- T
transpose, 전치
df.tranpose()
- pivot
- 데이터 컬럼에서 key 컬럼(index, columns)를 지정하여 값을 변형(행과 열 반환)
- index 지정 컬럼은 행의 index로 사용하고,
- columns 지정 컬럼은 열의 index로 사용한다.
- 그러니까, DataFrame의 컬럼에서 모두 고르는것이다!!
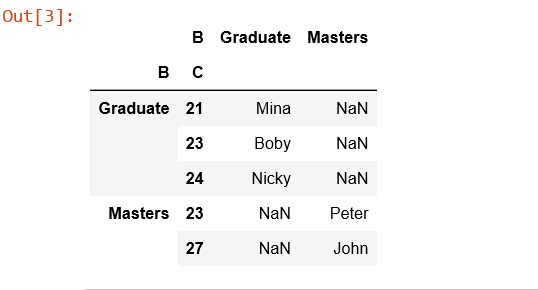
df.pivot(index='gender', columns='age', values='weight')
df.pivot(index='gender', columns='age')['weight]
# 남자 여자를 기준으로, 각 연령대에 대한 weight 찾기
#복수의 pivot column
df.pivot(index='gender', columns='age', values=['weight', 'address'])
# 남자 여자를 기준으로 ,각 연령대에 대한 무게와 주소 각각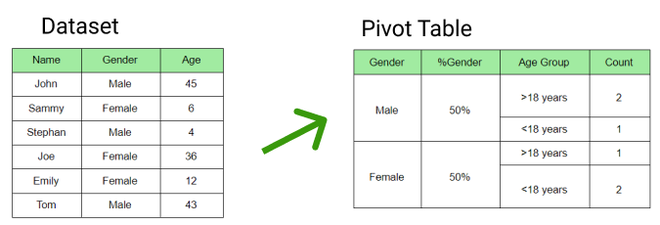
- melt
-
pivot의 반대 개념으로, ID로 지정한 컬럼을 제외한 나머지 컬럼의 자료를 위에서 아래로 쌓는다.
-
id_vars 컬럼을 기준으로 원래 데이터에 있던 여러 개의 컬럼을 'variable' 컬럼에 쌓고, 'value' 컬럼에 ID와 variable에 해당하는 값을 넣어주는 식으로 재구조화
-
그러니까, id_vars를 제외한 컬럼들이 variable의 도메인이 되고, value에는 각 컬럼의 값이 저장됨
df.melt(id_vars=['index','column'])
df.melt(id_vars=['index','column', value_vars=['value_1']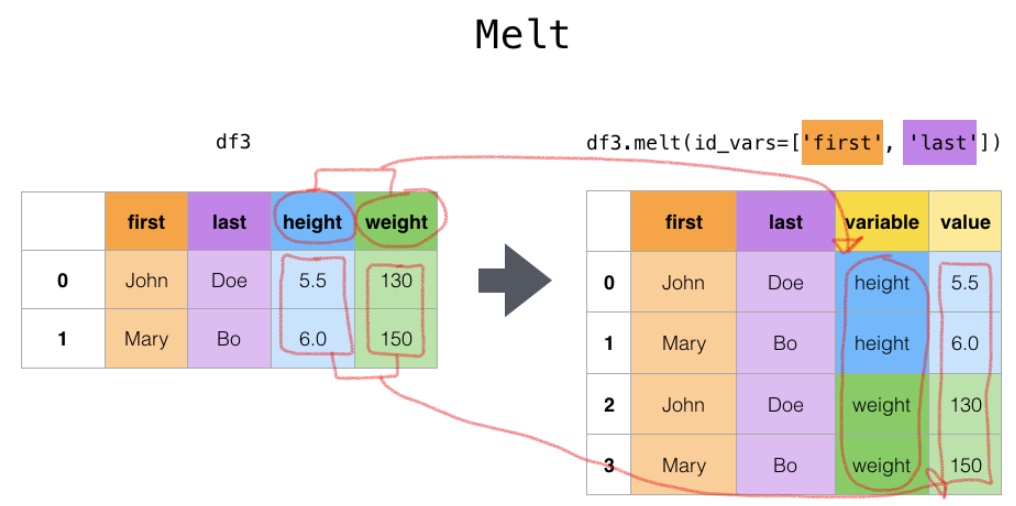
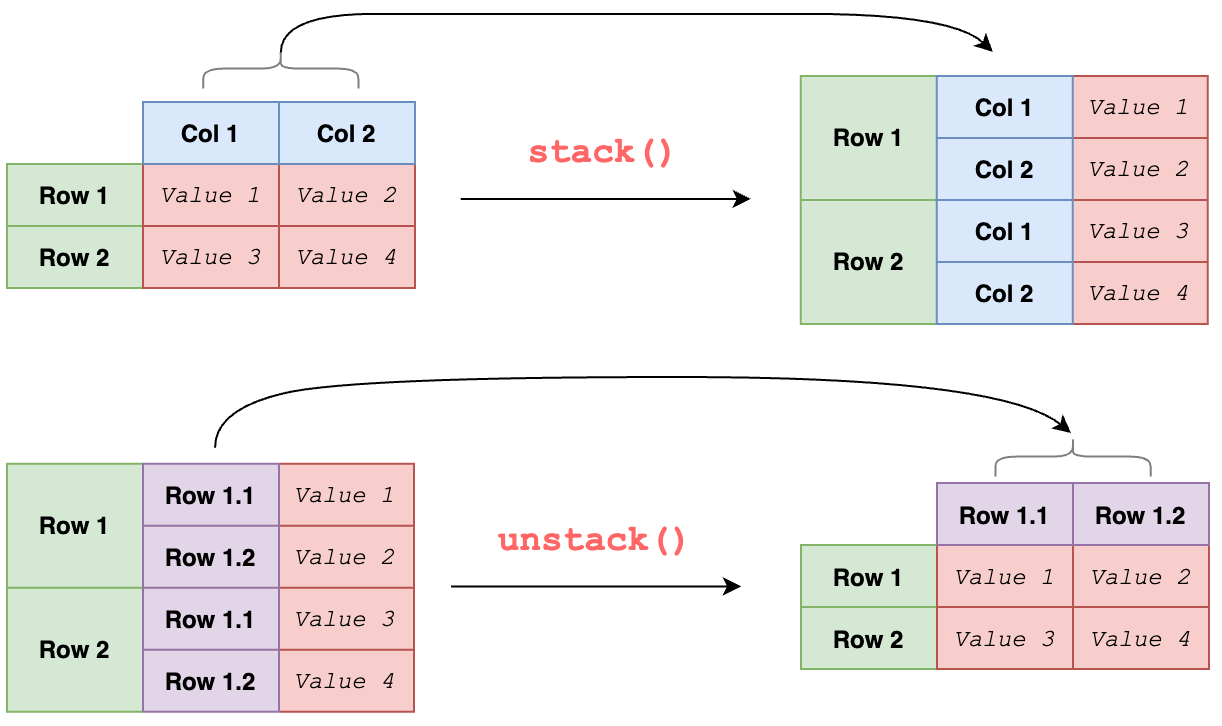
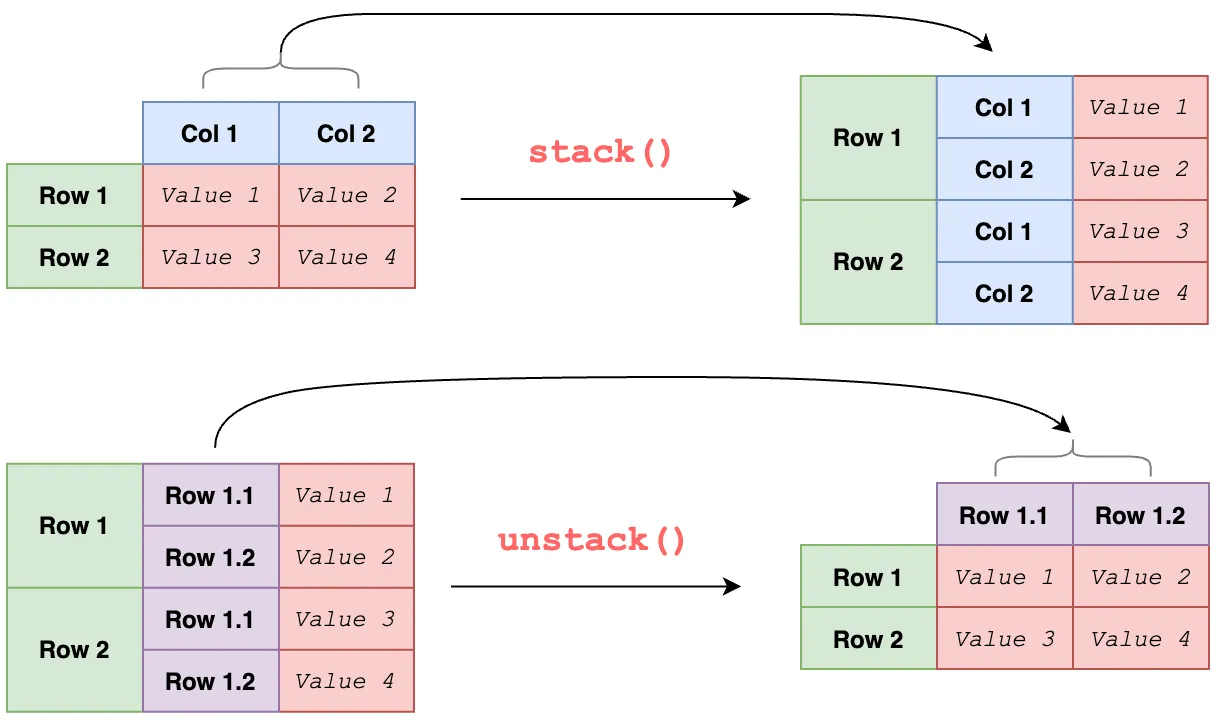
- stack / unstack
stack : 컬럼의 인덱스(열이름)을 행의 여러개 라벨 중 가장 왼쪽의 라벨로 un-pivot(melt)
unstack : stack의 반대, 행의 여러개 라벨 중 가장 왼쪽이 라벨을 컬럼의 인덱스로 변환
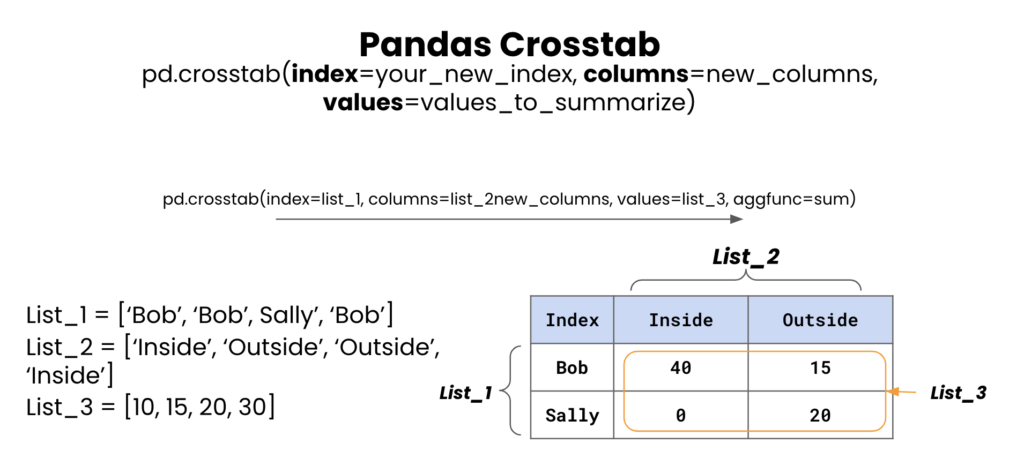
- crosstab 교차표
- 지정된 컬럼의 값(수준)별 빈도를 요약하여 도수분포표(frequency table), 분할표(contingency table) 생성
- 범주형 변수의 빈도 현황 파악에 자주 사용되며, 행렬의 합(margin) 또는 구성 비율 계산 가능
- 카이..스퀘어..?ㄱ스콥? 검정? 할때 사용
6.sort 정렬하기
- 행 인덱스 기준 정렬 : DataFrame.sort_index() # 인덱스 기준 내림차순 정렬
- 열 기준 정렬 : DataFrame.sort_values(by='c1', ascending=False) # c1열 기준 내림차순 정렬
- 중복 처리
- 중복 데이터 처리 : duplicated, drop_duplicates
- duplicated() : 중복되는 행을 Boolean 값으로 표시한다.
- DataFrame.drop_duplicates(['column_1']) : column_1을 기준으로 중복된 행을 제거하고 unique 한 행들만 표시
df.duplicated() # 결과는 boolean
df[df.duplicate()] # 중복된 데이터 조회
df.reset_index(drop=True, inplace=True) # 데이터의 인덱스를 리셋하기(중복행 빠지니깐)
df.drop_duplicates(ignore_index=True) # 중복된 데이터 제거