1st Deadline: 24.06.30
2nd Deadline: 24.07.05
오늘은 ICML 2020에서 발표된 Google research의 A Simple Framework for Contrastive Learning of Visual Representations 논문을 리뷰하려고 한다.
논문 출처: https://arxiv.org/pdf/2002.05709
코드 출처: https://github.com/google-research/simclr
🔸기존 문제점:
1. 복잡한 아키텍처와 메모리 뱅크의 필요성
2. 데이터 증강의 중요성에 대한 이해 부족
3. 표현과 대조 손실 사이의 단순한 관계
4. 작은 배치 크기와 제한된 학습 단계
🔸제안 내용:
1. 효과적인 데이터 증강 기법
2. 비선형 변환 도입
3. 더 큰 배치 크기와 더 많은 학습 단계
🔸결과:
1. 대조 학습의 효과 극대화
2. ImageNet 성능 향상
3. 레이블이 제한된 상황에서 성능 향상
1. Intro
사람의 개입없이 효과적인 시각적 표현을 학습하는 것은 오래전부터 문제로 여겨졌다.
이렇게 시각적 표현을 학습하는 방법에는 크게 Generative(생성적)와 Discriminative(판별적) 두가지의 접근법으로 나뉜다.
먼저 생성적 접근법은 입력 공간의 픽셀을 생성하거나 모델링하는 것을 학습하지만,
계산 비용이 많이 들고 표현 학습에 반드시 필요하지 않을 수 있다.
판별적 접근법은 지도 학습에서 사용되는 것과 유사한 목적 함수를 사용하여 표현을 학습하지만,
레이블이 없는 데이터셋에서 입력과 레이블을 모두 유도하는 사전 작업(pretext tasks)**을 수행하도록 네트워크를 훈련한다.
이 때 대부분 휴리스틱하게 사전 작업을 만들었기때문에 학습된 표현의 일반성이 제한될 수 있다.
*pretext task: 라벨이 없는 데이터에서 유용한 특징을 학습하도록 도와주는 중간 작업.
예) 이미지의 일부를 가리고 나머지 부분을 통해 가려진 부분을 예측, 이미지 조각을 원래 위치에 맞게 맞추는 작업 등
따라서 저자들은 SimCLR라고 부르는 시각적 표현의 대조 학습을 위한 프레임워크를 제안했다. SimrCLR는 이전 task의 성능을 능가했고, 특수한 아키텍처나 메모리 뱅크가 필요 없다.
이 논문에서 다음 내용을 주장한다.
-
데이터 증강이 효과적인 representation을 생성하는 contrastive prediction task를 정의하는데 중요하고, supervised learning보다 더 강력한 데이터 증강이 필요함
-
representation과 contrastive loss 사이에 학습가능한 non-linear 변환을 도입하면 학습된 representation의 품질이 크게 향상됨
-
contrastive cross entropy loss를 사용하는 표현 학습은 정규화된 임베딩과 적절히 조정된 temperature parameter에서 이점이 있다.
-
contrastive learning은 supervised learning에 비해 더 큰 배치 크기, 더 긴 학습 시간에서 이점이 있다.
supervised learning처럼 더 깊고 넓은 네트워크에서 이점을 얻는다.
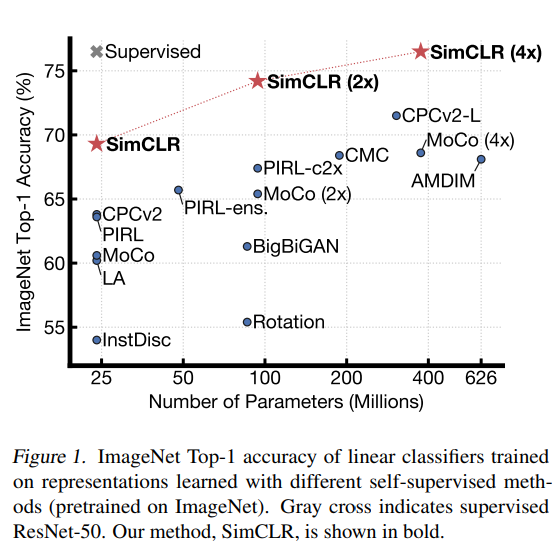
위 내용을 바탕으로 아래와 같은 성능을 달성하였다.
2. Method
2.1. The Contrastive Learning Framework
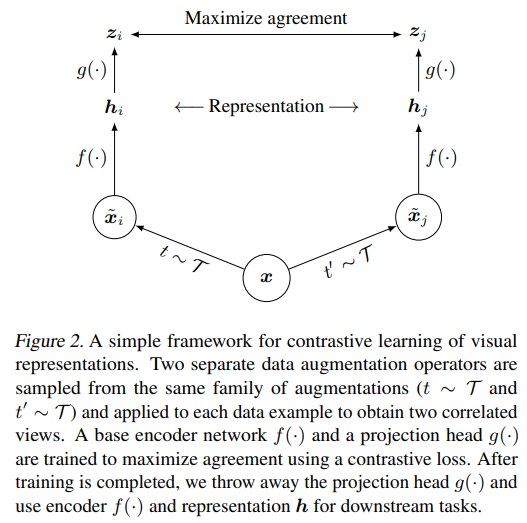
SimCLR framework이며, 순서대로 아래 네 가지 요소로 구성된다.
1. 확률적 데이터 증강 모듈:
주어진 데이터를 무작위 변환 후, 동일 샘플에 대해 두 개의 상관된 뷰 를 positive pair로 정한다.
여기에서 세 가지 증강을 차례대로 적용한다. (이 때, 모든 기법은 randomly 적용)
i) crop 후 resize
ii) color distortions
iii) Gaussian blur
2. 신경망 기반 인코더 (⋅):
증강한 데이터에서 representation vector를 추출
3. 작은 신경망 projection head (⋅):
representation을 contrastive loss가 적용되는 공간으로 매핑
4. Contrastive Loss fuction:
contrastive prediction을 위해 정의되는 손실 함수
positive pair ()에 대한 loss function은 아래와 같이 정의된다.
positive pair인 를 포함하는 {}가 주어지면 주어진 {}에 대해 에서 를 식별하는 것을 목표로 함
즉, 특정 샘플과 관련된 샘플을 찾아내는 것
4-1. 미니 배치 샘플링: 무작위 N개의 샘플 선택 ➡️ 두번 증강하여 2N개의 데이터 포인트 생성
4-2. negative sample: 미니배치 내의 다른 2(N-1)개의 증강된 예제를 negative로 선택
4-3. cosine similarity: 데이터 포인트들 간의 유사도를 코사인 유사도로 계산
4-4. contrastive loss: positive pair에 대해 loss를 계산 후, 미니 배치 내의 모든 positive pair에 대해 최종 손실 계산
4-5. temperature parameter : loss 계산 시 매개변수를 사용해 유사도의 민감도를 조정
위와 같은 방식으로 데이터 증강 및 효율적인 negative sample 선택, 기존 contrastie learning 알고리즘의 복잡성을 줄였다.
2.2. Training with Large Batch Size
2.2.0. Global BN
- 메모리 뱅크 없이 학습
- LARS 옵티마이저 사용으로 학습 안정화
- Cloud TPUs를 사용해 모델 훈련
2.2.1. Default setting
-
문제:
ResNet은 Batch Normalizaiton을 사용하며, 데이터 병렬 처리 시 BN 평균과 분산은 보통 장치별로 지역적으로 집계됨
하지만 contrastive learning은 positive pair가 동일한 장치에서 계산되기 때문에
모델이 local 정보를 활용해 예측 정확도를 높일 수 있어도 표현의 질이 향상되진 않음 -
해결책: 따라서 훈련 중 모든 장치에서 BN 평균과 분산을 집계해 이를 해결함
3. Data Augmentation for Contrastive Representation Learning
데이터 증강은 지도 및 비지도 학습에서 널리 사용되지만, contrastive prediction을 정의하는 체계적인 방법으로는 주목받지 못했다.
기존 방법들은 주로 네트워크 아키텍처를 변경하여 대조 예측을 했지만
이 논문에서는 간단한 randomly cropping과 resizing을 통해 복잡성을 피했다.
이를 통해 prediction을 신경망 아키텍처와 독립적으로 수행할 수 있고,
더 넓은 contrastive prediction을 정의할 수 있게 되었다.
4. Architectures for Encoder and Head
모델의 깊이와 너비가 증가하면 성능도 좋아지고,
non-linear projection head의 성능 > linear projection head 이며 head가 있을 때 성능이 훨씬 우수하다. projection head 이전의 층()이 이후의 층()보다 더 나은 representation을 가지는데,
이 이유는 contrastive loss에 의해 유도된 정보 손실 때문이라고 저자들은 추정한다.
따라서 non-linaer transformation ( · )을 활용하면, 에 더 많은 정보를 형성하고 유지할 수 있다.
는 데이터 변환에도 바뀌지 않도록 학습되기 때문에 downstream task에 유용한 정보를 제거할 수 있습니다.
5. Loss Functions and Batch Size
저자들은 NT-Xent loss를 contrastive loss function으로 자주 쓰이는 logstic loss 및 margin loss 와 비교했고, 그들보다 성능이 훨씬 뛰어남을 발견했다.
정규화와 적절한 매개변수 조절 없이 성능이 크게 떨어졌는데
정규화 없이 contrastive task의 정확도는 높지만, linear evalutation의 결과는 더 나빴다.
즉, 학습된 표현의 품질이 좋지 않았다는 것이다.
또한 더 큰 배치 크기는 더 많은 negative 샘플을 제공해 학습 속도를 높였다.
더 긴 훈련 시간은 더 많은 negative 샘픔을 제공해 결과를 개선했다.
짧은 훈련 시간 동안은 더 큰 배치 크기가 유리했고,
훈련 시간이 길어질 수록 배치 크기 간의 성능 차이가 줄어들었다.
6. Comparison with State-of-the-art
ResNet-50 모델을 다양한 너비 배율(1×, 2×, 4×)로 사용해 대규모 데이터셋에서 학습하고 평가했다.
주요 결과는 다음과 같다.
6.0 Linear Evaluation
Linear evaluation이란❓ pretext-task를 통해 학습했던 모델의 weights를 freeze한 후, 뒤에 FC layer를 붙여 fine-tuning을 진행한다.
그 결과 ResNet-50 (4×) 모델은 기존의 여러 방법보다 훨씬 더 나은 성능을 보였고,
이 모델의 성능은 감독 학습된 ResNet-50과 비슷한 수준이었다.
6.1 Semi-Supervised Learning
이 방법은 데이터셋의 label을 일부만 이용해 학습하는 것이다.
결과는 ILSVRC-12 데이터셋의 1% 및 10% 라벨을 사용하여 fine-tuning할 때, 최신 기술보다 더 나은 성능을 보였다.
또한 전체 ImageNet 데이터셋에서 pre-trained 모델을 fine-tuning 했더니 처음부터 학습한 모델보다 더 높은 성능을 보였다.
6.2 Transfer Learning
12개의 자연 이미지 데이터셋에서 다른 데이터셋으로 transfer learning 후 평가한 결과,
SSL 모델이 여러 데이터셋에서 감독 학습된 모델보다 더 우수한 성능을 보였고
fine-tunning에서는 5개의 데이터셋에서 SSL 모델이 감독된 기준을 능가했다.
