Instruction
Using More Registers
- $t0~$t9: Procedure 안밖에서 변경되어도 상관없는 변수
- $s0~$s7: Procedure 안밖에서 변경되지 않도록 stack에 저장해야하는 변수
- 그래서 Procedure call이 일어나면 먼저
addi \$sp, \$sp, -4lw \$s0 0(\$sp)이게 필요
Example
int leaf_example(int g, int h, int i, int j)
{
int f;
f = (g + h) - (i + j);
return f;
}- Register Allocation -> g~j $a0~$a4, f $s0, result \v0
- Code
add $t0, $a0, $a1 # (g + h)
add $t1, $a2, $a2 # (i + j)
sub $s0, $t0, $t1 # f = (g + h) - (i + j)
move $v0, $s0 # f를 return하기위해 $v0에 저장
jr $ra # $v0을 return 후 PC + 4로 jump- Manage Stack
addi $sp, $sp, -4
sw $s0, 0($sp)
~~~
~~~
lw $s0, 0($sp)
addi $sp, $sp 4- Join!
leaf_example:
addi $sp, $sp, -4
sw $s0, 0($sp)
add $t0, $a0, $a1 # (g + h)
add $t1, $a2, $a2 # (i + j)
sub $s0, $t0, $t1 # f = (g + h) - (i + j)
move $v0, $s0 # f를 return하기위해 $v0에 저장
lw $s0, 0($sp)
addi $sp, $sp 4
jr $ra # $v0을 return 후 PC + 4로 jumpNested Procedure
함수안에서 함수를 또 호출하게 되면 $ra가 꼬일 수 있어서 이 또한 $sp에 저장해야함
 만약 Stack에 저장하지 않았다면, F1의 중간부분 jal F2에서 PC + 4인 lw $a0, 0($sp)이 $ra에 저장됨.
만약 Stack에 저장하지 않았다면, F1의 중간부분 jal F2에서 PC + 4인 lw $a0, 0($sp)이 $ra에 저장됨.
F1의 제일 마지막줄 jr $ra에서 F1을 빠져나가지 못하고 갇히게 됨.
Stack, Heap
- Stack은 아래로 커짐
- $sp로 Stack을 접근가능
- Frame pointer ($fp)로 메모리 프레임의 제일 첫번째 word로 접근가능
- stable base register하므로, 메모리의 offset이 너무 커지면 초반 데이터는 $fp를 통해 접근할수도..
- Heap은 위로 커짐
- C언어에서 malloc(), free()로 C++에서 new, delete를 통해 작동
- Garbage Collector이 없는 언어에서 메모리 누수를 막기위해 프로그래머가 코드를 잘 짜야함
Register num
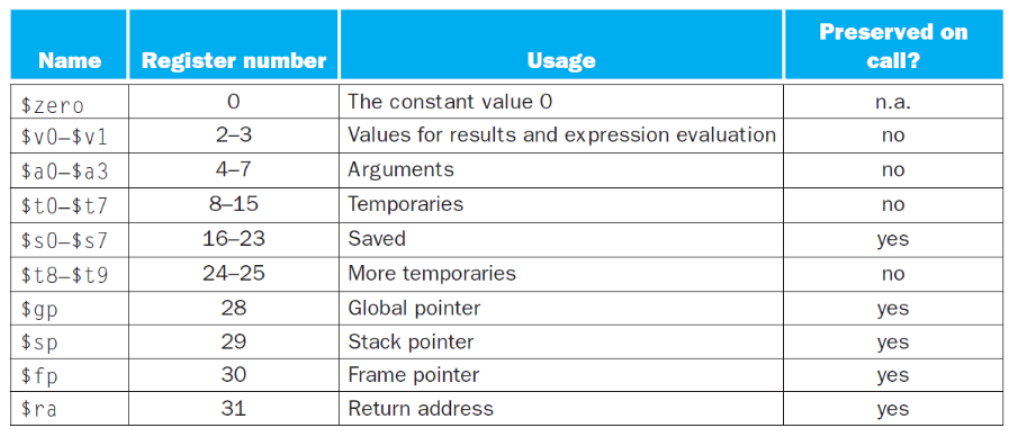 $k0~$k1(26~27)은 커널에 의해 관리되어서 해당표에서 제외
$k0~$k1(26~27)은 커널에 의해 관리되어서 해당표에서 제외
Subword Data
Character Data
- 문자열은 ASCII코드로 128가지 = 8bit = 1byte를 다루므로 lb(load byte), sb(store byte) 를 사용
- "Cal"은 C언어로 [67, 97, 108, 0]으로 표현이됨 (마지막은 항상 null = \0)
Halfword Data
- 1 word가 32bit라면 0.5 word는 16bit
- 이를 위해 lh(load half), sh(store half)가 존재
- halfword와 fullword는 signed, unsigned가 존재 / byte는 없음
MIPS addressing
Immediate addressing - Immediate를 16비트보다 더 크게
- 기존의 immediate를 사용하는 I Format은 immediate가 16비트가 한계
- load uper immediate(lui)를 통해 31~16번 비트까지 저장
- or immediate(ori)를 통해 15~0번 비트까지 더해서 immediate를 더 크게 확장

Register addresing - Branch, Jump
- J Format은 6 / 26 bit라서 jump를 최대 ±2^25의 범위까지 가능
- I Format인 bne는 immediate로 이동하기에 최대 ±2^15의 범위까지 가능
PC-relative addressing
- PC는 현재 실행중인 instruction의 주소를 가리킴
- jal을 통해 다른 procedure를 호출할 때, $ra에 PC + 4를 저장함으로써, 다음 명령을 점프위치로 저장!
- Exit는 3 word 떨어져있지만, PC + 4 기준으로 2 word 떨어져있으므로 2로 표현

Pseudodirect addresing
- J Format에서 address는 26bit임
- Alignment restriction(1word = 4byte)을 활용해 LSB에 00추가
- 다음에 jump할 주소는 PC의 근처일 가능성이 높음(locality)
- 그래서 PC의 맨 MSB 4비트를 가져옴

Synchronization Issue
- load linked(ll): lw와 똑같지만, 그 위치를 감지
- store conditional(sc): sw와 똑같지만, 다른 CPU에 의해 바뀌는지 검사
- 멀티프로세싱, 멀티스레딩 프로그램에서 공유자원을 보호하기위해 사용
프로그램 해석과정
- 컴파일러: C lang(.c) -> MIPS
- 어셈블러: MIPS -> Machine language(.obj)
- 링커: 여러 dll, 정적 linked를 모아 실행파일로 생성
- 로더: 실행파일을 실행하면 메모리에 올려줌
Swap Example
void swap(int v[], int k)
{
int temp;
temp = v[k];
v[k] = v[k+1];
v[k+1] = temp
}- Register allocation: v $a0, k $a1, temp $t0
- code
sll $t1, $a1, 2
add $t1, $t1, $a0 # $t1에 v[k]의 주소 할당
lw $t0, 0($t1) # temp에 v[k] load
lw $t2, 4($t1)
sw $t2, 0($t1) # v[k]에 v[k+1] load -> memory to memory는 lw, sw 세트
sw $t0, 4($t1) # v[k+1]에 temp store
jr $ra # void를 return하므로 $v0을 다루지는 않음- Stack -> 하지만 saved register을 사용하지 않고, 안에서 procedure를 또 부르지 않으므로 없음
Sort Example
void sort (int v[], int n)
{
int i, j;
for (i = 0; i < n; i += 1) {
for (j = i - 1; j >= 0 && v[j] > v[j + 1]; j-=1) {
swap(v, j);
}
}
}- Register alloction: v $a0, n $a1, i $s0, j $s1
- code
먼저 첫번째 for문for (i = 0; i < n; i+=1)에서i=0->move $s0, $zero이므로
move $s0, $zero
for1: slt $t0, $s0, $a1
beq $t0, $zero, exit1
~~~(body of 1th loop)~~~
addi $s0, $s0, 1
j for1
eixt1:그다음 두번째 for문
addi $s1, $s0, -1
for2: slt $t0, $zero, $s1
beq $t0, $zero, exit2
sll $t1, $s1, 2
addi $t2, $t1, $a0
lw $t3, 0($t2)
lw $t4, 4($t2)
slt $t0, $t4, $t3
beq $t0, $zero, exit2
~~~(body of 2nd loop)~~~
addi $s1, $s1, -1
j for2
exit2:swap(v, j);는
move $a0, $s2 # $s2에 v의 시작주소이므로 첫번째 파라미터 $a0로 이동
move $a1, $s2 # $s2가 j이므로 두번째 파라미터 $a1로 이동
jal swap # swap(v,j) 호출- Preserve register
$s0 ~ $s3, $ra들이 사용되었으므로 스택에 저장
sort: addi $sp, $sp, -20
sw $ra, 16($sp)
sw $s3, 12($sp)
sw $s2, 8($sp)
sw $s1, 4($sp)
sw $s0, 0($sp)
~~~(body of procedure)
lw $s0, 0($sp)
lw $s1, 4($sp)
lw $s2, 8($sp)
lw $s3, 12($sp)
lw $ra, 16($sp)
addi $sp, $sp, 20- Join!
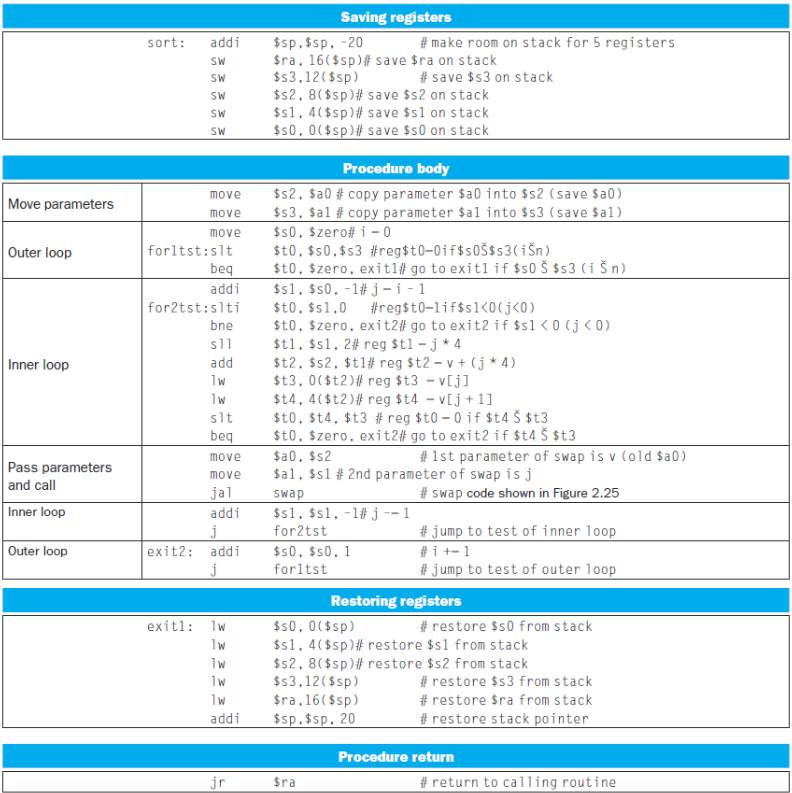
Array vs Pointer
Array
clear1(int array[], int size)
{
int i;
for ( i = 0; i < size; i += 1 )
array[i] = 0;
}를 MIPS로 변환하면 (i $t0, array $a0, size $a1)
move $t0, $zero
for: sll $t1, $t0, 2
add $t1, $t1, $a0
sw $zero, 0($t1)
addi $t0, $t0, 1
slt $t2, $t0, $a1
bne $t2, $zero forPointer
clear2(int *array, int size)
{
int *p;
for ( p = &array[0]; p < &array[size]; p = p + 1 )
*p = 0;
}를 MIPS로 변환하면 (*p $t0, array $a0, size $a1)
move $t0, $a0 # &array[0]은 array의 시작주소이므로 $a0와 같은 의미
sll $t1, $t0, $a1
add $t1, $t1, $a0
for: sw $zero, 0($t0)
addi $t0, $t0, 4
slt $t2, $t0, $t1
bne $t2, $zero, for두 개의 차이?
- Pointer가 Array보다 for:에 감싸진 부분이 작아서, 수행되는 instruction 개수가 작음
- 눈에 보이는 instuction수는 똑같아보여도, 반복되는 부분이 작음
