최근 모기업에서 주최한 Tech Summit에 다녀 온 후 다시 한번 AI 관련 산업이 대세라는 걸 느꼈다...
신문, 뉴스도 물론이지만 기술 세미나 대부분 AI Section 뿐이였다...
물론 블록체인, 메타버스 처럼 일시적인 붐일 수도 있겠으나,,, 유행에 뒤쳐질 수 없으니
AI의 시작과 현재 발전 수준 그리고 이론을 소개하도록 하겠다.
머신러닝 이란?
인간이 가진 문제를 해결하거나, 현상을 구현/설명 하려면 알고리즘(해결방법)을 정의 해야 한다.
**알고리즘**
수학과 컴퓨터 과학, 언어학 또는 관련 분야에서 어떠한 문제를 해결하기 위해 정해진
일련의 절차나 방법을 공식화한 형태로 표현한 것, 계산을 실행하기 위한 단계적 절차알고리즘을 도출하려면 사전 정보(문제, Input, Output)를 알야하고 그에 따라 답을 내는 방법이 나뉠 수 있다.
회귀
연속적인 값을 예측 하는 방법
ex: 나이 예측 (소스점 floating Point 가능)
분류
불연속적인 값을 예측
ex: Pass or Fail / 성적 분류 (A,B,C,E,F)
회귀 & 분류
회귀/분류 둘다 가능한 방법
ex: 나이를 클래스로 묶어 표시 (0~9세 : 클래스 0, 10~19세 : 클래스 2....)
머신러닝 방법 3가지
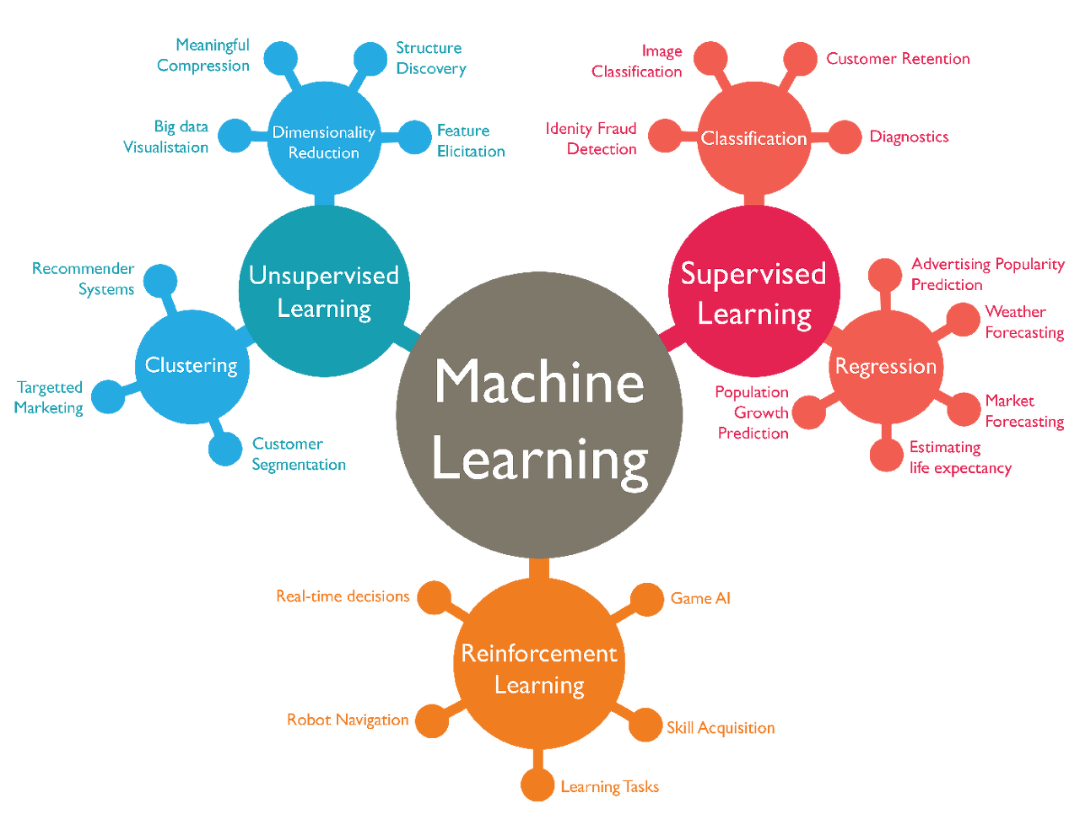
1. 지도학습 : 정답을 알려주면서 학습시키는 방법
- 기계에게 입력값과 출력값을 전부 보여주면서 학습시킴. 대신 정답(출력값)이 없으면 학습 시킬수 없고 입력값에 정답을 하나씩 입력해주는 작업을 하게 되는 경우가 있는데 그 과정을
노가다라벨링(Laberling, 레이블링) 또는 어노테이션(Annotation)이라고 한다.
2. 비지도학습 : 정답을 알려주지 않고 군집화(Clustering) 하는 방법
-
비지도 학습은 그룹핑 알고리즘(Grouping algorithm)의 성격을 띄고 있으며 라벨(Label 또는 Class)이 없는 데이터를 가지고 문제를 풀어야 할 때 도움이 된다.
ex: 음원 파일을 분석하여 장르를 팝, 락, 클래식, 댄스로 나누는 문제 -
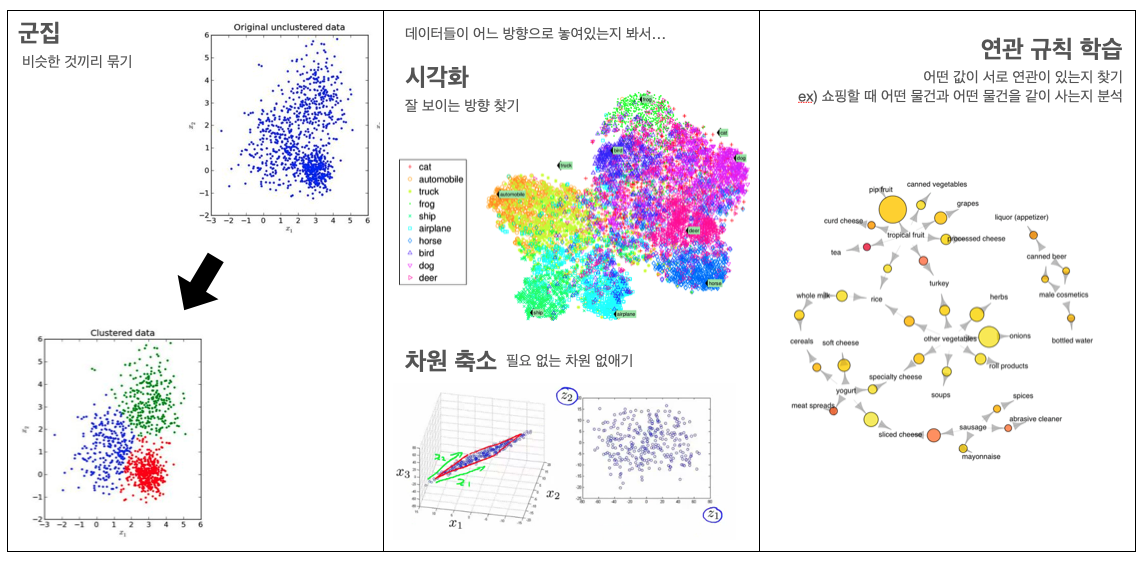
비지도학습의 종류 (참고)
3. 강화학습 : 주어진 데이터 없이 실행과 오류를 반복하면서 학습하는 방법 (Alphago 학습 방법)
- 행동 심리학에서 나온 이론으로 분류할 수 있는 데이터가 존재하지 않거나, 데이터가 있어도 정답이 따로 정해져 있지 않고, 자신이 한 행동에 대해 보상(Reward)를 받으며 학습
-
강화학습의 개념
- 에이전트(Agent)
- 환경(Environment)
- 상태(State)
- 행동(Action)
- 보상(Reward)
게임을 예로 들면 규칙을 따로 입력하지 않고 자신(Agent)이 게임환경(Environment)에서 현재 상태(State)에서 높은 점수(Reward)를 얻는 방법을 찾아가며 행동(Action)하는 학습 방법으로 특정 학습 횟수를 초과하면 높은 점수(Reward)를 획득할 수 있는 전략이 형성되게 됩니다. 단, 행동(Action)을 위한 행동 목록(방향키, 버튼)등은 사전에 정의가 필요 함.
이것을 지도 학습(Supervised Learning)의 분류(Classification)을 통해 학습 한다면 모든 상황에 대해 특정 행동을 해야 하는지 예측하고 답을 설정해야 하기 때문에 많은 비용과 데이터가 필요하다. 예를 들면 바둑을 학습한다고 가정하면, 아래와 같은 데이터가 필요함.
✔ 바둑의 경우의 수
208168199381979984699478633344862770286522453884530548425639456820927419612738015378525648451698519643907259916015628128546089888314427129715319317557736620397247064840935딥러닝의 등장 이후 강화 학습에 신경망을 적용하면서부터 바둑이나 자율주행차 같은 복잡한 문제에 적용할 있는 길이 열렸다.
-
선형회귀 (Linear Regression)
-
모든 문제는 선형으로 이루어져 있다는 가정하에 문제 해결 방법을 정의
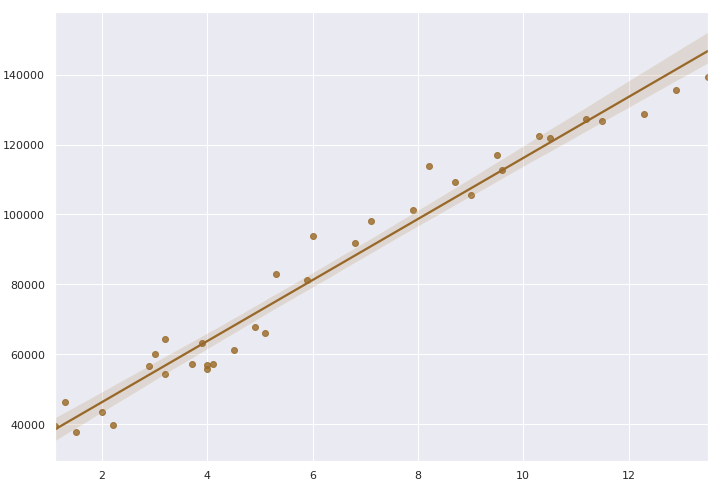
이런 그래프를 보고 가설을 세울 수 있는데, 임의의 직선 1개로 이 그래프를 비슷하게 표현할 수 있다고 가설 수립이 가능하다.
그러므로 이 모델은 수식으로써 아래와 같이 표현 할 수 있다.
여기서 정확한 시험 점수를 예측하기 위해 임의의 직선(가설)과 점(정답)의 거리가 가까워지도록 해야 한다. (=mean squared error)
여기서 H(x)는 우리가 가정한 직선이고 y는 정답 포인트 라고 했을 때 H(x)와 y의 거리(또는 차의 절대값)가 최소가 되어야 이 모델이 잘 할 습되었다고 할 수 있다.
여기서 임의로 만든 직선 H(x)를 가설(Hypothesis)이라고 하고 Cose를 손실 함수(Cost or Loss function)라고 한다.
경사 하강법(Gradient descent method)
- 손실함수를 최소화(Optimize) 하는 방법으로 Localminimum에 빠지지 않고 적절한 Iteration(반복)과 Learning rate(발자국 폭)으로 손실을 최소화 하는 작업 이다.
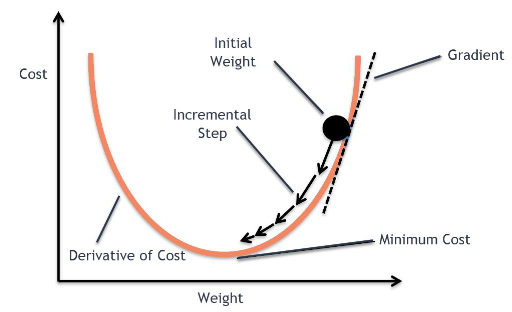
출처:https://towardsdatascience.com/using-machine-learning-to-predict-fitbit-sleep-scores-496a7d9ec48
여기서 Learning rate가 너무 크거나 작다면 최소값에 수렴하기가 힘들기 때문에 적절한 Learning rate를 노가다 작업을 통해 찾는게 필수적이다.
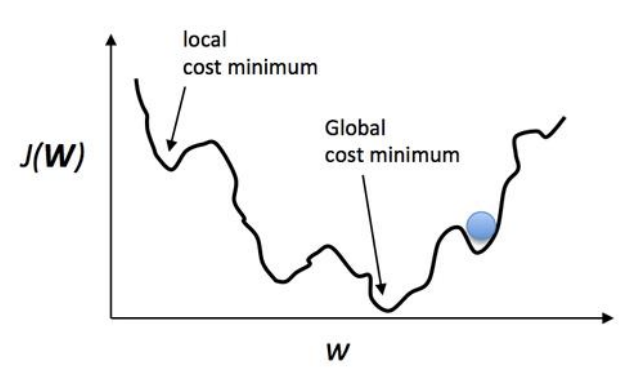
출처:https://regenerativetoday.com/logistic-regression-with-python-and-scikit-learn/
실질적인 목표는 위와 같은 솔실함수의 최소점인 Global cost minimum을 찾는 것이다. 그런데 우리가 한 칸씩 움직이는 스텝(Learning rate)를 잘못 설정할 경우 Local cost minimum에 빠질 가능성이 높다. Cost가 높다는 얘기는 만든 모델의 정확도가 낮다는 말과 같다. 따라서 우리는 최대한 Global minimum을 찾기 위해 좋은 가설과 좋은 솔실 함수를 만들어서 기계가 잘 학습 할 수 있도록 만들어야하고 그것이 바로 머신러닝 엔지니어의 핵심 역할 이다.
🎈 참고!
실습 환경 소개 (Colab)
Colaboratory란 구글에서 만든 개발 환경으로 구글 드라이브에 파일을 올려놓고 웹 상에서 직접 코드를 돌릴 수 있다.
[코드스니펫]
https://colab.research.google.com/drive/1ra0t0TuP0BSQlGCSVVaCoTIN3MJjEe7I
간단한 선형회귀 실습
TensorFlow를 이용하여 선형회귀 코드를 실행 하자.
https://colab.research.google.com/drive/1v9-UPBNCmq5MzivN0VToouy1ppUo4gCH#scrollTo=FABQeusq6k05캐글 선형회귀 실습
Kaggle은 다양한 데이터셋이 공개되어 있고 각 데이터 셋 별로 분석한 결과를 볼 수 있는 플랫폼이다.
https://colab.research.google.com/drive/1_zW7euAcxTpHqYTo_FpzeLS_DmyisaqP논리 회귀 (Logistic regression)
- 머신러닝에서 입력값과 범주 사이의 관계를 구하는 것!
논리회귀는 선형회귀를 발전시킨 것으로 선형회귀로 풀기 힘든 문제(ex Pass or Fail)를 설명한다.
예시) 대학교 시험 전 날 공부한 시간을 가지고 해당 과목의 이수 여부(Pass or Fail)을 예측 하는 문제
만약 선형 회귀를 사용하면 아래와 같이 표현 할 수 있다.
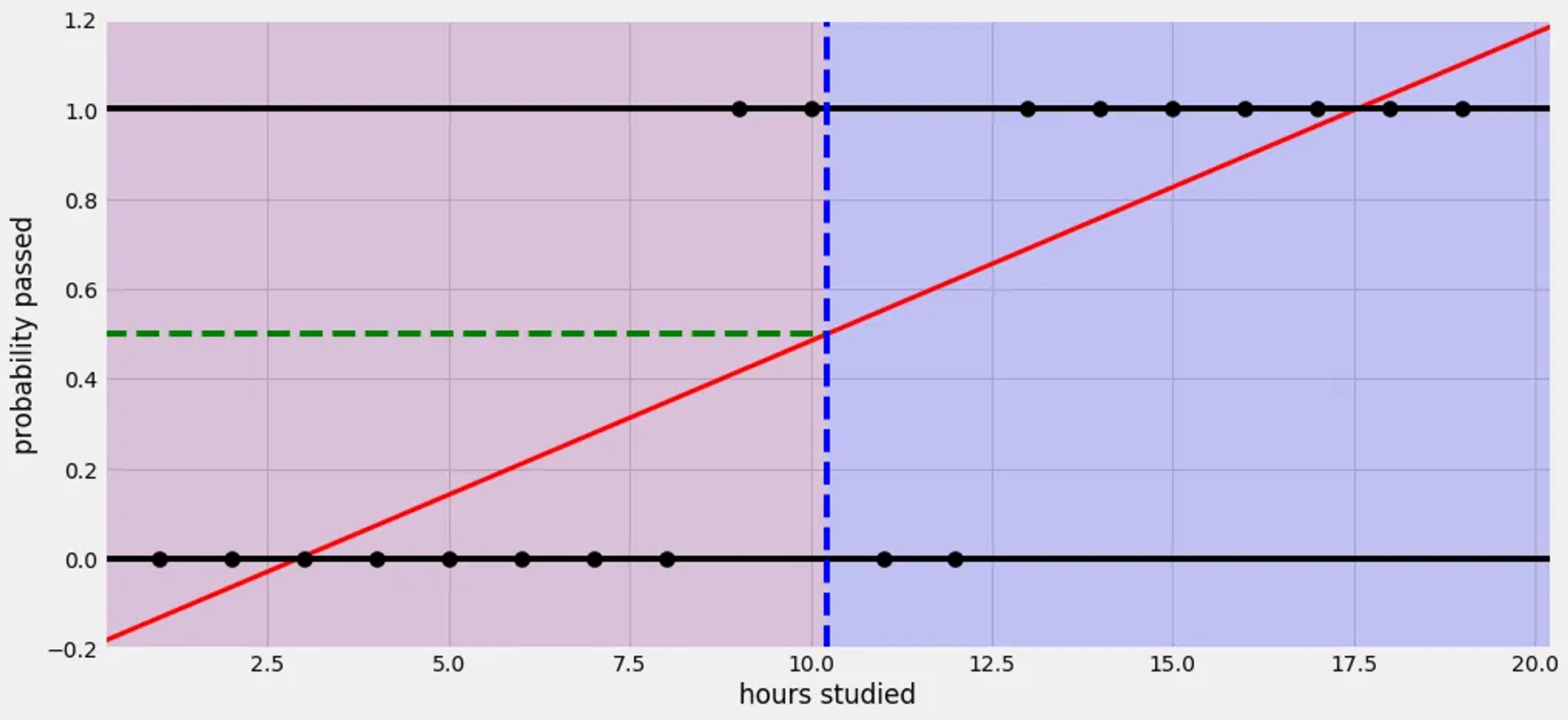
출처:https://ursobad.tistory.com/44
선형 회귀는 실제 결과 값을 도출 하기 힘들기 때문에 결과값을 잘 반영할 수 있는 Logistic function(=Sigmoid function)을 사용 한다.
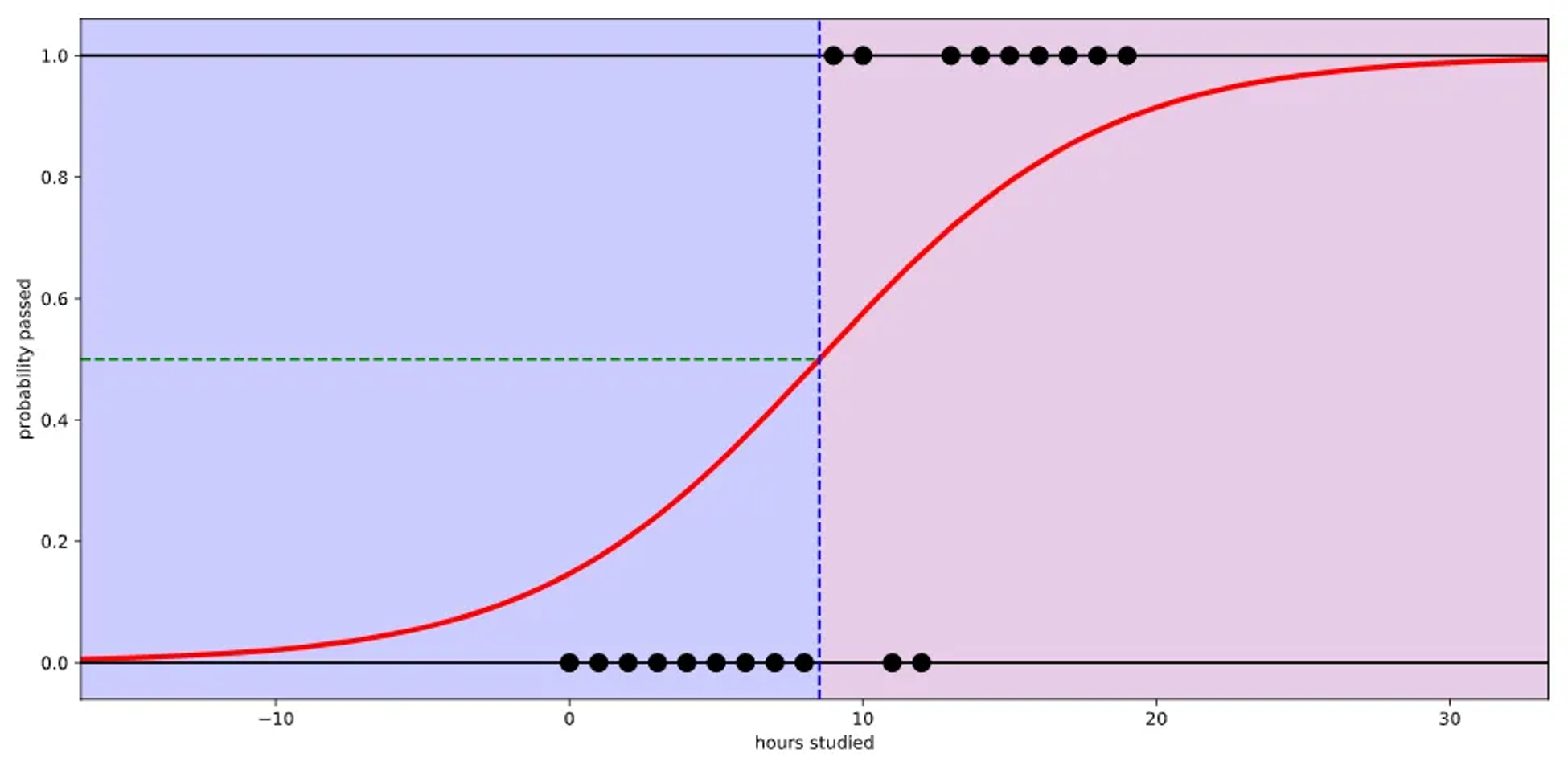
출처:https://ursobad.tistory.com/44
실제 많은 자연, 사회현상에서 특정 변수에 대한 확률값이 선형이 아닌 S-커브 형태를 따르는 경우가 많다. 이러한 S-커브를 함수로 표현해낸 것이 로지스틱 함수(Logistic function)이고 딥러닝에서는 시그모이드 함수(sigmoid function)이라고 불린다.
가설과 손실함수
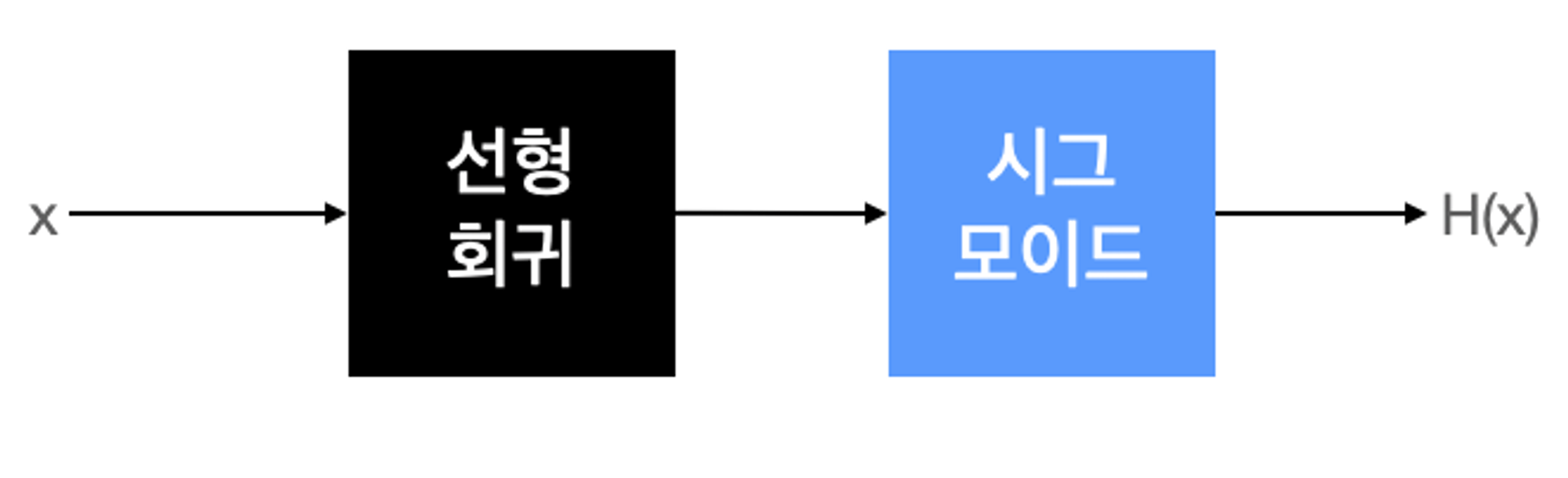
논리 회귀의 실질적 계산은 선형 회귀와 동일하지만, 출력에 시그모이드 함수를 붙여 0에서 1사이의 값을 가지도록 조정하는 것이다.
선형 회귀에서 가설은 , 시그모이드는 논리 회귀에서는 시그모이드 함수에 선형 회귀 식을 넣어 주면 됩니다.
손실함수
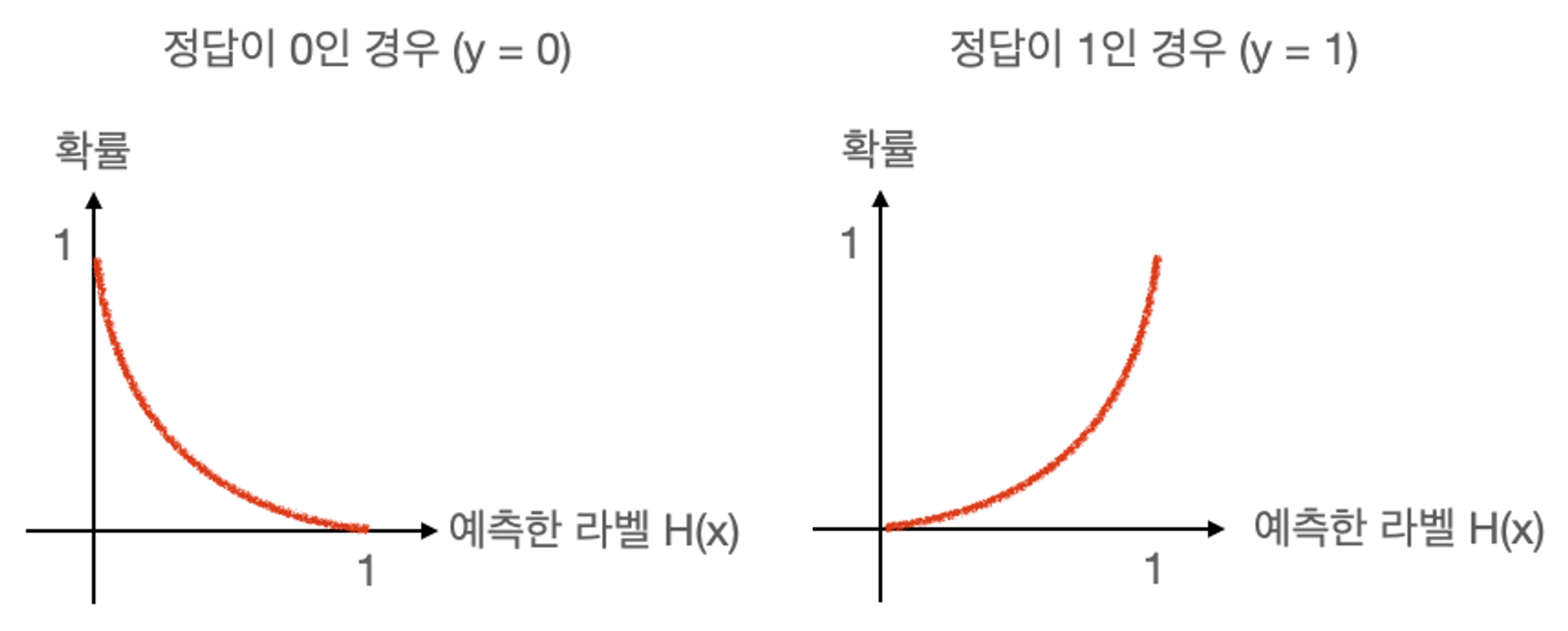
손실함수는 값 예측에 따른 정답 확률을 도출 하는 함수 이다.
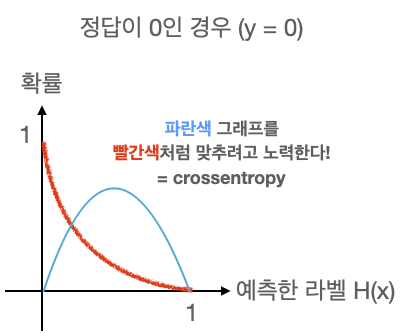
즉, 임의의 입력값에 대해 원하는 확률 분포 그래프를 만들도록 학습시키는 것이다.
🎈Keras에서 이진 논리 회귀의 경우 binary_crossentropy 솔실 함수를 사용
다항 논리 회귀 (Multinomial logistic regression)
- 다항의 선택지 중, 1개를 선택하는 다중 분류 문제를 학습 합니다. - 소프트맥스 회귀(Softmax Regression)이라고도 함.
예시) 대학교 시험 전 날 공부한 시간을 가지고 해당 과목의 성적(A, B, C, D, F)을 예측 하는 문제
다항의 선택지에 해당하는 클래스(A, B, C, D, E)(0, 1, 2, 3, 4, 5)를 나누고 원핫 인코딩 방법을 사용하여 문제를 다시 분류 한다.
| 성적 | 클래스 | Ont-hot encoded |
|---|---|---|
| A | 0 | [1, 0, 0, 0, 0] |
| B | 1 | [0, 1, 0, 0, 0] |
| C | 2 | [0, 0, 1, 0, 0] |
| D | 3 | [0, 0, 0, 1, 0] |
| E | 4 | [0, 0, 0, 0, 1] |
Softmax 함수와 손실함수
Softmax는 선형 모델에서 나온 결과(Logit)의 합이 1이 되도록 만들어주는 함수이다.
모든 합이 1이 되도록 만드는 이유는 예측의 결과를 확률(Confidence)로 표현하려는 것이고 One-hot encoding을 할 때에도 라벨의 값을 전부 더하면 1(100%)가 된다.
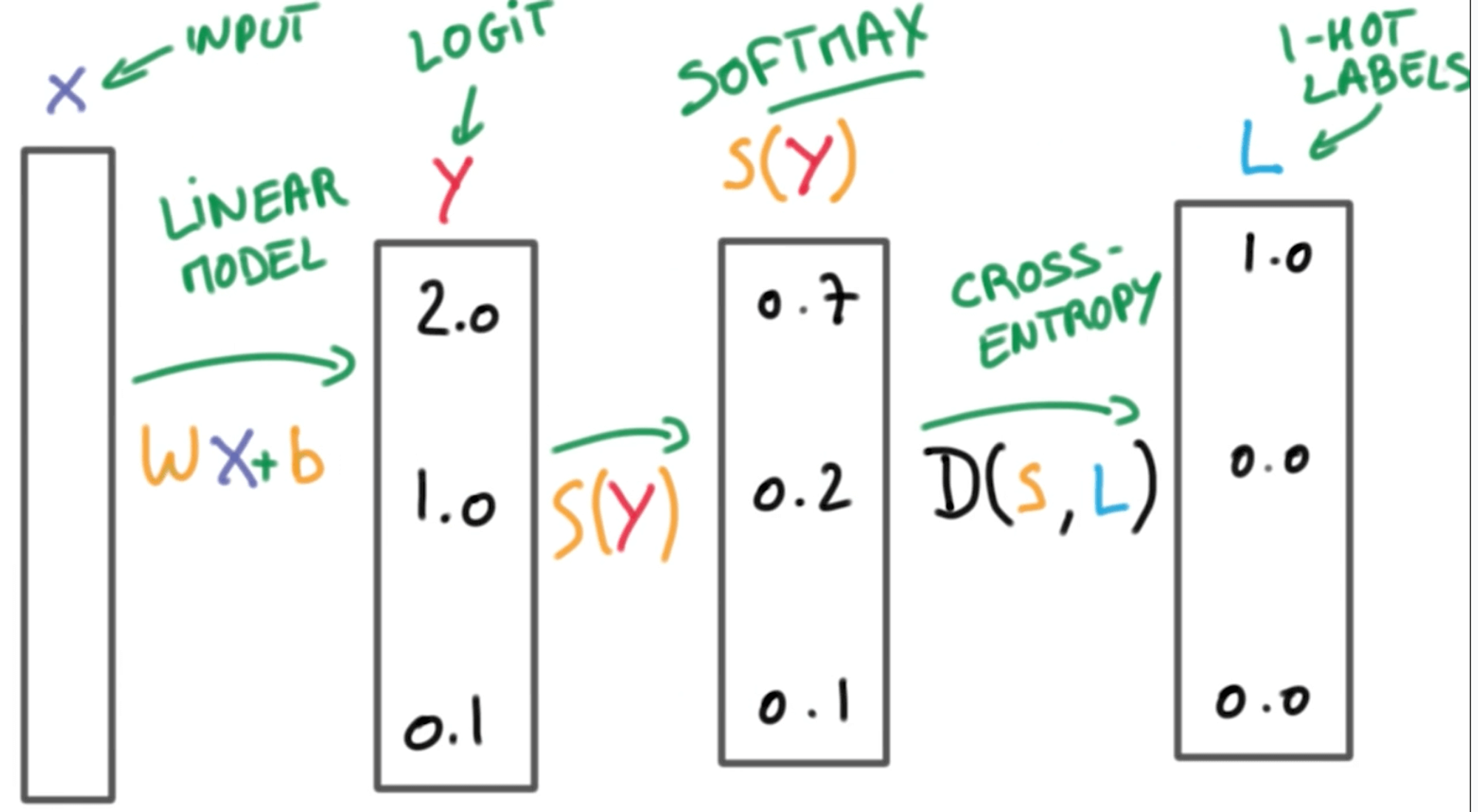
[출처:https://www.programmersought.com/article/62574848686/)
다항 논리 회귀에서 Softmax 함수를 통과한 결과 값의 확률 분포 그래프를 그려서 아래 그래프의 모양을 가정 해보자. 단항 논리 회귀에서와 마찬가지로 가로축은 클래스(라벨)이 되고 세로 축은 확률이 된다.
마찬가지로 확률 분포의 차이를 계산할 때는 Crossentropy 함수를 쓴다. 항이 여러개가 되었을 뿐 차이는 이진 논리 회귀와 차이가 없다. 데이터셋의 정답 라벨과 우리가 예측한 라벨의 확률 분포 그래프를 구해서 Crossentropy(크로스 엔트로피)로 두 확률 분포의 차이를 구한 다음 그 차이를 최소화하는 방향으로 학습 시클 것이다.
🎈Keras에서 다항 논리 회귀의 경우 categorical_crossentropy 솔실 함수를 사용
전처리(Preprocessing)
전처리란 기계가 학습 할 수 있도록 학습 전 데이터의 형태, 기준 등을 맞추어 바꾸는 모든 과정 이다. 불필요 데이터를 제거, 서로 다른 기준 값을 동일하게 하거나 파라미터 갯수를 맞추는 일련의 모든 과정이다.
정규화
데이터를 0과 1사이의 범위로 변환 하는 것
| 예시 | 100점 만점 시험 | 500점 만점 시험 |
|---|---|---|
| 실제 점수 | 50 | 50 |
| 정규화 점수 | 0.5 | 0.1 |
표준화
데이터의 분포를 정규분포로 바꾸는 것. 데이터의 평균은 0이고 표준편차는 1로 만든다.
데이터의 평균을 0으로 만들어주면 데이터의 중심이 0에 맞춰지게 된다. (Zero-centered) 그리고 표준편차를 1로 만들면 보기 쉽게 정규화(Normalized)되어 일반적으로 학습 속도(최저점 수렴 속도)가 빠르고, Local minimum에 빠질 가능성도 적다.
- 전처리까지 학습 해보았으니.... 실습하여 데이터 처리 방법 확인하기
이진 논리회귀 실습
타이타닉 승객 정보를 이용하여 이진 논리회귀를 실습
https://colab.research.google.com/drive/1AEsfo9q7pDxNPYz8oIlcAtEQ-9QZhnO2다항 논리회귀 실습
와인 종류 예측하기
https://colab.research.google.com/drive/1iO4JwhyL-3dW5nmaSaQLrep3DupcMd3i