
🥊 머신러닝 튜토리얼 cat-and-dog
💡 이미지 분류 CNN을 1시간30분 타임어택으로 완성해보자!
🚀 목표 설정
👓 Kaggle cat-and-dog Dataset
👣 같은 내용의 강의를 다양한 데이터셋으로 활용해보자
Kaggle의 데이터셋 중 하나인 cat-and-dog를 활용하여 이미지 분류 CNN을 사용해보는 것을 목적으로 한다.
강의 내용을 붙여보고, 마음대로 고쳐쓰면서 삽질하자. 그렇게 하다가 정답을 보면 아~ 하게 되는 것을 1차 목표로 삼았다.
또한 이 글을 작성하는 것으로 어떤 부분이 문제였는지 파악하는데 사용한다.
🔮 미리보는 개념정리
개와 고양이로 나누기 위한 CNN 이미지 분류
입력 - 중간 - 출력
👨💻 시행착오
강의자료 코드 Copy & Paste
우선은 알고 있는 자료로 똑같이 구현해보기 위해서 가지고 있는 이미지 분류 코드를 그대로 갖다 붙이기 시작했다. 내용을 아는 것은 아니었고, 그냥 비슷하게 생긴 데이터를 비슷하게 결과를 내보고 싶었다.
import os
os.environ['KAGGLE_USERNAME'] = 'yungsanghwang' # username
os.environ['KAGGLE_KEY'] = 'e57b686e5ced5139126b8cd598b7a958' # key
!kaggle datasets download -d puneet6060/intel-image-classification
!unzip -q intel-image-classification.zip
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D, Flatten, Dropout
from tensorflow.keras.optimizers import Adam, SGD
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
train_datagen = ImageDataGenerator(
rescale=1./255, # 일반화
rotation_range=10, # 랜덤하게 이미지를 회전 (단위: 도, 0-180)
zoom_range=0.1, # 랜덤하게 이미지 확대 (%)
width_shift_range=0.1, # 랜덤하게 이미지를 수평으로 이동 (%)
height_shift_range=0.1, # 랜덤하게 이미지를 수직으로 이동 (%)
horizontal_flip=True # 랜덤하게 이미지를 수평으로 뒤집기
)
test_datagen = ImageDataGenerator(
rescale=1./255 # 일반화
)
train_gen = train_datagen.flow_from_directory(
'seg_train/seg_train',
target_size=(224, 224), # (height, width)
batch_size=32,
seed=2021,
class_mode='categorical',
shuffle=True
)
test_gen = test_datagen.flow_from_directory(
'seg_test/seg_test',
target_size=(150, 150), # (height, width)
batch_size=32,
seed=2021,
class_mode='categorical',
shuffle=False
)
from pprint import pprint
pprint(train_gen.class_indices)
preview_batch = train_gen.__getitem__(0)
preview_imgs, preview_labels = preview_batch
plt.title(str(preview_labels[0]))
plt.imshow(preview_imgs[0])
from tensorflow.keras.applications import ResNet50
input = Input(shape=(224, 224, 3))
base_model = ResNet50(weights='imagenet', include_top=False, input_tensor=input, pooling='max')
x = base_model.output
x = Dropout(rate=0.25)(x)
x = Dense(256, activation='relu')(x)
output = Dense(6, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])
model.summary()
from tensorflow.keras.callbacks import ModelCheckpoint
history = model.fit(
train_gen,
validation_data=test_gen, # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20, # epochs 복수형으로 쓰기!
callbacks=[
ModelCheckpoint('model.h5', monitor='val_acc', verbose=1, save_best_only=True)
]
)
✍ 결과 : 카피 앤 페이스트
결과가 제대로 나오지 않는다. 데이터셋에 맞게 전처리 및 적절한 값 수정이 필요하다!
CNN 종류 변경
같이 튜토리얼을 진행하는 캠퍼의 제안으로 CNN 종류를 다른 것으로 교체해 라이브러리를 임포트 해보기로 했다. 여기까지만 해도 난 내가 뭘 해야 하는지 제대로 모르고 있었다..
성능이 얼마나 차이나는지 EfficentNetB0 라이브러리를 임포트했다.
from tensorflow.keras.applications import EfficientNetB0
input = Input(shape=(224, 224, 3))
base_model = EfficientNetB0 (weights='imagenet', include_top=False, input_tensor=input, pooling='max')
x = base_model.output
x = Dropout(rate=0.25)(x)
x = Dense(256, activation='relu')(x)
x = Dense(128, activation='relu')(x)
x = Dense(64, activation='relu')(x)
output = Dense(2, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])
model.summary()✍ 결과 : CNN 종류 변경
여전히 근본적인 것에는 접근하지 못했고, 제대로 된 결과가 나오지 않았다.
배치 사이즈 수정
배치 사이즈를 조정해주는 것으로 작업 속도가 줄어들었다고 해서 시도해 보았다.
train_gen = train_datagen.flow_from_directory(
'training_set/training_set',
target_size=(224, 224), # (height, width)
batch_size=16,
seed=2021,
class_mode='categorical',
shuffle=True
)
test_gen = test_datagen.flow_from_directory(
'test_set/test_set',
target_size=(224, 224), # (height, width)
batch_size=16,
seed=2021,
class_mode='categorical',
shuffle=False
)v✍ 결과 : 배치 사이즈 수정
유의미한 결과를 체감하지는 못했다. 게다가 결과는 여전히 제멋대로였다.
Softmax -> Sigmoid
같이 작업한 멤버들과 결과를 논의했더니, 개와 고양이 두 가지로 나눌 수 있기 때문에 이진 논리 회귀를 시도하면 좋다고 했다. 즉시 따라해 봤다.
train_gen = train_datagen.flow_from_directory(
'training_set/training_set',
target_size=(224, 224), # (height, width)
batch_size=16,
seed=2021,
class_mode='binary',
shuffle=True
)
test_gen = test_datagen.flow_from_directory(
'test_set/test_set',
target_size=(224, 224), # (height, width)
batch_size=16,
seed=2021,
class_mode='binary',
shuffle=False
)
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])
from tensorflow.keras.models import load_model
model = load_model('model.h5')
print('Model loaded!')
test_imgs, test_labels = test_gen.__getitem__(55)
y_pred = model.predict(test_imgs)
classes = dict((v, k) for k, v in test_gen.class_indices.items())
for img, test_label, pred_label, ax in zip(test_imgs, test_labels, y_pred, axes.flatten()):
for prediction in y_pred:
if prediction[0] > 0.5:
prediction[0] = 1
else:
prediction[0] = 0
fig, axes = plt.subplots(2,8, figsize=(20,12))
for img, test_label, pred_label, ax in zip(test_imgs, test_labels, y_pred, axes.flatten()):
test_label = classes[int(test_label)]
pred_label = classes[int(pred_label)]
ax.set_title('GT:%s\nPR:%s' % (test_label, pred_label))
ax.imshow(img)✍ 결과 : Softmax -> Sigmoid


놀랍게도 결과물이 출력이 되었다!
🤔 그러나 값이 정확하지 않았다. 강아지 사진에는 테스트/예측 라벨 값이 강아지로 나오는데, 고양이 사진에도 강아지로 나오는 문제가 있었다.
🤹♀️ 트러블 슈팅 : y_pred 값 출력
값이 도대체 뭔데?
print(y_pred)그래도 모르겠다
🥏 피드백 - 다시 Softmax
튜터님의 피드백에서 이진논리회귀와 다항논리회귀 둘 다 풀 수 있는 모델이기 때문에 Softmax로 다시 돌아가 학습시켜보기로 했다. 다만 여러가지 값을 바꿔가면서 말이다
🕵️♀️ 스레시홀드 값과 argmax
원래 Softmax를 활용한 이미지분류 모델에서는 마지막 출력 코드에서 argmax로 값을 가져와 뿌려주는데, Sigmoid를 활용한 모델에서는 따로 스레시홀드를 조건을 달아가면서 나눠줬다.
그리고 이 부분에 대한 피드백으로 굳이 필요할까? 라는 의문을 제기했다.
test_imgs, test_labels = test_gen.__getitem__(55)
y_pred = model.predict(test_imgs)
classes = dict((v, k) for k, v in test_gen.class_indices.items())
fig, axes = plt.subplots(2,8, figsize=(20,12))
for img, test_label, pred_label, ax in zip(test_imgs, test_labels, y_pred, axes.flatten()):
test_label = classes[np.argmax(test_label)]
pred_label = classes[np.argmax(pred_label)]
ax.set_title('GT:%s\nPR:%s' % (test_label, pred_label))
ax.imshow(img)🕵️♀️ Hidden Layer 추가하기
중간층의 Dense 레이어 설정은 왜 필요한지, 어떤 기준에서 설정되었는지에 대한 물음의 답은 뚜렷하게 얻어내지 못했지만, Hidden Layer를 추가해서 붙여보는 것으로 시도해 볼 방법을 찾게 되었다.
from tensorflow.keras.applications import EfficientNetB0
input = Input(shape=(224, 224, 3))
base_model = EfficientNetB0 (weights='imagenet', include_top=False, input_tensor=input, pooling='max')
x = base_model.output
x = Dropout(rate=0.25)(x)
x = Dense(256, activation='relu')(x)
x = Dense(128, activation='relu')(x)
x = Dense(64, activation='relu')(x)
output = Dense(2, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])
model.summary()✍ 결과 : 다시 Softmax
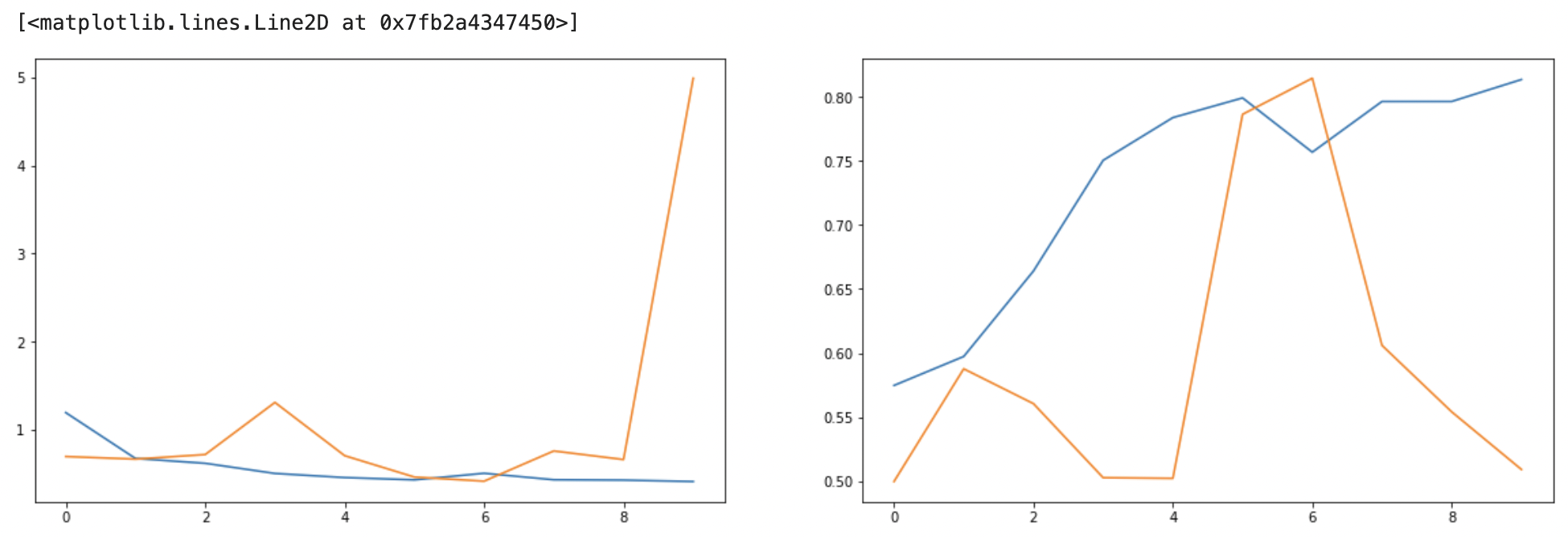
validation loss, acc 모두 부정적인 결과물이 나왔다. 어째서?
🤹♀️ 트러블 슈팅 : 학습 에폭 수를 바꿔보기
학습 에폭을 10까지 올려뒀지만, 다시 5로 수정하여 다시 돌려보기로 했다.
🎊 성공!
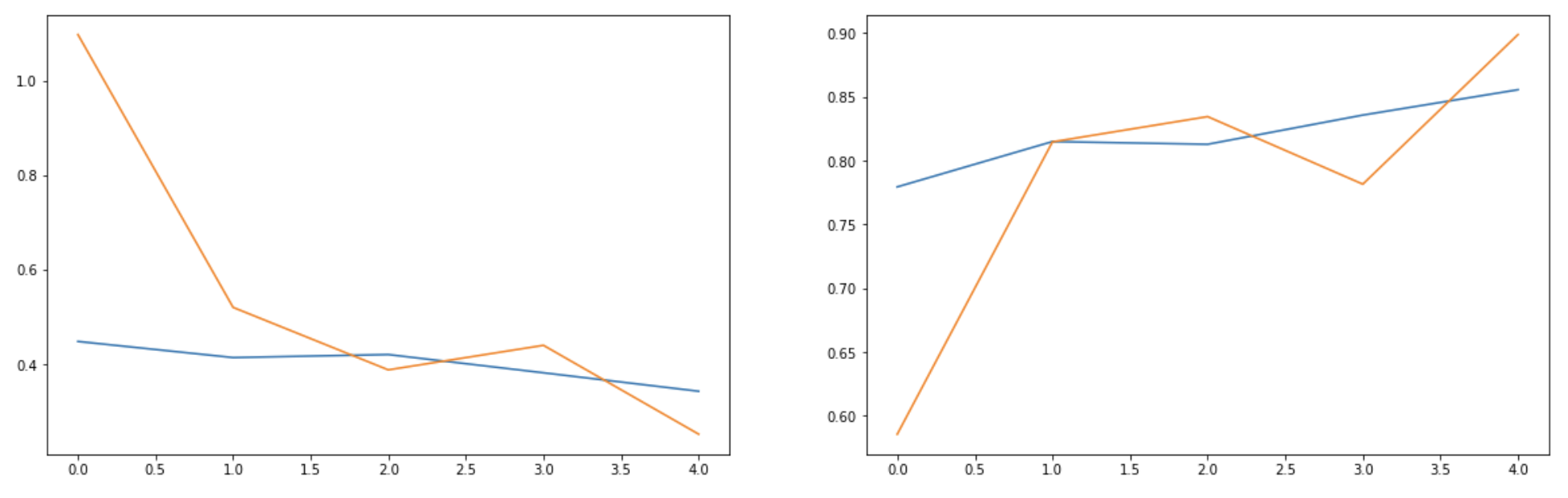
그래프도 나름 예쁘게 나오고 출력해보니 데이터도 일정 부분 잘 못 나올 때도 있지만, 그래도 어느 정도는 정확도를 가지고 있었다.

🎯 이런 결과물을 얻을 수 있게 시도한 내용은 다음과 같다
1. 히든 레이어 추가하기
2. 배치 사이즈 조정하기
3. 소프트맥스 -> 시그모이드 실험하기
4. CNN 종류 변경해보기(효과는 크게 체감 안됨)
5. 에폭 수 바꿔가면서 계속 돌려보기(이게 체감이 큼)
6. 예측 값 프린팅해보기
초보인 내가 모델을 설계하면서 바꿔볼 수 있었던 내용은 위와 같았고, 결과적으로는 계속 몇 번이고 시도해가면서 좋은 결과가 나오게 되었다.
어쩌면 운으로 만들어 냈을 수도 있지만, 그래도 내가 적용할 수 있는 요소를 찾아내서 기쁘다.
기타 시도한 내용
🥏 로컬환경에서 Kaggle을 이용한 머신러닝 학습
이걸 시도하게 된 이유는 colab에서의 하루 제한시간을 모두 소진했기 때문에 어떻게든 컴퓨터로 시도하려고 했다.
🚩레퍼런스 링크1, 🚩레퍼런스 링크2, 🚩레퍼런스 링크3
시도한 환경은 vs code로 python에 접근, jupiter notebook
결과적으로는 속도가 별 차이가 나질 않는다...
