코드카타
행렬 덧셈
배열 = 초기화
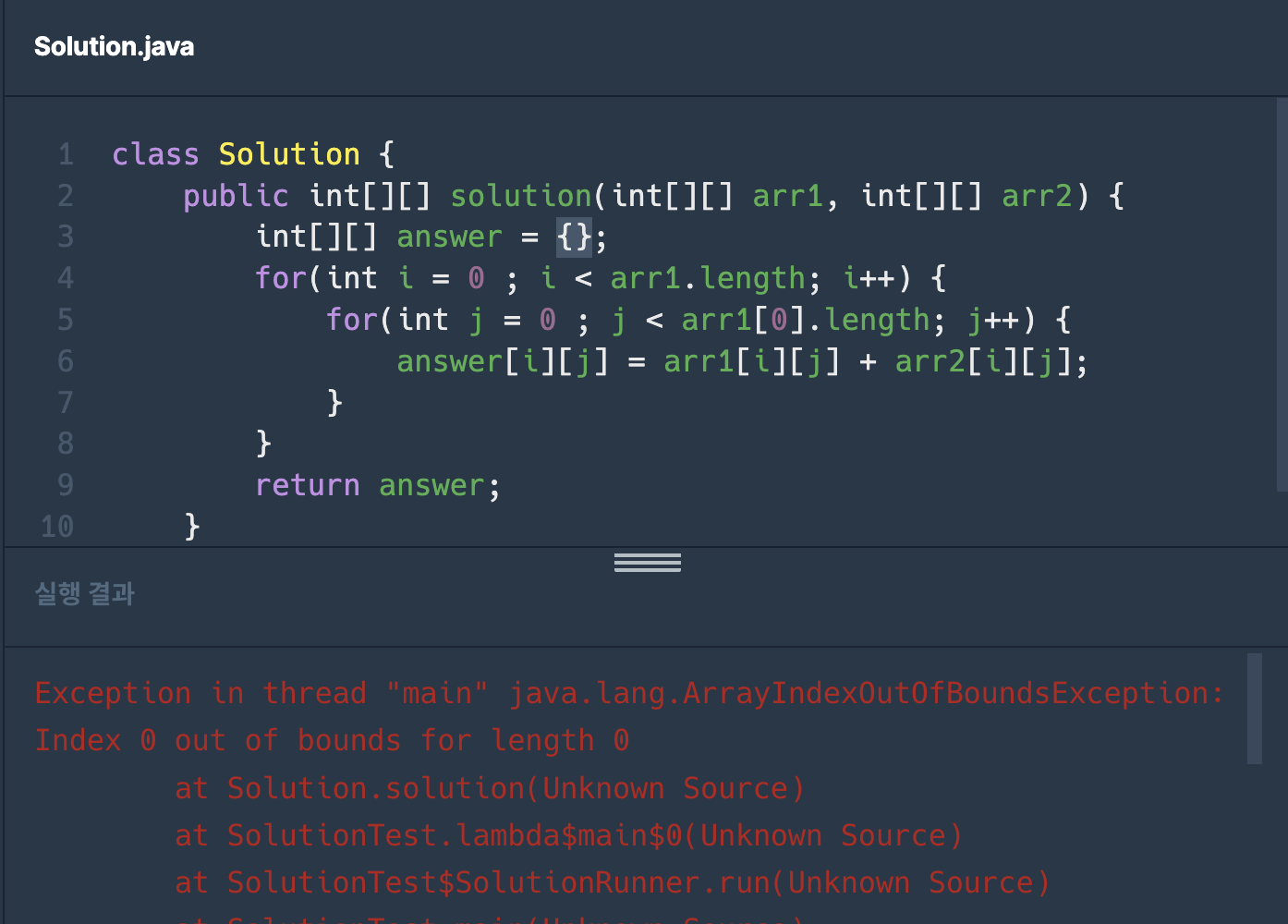
풀이
class Solution {
public int[][] solution(int[][] arr1, int[][] arr2) {
int[][] answer = new int[arr1.length][arr1[0].length];
for(int i = 0 ; i < arr1.length; i++) {
for(int j = 0 ; j < arr1[0].length; j++) {
answer[i][j] = arr1[i][j] + arr2[i][j];
}
}
return answer;
}
}더 최적화 할 방법이 있을까? 싶어서 AI에 물어보니 배열의 각 row를 변수로 해 참조하는 방식이 미세하게 더 빠르다고 했다. (+ 배열 포인터를 이동시키는거라 할당 비용 적음)
(그런데 JVM에 따라 알아서 최적화 하기도 한다고 한다.)
row reference 방식
class Solution {
public int[][] solution(int[][] arr1, int[][] arr2) {
int n = arr1.length;
int m = arr1[0].length;
int[][] answer = new int[n][m];
for (int i = 0; i < n; i++) {
int[] row1 = arr1[i];
int[] row2 = arr2[i];
int[] rowA = answer[i];
for (int j = 0; j < m; j++) {
rowA[j] = row1[j] + row2[j];
}
}
return answer;
}
}직사각형 별찍기
String.repeat()
지난번에 발견한 java11 문법 String.repeat()를 사용해봤다.
헛갈렸던 점은 row repeat 다음에 개행문자를 추가해야했는데 column repeat 다음에 개행문자를 추가해놓고 왜 개행이 안되지? 하고있었다.
import java.util.Scanner;
class Solution {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int a = sc.nextInt();
int b = sc.nextInt();
String shiningStars = ("*".repeat(a) + "\n").repeat(b);
System.out.println(shiningStars);
}
}String.repeat() 내부 구현
찾아보니 String.repeat()의 내부 구현은 배열 복사 기반이라고 한다.
char[] result = new char[len * count];
System.arraycopy(...)최소공배수, 최대공약수
지식 공백!
학부시절 알고리즘 들었을 때 한 번 봐놓고 쓰질 않아서 매번 코테 때 애먹었던 부분 중 하나인 최대공약수, 최소공배수 문제를 맞닥뜨렸다.
함수 이름만 봐도 얼마나 안 익숙한지 알 수 있다😂
class Solution {
public int[] solution(int n, int m) {
int[] answer = {}; return answer;
}
private int maxDiv(int a, int b) { // 최대공약수
}
private int minMulti(int a, int b) { // 최소공배수
}
}모르겠으면 외워
class Solution {
public int[] solution(int n, int m) {
int gcd = maxDiv(n, m);
int lcm = minMulti(n, m);
int[] answer = {gcd, lcm};
return answer;
}
private int maxDiv(int a, int b) { // 최대공약수 (유클리드 호제법)
while (b != 0) {
int temp = a % b;
a = b;
b = temp;
}
return a;
}
private int minMulti(int a, int b) { // 최소공배수
return (a * b) / maxDiv(a, b);
}
}최대공약수: 유클리드 호제법(互除法)
나머지가 0이 될 때까지 계속 나눈다!
while (b != 0) {
int temp = a % b;
a = b;
b = temp;
}
return a;원리:
1. 큰 수(a)를 작은 수(b)로 나눈다.
(코드에서 '큰 수' 판별을 굳이 안 하는 이유: 만약 b가 더 클 때%연산에서 나머지는 작은 수 a 자기 자신이 되어 결국gcd(b,a)호출과 같아진다.)
2. 그리고 나누었던 수()를 방금 나온 '나머지'로 또 나눈다.
3. 나머지가 0이 딱 떨어지는 순간, 마지막으로 나눈 그 숫자가 바로 최대공약수가 된다.🍎 예시: 24와 18의 최대공약수 구하기
24 % 18 = 6 (나머지가 6, 0이 아니니까 한 번 더!)
18 % 6 = 0 (아까 나눴던 18을 나머지인 6으로 나눈다.)
나머지가 0이네? 빙고! 마지막으로 나눈 수 6 == 최대공약수
재귀 함수 형태로도 구현 가능하다.
private int gcd(int a, int b) {
if (b == 0) return a;
return gcd(b, a % b);
}최소공배수
return (a * b) / maxDiv(a, b);
🤔 왜 곱하고 나눌까?
와 라는 두 숫자는 사실 (최대공약수 어떤 수) 로 이루어져 있다.
과 이 두 수를 그대로 곱해버리면 (),
공통된 뼈대최대공약수(6)가 두 번 중복해서 곱해진다.
최소공배수는 중복 없이 모든 성분을 한 번씩만 품어야 하므로,
두 수를 곱한 뒤에 중복된 최대공약수를 한 번 나눠서 빼줘야 한다.
최소공배수를 구할 땐, 숫자가 급격하게 커질 수 있다. 문제의 숫자 범위를 보고 필요하다면 long 타입을 사용하자.
함수 이름 바꾸기
greatestCommonDivisor // 최대공약수
leastCommonMultiple // 최소공배수TODO: 오늘 학습 끝나기 전에 한 번 더 보기
MSA
Spring Cloud Config
Spring Cloud Config는 분산 시스템 환경에서 중앙 집중식 구성 관리를 제공하는 프레임워크
중앙 집중식 구성 관리
- 애플리케이션의 설정을 중앙 한 곳에서 설정 파일을 동적으로 변경하고 관리하며, 변경 사항을 실시간으로 반영할 수 있다.
- Git, 파일 시스템, JDBC 등 다양한 저장소에서 중앙 정보를 관리할 수 있다.
환경별 구성
- 환경별(개발, 테스트, 운영)로 설정 파일을 분리하여 관리할 수 있다.
실시간 구성 변경
- 실시간 구성 변경이 가능하므로, 애플리케이션 재시작 없이도 수정 사항이 반영된다.(기존에는 애플리케이션 재배포가 필요)
Spring Cloud Config 서버
Spring Cloud config server 설정을 위해 빌드 Gradle에 서버용 의존성(Dependency) 추가
dependencies {
implementation 'org.springframework.cloud:spring-cloud-config-server'
implementation 'org.springframework.boot:spring-boot-starter-web'
}애플리케이션에 @EnableConfigServer 어노테이션을 반드시 추가
@SpringBootApplication
@EnableConfigServer
public class ConfigServerApplication {
public static void main(String[] args) {
SpringApplication.run(ConfigServerApplication.class, args);
}
}
server:
port: 8888
spring:
cloud:
config:
server:
git:
uri: https://github.com/my-config-repo/config-repo
clone-on-start: true
환경별 설정
Config 서버는 환경별로 다른 설정 파일을 제공할 수 있습니다.
로컬, 데브, QA, 릴리즈 등 다양한 환경별로 각기 다른 설정 파일(yaml 파일)을 사용하여 애플리케이션을 관리합니다.
환경별 설정은 yaml 파일명 뒤에 환경명을 dash(-)로 붙여 구분하며, 모든 설정 파일은 config server에 저장됩니다.
예를 들어, application-dev.yml, application-prod.yml 파일을 Git 저장소에 저장하여 환경별 설정을 관리합니다.
Spring Boot 애플리케이션에서 프로필을 사용하여 환경을 구분할 수 있습니다.
원하는 환경의 설정은 프로필의 active 항목에서 선택하여 해당 환경의 파일을 불러와 적용합니다.
spring:
profiles:
active: devSpring Cloud Config 클라이언트
client에서는 서버가 없는 Config Starter Dependency를 추가하며, 별도의 애플리케이션 어노테이션은 필요하지 않음
디스커버리 활성화 및 서비스 아이디 기입이 요구되고, 모든 서비스는 Eureka Client로 선언해야 한다.
dependencies {
implementation 'org.springframework.cloud:spring-cloud-starter-config'
}
spring:
application:
name: my-config-client
cloud:
config:
discovery:
enabled: true
service-id: config-server
eureka:
client:
service-url:
defaultZone: http://localhost:19090/eureka/실시간 구성 변경 방법
Spring Cloud Bus
Spring Cloud Bus를 사용하면 설정 변경 사항을 실시간으로 클라이언트 애플리케이션에 반영할 수 있습니다. 이를 위해서는 메시징 시스템(RabbitMQ 또는 Kafka 등)을 사용하여 변경 사항을 전파해야 합니다.
수동 구성 갱신
/actuator/refresh 엔드포인트 사용
Spring Cloud Bus를 사용하지 않는 경우, 클라이언트 애플리케이션에서 수동으로 설정을 갱신할 수 있습니다. 이를 위해 Spring Actuator의 /actuator/refresh 엔드포인트를 사용할 수 있습니다.
설정 갱신 절차
Config 서버에서 설정 파일을 변경합니다.
클라이언트 애플리케이션의 /actuator/refresh 엔드포인트를 POST 요청으로 호출하여 변경된 설정을 반영합니다.
이 방법은 간단하지만, 각 클라이언트 애플리케이션에서 수동으로 엔드포인트를 호출해야 합니다.
Spring Boot DevTools 사용
Spring Boot DevTools를 사용하면 개발 환경에서 파일 변경을 자동으로 감지하고 애플리케이션을 재시작할 수 있습니다. 이는 classpath 내의 파일 변경도 포함됩니다.
Git 저장소 사용
Spring Cloud Config 서버가 Git 저장소에서 설정 파일을 읽어오도록 설정할 수 있습니다. 이는 설정 파일의 변경 사항을 쉽게 반영하고, 여러 서비스 간에 일관된 구성을 유지하는 데 유용합니다.
네이티브 모드 실습
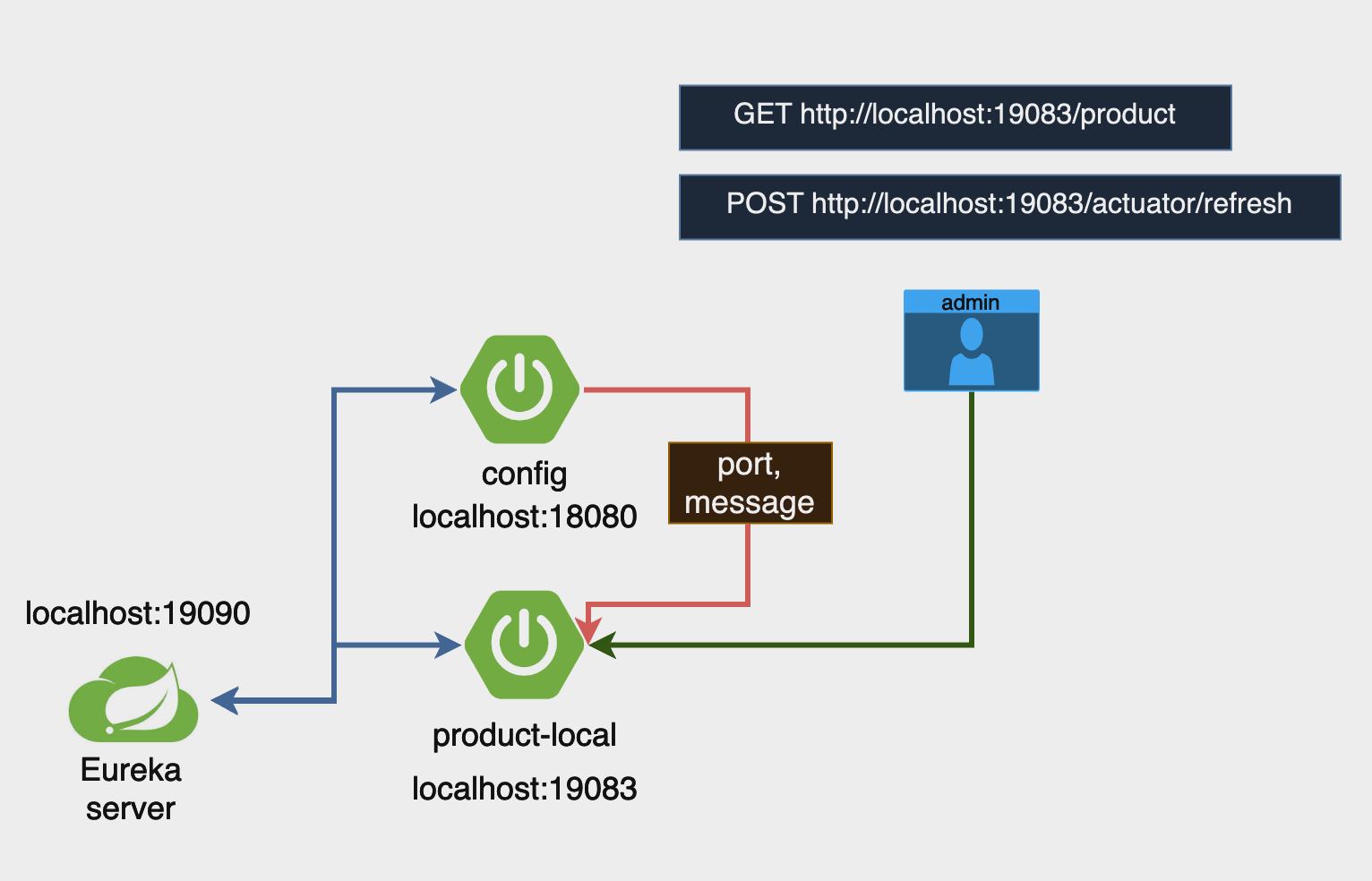
Config 서버 설정
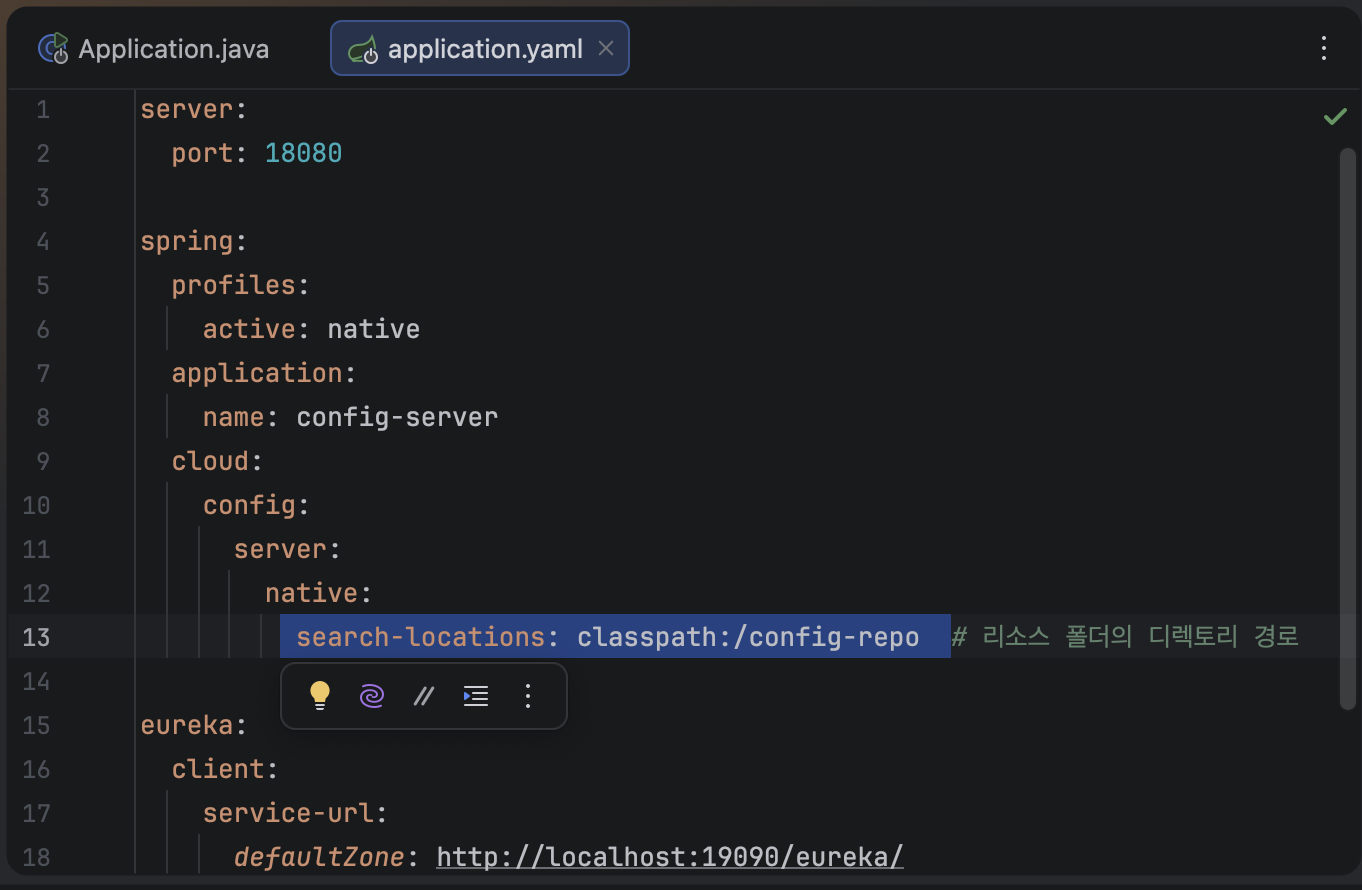
search-locations 경로에 아래의 두 파일을 만든다.
product-service.yml
server:
port: 19093
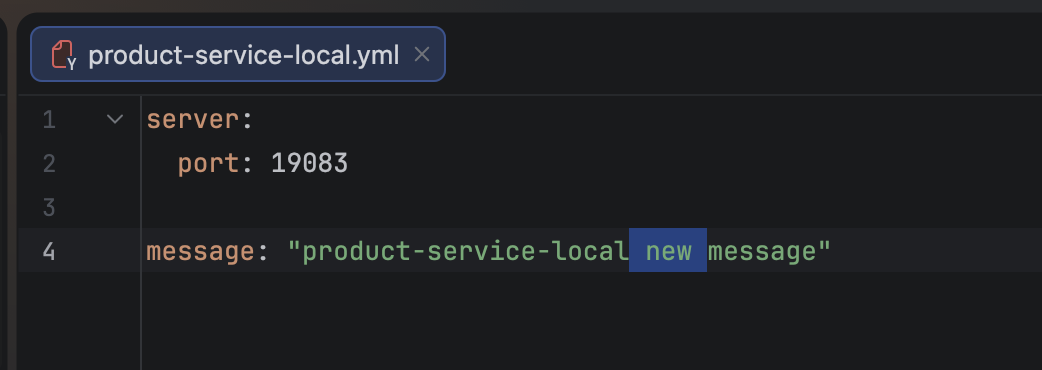
message: "product-service message"product-service-local.yml
server:
port: 19083
message: "product-service-local message"Product
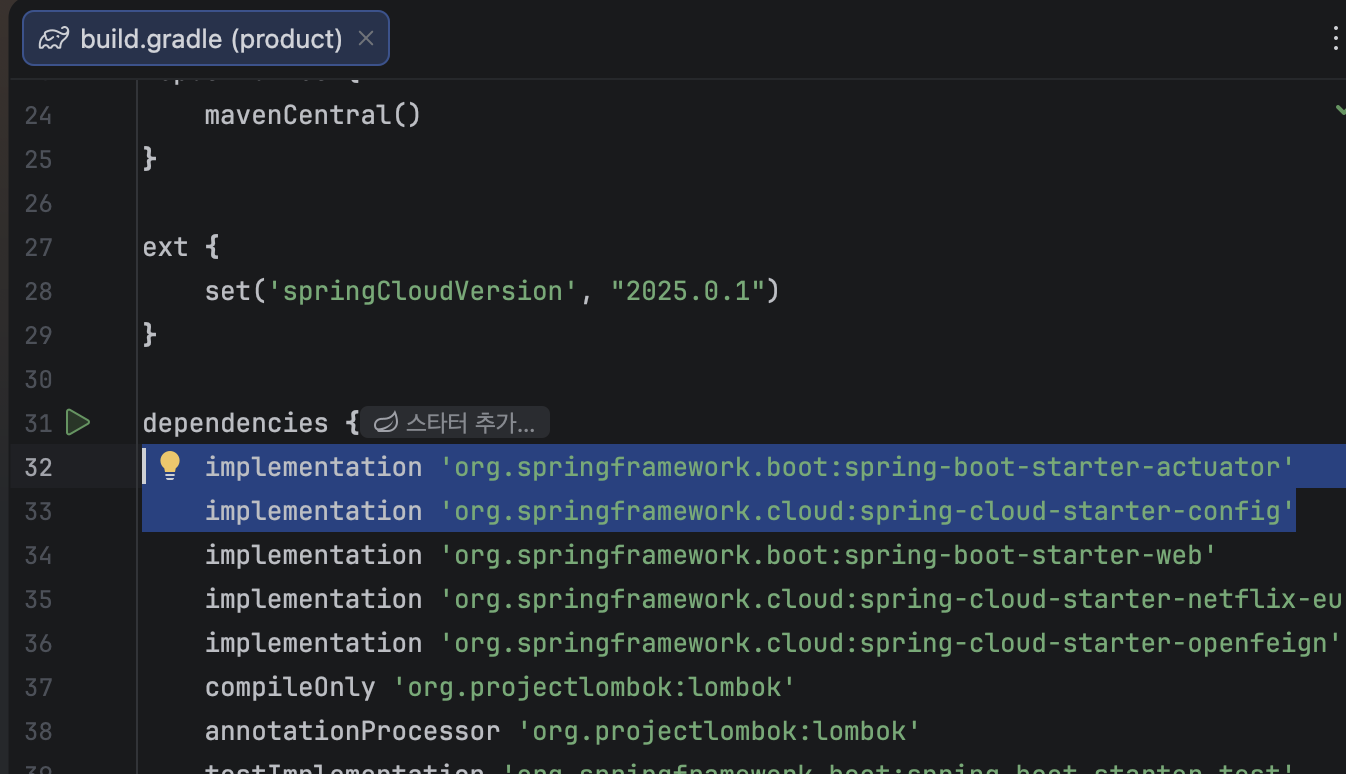
dependencies {
implementation 'org.springframework.cloud:spring-cloud-starter-config'
implementation 'org.springframework.boot:spring-boot-starter-actuator'
}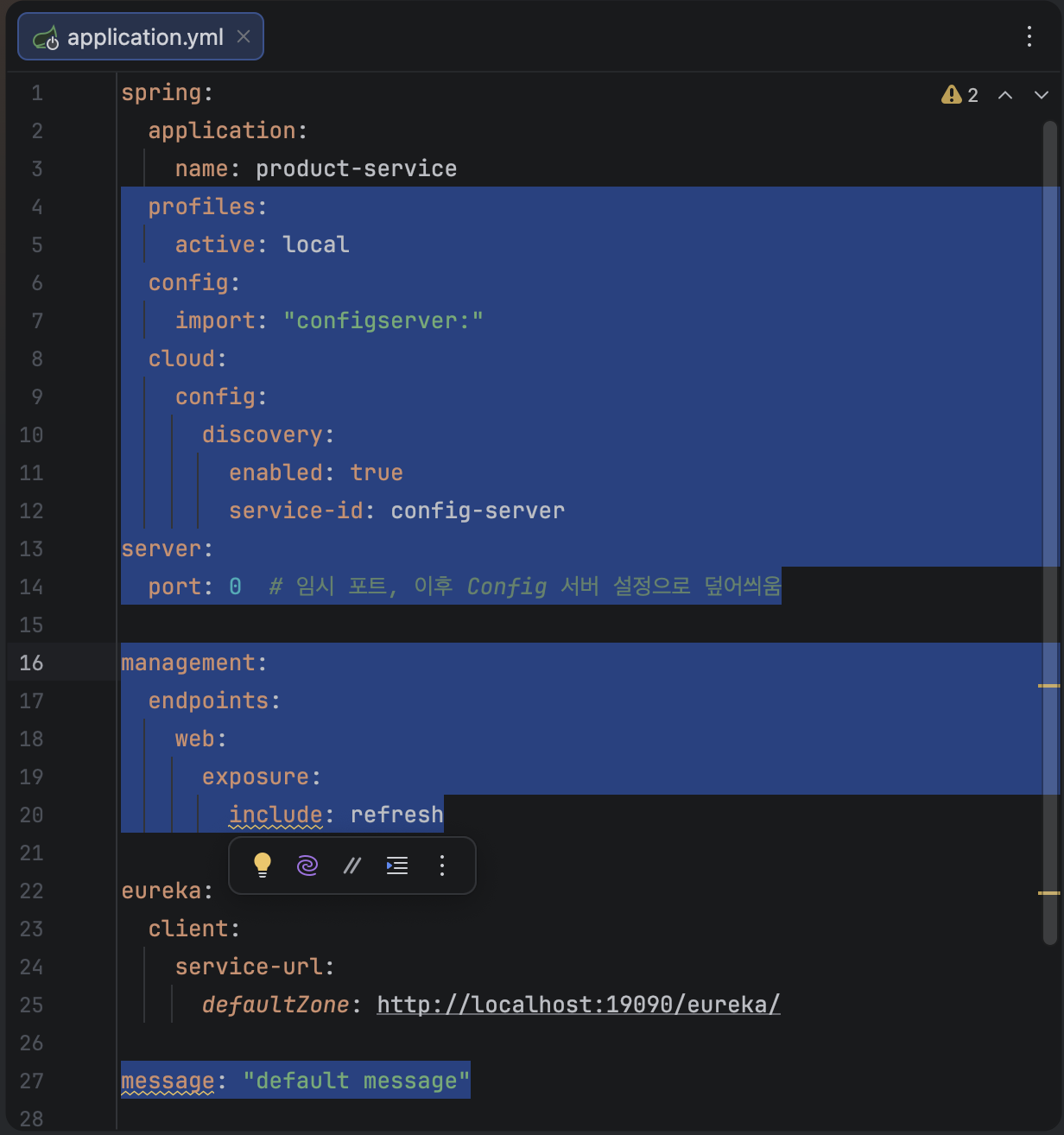
server:
port: 0 # 임시 포트, 이후 Config 서버 설정으로 덮어씌움
spring:
profiles:
active: local
application:
name: product-service
config:
import: "configserver:"
cloud:
config:
discovery:
enabled: true
service-id: config-server
management:
endpoints:
web:
exposure:
include: refresh
eureka:
client:
service-url:
defaultZone: http://localhost:19090/eureka/
message: "default message"@RefreshScope // Bean 설정값이 업데이트 되었을 때 의존 주입되도록 설정
@RestController
public class ProductController {
@Value("${server.port}") // 애플리케이션이 실행 중인 포트를 주입받습니다.
private String serverPort;
@Value("${message}")
private String message;
@GetMapping
public String getProductWithMessage() {
return "Product detail from PORT : " + serverPort + " and message : " + this.message ;
}local profile 설정 확인하기
spring:
profiles:
active: local에 맞게 Product의 포트 번호가 Config 서버의 product-service-local.yml 설정을 주입받아 사용함을 볼 수 있다.

message 또한 Product 자신의 환경설정 message: "default message" 대신 product-service-local.yml 에 설정된
message: "product-service-local message"을 가져옴을 알 수 있다.
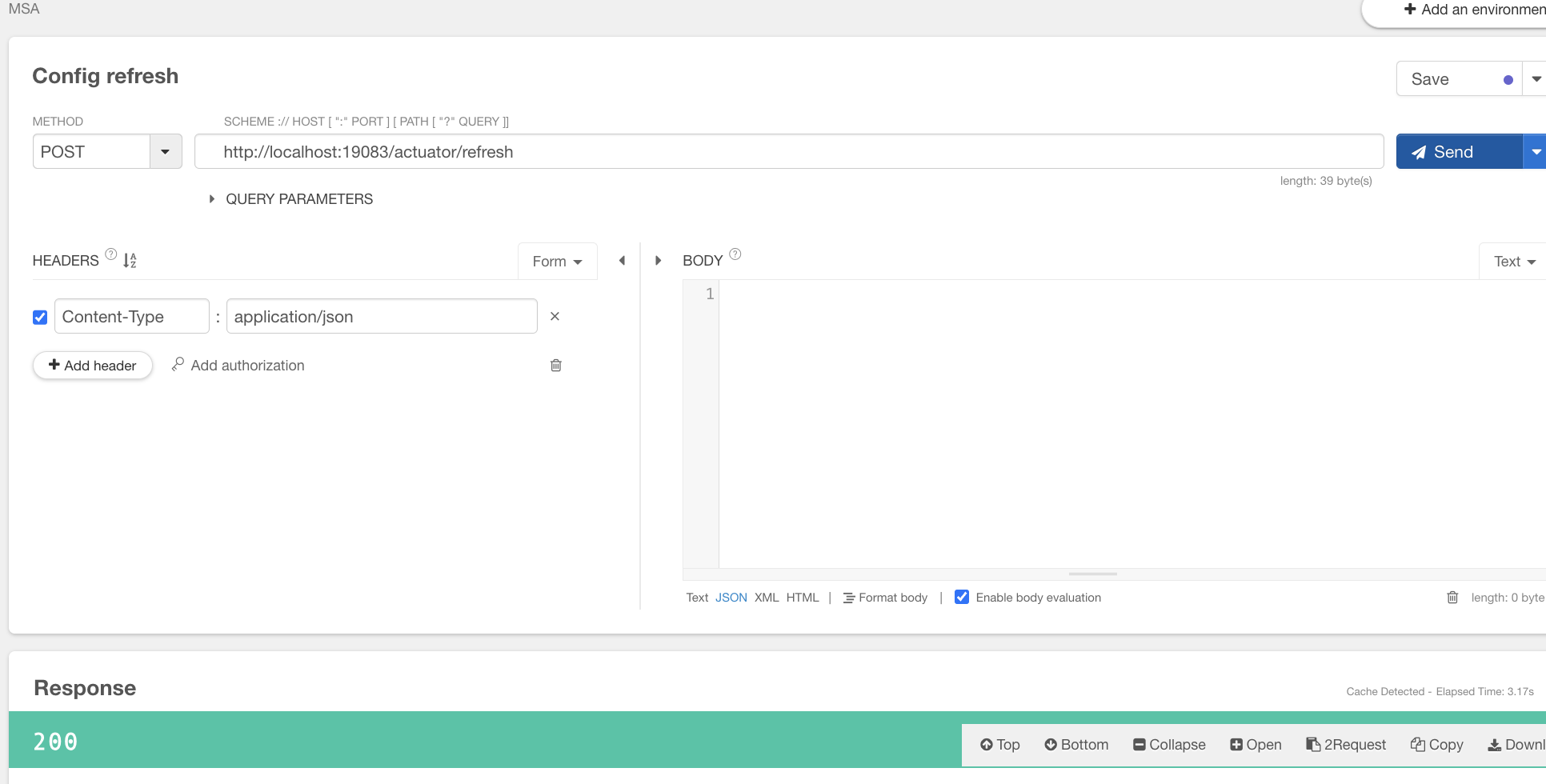
actuator/refresh로 실시간 구성 변경하기
Config server
config-server 의 product-service-local.yml 파일의 message를 수정하고 config-server 를 재시작
Product (Config client)
POST http://localhost:19083/actuator/refresh 요청
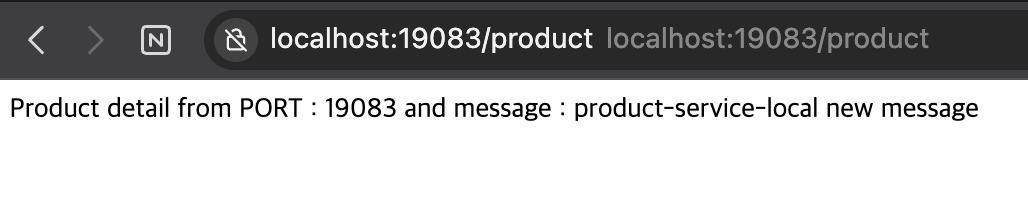
Product 서비스를 재실행 할 필요 없이 구성이 변경됨을 확인할 수 있다.
http://localhost:18080/product-service/local 에서
product-service의 설정 값들을 볼수 있다.
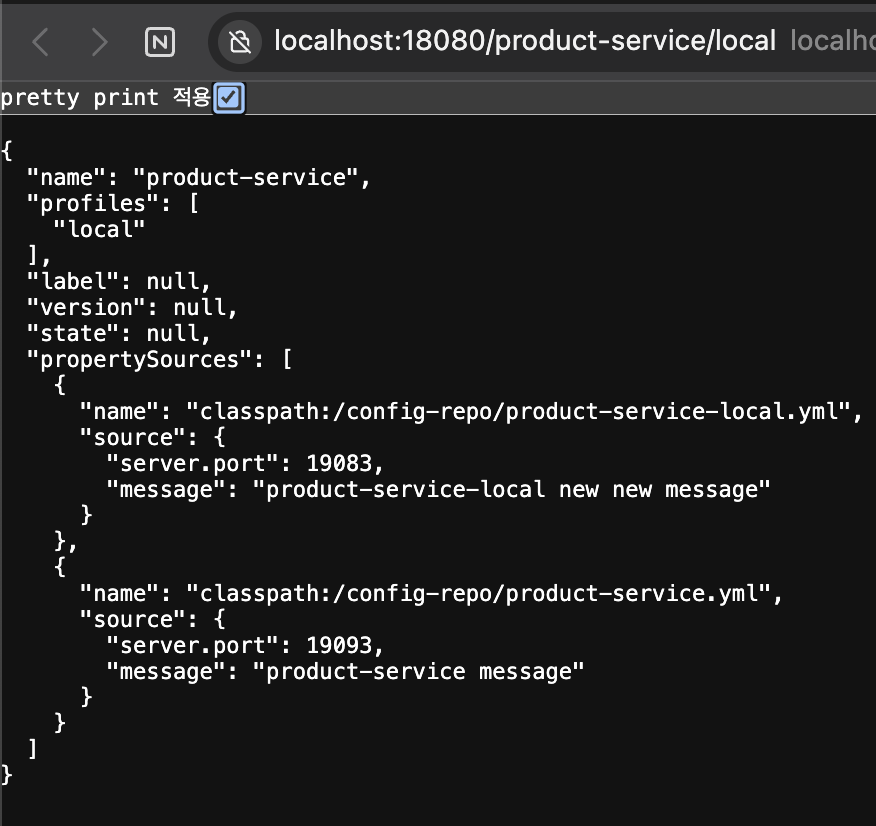
이를 통해 다른 설정값들도 확인할 수 있다.
주의: 실행 순서
Config 서버가 먼저 실행 된 후 Config 클라이언트가 실행되어야 한다.
Config 서버가 올라간 뒤 Product 서버를 실행하는데 4~5초 정도 텀을 두고 실행해줘야 했다.
Application run failed
org.springframework.cloud.config.client.
ConfigClientFailFastException:
Could not locate PropertySource and the resource is not optional, failingDDD 특강
[사전 학습] DDD(도메인 주도 설계)의 필요성과 핵심 개념 요약
1. 왜 DDD(Domain-Driven Design)인가?
전통적인 데이터 중심 설계는 데이터베이스 테이블을 먼저 정의하고 그 위에 비즈니스 로직을 얹는 방식이다. 하지만 시스템이 커질수록 다음과 같은 한계에 직면한다.
- 비즈니스 로직의 파편화: 서비스 로직이 수천 줄로 비대해지며 수정 시 영향도 파악이 어려워진다.
- 소통의 단절: 기획자, 개발자, 운영자가 사용하는 용어가 서로 달라 오해가 발생하고 소통 비용이 증가한다.
DDD는 기술적인 구현보다 비즈니스 도메인(영역) 자체를 코드의 중심에 둔다. 이를 통해 복잡한 로직을 격리하고 유지보수성을 극대화하는 것이 목적이다.
2. 전략적 설계: Bounded Context (경계 긋기)
모놀리식 프로젝트를 MSA(마이크로서비스 아키텍처)로 확장하기 위한 가장 중요한 기준이다. 모든 도메인을 하나의 큰 덩어리로 보지 않고, 특정 모델이 적용되는 문맥(Context)에 따라 경계를 나눈다.
- Bounded Context: 모델의 의미가 유효한 명확한 경계이다.
- 예: '상품' 객체는 [주문 컨텍스트]에서는 가격과 옵션이 중요하지만, [배송 컨텍스트]에서는 무게와 부피가 핵심 데이터가 된다.
- 이 경계를 명확히 설정해야 서비스 간의 결합도가 낮아지며, 독립적인 MSA 배포 및 확장이 가능해진다.
3. 전술적 설계: Aggregate & DIP (구조화)
도메인 모델의 내부 응집도를 높이고 기술 종속성을 제거하는 방법론이다.
Aggregate (애그리거트)
관련된 객체들을 하나의 논리적 묶음으로 취급하는 단위이다.
- Root Entity: 애그리거트의 대표자이다. 외부에서는 오직 이 루트를 통해서만 내부 객체에 접근할 수 있다.
- 데이터 일관성을 유지하는 최소 단위가 되며, JPA 사용 시 N+1 문제나 지연 로딩 최적화의 기준점이 된다.
Layered Architecture & DIP (의존성 역전 원칙)
비즈니스 핵심 로직이 특정 프레임워크나 데이터베이스 기술에 종속되지 않도록 층을 분리한다.
- DIP 적용: 고수준의 도메인 로직이 저수준의 인프라(DB, 외부 API)를 직접 참조하지 않고 인터페이스에 의존하게 한다. 이를 통해 기술 스택이 변경되어도 비즈니스 로직은 안전하게 보호된다.
4. MSA 확장을 위한 서비스 분리 원칙
DDD를 학습하는 궁극적인 이유는 '어디를 서비스로 자를 것인가'에 대한 논리적 근거를 얻기 위함이다.
- 도메인 분석: 비즈니스 흐름에 따라 Bounded Context를 식별한다.
- 서비스 분리: 각 컨텍스트를 독립적인 서비스 단위로 도출한다.
- 통신 설계: 서비스 간의 데이터 참조는 API(Feign Client 등)나 이벤트 기반 메시징을 활용한다.
이러한 설계 관점 없이 시스템을 쪼개면 '분산된 모놀리식'이 되어 관리 비용만 증가할 수 있다. 복잡한 비즈니스일수록 도메인 중심으로 구조화하는 연습이 반드시 필요하다.
DDD 특강
DDD가 필요한 이유
- 의도하지 않은 참조로 인한 N+1 문제, 스파게티 의존성 발생
- 연관관계 남발 및 Repository 직접 호출로 인한 팀 내 코드 일관성 붕괴
- 도메인 경계가 모호하여 하나의 서비스에 다수의 Repository가 포함됨
- 프로젝트가 커질수록 확장이 어려움
위 문제들은 대부분 ERD 중심 설계와 무분별한 객체 참조에서 발생하는 전형적인 문제이다.
강결합 vs 느슨한 결합
강결합
모든 서비스/엔티티가 서로를 직접 참조하는 구조이다.
하나를 변경하면 전체에 영향을 준다.
느슨한 결합
각 도메인을 독립적으로 설계하고 약속된 인터페이스(API, Facade)로만 소통하는 구조이다.
지금까지 우리 개발 방식
요구사항 분석 → ERD 설계 → 엔티티 관계 구현 → 서비스 로직 구현
DB에 FK가 존재하므로 객체에도 연관관계를 맺어야 한다고 생각한다.
하지만 DB의 조인과 객체의 참조는 다른 개념이다.
객체 관점에서 연관관계가 많아지면 Object Navigation이 발생하고
결과적으로 복잡도와 성능 문제가 증가한다.
나는 외래키가 있으면 성능상 fetch join을 위해 연관관계를 가져야 한다고 생각했다.
하지만 이는 객체 설계 관점에서는 잘못된 접근이다.
두 가지 연관관계
-
종속적인 관계
→ 생명주기를 함께한다 (Cascade 가능) -
독립적인 관계
→ 생명주기가 다르며 별도의 애그리거트로 분리해야 한다
바운디드 컨텍스트
큰 시스템을 작은 경계로 나누는 방법이며 비즈니스 영역의 경계이다.
회사 조직에 비유하면 다음과 같다.
- 인사부 / 재무부 / 영업부
→ 각 부서는 독립적으로 운영되지만 필요 시 공식 채널로 소통한다
특징
- 컨텍스트 내부에서는 고유한 비즈니스 규칙을 가진다
- 독립적으로 설계 및 구현된다
- 다른 컨텍스트와는 인터페이스로 소통한다
동일한 개념이 맥락에 따라 다르게 해석될 수 있다
도메인 간 소통
Facade를 통한 호출
모놀리식 구조에서 사용한다.
API / 이벤트 기반 호출
MSA 아키텍처에서 사용한다.
애그리거트와 애그리거트 루트
관련 객체를 하나로 묶고 진입점을 설정하는 방식이다.
예: 주문
주문은 다음과 같은 구성 요소를 가진다.
- 주문 상품 목록 (OrderItem)
- 배송 정보 (ShippingInfo)
- 주문자 정보 (Orderer)
주문 수량이 바뀌면 총 금액이 바뀌어야 한다.
배송지를 변경하면 배송 가능 여부를 먼저 체크해야 한다.
이처럼 함께 변경되는 객체들의 묶음을 애그리거트라고 한다.
애그리거트 루트
애그리거트의 대표 객체이며 유일한 진입점이다.
외부에서는 반드시 루트를 통해서만 내부 객체를 변경해야 한다.
잘못된 접근 방식
OrderItem item = orderItemRepository.findById(id);
item.setQuantity(5);
item.setPrice(5000);문제점
- 데이터 불일치 발생
- 비즈니스 규칙 무시
- Repository 남발
- 사이드 이펙트 추적 불가
올바른 접근 방식
Order order = orderRepository.findById(id);
order.changeQuantity(itemId, 5);모든 변경은 애그리거트 루트를 통해 이루어진다.
애그리거트 경계를 나누는 기준
- 함께 변경되는가
- 불변식이 존재하는가 (총액 = 수량 × 가격)
- 생명주기가 동일한가
- Cascade 가능한가
불변식 예시
주문 항목은 0~10개이다.
public Order(List<OrderItem> orderItems) {
validateOrderItems(orderItems);
this.orderItems = orderItems;
}
public void validateOrderItems(List<OrderItem> orderItems) {
if (orderItems == null || orderItems.isEmpty()) {
throw new IllegalArgumentException("주문 항목은 비어 있을 수 없다.");
}
if (orderItems.size() > MAX_ORDER_ITEMS) {
throw new IllegalArgumentException("주문 상품 수 초과");
}
}
도메인 관점 설계
ERD보다 도메인 모델을 먼저 설계한다.
요구사항 → 도메인 모델 → 바운디드 컨텍스트 정의 → 애그리거트 & 루트 설정 → 구현 모델 → 패키지 구조 → 코드작성
: 완벽한 설계는 없지만 변경에 유연한 구조가 중요하다.
바운디드 컨텍스트 vs 애그리거트
-
바운디드 컨텍스트
→ 시스템을 나누는 큰 경계 -
애그리거트
→ 데이터 일관성을 보장하는 내부 단위
QnA
정합성 문제
- 같은 애그리거트 내부 → 강한 일관성 유지
- 다른 애그리거트 간 → 이벤트 기반으로 결국적 일관성 유지
루트 애그리거트 Repository 외에 Repository를 만드는 경우는 언제?
조회 성능이나 복잡한 쿼리 요구사항이 있는 경우이다.
예를 들어 Order가 루트이고 OrderItem이 내부 엔티티인 경우
특정 조건의 OrderItem만 조회해야 하는 상황이 있다.
루트를 통해 조회하면
Order 전체를 조회한 뒤 메모리에서 필터링해야 하므로 비효율적이다.
이 경우
- OrderItemRepository를 조회 전용으로 생성
- DTO Projection으로 필요한 데이터만 조회
하는 방식으로 성능을 개선할 수 있다.
단, 변경은 반드시 루트를 통해서만 이루어져야 한다.
추가 개념 짚고가기:
도메인이란
해결해야 하는 문제의 영역이다.
하나의 대상도 컨텍스트에 따라 의미가 달라진다.
예: 홍길동
- 회원 컨텍스트 → 사용자
- 주문 컨텍스트 → 주문자
- 리뷰 컨텍스트 → 리뷰 작성자
설계 포인트
회원 이름이 변경되었을 때
주문, 리뷰의 이름까지 변경해야 하는가?
정답은 아니다.
이유:
- 각 도메인은 독립적인 컨텍스트이다
- 식별자(userId)를 기준으로 연결한다
핵심 정리
- DB 중심 설계 → 복잡도 증가
- DDD → 도메인 중심 설계
- 애그리거트 → 일관성 보호 장치
- 루트 → 유일한 진입점
- Repository → 루트 기준
- 조회는 별도 모델로 분리 가능
