Memory Management
Main Memory
-
주기억 장치로 RAM(Random Access Memory)라고 부르기도 함
-
OS가 관리하는 자원 중에서 가장 abstraction이 잘 되어있음
Logical Memory
CPU나 개발자들이 개념적으로 이해하는 메모리
Physical Memory
실제 메모리 안에 Logical Memory가 배치되는데 메모리의 실체를 의미
Batch Programming
- 한 프로세스만 계속 실행하는 것이 특징
- Logical Memory의 개념보다는 Physical Memory를 직접 바로 사용
- OS는 Physical Memory를 직접적으로 load, execute, unload
Multiprogramming
-
여러 프로세스가 메모리 공간을 공유하게 됨
-
다수의 프로세스가 실행됨로 서로의 메모리 공간을 isolation해줌
-
Protection
메모리 공간을 isolation함으로써 프로세스간 영역을 침범하지 않도록 보호 -
Fast translation
논리적 주소를 통해 메모리에 접근하는 속도를 빠르게 성능을 올림 -
Fast context swtiching
context swtiching이 빨라야 메모리를 보다 좋게 사용가능
Issue
- 메모리를 구분할 때 최대한 낭비되는 빈 공간(hole)이 없도록 알뜰하게 써야함
- 메모리를 접근하는데 빨라야함(fast translation)
- context swtiching이 빨라야함(fast context swtiching)
Solution: Virtual Memory(VM)
HDD, SSD같은 secondary memory를 main memory처럼 사용하는 방법
- main memory는 비싸고 크기가 한정적
- Memory Replacement
- 사용한지 오래된 코드나 데이터들을 secondary memory로 swap out
- 당장 써야하고 중요한 급한 데이터들은 main memory로 swap-in
Binding of Memory Address
Binding of Instructions and Data to Memory
- secondary memory(disk)에 있던 프로그램을 main memory로 load해서 실행하는 것이 폰누이만 architecture의 일반적인 예
- 그 과정에서 프로세스는 memory의 공간을 차지하게 되는데
- 이 프로세스의 개념적 메모리 공간을 logical memory
- 이 logical memory를 어느 시간대에 physical memory로 올릴지가 관건
- Compile time / Load time / Execution time 세가지의 종류
Compile time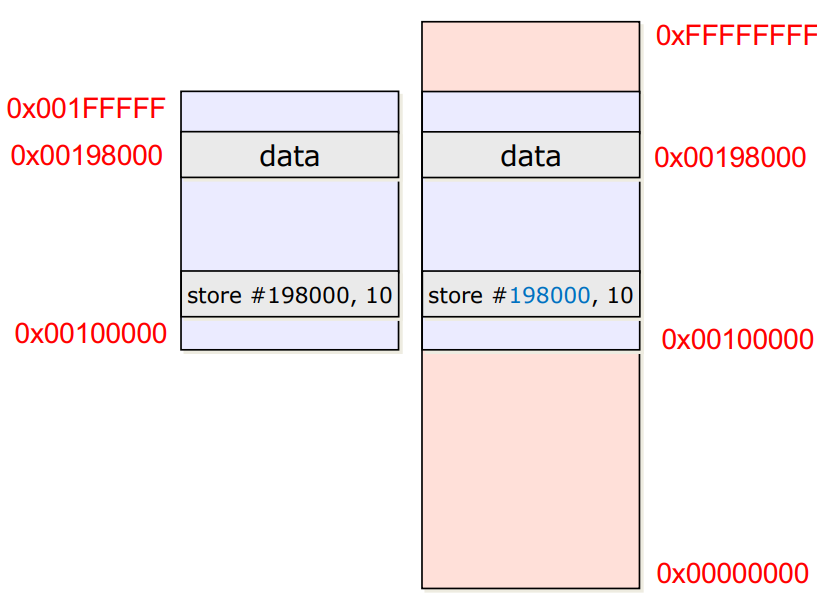
- 소스코드를 컴파일 중일 때 Logical Memory의 주소를 모두 정함
- Logical Memory안의 메모리 주소들은 모두 고정적이어서 수정 불가
- Embedded System에서 사용
→ 이미 메모리의 용량같은 사양들이 구동할 프로세스에 맞춰 설계되어 있어서 컴파일 중일때 memory binding을 하는게 훨씬 효율적
Load time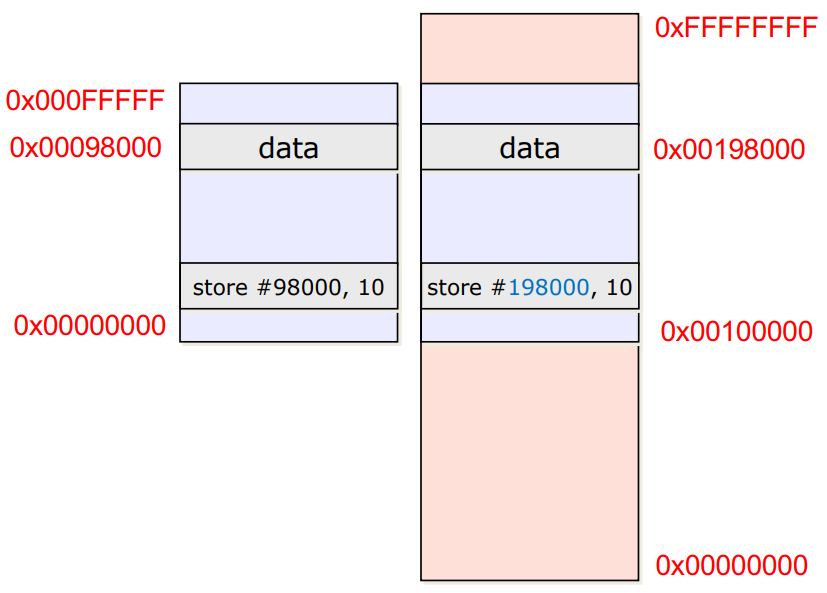
- 소스코드를 컴파일 하고 Main memory로 load하는 중에 주소를 모두 정함
- 프로세스의 Logical memory를 만들어 놓고, load하는 시간동안 offset을 모든 주소에 계속 더해줘서 Physical Memory의 빈공간을 찾아 위치시킴
→ Load time에 offset을 찾도록 계속 빈 공간을 검사해야하므로 자연스레 Load time이 길어짐
Execution time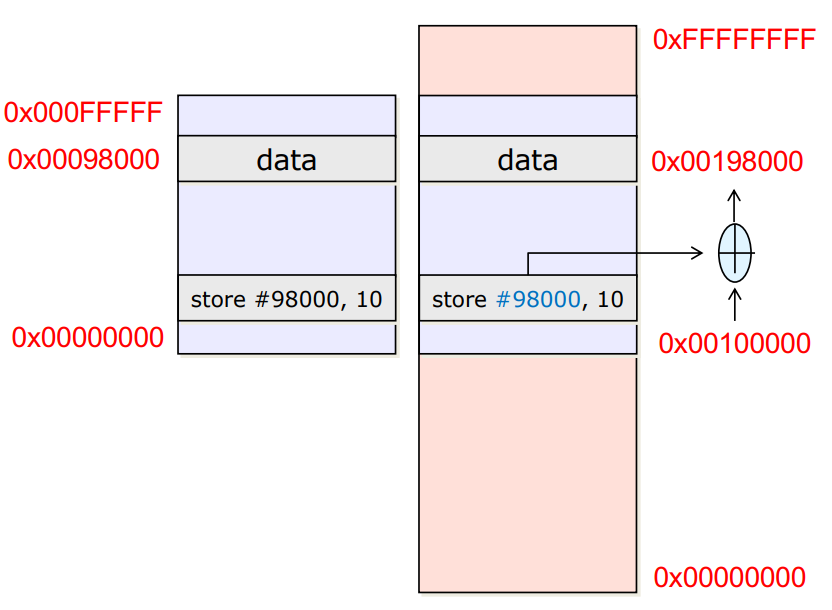
- 컴파일 하고 Main memory로 load후 CPU로 실행하는 중에 주소를 모두 정함
- Load time과 동작이 똑같고 딱 한가지가 다름
→Load time은 모든 주소에 offset만큼 더해주는 과정을 직접 하지만
→Execution time은 MMU가 offset만큼 더해서 접근 - Execution time이 길어지나, MMU를 통해 빠르게 offset을 찾아 접근해서 해결
Address mapping
- 기존의 Execution Time처럼 실행시간에 동작
- Virtual Memory
Physical memory의 공간이 부족하다면 Secondary Storage로 잘 안쓰던 데이터들과 당장 필요한 데이터들을 swap하는 형식으로 교체
Memory management
Memory-Management Unit (MMU)
-
CPU안에 있는 메모리 접근 및 관리를 도와주는 역할
-
embedded system은 MMU가 없음
→Compile time에 주소를 한 번에 지정하기 때문에 매번 실행시킬 때마다 주소의 위치가 고정적이라 offset 조정이 필요없기 때문 -
Execution time 메모리 접근은 Execution이 길지만 MMU를 통한 빠른접근으로 단점 해결
Contiguous Allocation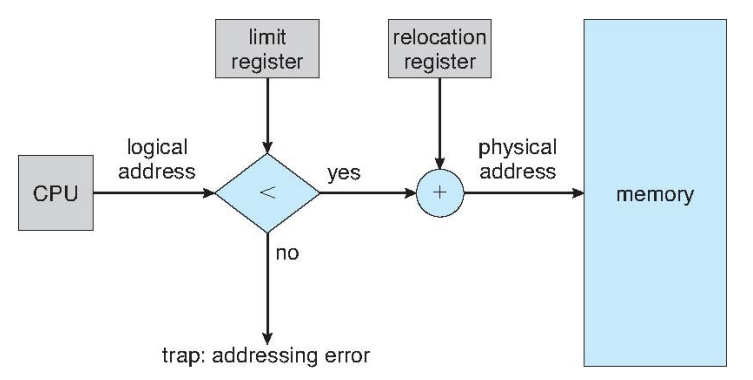
Physical Memory로 프로세스를 올릴 때 덩어리 그 자체를 일련적으로 (Contiguous) offset을 더하면서 접근하는 방식
- Physical address = logical address + relocation register
- Limit register<logical address: 프로세스가 메모리 보다 더 크기 때문에 trap
- Hole 발생: 메모리 사이에 비어있는 공간이 생기게 된다
Dynamic Storage-Allocation Problem
-
First-fit: 위에서 부터 탐색하다가 처음 만난 빈 공간에 배치
-
Best-fit: 전체 hole 중에서 넣어야할 프로세스와 딱 크기가 맞는 곳에 배치
-
Worst-fit: 제일 큰 hole에다가 넣기
-
First-fit과 Best-fit이 Worst-fit보다 효율이 좋음
Fragmentation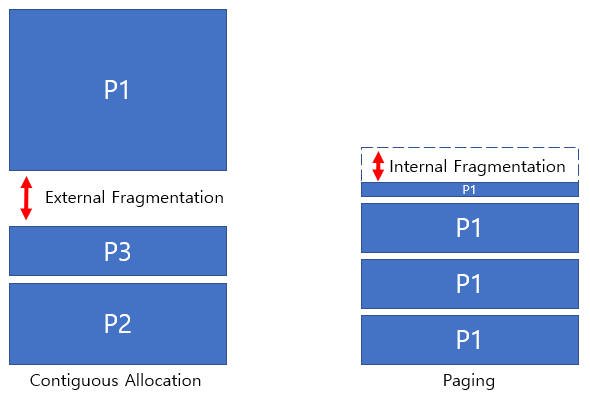
External Fragmentation
- 프로세스 외부에서 hole이 발생
- Contiguous allocation에서 일어나는 상황
Internal Fragmentation
- 프로세스 내부에서 hole이 발생
- Paging 기법에서 일어나는 상황 그 자체를 뜻
Compaction
- 디스크 조각모음을 하듯이 프로세스들의 주소를 미는 방식
- 작은 여러 hole들을 줄이고 하나의 hole을 더 크게 만듦
- 하지만 오버헤드가 너무 커서 Contiguous allocation을 안 씀
Paging
Paging
- Page: 프로세스를 일정한 크기로 나눈 단위
- Frame
- Page와 크기가 똑같은 Physical memory의 공간
- Page가 CD라면 Frame은 CD 슬롯 혹은 CD리더기라고 보면됨
- Page mapping table(Page Table)
몇 번째 Page가 몇 번째 Frame에 들어가있는지를 기억하는 표
Address Translation
- Logical Address: (페이지번호, 오프셋) = (p, d)로 저장
- Physical Adderss: (프레임번호, 오프셋) = (f, d)로 저장
- 단점: External Fragmentation은 없지만, Internal Fragmentation은 있음
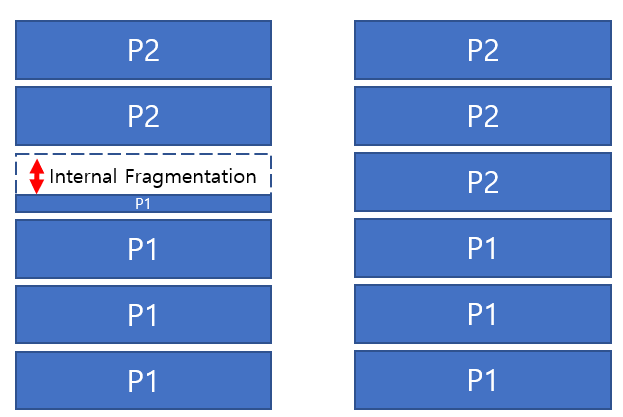
왼쪽 상황- 프로세스가 3.1개의 Page로 분할된다면 4개의 프레임을 사용
- 하나의 프레임은 0.9개의 페이지 크기 만큼의 hole이 발생
오른쪽 상황
- 프로세스가 딱 3개의 Page로 분할되어서 hole이 발생하지 않음
Paging Example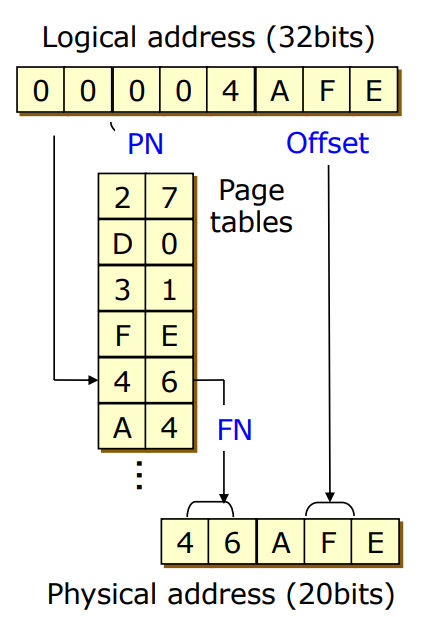
-
Logical Address
- 크기: 32bit = Page Number 20bit + Offset 12bit
-
Physical Adderss
- 크기: 20bit
- Page Number 값에 Offset 값을 연결한 것이 아닌 더하기 연산을 해서 20bit 크기
- Logical Address처럼 Page Number와 Offset을 연결한 것이 아님
-
Page size: 프로세스는 4kb의 페이지 크기로 조각조각 나뉨
-
Page table entries: 페이지 테이블은 2^20개의 행을 저장함
-
Page table size
- Entry Size: 하나의 Logical adderss를 저장하므로 32bit
- Total Size: 32bit × 2^20 = 4byte × 10^6 = 대략 4mbyte
32bit OS의 메모리 인식 최대 범위가 4Gbyte인 이유?
- Page가 최대 페이지 테이블 entry인 2^20개를 저장
- 4kb × 2^20 = 대략 4Gbyte
Free Frames
- 캐싱의 개념처럼 오랫동안 사용하지 않은 공간을 채워줘야함
- 그래서 빈 공간도 같이 관리하므로 free-frame list도 존재
Implementation of Page Table
-
Page Table은 PCB처럼 프로세스마다 하나씩 4MB를 차지
→ 배보다 배꼽이 커질 수 있음 -
특정 메모리에 두번이나 접근
→ Page Table 조차도 Physical memory에 올라가있으므로, Logical Address에서 Physical Address로 접근하기 위해 Page Table에 접근하는 곳에 한 번, 참조한 결과로 Physical Address로 또 접근하는데 두 번 -
그래서 Translation Look-aside Buffer(TLB) 메모리보다 접근 속도가 빠른 버퍼를 MMU안에 설계
TLB
TLB와의 Paging 과정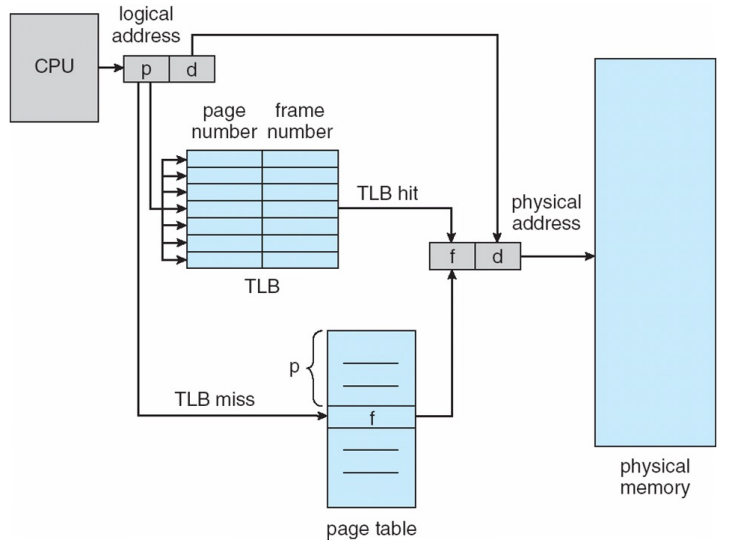
- CPU: logical address (p,d)로 접근할래
- MMU안의 TLB에서 (p,d)에 해당하는 frame 번호가 있는지 확인
- TLB에서...
3-1. TLB hit: 바로 frame 번호를 가져와서 Physical memory 접근
3-2. TLB miss: Physical memory에 있는 Page Table을 참조 → 4로 이동 - frame 번호를 가져와서 Physcial memory로 접근 (기존의 TLB가 없던 방법)
- TLB hit ratio가 높아야 TLB miss가 적게 일어나서 메모리를 2번 접근하는 일이 발생안함
- 실제로 TLB hit ratiosms 99.9%이기 때문에 TLB miss는 거의 안남
Translation Look-aside Buffer(TLB)
-
Associative Memory
TLB는 Associative Memory로 이루어져 있어서 parallel search가 가능 -
Locality: 프로그램은 순차적이므로 주소 또한 근처에 있는 성질
- Spatial locality
- Paging 하나를 실행할 때 마다 Page Table을 참조하면 너무 느림
- 한 Page 내에서 어떤 코드를 실행하고 다음 코드를 실행할 때 다음 주소에 있을 확률이 크다는 성질을 이용
- Tempoal locality
- 반복문 안에서는 같은 내용이 반복됨
- 또 같은 주소를 사용할 확률이 크므로 Page Table를 덜 참조 가능
- Spatial locality
-
Handling TLB miss
그렇다고 완전하게 miss가 없는 것은 아니라서 miss에 대한 handling이 필요-
Intel x86
MMU에 Page Table에서 Frame으로 접근하는 기술을 넣어서 miss가 나도 빠르게 접근 -
저사양 IOT, embedded system
MMU가 없으므로 miss나는 내용은 논외
-
-
Context Swtich 발생 시 TLB는 다 지워지고 새 프로세스의 Page Table를 추가
-
ε=TLB에서 Frame으로 가는 시간 α=TLB hit ratio
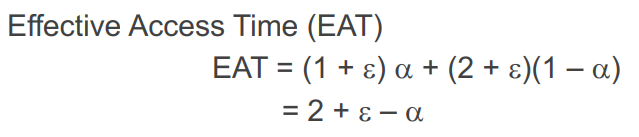
Memory Protection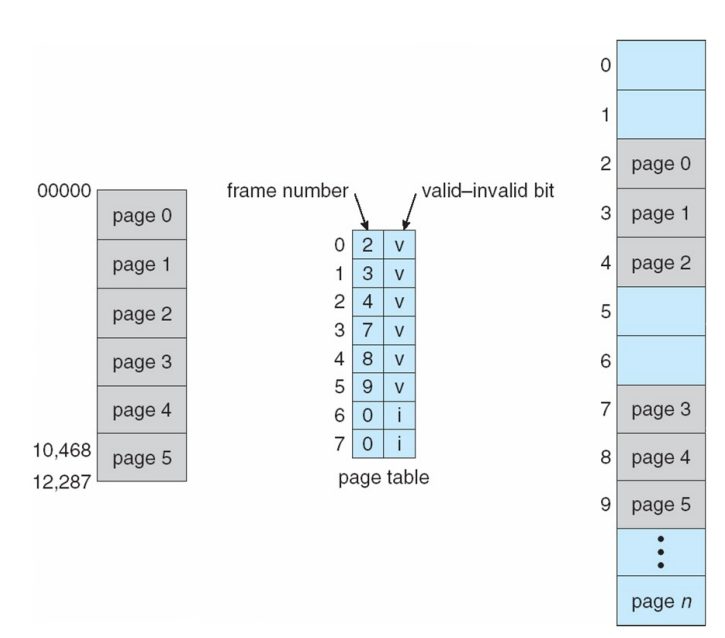
- 사용되는 Page Table Entry를 v(valid), 사용하지 않는 Entry를 i(invalid)로 설정
- i에 접근하게 되면 Trap을 걸어 중지
Page Table Entries(PTEs)
- 총 32bit 중 25비트를 사용하고 7비트는 그냥 빈 공간
- V비트는 Valid/Invalid를 나타내는 비트이며 R, M, Prot은 다음장에서 설명
Page Table Structure
Manging page tables
- Page Table은 4MB라서 오버헤드가 큼
- "일부분만 사용하는 방법은 없을까?"라는 생각에서
Hierarchical paging / Hashed page table / Inverted page table 등장
Hierarchical paing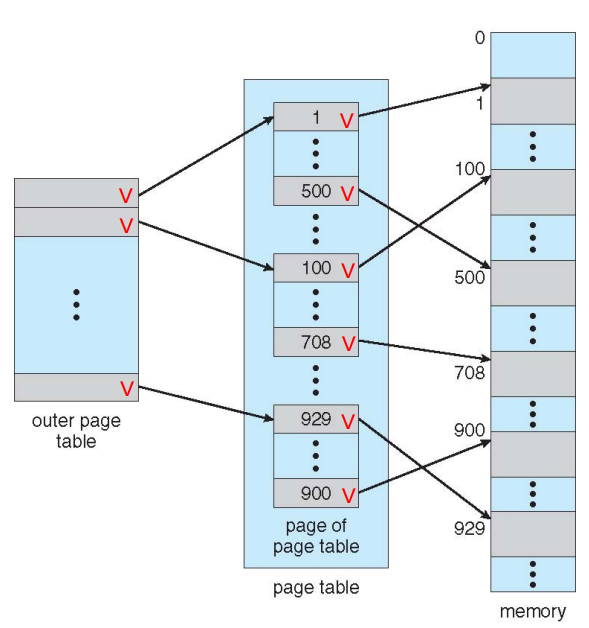
위의 세 방식 중 제일 많이 쓰는 방식
-
기존의 Page Number 20비트에서 p1, p2로 각각 10비트로 쪼갬
-
2차원 배열처럼 outer page table과 page of page table을 구분
-
게임같은 큰 프로세스는 page table을 꽉 채워서 사용
- Outer page table 1개, outer page table안에 있는 page table 2^10개
- 페이지 테이블 2^10+1개를 쓰므로 총 4MB+4kb 소모
- 기존의 방식은 single-level보다 페이지 테이블 한개를 더 씀
-
한개의 page만 쓰는경우
- outer page table 1개, 내부 page table 1개
- 페이지 테이블 2개를 쓰므로 총 8kb 소모
- 기존의 방식인 single-level에서는 4MB다 사용
Hashed Page Tables
- Hash map을 이용해 modulo 연산으로 주소 접근
- modulo 연산을 해서 접근하기 때문에 hash table의 크기가 훨신 작아짐
- 하지만 해당 값을 찾으러 가는 오버헤드가 커서 안씀
Inverted Page Tables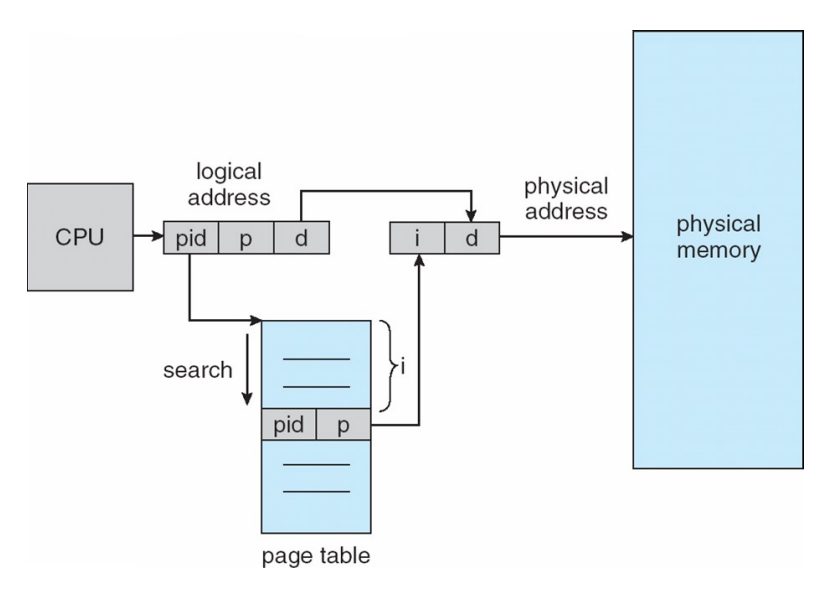
- 특정 프로세스의 pid와 그 프로세스 안의 Page Number를 통해 frame number인 i를 구하는 방식
- Logical address (pid, p, d)에서 pid, p를 통해 physical address (i, d)를 도출
Shared Pages Example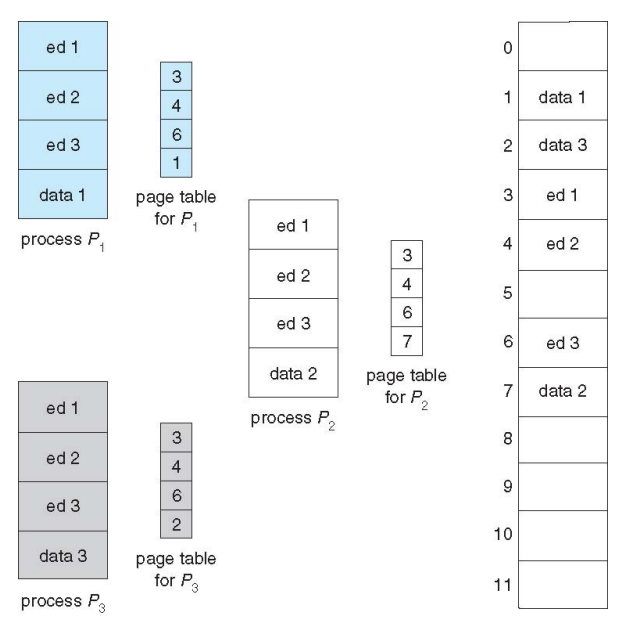
- P1이 도중 fork되어 자식 프로세스 P2가 생김
- frame을 두개 사용하지 않고 같은 frame을 참조해서 공유해서 사용
- 메모리를 최대한 적게 쓰기 위함
Advantages of Paging
-
External fragmentation이 없음 (제일 큰 장점)
-
Memory Protetion이 쉬움: v, i를 통해 Trap
-
페이지 공유도 쉬움: shared memory나 같은 code segment를 사용하는 프로세스
Disadvantages of Paging
-
여전히 internal fragmentation이 있음 (하지만 External 보단 작아서 무시)
-
메모리를 2번 접근함: TLB로 해결
-
배보다 배꼽이 더 크다: Hierarchical, Hashed, Inverted Page Table을 통해 해결
Segmentation
Segmentation
- Page를 프로세스를 같은 크기로 나누는 상황에서
- Code와 Data나 Heap Stack영역이 섞인 Page가 나올 수도 있음3
- 위의 그림에서 검은색 부분은 섞이지 않은 구간, 빨간색은 섞인 구간
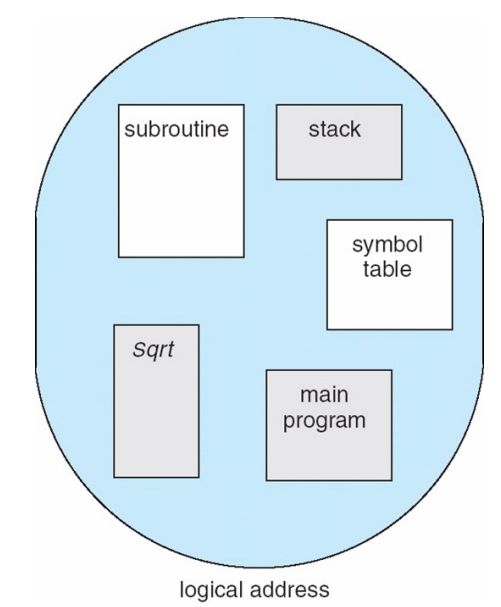
-
Segmentation은 user level의 관점에서 의미 있는 단위로 Page를 나눔
-
단점: Page의 크기가 다르기 때문에 external fragment가 있음
-
segment table에는 segment의 꼭대기가 어디있는가의 limit과 와 0번지 기준이 어디에 위치하는 가의 base 가 저장되어 있음
Segmentation 과정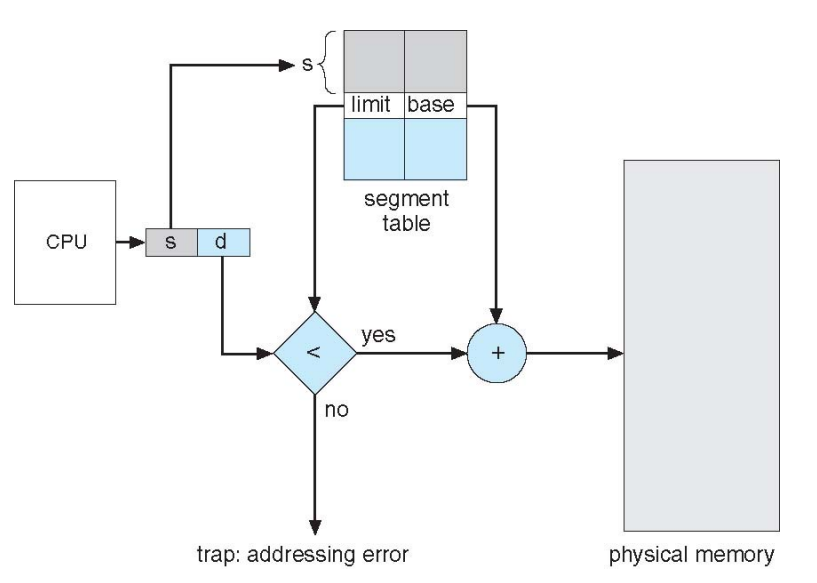
-
세그먼트 번호 s, offset d를 통해 (s, d)로 segment table을 참
조 -
d가 segment table의 limit보다 크다면 정해진 메모리 공간보다 더 큰 곳을 참조하는 것이므로 protection인 trap 발생
-
알맞게 접근했다면 base값을 더해주어 contiguous allocation처럼 physical memory에 접근
Advantages of Segmentation
-
Protection이 쉬움: 더 큰 값에 참조하거나 page의 valid invalid비트처럼 접근에 대해 trap을 걸어줌
-
Share이 쉬움: 같은 Code영역, Shared libraries, Shared Memory의 주소를 공유해서 사용하므로써 메모리도 아끼고 접근도 수월함
-
Internal Fragmentation이 없음
(하지만 External Fragmentation은 있어서 두개는 trade-off 관계)
Disadvantages of Segmentation
-
여전히 Table 크기가 큼
-
External Fragmentation으로 인한 internal Fragmentation보다 더 큰 hole 발생
Hybrid approaches
Paged segments
-
Page와 Segentation이 극명하게 장단점이 갈려서 두 개의 장점만을 가져와 섞어버림
-
의미 있는 덩어리로 나눈 Segment를 같은 크기의 Page로 쪼개서 기존의 hole 크기가 더 줄어들게 됨
Multiple page size
기존의 4kb인 Page size를 2MB, 4MB나 8kb, 16kb으로 알맞게 할당
Intel x86의 Pentium CPU 예제
Segmentation + Hierarchical Paging(Two-level Paging)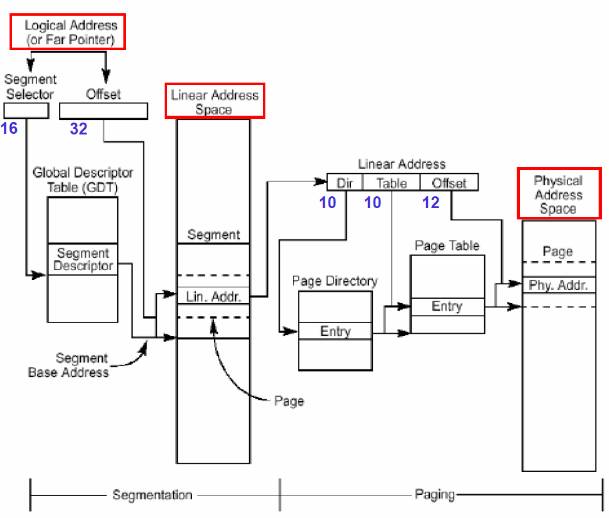
1. (Segment Num, Offset)으로 Segment Base Address 도출
2. Linear Address Space공간을 참조해 Linear Address을 도출
Linear Address는 Hierarchical Paging처럼 (Dir=p1, Table=p2, Offset)으로 구성
3. Hierarchical Page Table로 Page 접근
IA-32
Multiple page size + Two-level Paging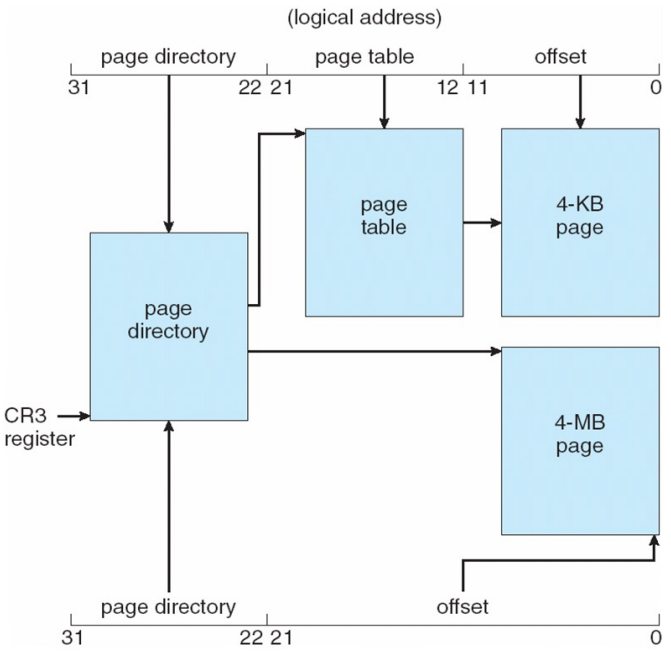
- 3.9MB짜리 프로세스는 4MB 페이지를 할당
- 4.008MB짜리는 4MB 페이지 1개, 4kb페이지 2개로 할당
