PCA의 활용 목적
- 데이터의 분포를 가장 잘 설명하는 벡터(aka 주차원 벡터)를 찾고, 이를 활용하여 차원 축소를 하고자 한다
- 가장 잘 설명하는 벡터는 무엇인가?
1. 분포의 분산이 가장 큰 방향의 벡터
2. 1.에 수직인 방향의 벡터
PCA 순서
- 표기
- x~i=⎣⎢⎢⎢⎡x1x2⋯xn⎦⎥⎥⎥⎤ : 평균을 빼지 않은 데이터
- xˉ=⎣⎢⎢⎢⎡x1x2⋯xn⎦⎥⎥⎥⎤ : 데이터의 평균값
- xi=x~i−xi : 평균을 뺀 데이터값
- u : 어떤 벡터
- 어떤게 가장 잘 설명한다고 할 수 있을 까?
- 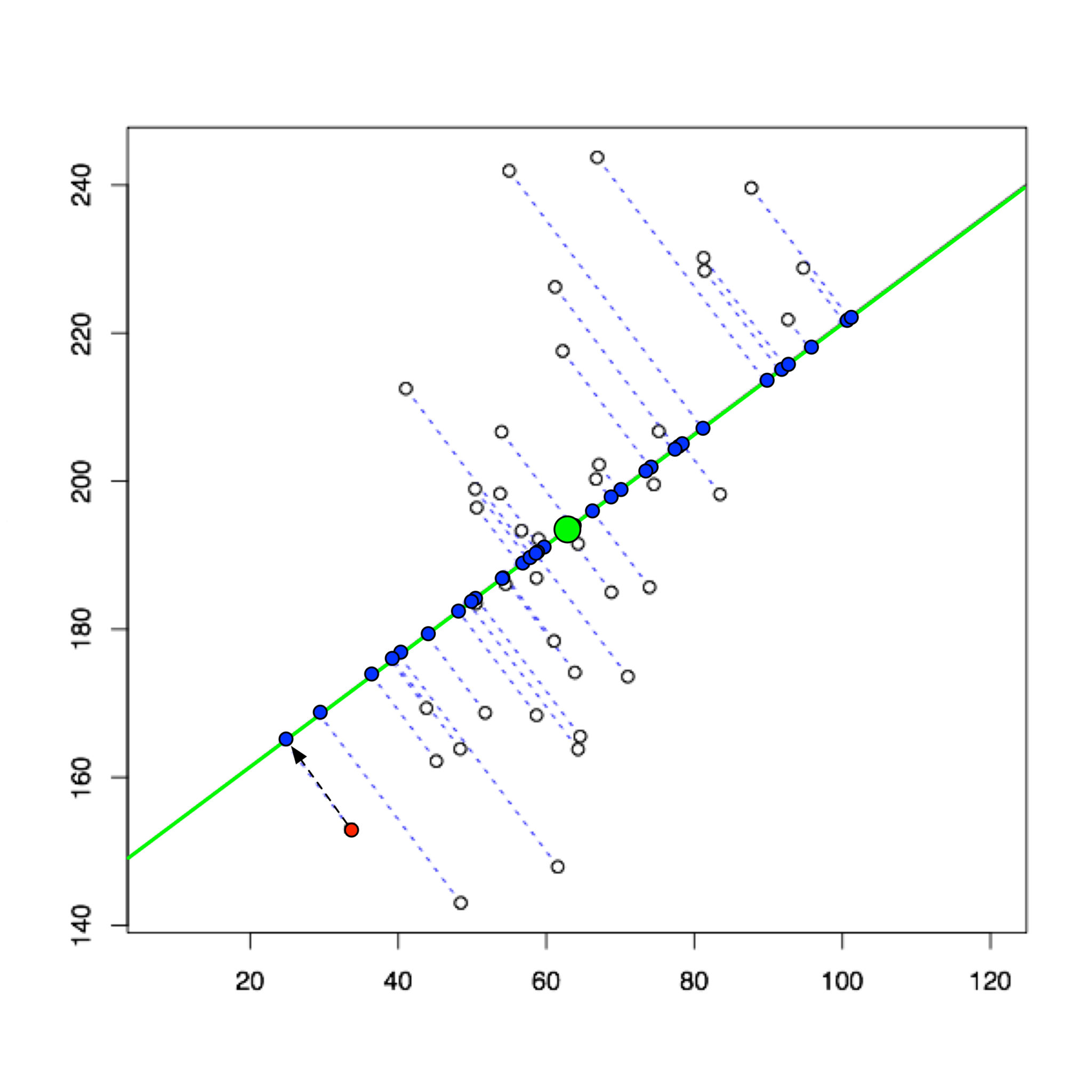
- 어떤 벡터 u 가 있을 때, xi 와 ui 에 정사영내렸을 때의 가장 짧을경우 가장 잘 설명할 수 있다고 할 수 있을 것이다.
- 수식유도
- u .s.t.∥u∥2=1minN1i∑(xi−xiTu⋅u)T(xi−xiTu⋅u)
- =u .s.t.∥u∥2=1minN1i∑(xiT−(xiTu)⋅uT)(xi−xiTu⋅u)
- =u .s.t.∥u∥2=1minN1i∑xiTxi−(xiTu)2+(xiTu)2uTu−(xiTu)uTxi
- =u .s.t.∥u∥2=1minN1i∑xiTxi−xiTuuTxi
- =u .s.t.∥u∥2=1minN−1i∑xiTuuTxi
- =u .s.t.∥u∥2=1minN−1i∑uTxixiTu
- =u .s.t.∥u∥2=1minN−1uTi∑xixiTu
- =u .s.t.∥u∥2=1minN−1uTi∑(xi~−x)(xi~−x)Tu
- =u .s.t.∥u∥2=1min−uTRdu ( Rd 는 N-1로 나눠주는 것으므로 정확한 정의는 아니지만 N이 충분히 크면 N∼N−1 이므로 표본공분산이라 칭함)
- =u .s.t.∥u∥2=1maxuTRdu
- L=uTRdu+λ(1−uTu)
- ∂u∂L=2Rdu−2λu
- (Rd−λ)u=0
- (∂x∂xAx=2Ax )
- 즉 u 는 Rd 의 고유벡터이다
- Cov(x,x) 는 대각화가능하므로
- u .s.t.∥u∥2=1maxuTRdu
- =u .s.t.∥u∥2=1maxuT(i=1∑nλiqi)u (λi,qi는 Cov(x,x)의 고유값,그에 대응되는 정규직교벡터. λ1<λ2<⋯ 라고 하자)
- u 는 가장 큰 고유값에 대응되는 정규직교벡터 q1 (∥q1∥=1)일때 가장 큰 값을 갖는다
- 차원축소
- x^i=xTq1⋅q1+xTq2⋅q2+⋯
- SVD와 PCA의 차이
- SVD는 하나의 데이터에 대한 개별적 압축
- PCA는 전체 데이터에 대한 집단적 압축
- 예) 100X100 얼굴 인식
- 이미지 데이터 차원은 10000
- 10차원으로 줄인다고 하면
- i=1∑10xiTqi⋅qi∼xi
- =xiT[q1,q2,⋯,q10]⎣⎢⎢⎢⎡q1Tq2T⋯q10T⎦⎥⎥⎥⎤
- encoder-decoder로 해석할 수 있다
- manifold learning은?
- 기존 PCA는 데이터의 정보를 가장 잘 보존할 수 있는 hyperplane을 찾는(i∑aixi=0 꼴) 반면에 manifold learning은 다차원의 곡면, manifold를 찾는 것이다
