Deadline: 24.07.18
오늘 리뷰할 논문은 ICML 2020에서 발표된 Learning Deep Kernels for Non-Parametric Two-Sample Tests 이다.
논문 출처: https://arxiv.org/pdf/2002.09116
코드 출처: https://github.com/fengliu90/DK-for-TST
🔸기존 문제점:
1. 단순한 커널을 사용해 제한적인 적응성 (공간적 균질, 길이 척도에만 적응함)
🔸제안 내용:
1. 두 샘플 집합이 같은 분포에서 나왔는지 판별하는 새로운 커널 기반 테스트 방법
2. 심층 신경망으로 매개변수화된 커널을 사용
🔸결과:
1. 테스트 정확도 높임
2. 분포의 복잡한 변화에 잘 적응하기 때문에 고차원/복잡한 데이터에 적합
3. 벤치마크 및 실제 데이터에 대한 가설 검정에서 우수한 성능 발휘
(이 논문은 통계적 가정과 추정 전제하에 실험을 진행했기때문에
복잡한 수식이 너무 많아서 간단하게만 정리함😁)
1. Intro
'two sample tests' 란, 두 샘플 집합이 동일한 분포에서 나왔는지를 판단하는 가설 검정 방법이다.
하지만 전통적인 방법들은 분포에 대한 강한 모수적 가정이 필요하거나 저차원 데이터에만 효과적이다.
그러나 우리가 다루고자 하는 문제들은 복잡한 구조를 가진 분포를 포함하며, 단순한 커널**은 종종 구별하기 어려운 평균 임베딩** 을 만든다.
*커널: 두 데이터 포인트 간의 유사도를 측정하는 함수로, 특히 고차원 공간에서 사용
*임베딩: 각 distribution에 대한 커널 평균 임베딩을 구성하고, 이 임베딩의 차이를 측정함
모든 특성 커널에 대해 두 분포가 동일하면 평균 임베딩도 동일하며,
평균 임베딩 간의 거리는 최대 평균 차이(MMD)로 측정됨
예를 들어, 여러 모드가 있는 데이터셋 **에서 각 모드의 구조가 다를 경우 단순한 커널은 데이터의 각 모드 내에서 균일하게 처리하여 많은 샘플이 필요하다.
*데이터셋: 여러 개의 중심값(또는 피크)을 가진 분포를 나타내는 데이터셋을 의미
예) 두 개의 다른 중심값을 가진 혼합 가우시안 분포
가우시안 분포는 하나의 모드를, 혼합된 분포는 두 개의 모드를 가지는데 각 모드가 서로 다른 특징을 가질 수 있다.
단순한 커널 방법은 러한 모드 간의 차이를 잘 구별하지 못할 수 있다.
각 모드의 구조를 이해하면 더 효과적으로 분포를 구별할 수 있기때문에 복잡한 함수를 모델링하기 위해 저자들은 deep kernel을 채택해 심층 신경망으로 커널을 구성한다.
이 논문에서는 깊은 신경망이 샘플의 특징을 추출하고, 이 특징들에 대해 간단한 커널을 적용하는 방식의 커널을 사용한다.
이는 커널을 매우 유연하게 하여 공간의 다른 부분에서 매우 다른 복잡한 동작을 학습할 수 있다.
distribution을 비교하는 다른 방법은 두 분포 간의 classifier를 학습시키고 정확도를 평가하는 것이다.
논문에서 제안하는 프레임워크는 이 접근법을 포함하면서, 심층 커널이 데이터를 더 효율적으로 사용할 수 있음을 보인다.
또 cross-entropy surrogate loss가 아닌 test power를 최대화하도록 직접 representation을 학습시켰다.
정리하면 저자들은 복잡한 합성 분포, 고에너지 물리 데이터 및 도전적인 이미지 문제를 포함한 여러 시뮬레이션 및 실제 데이터셋에서 심층 신경망으로 구성된 커널을 테스트했다.
그 결과, 학습된 심층 커널이 단순한 얕은 방법보다 우수하며, test power를 최대화하는 학습이
cross-entropy surrogate loss을 통한 학습보다 뛰어남을 확실히 입증하였다.
2. MMD Two-Sample Tests
두 샘플 집합이 같은 분포에서 나왔는지를 알아보기 위해 통계적 검정을 했고,
MMD라는 방법을 사용해 두 분포의 차이를 계산하였다.
MMD는 Maximum mean discrepancy로, 커널 라는 함수를 이용해 각 점에서의 유사성을 측정한다.
이로서 두 distribution의 차이를 계산하는데 사용된다.
3. Limits of Simple Kernels
Translation-invariant Gaussian Kernel
이 방식은 데이터의 위치와 상관없이 동일한 방식으로 데이터를 관찰한다.
즉, 두 데이터 포인트 𝑥와 𝑦 사이의 거리에 기반하여 유사도를 계산한다.
따라서 데이터의 전체적인 구조를 파악하지 못하고, 각 모드 내의 세부적인 구조를 구별하는 데 한계가 있다.
그래서 저자들은 아래와 같은 새로운 커널, deep kernel을 제안한다.
이 커널은 데이터의 각 모드 구조를 이해하고, 모드 간의 차이를 효과적으로 구별할 수 있다.
translation invariant(=변환 불변성)을 갖지 않는 커널, 즉 deep kernel은 데이터의 위치에 따라 다르게 작동할 수 있다.
이는 데이터가 공간에서 다르게 분포하는 경우에 더 잘 적응할 수 있어, 다양한 형태를 더 효과적으로 학습할 수 있다는 장점을 가진다.
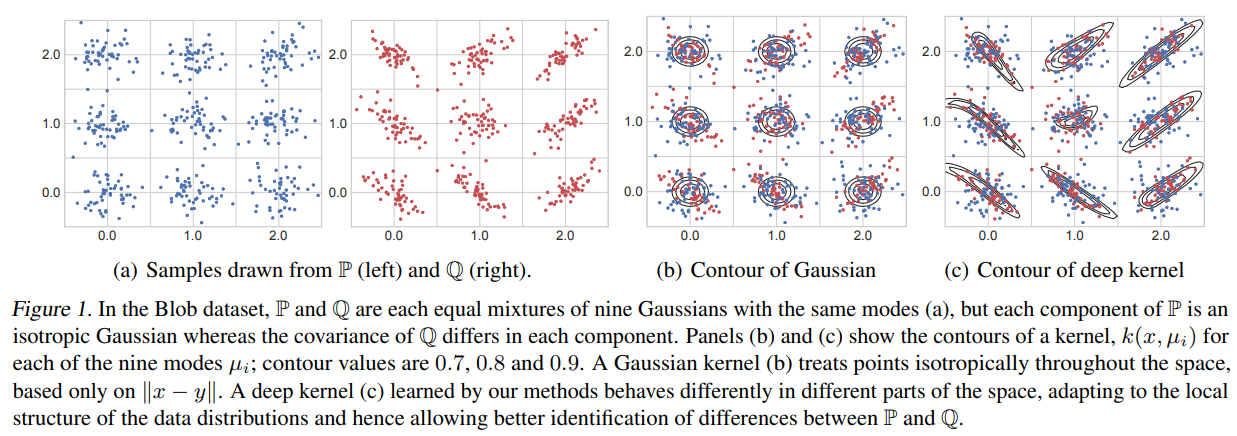
논문에서 MMD 검정을 위해 사용하는 대부분의 단순한 커널(가우시안, 라플라스 등)은 translation invariant을 가진다.
즉 공간 전체에서 동일한 방식으로 작동하지만 분포의 행동이 공간을 따라 변하는 경우에는
(그림 1처럼 모양이 달라지거나 밀집된 영역이 있음) 최적이 아니다.
하지만 translation invariant을 갖지 않는 그림 1c의 deep kernel은 서로 다른 영역에서 필요한 다양한 형태에 적응할 수 있다.
deep kernel을 학습하는 알고리즘은 다음과 같다. (그냥 그렇구나 하고 넘어감)

4. Relationship to Classifier-Based Tests
두 개의 샘플을 검정하는 다른 방법은 두 데이터셋 사이에 classifier를 훈련시키고 성능을 평가하는 것이다.
저자들은 이를 Classifier Two-Sample Test based on Sign, C2ST-S라 부르기로 하였다.
방법은 아래와 같다.
1. 두 샘플 데이터셋을 사용하여 classifier를 훈련
2. 테스트 데이터셋에서 그 classifier의 성능을 평가함
만약 두 샘플이 같은 분포에서 나왔다면, 분류는 불가능하고 성능은 무작위 추측과 같아짐
성능 지표는 accuracy를 사용하였다.
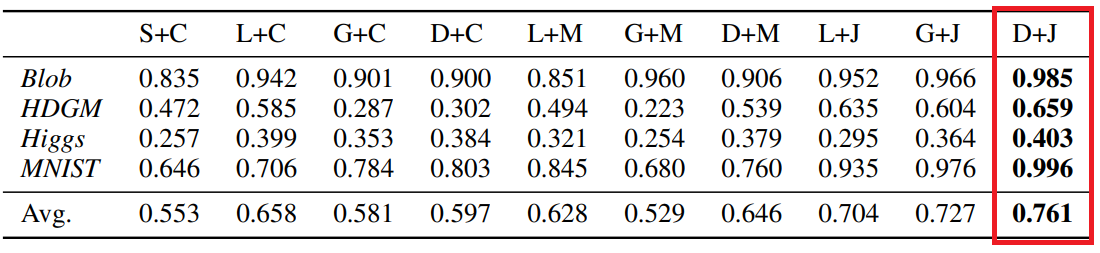
7. Experimental Results
Benchmark Dataset(Blob, HDGM, Higgs, MNIST에 대해서 비교 실험을 진행했고,
그 결과 저자들이 제안한 MMD-D 섹션에서 가장 높은 정확도를 달성했다.
S+C corresponds to C2ST-S, L+C to C2ST-L, and D+J to MMD-D. L+M is the method proposed y Kirchler et al. (2020).