Virtual Memory
Demand Paging
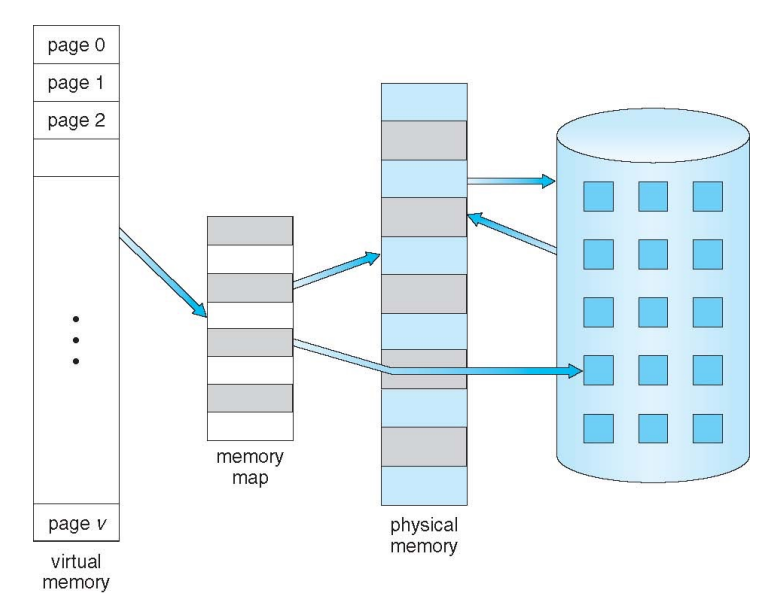
Virtual Memory
-
메모리 크기보다 실행할 프로세스의 크기가 더 큰 상황에서, 디스크를 메모리처럼 쓰는 방법
-
Page Replacement를 통해 디스크에 있는 페이지를 교체
-
기존의 Paging
처음부터 process의 모든 page를 메모리에 전부 valid상태로 올리고, page table또한 valid bit를 v로 설정 -
Demand Paging
처음에 모든 valid bit를 i로 초기화하고 실제 실행하려는 영역만 v로 갱신만약 분기가 있는 프로그램에서 한 번도 실행안 되는 부분이 존재
기존의 paging: 이 분기도 메모리에 올라가 공간을 차지
Demand paging: 이 분기는 메모리에 올라가지 않음
Locality
디스크에 있는 프로그램 전체를 다 메모리에 올리는 것이 아닌, locality의 특성을 이용해서 지금 코드 중 필요한 부분만 올려 실행이 가능하게 함
Valid-Invalid bit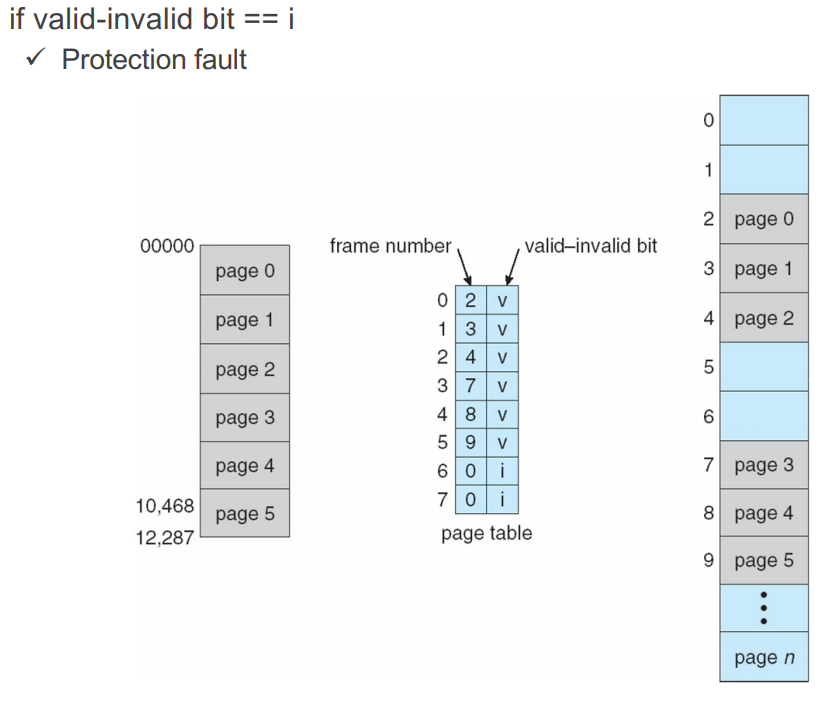
- 기존의 Paing
- valid bit == i
Protection fault(메모리에 존재하지 않아 잘못된 주소 접근으로 trap)

- valid bit == i
- Demand paging
- valid bit == i
Protection fault, Page fault(메모리에는 없으나 디스크에 존재)
- valid bit == i
Page Fault
특성
- Page Fault는 요청한 주소가 메모리에 올라와있지 않을 때 발생
- swap-in을 위해 디스크에 접근하는 I/O를 유발하므로 오버헤드가 일어날 수 있음
과정
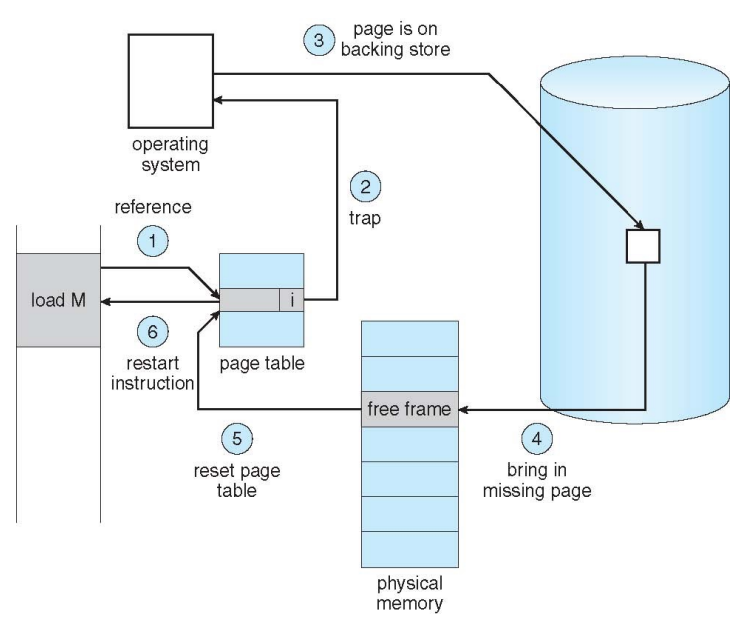
load M(M 주소에 해당하는 page를 memory로 올리는 instruction)
- 주소 요청 후 page table 탐색
- invalid 비트를 만나 protection fault인지 page fault인지 구분해야 하므로 trap을 걸어 OS에 알림
- OS가 page fault라고 판단하고 disk에 접근
- disk에 1번과정에 요청했던 페이지를 physical memory에서 필요없는 page와 교체
- 기존의 invalid page를 메모리로 올렸으므로 i→v page table을 갱신
- instruction을 재시작
instruction은 atomic해서 중간부터 다시 시작할 수 없으므로모든 과정을 하고 난 후 재시작을 해야함
주소 접근──TLB hit(99.9%)──메모리로 바로 접근
└─TLB miss(0.1%)──Page Table참조──v? 메모리로 접근
└i?──Protection Fault(거의 대부분)
└─Page Fault(극히 일부)Copy-on-Write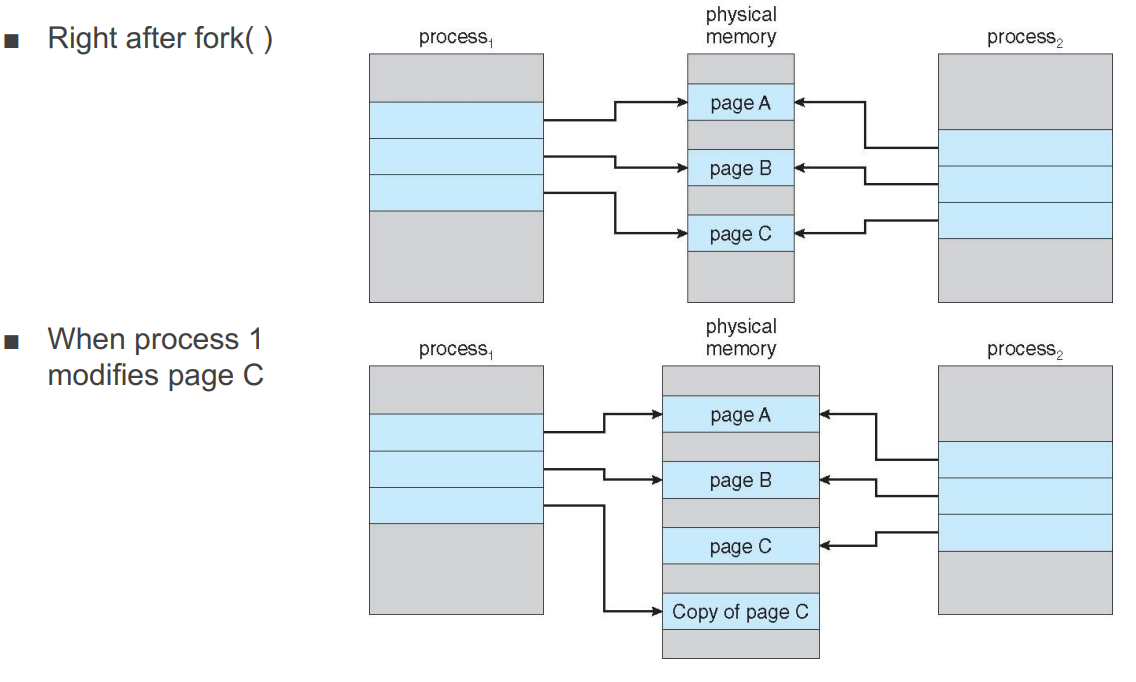
- fork를 하면 서로 주소를 공유해서 같은 physical memory를 가리킴
- 프로세스에서 변경이 일어나면 그 변경이 일어난 page에 대해서만 복사본을 만들어 확장
- 최대한 메모리를 적게 쓰기위해 page를 공유하는 방식으로 운용
Page Replacement Algorithm
-
Page Replacement 과정에서 어떤 프로세스를 Swap-out할지 정하는 알고리즘
-
Page Fault는 오버헤드를 발생시키므로 Page Fault가 가장 덜 일어나는 알고리즘이 중요
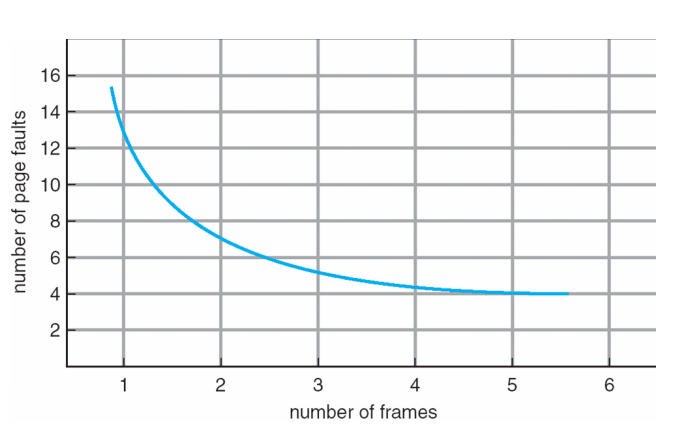
Frame 수가 적을 수록 Page fault가 자주 일어남(메모리크기가 작으므로)하지만 무한대로 크다고 계속 감소하는 것은 아니다!
5~6개 이상부터는 일정수준 유지(locality때문)
FIFO Algorithm
-
메모리에 오래 머물렀던 친구를 빼자
-
오히려 frame이 많은데 page fault가 더 일어나는 현상 > Belady's anomaly
Least Recently Used (LRU) Algorithm
-
최근에 가장 사용되지 않은 것을 빼자
-
시간정보를 추가적으로 다뤄야함
- 4~8비트정도 추가공간 소모
- 시간정보를 계속 증가 연산시키는 오버헤드
-
Stack을 통해 시간정보를 다루자
- Stack조차도 공간을 차지
- Pop, Push 연산 또한 오버헤드
-
Approximation 근사치 개념으로 1비트만 추가해서 보완 < 이방법 사용
Least Recently Used (LRU) - Approximation Algorithm
-
기존 LRU와는 다르게 Reference 1비트 만을 추가
- 최근에 실행됐으면 1, 정해진 시간이 지났으면 0 설정
- Reference 비트가 0인 페이지를 victim으로 선정
-
하지만 같은 0끼리는 누가 오랫동안 실행되지 않았는지 모름
-
Second Change(LRU Clock) Algorithm
- 모든 페이지들은 원형큐(Circular Queue)로 연결되어 있음
- 1이면 0으로 바꿔주고 다음 페이지로 넘어감
- 0이면 그 페이지를 victim으로 선정
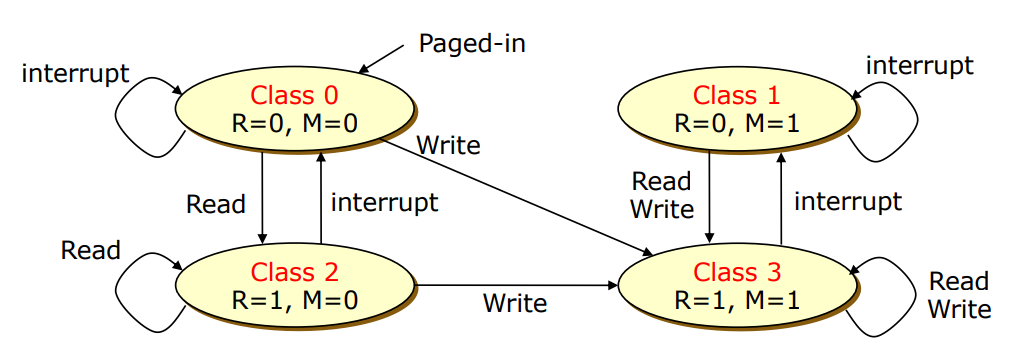
Not Recently Used (NRU) Algorithm
-
기존의 LRU Reference 1비트에서 Modify 비트 1비트를 추가
- Modify는 최근에 수정되었으면 0에서 1로 바뀌고 이후로는 변경 없음
-
메모리 사용은 Read만 있는게 아닌 Write도 있으므로 Modify 비트 도입
-
R=0, M=0 / R=0, M=1 / R=1, M=0 / R=1, M=1 순으로 class를 정하고 victim선정
-
이해하기 쉽고 효율적이라 최적화된 알고리즘
Least Frequently Used (LFU) Algorithm
- 가장 사용한 횟수가 작은 녀석을 빼자
- count를 저장하고 계속 이를 증가시키는 연산도 필요하므로 오버헤드 발생
Aging
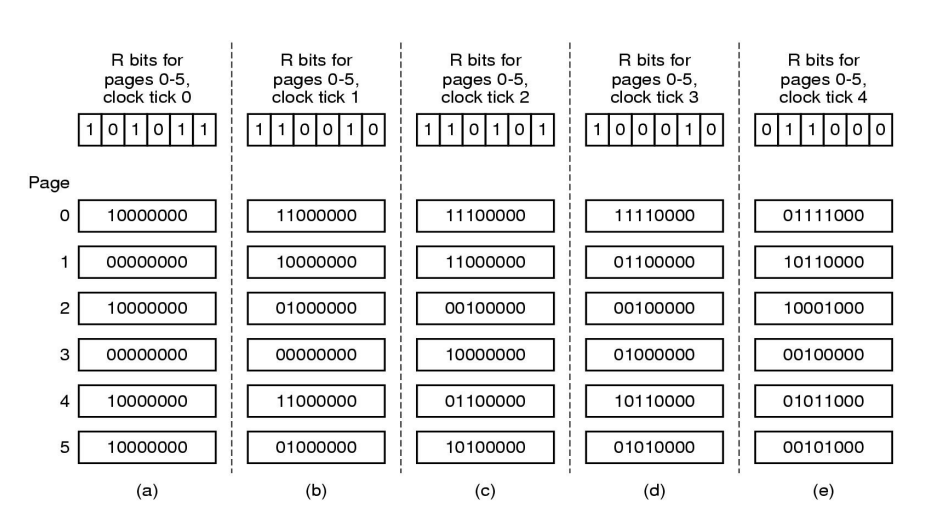
- 페이지 수만큼 세로축, 시간을 가로축
- 최근에 사용됐으면 1, 사용하지 않았으면 0
- shift 연산으로 1의 개수가 가장 적은 페이지를 victim으로 선정
Allocation of Frames
Allocation algorithms
-
Equal allocation: 프로세스마다 프레임수를 골고루 분배
-
Proportional allocation: 프로세스 크기가 크면 프레임을 많이 분배
실제로는 이 방법을 베이스로 priority를 조금 고려한 방법을 사용 -
Priority-based allocation: 덩치가 작더라도 우선순위가 큰 프로세스에게 많이 분배
Page replacement
만약 메모리가 꽉차서 replacement가 필요한 상황일 때
- Global replacement: 현 프로세스 외에도 모든 프로세스의 페이지들에서 replacement
- Local replacement: 현 프로세스 내부의 페이지에 대해서만 replacement
Page-Fault Frequency Scheme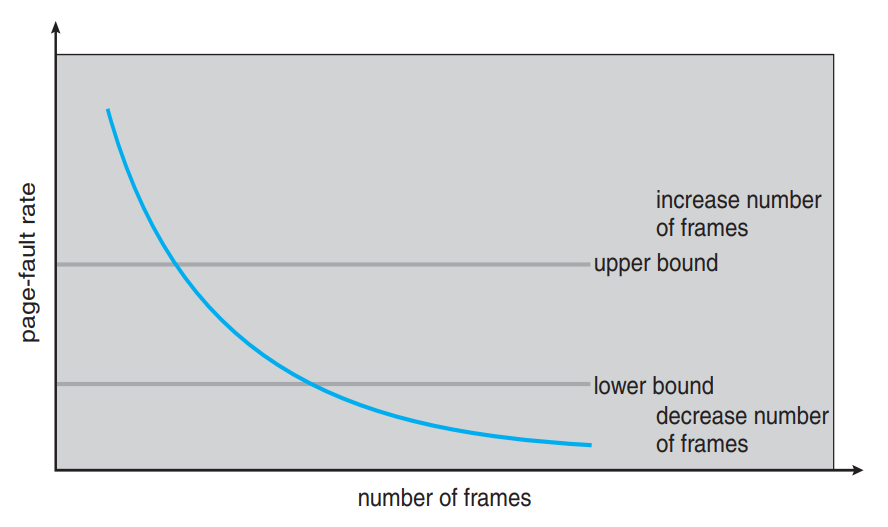
- page fault가 일어나는 횟수의 상한과 하한을 정해서 동적으로 관리
- page fault가 상한보다 자주 일어나면 frame을 더 할당
- page fault가 하한보다 적게 일어나면 frame을 압수
Thrashing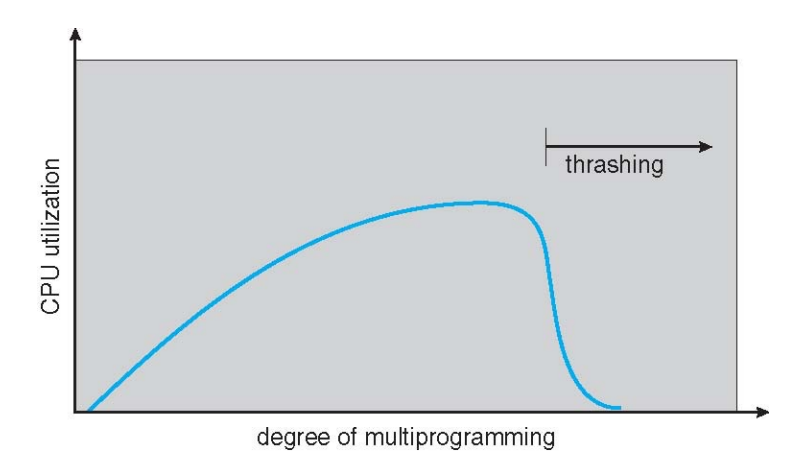
- Multiprocess를 많이 할 수록 CPU 사용률이 점점 올라가지만, 일정 수준이상에서는 감소하는 현상
- 메모리 공간은 제한적이므로 process를 multiple하게 많이 쓰게되면?
→공간이 부족해지고 이에 따라 Page Replacement도 자주 일어남
→오버헤드가 발생하므로 CPU 사용률이 현저히 떨어지게 됨 - 메모리 크기보다 지금 실행해야할 locality의 크기 합이 크면 발생
Working-Set Model
- 단위 시간당 필요한 프레임의 개수를 나타내는 성능측정 모델
- 정해진 델타 시간안에 몇 가지의 페이지가 들어오는지를 측정
- 메모리 크기 < 단위 시간안에 사용하는 페이지 크기 = Thrashing 발생
Other Considerations
Prepaging
매번 필요할때 조금씩 demand paging하는게 아니라, 필요하다고 여겨지는 페이지까지 예측해서 한 번에 i를 v로 바꾸고 memory에 적재하는 paging방식
ex) 하드디스크 파일 로딩
Page size selection
아래를 고려해서 적절한 페이지 크기를 정하자
- Fragmentation: 페이지가 크면 Internal Fragmentation도 커짐
- Page table size: 페이지가 크면 entry개수는 작아지므로 table은 작아짐
- I/O overhead: 페이지가 크면 디스크에서 swap-in한번할때 크기도 크므로 한번에 올릴 수 있어서 오버헤드가 작음
- Locality: 페이지가 크면 한 덩어리안에 실행할 코드가 거의 다 있어서 Locality가 좋음
TLB Reach
- TLB를 가지고 Physical memory에 접근 가능한 공간 크기
- TLB Reach = TLB Entry 수 × Page Size
- 이게 적당히 클 수록 좋음 > TLB에서 모든 Physical memory에 접근할 수 있으면 TLB miss ratio가 줄어듦
- 무작정 많다고 좋은 것은 아니라 적당한 크기로 설정
2차원 배열 탐색시
i, j순으로 탐색하라
j, i순으로 하면 1024 * 1024 회의 page fault발생 / i, j순은 1024회
I/O Interlock
I/O 요청을 한 페이지가 메모리에 올라가 대기중인데 Victim으로 선정되지 않도록 lock을 걸어주는 기능
