코드카타
3진법 뒤집기
3진법은 처음 봐서 대체 어떻게 구하지.. 하다가
문제에서 주어진 답을 도출하는 과정을 보고 2진법을 구하는 방식의 규칙을 대조해 3으로 나눠가며 나머지를 모으면 3진법이 되는것을 알았다.
또 문제에서 그냥도 아니고 그 역순을 구하라 해서 역순은 또 어떻게 구하나 막막했는데, 3진법을 만드는 과정에서 오히려 역순을 표현하기가 더 쉽다는 것을 알게되어 문제에서 배려를 해 준 것을 알게되었다.
문제의 조건이 꼭 더 어렵게 하기 위한 조건만 있는 건 아니라는 것을 깨달았다.
class Solution {
public int solution(int n) {
int answer = 0;
answer = threeToTen(reversedThree(n));
return answer;
}
// 앞뒤 반전 3진법
private String reversedThree(int n) {
StringBuilder sb = new StringBuilder();
while(n>0) {
sb.append(n%3);
n/=3;
}
return sb.toString();
}
// 10진법으로 표현
private int threeToTen(String n) {
int answer = 0;
for(int i = 0; i < n.length(); i++) {
// 앞자리 수를 왼쪽으로 밀고(×3), 그 다음 숫자를 붙인다
answer = answer * 3 + (n.charAt(i) - '0');
}
return answer;
}
}Integer.toString()
Integer.toString(n, 진법)내장함수를 사용하면 n진수 문자열을 바로 구할 수 있다.
class Solution {
public int solution(int n) {
String reversed = new StringBuilder(Integer.toString(n,3)).reverse().toString();
return Integer.parseInt(reversed,3);
}
}지난 프로젝트 코드로 DDD 알아보기 (DIP)
어제 DDD특강을 듣고 튜터님께서 지난 프로젝트를 통해 DDD를 다시 한번 설명해주실 수 있다고 하셔서 저번 팀원들과 함께 튜터님 방에 다녀왔다.
튜터님께서는 우리가 먼저 뭐가 궁금한지 잘 표현하고 여쭤보지 못해도 가려운 부분을 긁어주시는 부분이 좋다.
1. DDD는 하루아침에 배우는 기술이 아니다
DDD는 단순한 아키텍처 패턴이 아니라
비즈니스 문제를 소프트웨어 구조로 표현하는 방법론이다.
도메인에서 관심을 가지는 영역과 비지니스적 문제가 계속 바뀌기 때문에
DDD 또한 계속 발전시키고 적용 방법을 연구해나가야한다.
따라서 지속적으로 공부해야 하고 프로젝트 경험 속에서 체화시켜 나가야한다.
특히 개발자 컨퍼런스나 실제 사례를 많이 참고해서 배워나는 것이 좋다.
2. 도메인은 회사의 관심사에 따라 변한다
도메인은 '비즈니스가 중요하게 생각하는 영역'이다.
예시
개인정보 유출 사건 발생 ->
회사 관심사 : 보안, 인증, 인가
이 영역이 '핵심 도메인' 으로 올라갈 수 있다.3. 모든 도메인이 동일하게 중요하지 않다 (Core / Supporting)
DDD Strategic Design
DDD에서는 도메인을 3가지로 나눈다.
| 종류 | 의미 | 배달앱 예시 |
|---|---|---|
| Core Domain | 회사의 핵심 경쟁력 | 상점, 메뉴 |
| Supporting Domain | 핵심을 지원 | 배달 |
| Generic Domain | 그냥 사다 쓰는 것 | 채널톡 상담, 결제 시스템, 로그 시스템 |
4. DDD의 핵심 목표
확장성
유연성
돈을 버는 비즈니스 로직은 가장 자주 변경된다.
그래서 비즈니스 로직을 기술에서 분리해야 한다.
5. DDD에서 가장 중요한 것은 확장성과 유연성
비즈니스와 기술을 분리하고
비즈니스 로직은 돈을 버는 로직이므로 언제든 변화 가능해야한다.
따라서 DIP를 통해 의존성을 끊어내는 것이다.
가장 큰 문제는 "도메인 의존성"
Order -> Product
Order가 Product 도메인을 직접 참조하면
Product 변경
→ Order 영향
도메인 간 결합도가 높아진다.+ 의존 관계:
import 문을 지워서 컴파일 에러발생
없으면 비즈니스를 이어나갈 수 없는 것.일반적인 구조에서는 OrderService가 ProductRepository나 ProductEntity 같은 구체적인 구현에 직접 의존한다.
이렇게 되면 Order 도메인이 Product 도메인의 내부 구조나 데이터 모델에 강하게 묶이게 된다. 그래서 Product 도메인의 구조가 바뀌거나 DB 구조가 변경되면 Order 도메인의 코드도 같이 수정해야 하는 상황이 생긴다.
즉, 비즈니스 로직이 기술이나 다른 도메인의 변화에 쉽게 영향을 받게 된다.
해결 방법 - DIP
DDD에서는 이를 해결하기 위해 Dependency Inversion Principle 을 사용해 구현체 대신 인터페이스에 의존하도록 구조를 바꾼다.
기존 구조
OrderService
-> ProductRepository
-> ProductEntityDDD 구조
OrderService
-> OrderProductReader (interface)구현
OrderProductReaderHttp
OrderProductReaderEvent
OrderProductReaderJpa예를 들어 Order는 Product의 구현을 직접 사용하는 대신 OrderProductReader 같은 인터페이스에만 의존한다.
인터페이스의 실제 구현은 HTTP 통신, 메시지 큐(Kafka), DB 조회 등 어떤 방식이든 될 수 있지만, 이런 기술적인 부분은 숨겨진다.
- Order 도메인이 의존성을 가진 Product 도메인의 정보를 가져오기 위한 인터페이스 생성 (Http /tcp / 이벤트)
public class OrderProductReaderImpl implements OrderProductReader {
@Override
public List<ProductDto> getProducts(List<UUID> productIds, UUID storeld) {
return List.of();
}- 그리고 Order는 그 인터페이스만을 의존하게 한다
(인터페이스와의 통신은 해당 도메인 엔티티가 아닌 Dto를 통한다.)
서비스 코드에는 순수한 비즈니스 로직만 남게 된다.
피드백 중 작성된 코드:
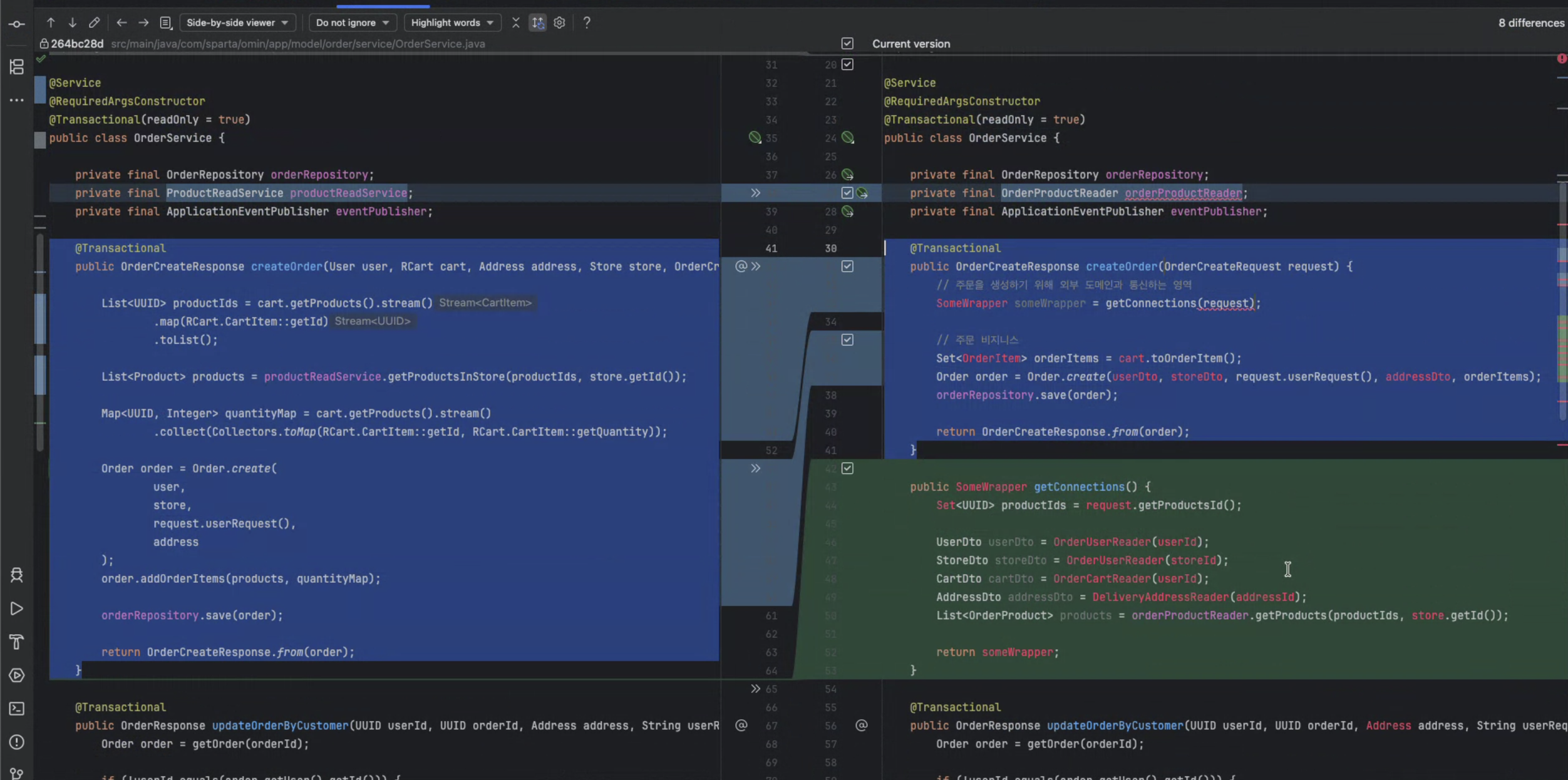
이렇게 하면 Order 도메인은 상품 정보를 가져온다는 비즈니스 기능만 알면 되고,
통신 방식이나 DB 구조 같은 기술적인 세부사항은 몰라도 된다.
DB가 바뀌거나, 다른 서비스와의 통신 방식이 HTTP에서 이벤트 기반으로 변경되어도 Order의 핵심 로직은 수정할 필요가 없다.
결과적으로 기술이 바뀌어도 비즈니스 로직은 그대로 유지된다.
(참고)좋은 시도:
기존의 application계층은 도메인 서비스.(같은도메인을 공유하는경우)
하지만 근본적인 의존관계를 해결하지 못한다.
6. 회사가 대신 성장시켜주지 않는다
응집도, 결합도를 따지고 클린코드, 디자인패턴 등을 실제 적용할 수 있는 단계에 이르러야 한다.
하지만 '돈을 버는 코드를 잘 쓰는 사람'이 필요한 회사는 이런 코드를 작성하는 것이 부담 될 수 있다.
현재 5년차 10년차 공고가 많은 이유가 바로 이 때문인데,
경기가 어려워 비즈니스 축소로 인해 3년차 성장 구간이 많이 사라졌다.
그래서 본인이 직접 주체적으로 시도를 해보는 개인의 공부와 성장이 중요하다.
7. 공부 방법
지금 배운 DDD 역시 전체 개념 중 일부일 뿐이며, 한 번에 모두 이해하기는 어렵다. 따라서 DDD를 공부할 때는 처음부터 모든 내용을 완벽히 이해하려 하기보다는 관심이 가는 주제나 필요한 개념부터 하나씩 읽어나가는 방식이 좋다.
1. 방법 (How)
실제 코드 구조와 구현 방법을 이해하는 것
-
DIP(Dependency Inversion Principle)
-
DDD 4계층 구조
2. 배경 (Why)
왜 이런 구조와 방법을 사용하는지에 대한 설계 개념
-
Bounded Context
-
애그리거트 분리
-
애그리거트 루트
-
데이터 생애주기 관리
-
애그리거트 간 결합도를 낮추기 위해 DIP나 이벤트 기반(Event Driven) 방식을 사용하는 이유
8. DDD 흐름 정리
(DIP는 도구고 진짜 목적은 도메인 경계 분리)
1. 도메인을 나눈다 (Bounded Context)
2. 애그리거트를 정의한다
3. 애그리거트간 의존성을 줄인다
4. DIP / 이벤트로 연결한다프로젝트 관리 심화
Docker
주요 키워드
이미지: 애플리케이션과 모든 실행에 필요한 파일을 포함한 읽기 전용 템플릿 (세이브 파일까지 포함한 게임 패키지)
컨테이너: 이미지를 실행하여 동작하는 애플리케이션 인스턴스
Dockerfile: 이미지를 생성하기 위한 명령어가 담긴 스크립트 파일
Docker Hub: 이미지를 저장하고 공유하는 중앙 저장소
볼륨: 컨테이너 데이터를 지속적으로 저장하는 메커니즘
네트워크: 컨테이너 간의 통신을 관리하는 방식
- Host Network (호스트 네트워크)
컨테이너가 호스트의 네트워크 스택을 직접 사용하는 네트워크
네트워크 격리가 없기 때문에 성능상 이점, 보안 및 네트워크 충돌 위험 단점docker run -d --network host nginx- Overlay Network (오버레이 네트워크)
여러 Docker 호스트에 걸쳐 있는 컨테이너를 연결할 때 사용
Swarm 모드나 Kubernetes 같은 오케스트레이션 도구와 함께 사용
데이터 센터 또는 클라우드 환경에서 분산 시스템을 구축할 때 유용- Bridge Network (브리지 네트워크)
기본적으로 Docker가 컨테이너를 실행할 때 사용하는 네트워크
동일한 브리지 네트워크에 연결된 컨테이너들은 서로 통신할 수 있다.
외부 네트워크와는 NAT를 통해 통신합니다.
일반적으로 단일 호스트에서 여러 컨테이너를 연결할 때 사용됩니다.
(명시하지 않으면 모두 브리지 네트워크에서 실행된다.)
docker network create my-bridge-network
docker run -d --name container1 --network my-bridge-network nginx
docker run -d --name container2 --network my-bridge-network nginxDocker vs 가상 머신
Docker
- 빠른 시작 시간과 낮은 오버헤드
애플리케이션만 실행하고, 운영 체제의 핵심 부분은 공유 - 높은 이식성과 확장성
개발 환경, 테스트 환경, 실제 운영 환경 모두에서 같은 방식으로 동작헤 여러 컨테이너를 쉽게 추가하고 관리하기 쉽다. - 보안 격리가 가상 머신보다 약함
하나의 컨테이너에서 보안 문제가 발생하면, 같은 커널을 공유하는 다른 컨테이너에도 영향을 줄 가능성 - 운영 체제 종속성 존재
Docker는 리눅스 커널을 사용하여 작동
(WSL(Windows Subsystem for Linux) 필요 등 호환성과 가상화 오버헤드 문제)
가상 머신
가상 머신(VM): 하이퍼바이저를 통해 물리적 하드웨어 위에 가상화된 운영 체제를 실행하는 기술
하이퍼바이저 : 여러 운영 체제를 동시에 실행할 수 있도록 물리적 하드웨어를 가상화하는 소프트웨어- 격리된 환경 제공
각 가상 머신은 완전히 독립된 운영 체제를 실행되어 다른 가상 머신이나 호스트 시스템에 영향을 주지 않음 - 다양한 운영 체제 실행 가능: 한 물리적 서버에서 여러 종류의 운영 체제를 동시에 실행할 수 있어 개발자나 테스트 팀은 다양한 환경을 쉽게 구축하고 사용 가능
단점 - 큰 오버헤드, 느린 부팅 시간: 가상 머신을 부팅할 때 운영 체제를 처음부터 시작해야 해서 시간이 오래 걸림
- 높은 리소스 소비: 가상 머신은 각기 독립된 운영 체제를 포함하므로, 여러 가상 머신을 실행하면 많은 메모리(RAM)와 CPU 자원을 소비
Docker는 언제 사용할까?
일관된 개발 환경이 필요할 때
애플리케이션을 빠르게 배포하고 싶을 때
마이크로서비스 아키텍처를 도입할 때
CI/CD 파이프라인을 구축할 때
리소스 효율성을 높이고 싶을 때
애플리케이션 격리가 필요할 때
쉽게 스케일링하고 싶을 때
쿠버네티스(Kubernetes)와 함께 사용하고자 할 때
Docker 명령어
이미지
# 이미지 빌드 (Build)
docker build -t <이미지이름>:latest .
# 현재 디렉토리의 `Dockerfile`을 기반으로 이미지를 생성
# -t 옵션을 사용하여 이미지의 이름과 태그를 입력
# 태그는 latest가 기본값
# 이미지 가져오기
docker pull postgres
# 이미지 목록 보기
docker images
# 이미지 삭제 (이름:태그 또는 이미지 ID 사용)
docker rmi myapp:latest
# 또는 ID 앞글자만 입력 (예: 1a2b...)
docker rmi 1a2b
# 사용하지 않는 모든 이미지, 컨테이너, 네트워크 한방에 청소
docker system prune컨테이너
# 컨테이너 실행 (Run)
# -d: 백그라운드 실행, -p: 호스트포트:컨테이너포트 매핑
docker run -d -p 8080:80 --name my-app myapp:latest
# 컨테이너 내부 접속 (쉘 환경 열기)
docker exec -it <컨테이너ID/이름> /bin/bash
# -i (interactive): 컨테이너의 표준 입력(STDIN)을 열어 컨테이너 내부에서 사용자 입력을 받을 수 있게 함
# -t (tty): 가상 터미널을 할당
# -it: 터미널 입력을 가능하게 함
# 실행 중인 컨테이너 목록 보기
docker ps
# 중지된 컨테이너 포함 모든 목록 보기 (-a: all)
# -l 마지막으로 실행된 컨테이너를 가장 먼저 나열.
docker ps -al
# 컨테이너 중지 및 시작
docker stop <컨테이너ID/이름>
docker start <컨테이너ID/이름>
# 컨테이너 삭제 (실행 중이면 삭제 불가, stop 후 삭제)
docker rm <컨테이너ID/이름>
# 실행 중인 컨테이너 강제 삭제
docker rm -f <컨테이너ID/이름>네트워크 및 볼륨
# 네트워크 생성 (컨테이너 간 통신용)
docker network create <네트워크이름>
# 네트워크 목록 및 삭제
docker network ls
docker network rm <네트워크이름>
# 볼륨 생성 (데이터 보존용)
docker volume create <볼륨이름>
# 볼륨 목록 및 삭제
docker volume ls
docker volume rm <볼륨이름>docker 사용
# -v (Volume): 호스트의 폴더와 컨테이너 폴더를 연결
# 해당 볼륨이 여러 컨테이너에서 공유될 수 있음을 표시
# :z (SELinux 옵션): 만약 호스트가 리눅스(SELinux)일 때, 파일 시스템 접근 권한 문제 안 생기게 딱지를 붙여준다(컨텍스트 설정).
docker run -d --name postgres-sample \
-p 5433:5432 \
-e POSTGRES_USER=admin1 \
-e POSTGRES_PASSWORD=admin2 \
-e PGDATA=/var/lib/postgresql/data/pgdata \
-v ${로컬_바인딩_폴더}:/var/lib/postgresql/data:z \
postgresMacOS - Permission denied
-v 옵션으로 호스트 폴더를 연결할 때 발생할 수 있는 에러
현상: 맥 보안관이 도커의 접근을 막음.
조치: 도커 설정에서 호환성이 높은 통신 방식(9p 또는 osxfs)으로 교체
결과: "아, 이 통신 방식은 내가 아는 거네" 통과 시켜줌
Docker compose
docker-compose.yml 파일 하나로 애플리케이션의 서비스, 네트워크, 볼륨 등을 정의하며 여러 컨테이너로 구성된 애플리케이션을 쉽게 관리하고 배포할 수 있다.
Docker 20.10부터는 Docker Compose가 기본적으로 설치된다.
version: '3' # Docker Compose 파일의 버전을 지정
services: # 애플리케이션의 각 서비스를 정의
web: # 서비스 이름- web
image: nginx # 서비스를 실행할 Docker 이미지를 지정
ports: # 호스트와 컨테이너 간의 포트를 매핑 호스트:컨테이너
- "8080:80"
app: # 서비스 이름- app
build: . # Dockerfile이 있는 디렉토리 경로를 지정하여 이미지를 빌드
ports:
- "8081:8080"
depends_on: # 다른 서비스가 먼저 실행되어야 하는 순서를 지정
- db
db: # 서비스 이름- db
image: postgres
environment: # 컨테이너의 환경 변수를 설정
POSTGRES_PASSWORD: example
networks:
default:
driver: bridge
Docker Compose에서 생성되는 네트워크
Docker Compose는 실행 시 기본적으로 user-defined bridge 네트워크를 생성하고,docker-compose.yml에 정의된 모든 서비스 컨테이너를 해당 네트워크에 연결한다.
이 네트워크를 통해 서비스 간에는 컨테이너 이름(서비스 이름)을 기반으로 통신할 수 있다.
이 네트워크는 docker-compose.yml 파일이 있는 디렉토리의 이름을 기반으로 생성된다.
<directoryname>_defaultDockerCompose 명령어
# docker-compose.yml 파일에 정의된 서비스를 빌드하고 시작
# 만약 이미 빌드된 이미지가 있다면 이를 사용
# -d 옵션: 백그라운드에서 실행
docker compose up -d
# -f 옵션: docker-compose 파일 경로 지정
# Compose 파일을 직접 지정하는 옵션이라서 파일 이름은 상관없다.
# -f 옵션 여러 개 사용해 설정 override도 가능하다.
docker compose -f /path/to/your/project/docker-compose.yml up -d
#실행 중인 모든 서비스를 중지하고 컨테이너, 네트워크, 볼륨 등을 정리
docker compose down
# docker-compose.yml 파일에 정의된 서비스를 빌드
docker compose build
# 현재 실행 중인 서비스를 확인
docker compose ps
# 실행 중인 서비스의 로그를 확인
docker compose logsDockerfile
# Java 11 실행 환경이 포함된 경량 OpenJDK 이미지를 베이스로 사용
FROM openjdk:11-jre-slim
# 호스트 로컬 파일 -> 컨테이너 파일
COPY target/myapp.jar /app/myapp.jar
# 이 이후 모든 명령은 /app 기준으로 실행
WORKDIR /app
# 컨테이너가 시작될 때 실행되는 기본 명령어
ENTRYPOINT ["java", "-jar", "myapp.jar"]튜터님의 가이드 들으면서 MSA 정리하기
MSA는 각 도메인을 각 서버로 나눠서 분리하는 것
SPOF 문제와 고가용성
SPOF (Single Point of Failure) 단일 장애 지점
시스템에서 하나의 컴포넌트가 죽으면 전체 서비스가 멈추는 구조
서비스 디스커버리
도메인이 다른 도메인의 정보를 필요로 할 때는?
어디에 있는지 어떻게 알아?
-> 서비스 디스커버리 (각 서버들의 위치를 알려주는 서버)
-> 유레카! 여기 있구나!
로드 밸런싱
사용자가 가장 많이 접속하는 도메인: 나 혼자 처리하기 힘든데;
또는 SPOF을 피하기 위해서
이 도메인 서버 여러개 둬요!
Scale-Out (수평 확장)
여러 서버에 요청을 분산
방법
- Round Robin
- Least Connection
- Weighted Round Robin
→ 로드밸런서
서버사이드 vs 클라이언트사이드 로드밸런싱
1. 서버사이드 로드밸런싱
Client → LoadBalancer → Server
Nginx
HAProxy
AWS ALB-> LoadBalancer 자체가 SPOF 될 수 있음
2. 클라이언트사이드 로드밸런싱
클라이언트가 서비스 목록을 알고 직접 선택
Client → Server
유레카로부터 서버 리스트를 받아
클라이언트가 직접 선택해서 요청
- Ribbon
- Spring Cloud LoadBalancer
게이트웨이
클라이언트가 필요한 정보를 얻기 위해 해당 서버에 직접 접근하지 않고, 게이트웨이를 통해서만 요청을 보내고 응답을 받게 한다.
게이트웨이 또한 서비스 디스커버리의 클라이언트이다. 하나의 서비스처럼 보일 수 있다.
MSA의 장점
하나의 언어로만 개발되어야 하는 모놀리스와 달리 서로 다른 서버가 다른 언어로 개발될 수 있음.
각 서비스가 API 명세만 잘 맞추면 통신을 할 수 있다.
서킷브레이커와 고가용성
MSA에서는 서비스 간 호출이 많다
A → B → C
C가 죽으면
B 대기
A 대기
→ 장애 전파->서킷브레이커: Resilience4j (close / half-open / open 상태로 눈치보면서 요청 응답)
서킷브레이커 추가 기능:
- Fallback 실패를 대체하는 대안 응답
- Bulkhead(격벽) 스레드풀 분리해서 장애 격리
Open Feign API 통신 vs 비동기 Message Broker
- OpenFeign (동기 통신)
서비스 간 REST API 호출을 쉽게 해주는 라이브러리.
요청을 보내고 응답을 받아 그에 대한 처리를 할때 사용
API 호출 문제 - 응답 대기
- 장애 전파
그래서 응답에 대해 따로 처리가 필요하지 않을 땐 이벤트 기반 아키텍처 메시징 시스템을 사용해 느슨한 결합을 이루고 비동기로 처리해 장애 전파를 감소시킨다.
CloudBus
RabbitMQ(메시징 특화) / Kafka (메시징 파이프라인 이벤트 스트리밍 플랫폼) / 둘 다 사용
분산 환경에서 중앙화된 서버 로그 확인
모니터링 해야할 것:
1. 서버의 건강 상태 (메트릭) 메모리 가용정보 등
2. 각 애플리케이션 내부에서 발생하는 로그
3. 이벤트 발생 로그
4. 분산 추적 (어떤 서버에 요청이 몰리고 병목현상이 일어나는지)
-> SpringBootActuator (애플리케이션 상태 확인)
-> PLG 스택 (Prometheus- 메트릭 수집, Loki- 로그 수집, Grafana- 시각화, 알림)
가볍고 빠르게 서버 상태와 로그를 연결해서 볼때 사용
-> ELK 스택 : logstash(+kafka로 로그 양이 많아 다운되는 것을 방지하기 위해 로그 분산해 수집하기도) 엘라스틱 서치 kibana 시각화
ELK 스택 (Elasticsearch-로그 저장/탐색, Logstash-로그 수집.변환, Kibana-시각화)
로그의 모든 내용을 낱낱이 파헤칠 때
분산 추적
Zipkin
힙 부족 문제 :
- MySQL
- Elastic Search
게이트웨이 로드밸런싱 (캐시 레이어)
Gateway 앞단에서 트래픽 제어
- Nginx
- HAProxy
인증을 어디서 할까?
보통 Gateway Filter에서 인증 처리를 하는데,
위험: 게이트웨이 뒷 단 서비스는 인증로직이 없어 무조건 보내는 정보를 믿게 된다.
1. 서비스가 항상 게이트웨이를 통해서만 접근할 수 있게 방화벽 설정을 해준다.
2. 인증 토큰을 헤더에 담아 뒷단에 보내고(Header Propagation), 뒷단에서는 헤더가 포함된 요청만 받아들인다.
3. 사설네트워크망 VPC(Virtual private cloud)
4. 쿠버네티스
5. ALB (필요할때만 포트를 연결해서 사용)
SSO (Single Sign On)
한 번 로그인으로 여러 서비스 이용하는 것
- Google 로그인
- OAuth2
- JWT
msa 구축 순서
1️⃣ Eureka (서비스 디스커버리)
2️⃣ Config Server (설정 관리)
3️⃣ API Gateway (인증 + 라우팅)
4️⃣ 각 도메인 서비스
5️⃣ Monitoring (Prometheus / Grafana)
프로젝트 시작 전 팀원들과 함께 인프라 구성을 같이 하면서 익히고 프로젝트를 시작하는 것을 추천하심.
