코드카타
삼총사 (숫자 배열에서 더해서 0 만들어지는 경우의 수 구하기)
주석과 같은 아이디어로 코드를 짰다.
class Solution {
public int solution(int[] number) {
int answer = 0;
// 앞 학생부터 차례로 가능한 조합 확인
// 이미 본 조합 가능? a b c -> b a c -> c a b 지나온 학생은 탐색 제외하기
int n = number.length;
for(int i = 0 ; i < n; i++) {
for(int j = i; j < n; j++) {
for(int k = j; k < n; k++) {
if(number[i] + number[j] + number[k] == 0) answer++;
}
}
}
return answer;
}
}하지만 인덱스 범위를 이렇게 정하면
for(int j = i; j < n; j++)
for(int k = j; k < n; k++)i == j == k 같은 학생 3번 선택되는 경우도 포함된다.
그래서 다음과 같이 고쳐야 했다.
i < j < k
그리고 불필요한 반복을 줄이기 위해(a,b,c 합을 구할 때 a 반복문에서는 무조건 뒤에 b, c 가 있으므로)
n-2, n-1 조건을 추가한다.
class Solution {
public int solution(int[] number) {
int answer = 0;
int n = number.length;
for(int i = 0; i < n - 2; i++) {
for(int j = i + 1; j < n - 1; j++) {
for(int k = j + 1; k < n; k++) {
if(number[i] + number[j] + number[k] == 0) {
answer++;
}
}
}
}
return answer;
}
}MSA 이벤트 통신 전략
1️⃣ 오케스트레이션 (Orchestration)
- 뜻: 지휘
- MSA에서 의미: 중앙에 있는 컨트롤러(Orchestrator)가 각 마이크로서비스에게 “언제, 뭘 해라” 하고 직접 지시해주는 방식.
- 비유: 오케스트라 지휘자가 악기마다 연주 타이밍과 순서를 다 알려주는 느낌.
- 특징: 중앙 집중형이라 서비스들은 지시받은 것만 수행, 스스로 판단은 안 함.
2️⃣ 코레오그래피 (Choreography)
- 뜻: 안무
- MSA에서 의미: 각 서비스가 자기 할 일을 알고, 다른 서비스와의 상호작용은 규칙이나 이벤트 계약에 맞춰 자연스럽게 발생
- 비유: 무용수들이 서로의 동작을 보면서 음악에 맞춰 움직이지만, 누가 일일이 지시하지는 않는 것과 같음
- 특징: 분산형, 이벤트 기반, 자율적 상호작용
관련 패턴
이벤트 기반 통신에서는 네트워크가 끊기거나, 서비스가 다운되거나, 재시도가 발생하면 같은 이벤트가 여러 번 처리될 수 있음
그래서 멱등성을 보장하기 위해 아웃박스/인박스 패턴을 사용한다.
- 아웃박스(Outbox): 이벤트를 보내는 쪽에서, 중간에 실패해도 다시 보낼 수 있도록 전송 기록을 남김
- 인박스(Inbox): 이벤트 받는 쪽에서, 중간에 실패해도 이벤트를 받았다는 기록을 남김
- 보상 트랜잭션(Compensating Transaction):
- 이미 처리된 작업을 취소하거나 되돌려야 할 때 사용
- 예: 결제 완료 후 배송 취소 → 결제 환불 처리
- 코레오그래피에서는 실패한 이벤트 처리나 비즈니스 실패 상황에서 각 서비스가 독립적으로 상태를 되돌리는 방식으로 구현됨
SpringBoot 에서 Redis 사용하기
프로젝트 생성
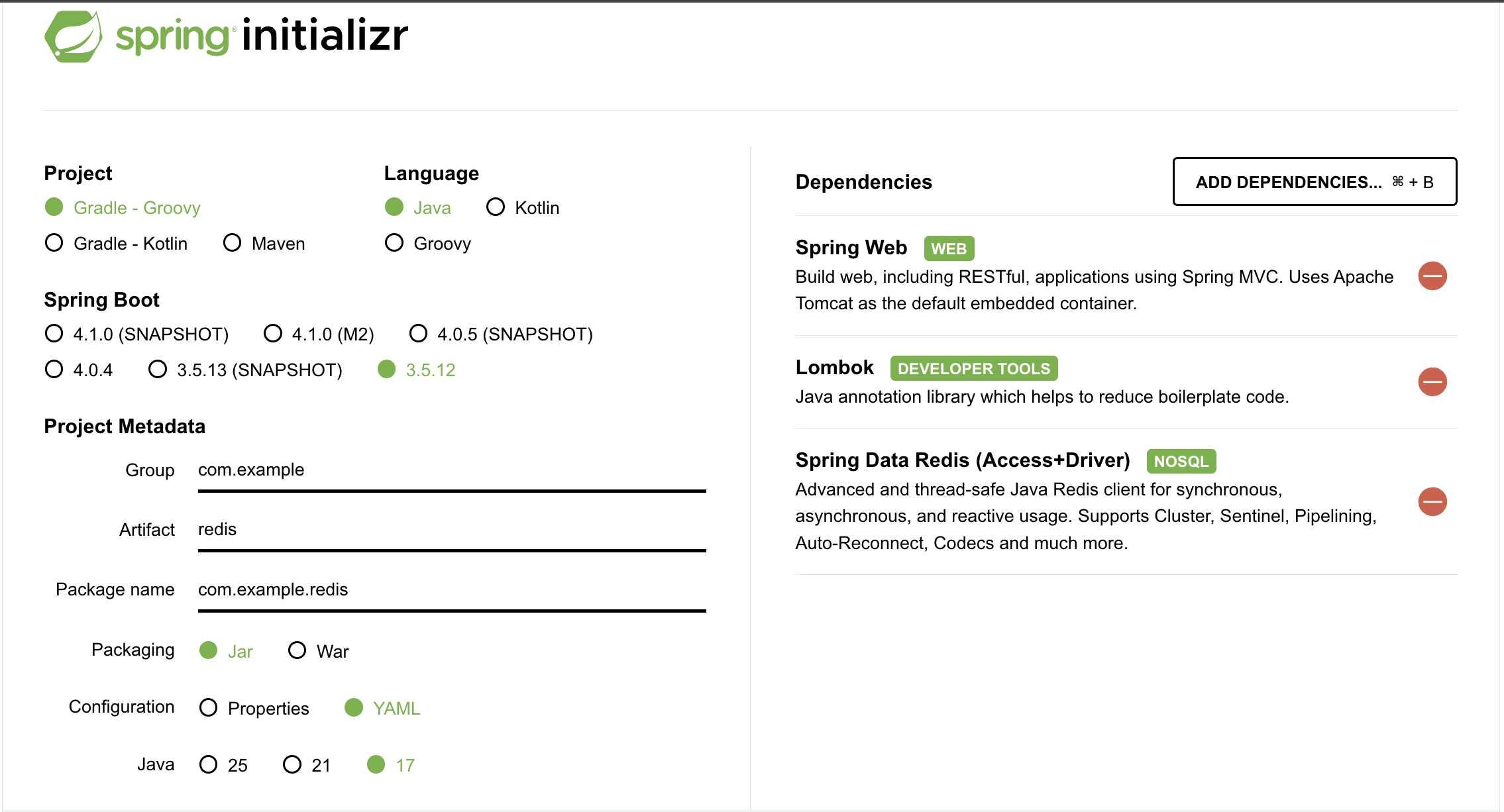

build.gradle
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
implementation 'org.springframework.boot:spring-boot-starter-web'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}application.yml
포트번호 : 6379
spring:
data:
redis:
host: <서버 주소 기본값 localhost>
port: <포트 번호>
username: <사용자 계정, 기본값 default>
password: <사용자 비밀번호>레디스에 데이터를 넣는 방식
추상화 수준
↑
Redis OM
Repository
RedisTemplate
↓
제어 수준1. RedisOM for Java
강의에선 소개되지 않았지만 공식문서를 찾아보다 발견했다.
Redis OM Spring은 Redis에서 제공하는 객체 매핑(Object Mapping) 라이브러리로
Spring Data Redis 위에서 동작하며 Redis 데이터를 ORM 방식으로 관리할 수 있게 해준다.
특징
- Redis JSON 기반 객체 저장
- Redis Search 기반 자동 Query
- Repository 스타일 Query 지원
주 사용 용도
- 검색 시스템
- 추천 시스템
- Redis JSON 데이터 저장
- Vector Search (RAG 등)
- Redis Stack 기능 활용
2. Spring Data - Repository Interface
Spring Data Redis가 제공하는 객체 중심 저장 방식
@RedisHash 엔티티와 Spring Data의 레포지토리 인터페이스CrudRepository를 사용하여 CRUD 중심으로 데이터를 관리한다.
메서드 호출이 내부적으로 Redis 명령으로 변환되어 실행된다.
주 사용 용도
- 장바구니
- 유저 환경 설정
- 세션 정보
- 간단한 상태 저장
특징
- JPA와 비슷한 개발 방식
- Redis Hash 기반 저장
- 복잡한 Redis 자료구조 활용에는 제한적
Redis에서는 @Entity 대신 @RedisHash 사용
Redis의 @RedisHash 애노테이션을 사용한 엔티티는, 저장 시 세트(Set)에 아이디 집합을 만들어지고, 각 아이디와 조합된 해시(Hash)에 실제 데이터가 들어가 관리된다.
keyspace:{index} Hash
item(keyspace) Set
┌───────┼────────┐
│ │ │
▼ ▼ ▼
item:1 item:2 item:3
Hash Hash Hash@RedisHash("item")
@NoArgsConstructor
public class Item implements Serializable {
@Id
private Long id;
private String name;
private String description;
private Integer price;
}Redis는 RDB와 달리 캐시, 세션, 토큰 등 임시 데이터를 저장하는 용도로
많이 사용되며, 여러 애플리케이션 서버에서 동시에 접근하는 경우가 많다.
이러한 분산 환경에서는 DB에 auto increment ID 생성을
요청하는 구조가 병목이 될 수 있기 때문에
애플리케이션에서 직접 생성할 수 있는 ID를 사용하는 경우가 많다.
따라서 대부분의 실사용 예시에서는 충돌 가능성이 거의 없는 UUID나
시간, 서버 ID, 시퀀스를 포함한 Snowflake ID와 같은
분산 환경에 적합한 ID 생성 방식을 사용하는 경우가 많다.
Redis Repository 구현 (CrudRepository 사용)
import org.springframework.data.repository.CrudRepository;
public interface ItemRepository extends CrudRepository<Item, Long> {}| 구분 | JpaRepository | CrudRepository |
|---|---|---|
| 소속 | Spring Data JPA | Spring Data Commons |
| 주 사용처 | RDB (MySQL, PostgreSQL 등) | Redis, MongoDB 등 |
| 기능 수준 | 많음 (확장형) | 최소 기능 |
| 쿼리 | JPQL / SQL 가능 | 거의 없음 |
| 페이징 | ✅ | ❌ |
| 정렬 | ✅ | ❌ |
| 배치 처리 | ✅ | ❌ |
상속구조:
CrudRepository
↑
PagingAndSortingRepository
↑
JpaRepository
CrudRepository 메서드:
<S extends T> S save(S entity);
Optional<T> findById(ID id);
Iterable<T> findAll();
void deleteById(ID id);
boolean existsById(ID id);사용 예제
import com.example.redis.Item;
import com.example.redis.ItemRepository;
@SpringBootTest
class RedisRepositoryTests {
@Autowired
private ItemRepository itemRepository;
@Test
public void createTest() {
Item item = Item.builder()
// @Id 필드를 Long 타입으로 두고 값을 직접 지정하지 않으면 Spring Data Redis는 Random 기반 Long 값을 생성한다.
//.id(1L)
.name("keyboard")
.price(1000000)
.description("Keyboard Is Expensive 😢")
.build();
itemRepository.save(item);
}
@Test
public void readOneTest() {
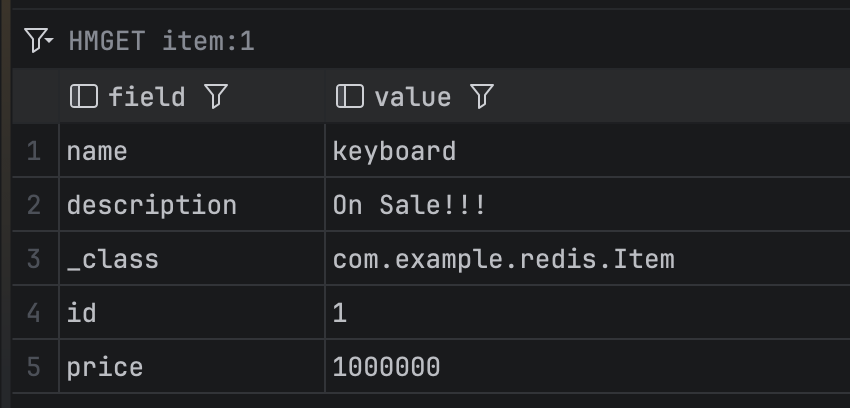
// HGETALL item:1
Item item = itemRepository.findById(1L)
.orElseThrow();
System.out.println(item.getDescription());
}
@Test
public void updateTest() {
Item item = itemRepository.findById(1L)
.orElseThrow();
item.setDescription("On Sale!!!");
itemRepository.save(item);
item = itemRepository.findById(1L)
.orElseThrow();
System.out.println(item.getDescription());
}
@Test
public void deleteTest() {
itemRepository.deleteById(1L);
}
}
Repository를 사용하면 Spring Data JPA와 유사하게 CRUD작업을 손쉽게 만들 수 있다.
반면, Redis의 다양한 자료구조를 활용한 복잡한 기능 구현에는 적합하지 않다.
List, Set, SortedSet 조합 로직
Pub/Sub, Stream 처리
Lua script 활용
복잡한 트랜잭션3. Redis Template
Class RedisTemplate
Spring Data Redis가 제공하는 Redis 데이터 접근 API이다.
Repository 방식보다 낮은 수준의 API로 Redis 명령과 자료구조를 직접 다룰 수 있다.
JdbcTemplate과 유사하게 Redis 명령을 직접 다루며 다양한 Redis 자료구조를 사용한다.
Repository 방식으로 구현하기 어려운 캐시, 랭킹 시스템, 작업 큐 등을 구현할 때 주로 사용된다.
주 사용 용도
- 캐시 저장
- 조회수 카운트
- 토큰 관리
- 랭킹 시스템
- Pub/Sub
- Stream 처리
특징
- Redis 명령을 세밀하게 제어할 수 있다.
String,List,Set,SortedSet,Hash등 모든 Redis 자료형을 정교하게 다룰 수 있고, Java 객체와의 직렬화/역직렬화도 지원된다.- 코드가 비교적 복잡해질 수 있음
1) 문자열 값을 저장
import java.util.concurrent.TimeUnit;
import org.springframework.data.redis.core.ListOperations;
import org.springframework.data.redis.core.SetOperations;
import org.springframework.data.redis.core.ValueOperations;
import org.springframework.data.redis.core.StringRedisTemplate;
@SpringBootTest
public class RedisTemplateTests {
@Autowired
private StringRedisTemplate redisTemplate;
@Test
public void stringOpsTest() {
// 문자열 조작 (String operation)을 위한 클래스
// ValueOperations<k, v>
ValueOperations<String, String> ops
// 지금 RedisTemplate에 설정된 타입 (String)을 바탕으로
// Redis 문자열 조작을 할거다.
= redisTemplate.opsForValue();
ops.set("simplekey", "simplevalue"); // SET simplekey simplevalue
System.out.println(ops.get("simplekey")); // GET simplekey
// 집합을 조작하기 위한 클래스
// SetOperations<k, v>
SetOperations<String, String> setOps
= redisTemplate.opsForSet();
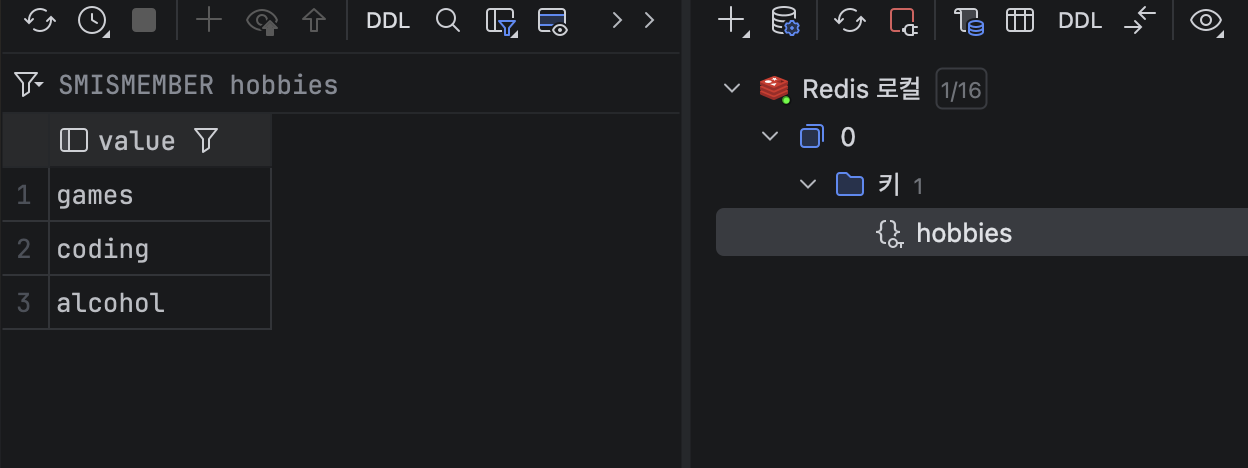
setOps.add("hobbies", "games");
// SADD hobbies games
setOps.add("hobbies",
"coding", "alcohol", "games"
);// SADD hobbies coding alcohol games
System.out.println(setOps.size("hobbies")); // 3
// SCARD hobbies
setOps.add("jobs", "job1", "job2", "job3");
// SADD jobs job1 job2 job3
System.out.println(setOps.members("jobs")); // [job1, job2, job3]
// SMEMBERS jobs
System.out.println(setOps.pop("jobs")); // job3
System.out.println(setOps.pop("jobs")); // job1
System.out.println(setOps.pop("jobs")); // job2
// SPOP jobs (랜덤하게 하나 추출 후 삭제; Set은 순서보장 x)
// 키에 대한 관리 : template
redisTemplate.expire("hobbies", 10, TimeUnit.SECONDS);
// EXPIRE hobbies 10
redisTemplate.delete("simplekey");
// DEL simplekey
ListOperations<String, String> listOps
= redisTemplate.opsForList();
listOps.leftPush("ate", "hamburger");
// LPUSH ate hamburger
listOps.leftPushAll("ate", "chicken", "pizza");
// LPUSH ate chicken pizza
System.out.println(listOps.getFirst("ate")); // pizza
// LINDEX ate 0 (또는 LRANGE ate 0 0)
System.out.println(listOps.getLast("ate")); // hamburger
// LINDEX ate -1
// 오바이트 🤮
System.out.println(listOps.leftPop("ate")); // pizza
// LPOP ate
// 소화 💩
System.out.println(listOps.rightPop("ate")); // hamburger
System.out.println(listOps.rightPop("ate")); // chicken
// RPOP ate
}
}
hobbies 정보는 stringRedisTemplate.expire()에 의해 10초 뒤에 만료되어 사라진다.
2) 직렬화된 객체를 값으로 저장
// @ToString // java 출력용 :com.example.redis.ItemDto@193f3306 -> ItemDto(name=Pretty Keyboard, description=LIT, price=250000)
@Builder
@AllArgsConstructor
@Getter
@NoArgsConstructor
// JSON 직렬화를 사용하기 때문에 Serializable 구현은 필수는 아님.
// 단, JdkSerializationRedisSerializer 등을 사용할 경우 필요할 수 있음.
public class ItemDto {
private String name;
private String description;
private Integer price;
}
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.RedisSerializer;
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, ItemDto> itemRedisTemplate(
RedisConnectionFactory connectionFactory
) {
RedisTemplate<String, ItemDto> template
= new RedisTemplate<>();
// 레디스 템플릿에 설정을 추가
template.setConnectionFactory(connectionFactory);
// 키 직렬화 방식 : 문자열
template.setKeySerializer(RedisSerializer.string());
// 값 직렬화 방식 : json
template.setValueSerializer(RedisSerializer.json()); // GenericJackson2JsonRedisSerializer 사용
return template;
}
}@Autowired
private RedisTemplate<String, ItemDto> itemRedisTemplate;
@Test
public void itemDtoOpsTest() {
ValueOperations<String, ItemDto> ops
= itemRedisTemplate.opsForValue();
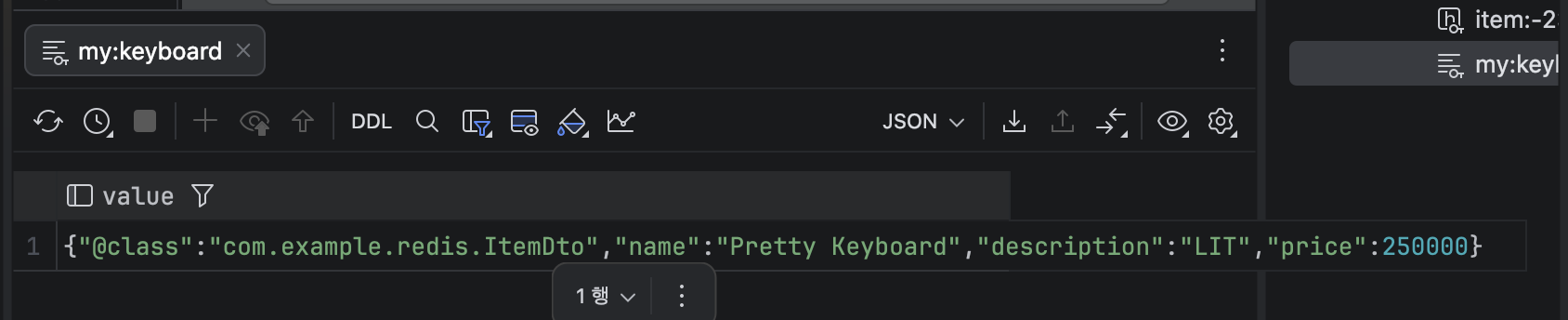
ops.set("my:keyboard", ItemDto.builder()
.name("Pretty Keyboard")
.price(250000)
.description("LIT")
.build());
// SET "my:keyboard" "{\"@class\":\"...ItemDto\",\"name\":\"Pretty Keyboard\",\"description\":\"LIT\",\"price\":250000}"
System.out.println(ops.get("my:keyboard"));
// GET "my:keyboard"
}
AI RAG 특강
LLM 한계와 극복
LLM의 한계
❗ 주요 문제
- 지식의 단절 (Cut-off) → 학습 이후 데이터는 모름, 최신 정보 부족
- 사실 오류 (Hallucination) → 틀린 내용을 그럴듯하게 생성
- 도메인 지식 부족 → 특정 산업/회사 데이터 반영 어려움
- 외부 데이터 접근 불가 → 비공개 내부 문서, DB 활용 못함
파인튜닝 (Fine-tuning)
- 기존 LLM + 새로운 데이터(지식) 학습
- 특정 도메인 성능 향상
- 모델 자체를 업데이트하는 방식
👉 "모델을 똑똑하게 만들기"
❗ 단점
- 학습 비용 큼 (시간/비용, 대규모 모델일수록 부담 ↑)
- 데이터가 추가되면 재학습 필요
- 최신 정보 반영이 어려움
RAG(Retrieval-Augmented Generation)
Retrieval (검색): 외부 데이터베이스나 문서에서 관련 정보를 찾아오고
Augmented (보강): 그 정보를 바탕으로
Generation (생성): 더 정확하고 풍부한 답변을 생성하는 방식👉 “모르는 건 찾아보고 답하는 AI”
RAG 핵심 구성 요소
1) 임베딩 모델 (Embedding Model)
텍스트를 숫자 형태(실수 벡터)로 변환
문장의 의미를 벡터 공간에 표현
“고양이” / “야옹이” → 비슷한 벡터
2) 외부 지식 저장소 (Vector Store)
임베딩된 데이터를 저장하는 공간
텍스트 → 벡터(숫자 배열) 형태로 저장
대표적인 저장소:
- Chroma (크로마)
- PGVector (PostgreSQL 기반)
- Elasticsearch
3) 질의 → 임베딩
사용자의 질문도 동일하게 임베딩 모델로 벡터화
(문서,질문 모두 벡터로 변환)
4) 유사도 검색 (Similarity Search)
질문 벡터와 가장 비슷한 문서 벡터를 찾는 과정
의미 기반 검색 (Semantic Search)
-
유클리디안 거리 (Euclidean Distance)
- 피타고라스 정리를 기반으로 한 거리 계산
- 벡터 간 직선 거리를 측정
- 값이 0에 가까울수록 유사함
- 주로 군집화(Clustering)에서 사용
-
코사인 유사도 (Cosine Similarity)
- 두 벡터의 각도(방향)를 기준으로 유사도 측정
- 값 범위: -1 ~ 1
- 1: 매우 유사
- 0: 무관
- -1: 반대 의미
- 텍스트/자연어 처리에서 가장 많이 사용됨
- 문장 길이보다 의미적 유사성을 잘 반영
5) RAG 성능 전략
청킹 전략 (Chunking Strategy)
- 긴 문서를 적절한 크기의 작은 단위(Chunk)로 나누는 과정
- LLM의 입력 길이 제한 때문에 설계됨
너무 길면 → 검색 정확도 ↓
너무 짧으면 → 문맥 손실 발생오버랩 (Overlap)
청크를 나눌 때 일부 내용을 겹치게 분할하는 방법
문맥이 끊기는 문제를 해결하기 위해 사용
Chunk1: A B C D
Chunk2: C D E FSpringBoot에서 RAG 프롬프트 사용해보기
build.gradle
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-thymeleaf'
implementation 'org.springframework.boot:spring-boot-starter-webflux'
implementation 'org.springframework.boot:spring-boot-starter-webmvc'
implementation 'org.springframework.ai:spring-ai-advisors-vector-store'
implementation 'org.springframework.ai:spring-ai-starter-model-openai'
implementation 'org.springframework.ai:spring-ai-starter-vector-store-pgvector'
implementation 'org.springframework.ai:spring-ai-rag'
implementation 'org.springframework.ai:spring-ai-jsoup-document-reader'
implementation 'org.springframework.ai:spring-ai-pdf-document-reader' // PDF 파일을 읽기 위한 PagePdfDocumentReader를 제공
implementation 'org.springframework.ai:spring-ai-tika-document-reader' // word(doc/docx), Power Point(ppt/pptx) 파일을 읽기 위한 TikaDocumentReader 제공
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
testCompileOnly 'org.projectlombok:lombok'
testAnnotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-thymeleaf-test'
testImplementation 'org.springframework.boot:spring-boot-starter-webflux-test'
testImplementation 'org.springframework.boot:spring-boot-starter-webmvc-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}docker-compose (pgvector)
services:
pgvector:
image: pgvector/pgvector:pg17
container_name: pgvector
ports:
- "5432:5432"
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_DB: postgress
volumes:
- pgdata:/var/lib/postgresql/data
networks:
- pg-network
volumes:
pgdata: # 로컬 볼륨 생성
networks:
pg-network:
driver: bridge docker compose up -d
[+] up 21/21
✔ Image pgvector/pgvector:pg17 Pulled 35.6s
✔ Network rag_pg-network Created 0.0s
✔ Volume rag_pgdata Created 0.0s
✔ Container pgvector Created 0.3s데이터 엔지니어링
- Offline (오프라인): 사용자 질문이 있기 전, 외부 소스로부터 데이터를 추출·변환하여 벡터 저장소(Vector Store)에 미리 적재하는 과정 (ETL 파이프라인)
- Runtime (런타임): 사용자가 질문하면 벡터 저장소에서 관련 데이터를 검색(Retrieval)하고, 이를 프롬프트에 포함(Augmentation)하여 LLM이 답변을 생성(Generation)하는 과정
ETL (Extract, Transform, Load)
파일 → 읽기 → 가공 → 벡터DB 저장
@Slf4j
@SpringBootTest
public class ETLTest {
@Autowired
ChatModel chatModel;
@Autowired
VectorStore vectorStore;
Resource textResource;
Resource docResource;
Resource pdfResource;
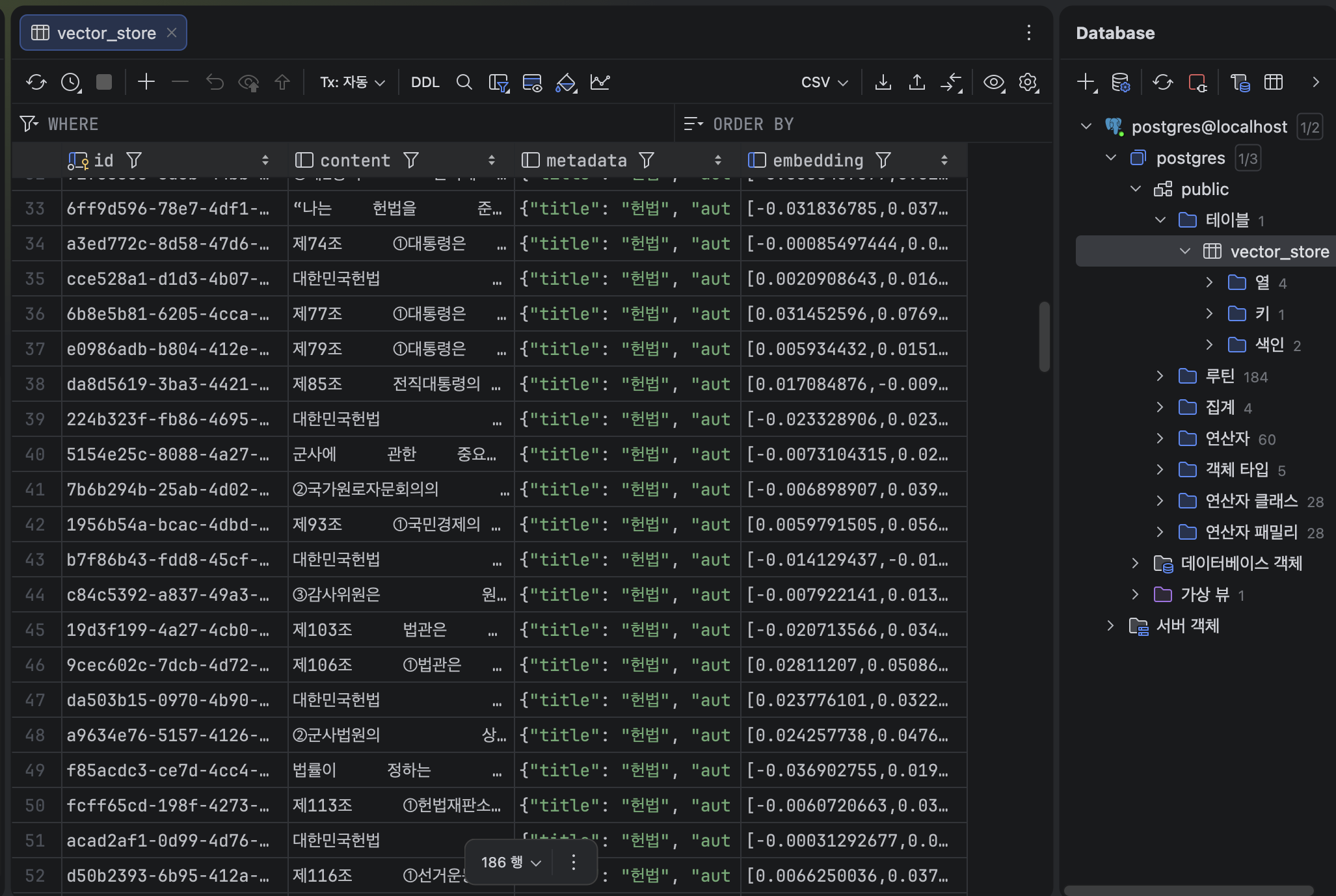
String title = "대한민국헌법";
String author = "법제처";
@BeforeEach
void init() {
String dir = <해당 파일 경로>;
textResource = new FileSystemResource(dir + "대한민국헌법(19880225).txt");
docResource = new FileSystemResource(dir + "대한민국헌법(19880225).docx");
pdfResource = new FileSystemResource(dir + "대한민국헌법(19880225).pdf");
}
@Test
@DisplayName("txt 파일")
void ETL_text() {
// E: 추출하기
DocumentReader reader = new TextReader(textResource);
List<Document> documents = reader.read();
log.info("추출된 Document 수: {} 개", documents.size()); // 추출된 Document 수: 1 개
// T: 메타데이터에 공통 정보 추가하기
for (Document doc : documents) {
Map<String, Object> metadata = doc.getMetadata();
metadata.putAll(Map.of(
"title", title,
"author", author,
"source", "대한민국헌법(19880225).txt"
));
}
// T: 작은 사이즈로 분할하기
documents = transform(documents);
log.info("변환된 Document 수: {} 개", documents.size()); // 변환된 Document 수: 25 개
// L: 적재하기
vectorStore.add(documents);
}
@Test
@DisplayName("docx 파일")
void ETL_docx() {
// E: 추출하기
DocumentReader reader = new TikaDocumentReader(docResource);
List<Document> documents = reader.read();
log.info("추출된 Document 수: {} 개", documents.size()); // 추출된 Document 수: 1 개
// T: 메타데이터에 공통 정보 추가하기
for (Document doc : documents) {
Map<String, Object> metadata = doc.getMetadata();
metadata.putAll(Map.of(
"title", title,
"author", author,
"source", "대한민국헌법(19880225).docx"
));
}
// T: 작은 사이즈로 분할하기
documents = transform(documents);
log.info("변환된 Document 수: {} 개", documents.size()); // 변환된 Document 수: 25 개
// L: 적재하기
vectorStore.add(documents);
}
@Test
@DisplayName("pdf 파일")
void ETL_pdf() {
// E: 추출하기
DocumentReader reader = new PagePdfDocumentReader(pdfResource);
List<Document> documents = reader.read();
log.info("추출된 Document 수: {} 개", documents.size()); // 추출된 Document 수: 14 개
// T: 메타데이터에 공통 정보 추가하기
for (Document doc : documents) {
Map<String, Object> metadata = doc.getMetadata();
metadata.putAll(Map.of(
"title", title,
"author", author,
"source", "대한민국헌법(19880225).pdf"
));
}
// T: 작은 사이즈로 분할하기
documents = transform(documents);
log.info("변환된 Document 수: {} 개", documents.size()); // 변환된 Document 수: 40 개
// L: 적재하기
vectorStore.add(documents);
}
// 작은 키워드로 분할하고 키워드 메타데이터를 추가하는 메서드
private List<Document> transform(List<Document> documents) {
List<Document> transformedDocuments = null;
// 작게 분할하기
DocumentTransformer splitter = new TokenTextSplitter();
transformedDocuments = splitter.apply(documents);
// 메타데이터에 키워드 추가하기
KeywordMetadataEnricher keywordMetadataEnricher = new KeywordMetadataEnricher(chatModel, 5);
transformedDocuments = keywordMetadataEnricher.apply(transformedDocuments);
return transformedDocuments;
}
}
@Slf4j
@SpringBootTest
public class ETLHTMLTest {
@Autowired
VectorStore vectorStore;
@Test
void etlTest() {
// E: 추출하기
String path = <파일 경로>.html;
String title = "대한민국헌법";
String author = "법제처";
Resource resource = new FileSystemResource(path);
JsoupDocumentReader reader = new JsoupDocumentReader(
resource,
JsoupDocumentReaderConfig.builder()
.charset("UTF-8")
.selector("#content")
.additionalMetadata(
Map.of(
"title", title,
"author", author,
"source", "대한민국헌법(19880225).html"
)
)
.build());
List<Document> documents = reader.read();
log.info("추출된 Document 수: {} 개", documents.size()); // 추출된 Document 수: 1 개
// T: 변환하기
DocumentTransformer splitter = new TokenTextSplitter();
List<Document> transformedDocuments = splitter.apply(documents);
log.info("변환된 Document 수: {}", transformedDocuments.size()); // 변환된 Document 수: 26
// L: 적재하기
vectorStore.add(transformedDocuments);
}
}
@Slf4j
@SpringBootTest
public class ETLJSONTest {
@Autowired
private VectorStore vectorStore;
@Test
void etlTest() {
// E: 추출하기
String path = "<파일경로>대한민국헌법(19880225).json";
String title = "대한민국헌법";
String author = "법제처";
Resource resource = new FileSystemResource(path);
JsonReader reader = new JsonReader(
resource,
new JsonMetadataGenerator() {
@Override
public Map<String, Object> generate(Map<String, Object> jsonMap) {
return Map.of(
"title", jsonMap.get("title"),
"author", jsonMap.get("author"),
"source", "대한민국헌법(19880225).json");
}
},
"date", "content");
List<Document> documents = reader.read();
log.info("추출된 Document 수: {} 개", documents.size()); // 추출된 Document 수: 12 개
// T: 변환하기
DocumentTransformer splitter = new TokenTextSplitter();
List<Document> transformedDocuments = splitter.apply(documents);
log.info("변환된 Document 수: {} 개", transformedDocuments.size()); // 변환된 Document 수: 31 개
// L: 적재하기
vectorStore.add(transformedDocuments);
}
}
Advisor
세부적인 질문을 프롬프트 컨텍스트에 포함시켜 더 정확한 답변을 하게 함
| 항목 | QuestionAnswerAdvisor | RetrievalAugmentationAdvisor |
|---|---|---|
| 구조 | 통합형 | 모듈형 |
| 난이도 | 쉬움 | 어려움 |
| 확장성 | 낮음 | 매우 높음 |
| 추천 상황 | 빠른 구현 | 실무/고급 |
Transformer
검색이 잘 되게 질문을 바꾸는 도구
| Transformer | 목적 | 특징 | 필수 조건 |
|---|---|---|---|
| Compression | 문맥 보완 | 대화 기반 | Memory Advisor 필요 |
| Rewrite | 질문 정제 | 노이즈 제거 | 없음 |
| Translation | 번역 | 언어 통일 | targetLanguage |
| MultiQuery | 확장 | 검색 범위 증가 | 비용 증가 |
