빅데이터 분석
1.Pandas Series 구조와 DataFrame 구조

series 구조 생성하기pd.Series({'a':1, 'b':2, 'c':3})DataFrame 구조 생성하기데이터 파일 읽어오기DataFrame 구조 파일 저장하기데이터 내용 확인데이터 내용 미리보기 : head(n), tail(n)요약 정보 확인하기 : 크기 확
2.데이터 선택 Subset
slice : 이름 또는 인덱스를 이용한 부분 데이터 선택DataFrame의 특정 열 또는 행의 데이터를 선택 및 추출 대괄호 이용. 복수 열 선택 시 \[ ] 대괄호 추가: 콜론을 이용하여 행의 범위로 가져오기 가능loclabel of column 열의 이름을 줘야
3.Pandas 데이터 결합 | concatenate, append, merge, join
기준 열(key column)을 사용하지 않고 단순히 데이터를 연결함 :concatenate기본적으로는 위/아래로 행추가. index값 중복 가능concat(A,B), A.append(B)데이터 연결 concat기존 데이터에 추가로 연결 append.병합 mergeDa
4.Pandas 데이터 변환 | T, pivot, melt, stack, unstack, crosstab, sort, duplicated
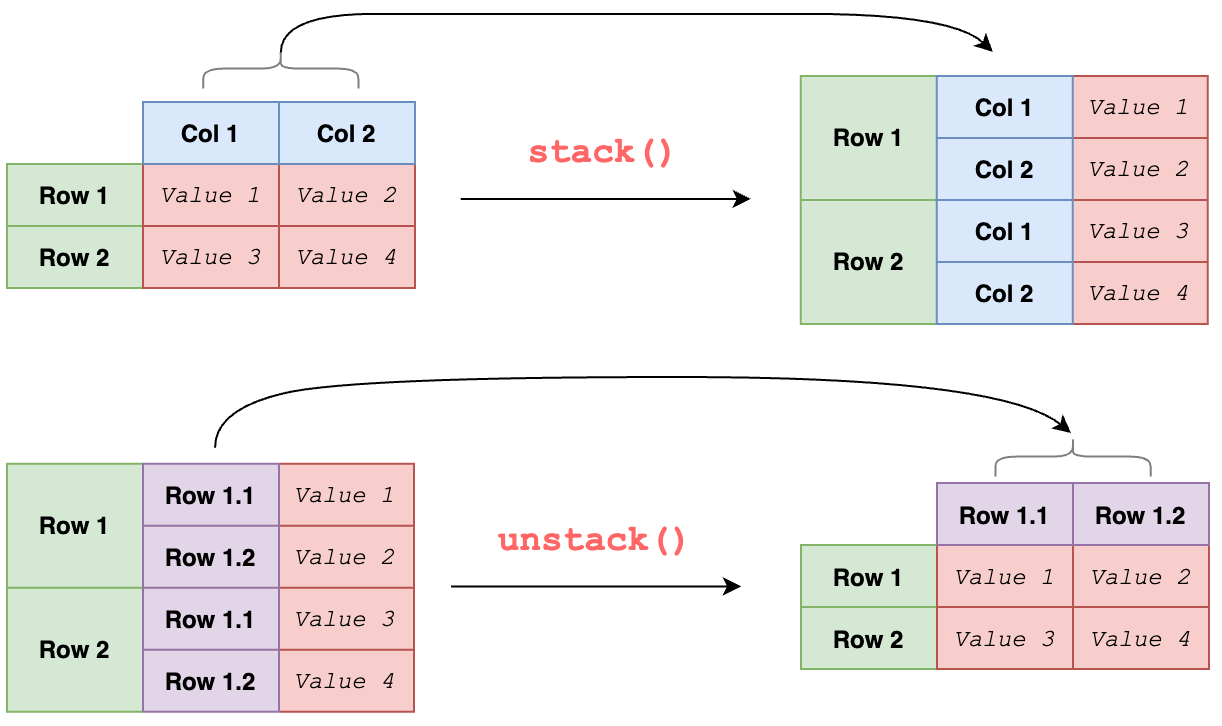
Ttranspose, 전치df.tranpose()pivot데이터 컬럼에서 key 컬럼(index, columns)를 지정하여 값을 변형(행과 열 반환)index 지정 컬럼은 행의 index로 사용하고,columns 지정 컬럼은 열의 index로 사용한다.그러니까, Da
5.확률분포 | 연속확률분포와 이산확률분포 | 정규분포, 표준정규분포, t분포, 카이제곱분포, f분포, 이항분포
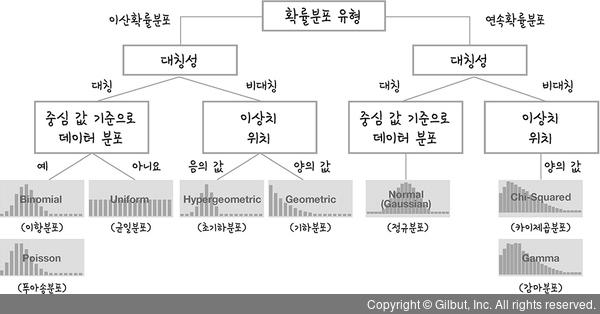
확률분포는 연속확률분포와 이산확률분포로 나뉜다. 확률분포란 확률변수에 대하여 정의된 실수를 0과 1 사이의 실수(확률)에 대응시키는 함수이다.이산확률분포 PMF연속확률분포 PDF 누적확률분포 CDF정규분포가우스분포X ~ N(mu, sigma)prob = stats.no
6.통계적 추론 | 통계적 가설검정, 가설 검정 수행 | 검정통계량(z, t, f, 카이제곱)

7.머신러닝 알고리즘 | 예측 | 선형 회귀분석, 다중 선형 회귀분석, 규제화 회귀분석 | Linear Regression, Ridge, LASSO, ElasticNet
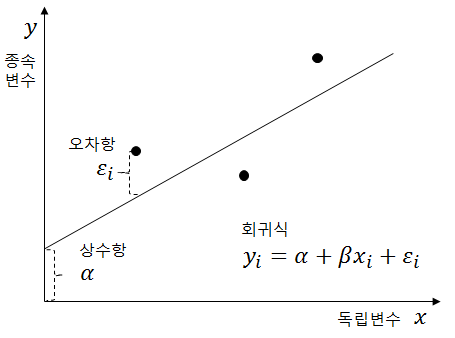
모델링이란, 대용량의 데이터로부터 이들 데이터 내에 존재하는 관계, 패턴, 규칙 등을 탐색하고 변수들 간의 관련성을 찾아내어 모형화함으로써 유용한 지식을 추출하는 일련의 과정을 말한다.모델링의 종류: Data 모델링: 지도학습, 비지도학습회귀: 주어진 데이터에 근거하여