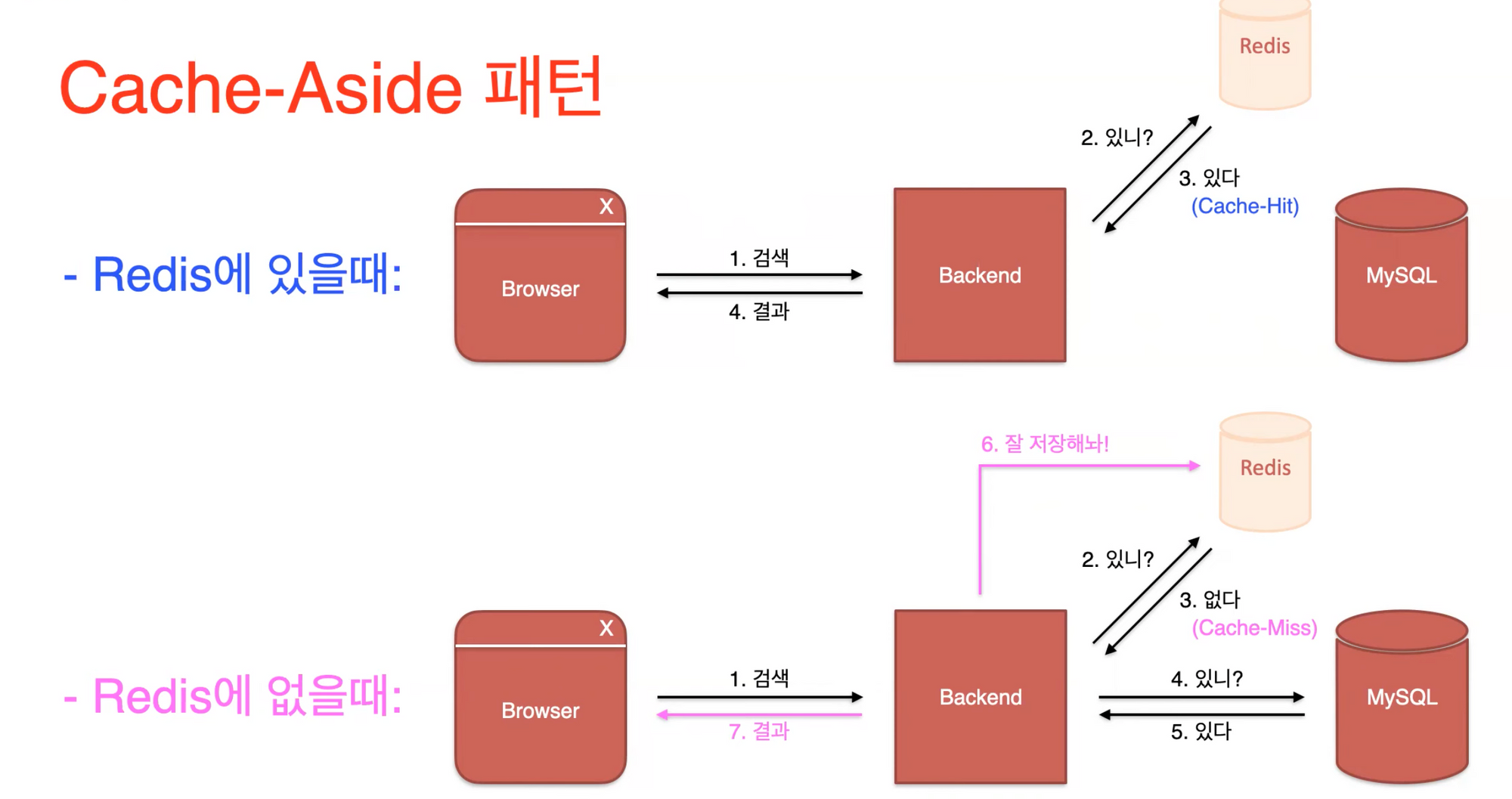
▷ Cache-Aside 패턴(빠른검색용)
- 검색 시 Redis에서 먼저 찾아보고 Redis에 저장된 내용이 있다면 저장된 정보를 바로 보여주고
- 없다면 MySQL에서 정보를 보여준 다음 검색된 내용을 redis에 저장하는 방식
- 같은 내용의 2번째 검색부터는 redis에 저장된 정보를 보여주기 때문에 속도가 빨라진다.
▷ Write-Back 패턴(임시저장용)
- redis에 먼저 임시 저장해놓은 뒤 Database에 저장하는 방식
- 디스크 기반의 Database에 저장해야할 데이터 양이 많은 경우 디스크I/O(속도가 느린 현상)가 발생하게 되는데 이를 해결하기 위해 Write-Back 패턴을 사용한다.
📝 maxmemory

-
위의 명령어로 maxmemory 기본 설정을 확인할 수 있다.
- 기본값: 0 (내 컴퓨터 메모리 전부 다 사용한다.)
▷ maxmemory-policy

- 위의 명령어로 maxmemory-policy 기본 설정을 확인할 수 있다.
- 기본값: noeviction (기존 데이터 제거 안한다.)
- 추천: allkeys-lru - 모든 key들 중 가장조금 최근에 사용된 것부터 지운다.
오늘의 마무리 👍
- 복습
- github 공부
- 블로그 포스팅
- 데일리 퀴즈
- 알고리즘 문제 풀기
항상 겸손한 자세로 배우면서 성장하자, 할 수 있다!! 💪
출처 : 코드캠프
