
코드카타
이상한 문자열 만들기
이상한 코드 만들기 (오답노트)
30분 간 노력은 했다... (코테 합격 <- 이거 다음 생 이야긴가요?😭)
class Solution {
public String solution(String s) {
String answer = "";
// StringTokenizer st = new StringTokenizer(s);
StringBuilder sb = new StringBuilder();
int j = 0; // 각 단어의 알파벳 인덱스
for(int i = 0; i < s.length(); i++) {
char c = s.getChar(i);
if(c == ' '){
sb.append(' ');
j = 0;
}else {
sb.append((j%2 == 0)?
c.toUpperCase():
c.toLowerCase()
);
j++;
}
}
return sb.toString();
}
}- StringTokenizer는 공백을 따로 처리해줘야해서 이 문제엔 적합하지 않다.
StringTokenizer st = new StringTokenizer(s, " ", true); // ["try", " ", " ", "hello"]- (내 머릿속 어디서 나온건지 감도 안 옴)
getChar()->String.charAt() s.toXCase->Character.toXCase(c)
class Solution {
public String solution(String s) {
String answer = "";
StringBuilder sb = new StringBuilder();
int j = 0; // 각 단어의 알파벳 인덱스
for(int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if(c == ' '){
sb.append(' ');
j = 0;
}else {
sb.append((j%2 == 0)
?Character.toUpperCase(c)
:Character.toLowerCase(c)
);
j++;
}
}
return sb.toString();
}
}String.toCharArray()
toCharArray() 메서드를 통해 반복문을 간소화 시키고,
j를 가독성 좋게 idx로 바꾼다.
조건문 idx++ % 2 == 0 에서 짝/홀 판단과 증가를 한 줄에 처리할 수 있다.
class Solution {
public String solution(String s) {
StringBuilder sb = new StringBuilder();
int idx = 0;
for (char c : s.toCharArray()) {
if (c == ' ') {
idx = 0;
sb.append(c);
} else {
sb.append(idx++ % 2 == 0
? Character.toUpperCase(c)
: Character.toLowerCase(c));
}
}
return sb.toString();
}
}Redis

Redis는 가장 대중적인 인메모리 데이터베이스이며, 일반적으로 관계형 데이터베이스에 저장하던 데이터를 RAM에 따로 저장하는 용도로 활용된다.
인메모리 데이터베이스 중에서 시장 점유율이 가장 높은 Redis이지만,
2024년 7월 기준, Redis는 오픈소스 라이선스에서 변경되어 더 이상 완전한 오픈소스가 아니며,(클라우드 서비스를 제공하는 업체에게 영향을 줌)
이에 따라 포크 프로젝트인 "Valkey"가 등장했고, AWS, Google, Oracle 등 참여로 빠르게 성장 중이다.
관계형 데이터베이스의 구조와 성능 한계
데이터 영속성에 따른 데이터 변경속도의 한계
대부분의 관계형 데이터베이스(예: MySQL, MariaDB, Oracle)는 데이터를 테이블 구조로 저장하며, 데이터의 영속성과 일관성에 초점을 맞추고,
일반적으로 파일 시스템(하드 드라이브 또는 SSD)에 데이터를 저장하므로 데이터 변경 속도가 상대적으로 느리다.
H2처럼 메모리에 데이터를 저장하는 예외적 관계형 데이터베이스도 있긴 하다.
관계형 데이터베이스 구조상 한계와 NoSQL의 특징
RDBMS
관계형 데이터베이스는 데이터의 일관성과 무결성을 보장하는 데 강점이 있지만,
처리해야 할 데이터 규모가 커지고 형태가 다양해지면서 몇 가지 한계가 드러나기 시작했다.
데이터가 미리 정의된 스키마에 따라 저장되기 때문에 구조가 자주 변경되거나 비정형 데이터(JSON 등)를 다루는 데에는 상대적으로 유연성이 떨어진다.
또한 강한 일관성을 유지하기 위한 설계로 인해 수평적 확장(scale-out)에도 제약이 있는 편이다.
NoSQL
이러한 배경에서 NoSQL에 대한 관심이 높아졌다.
NoSQL은 다양한 저장 방식을 통해 확장성과 유연성을 중심으로 설계된 데이터베이스이다.
일부 경우에는 전통적인 관계형 데이터베이스보다 일관성을 완화하는 대신, 대규모 데이터를 빠르게 처리하는 데 초점을 둔다.
NoSQL의 주요 데이터 모델
-
Key-Value
가장 단순한 형태로, 하나의 Key에 하나의 Value를 저장한다.
JSON이나 Python의 Dictionary, Java의 Map과 유사한 구조로 이해할 수 있다.
대표 예: Redis -
Document
Document라는 단위(JSON, XML 등)로 데이터를 저장하며, 구조가 유연하다.
Key-Value 구조에서 발전한 형태로, 복잡한 객체를 그대로 저장할 수 있다.
대표 예: MongoDB -
Column-Family
각 Row마다 Column이 고정되어 있지 않고, 필요한 컬럼을 동적으로 저장한다.
대규모 분산 환경에서 높은 성능을 내도록 설계된 모델이다.
대표 예: Apache Cassandra
학부 시절 사물인터넷(IoT)을 전공하면서 주로 Document DB를 사용했었다.
센서 데이터처럼 구조가 일정하지 않고, JSON 형태로 유연하게 데이터를 저장해야 하는 경우가 많았기 때문이라고 생각한다.
Redis는 언제 사용?
Redis는 NoSQL 계열의 Key-Value Store로,
메모리에 데이터를 저장하여 매우 낮은 지연 시간(latency)과 빠른 읽기/쓰기 성능을 제공한다.
이러한 특성 때문에 Redis는 영구 저장보다는 빠른 접근이 중요한 데이터,
또는 변경이 잦고 일시적인 성격의 데이터를 다루는 데 적합하다.
또한 단순한 Key-Value 저장을 넘어 다양한 자료구조(List, Set, Sorted Set 등)를 지원하여 실시간 처리나 고성능이 요구되는 기능 구현에 널리 활용된다.
- Session Clustering: 여러 애플리케이션 인스턴스에서 같은 세션 정보를 사용할 수 있도록 도와준다. (서버 scale-out)
- Caching: 자주 조회되는 데이터를 Redis에 캐싱하여 DB 접근을 줄이고 전체 응답 속도를 개선한다.
- 장바구니 (데이터 유실 가능성을 고려하여 DB와 함께 사용)
- 조회수(쓰기 요청이 빈번한 데이터를 Redis에 먼저 저장하고, 이후 비동기적으로 DB에 반영)
- 리더보드 (
Sorted Set자료구조) - 좌표 기반 검색 (
Geo자료구조)
Redis native 설치
강의에서는 Redis의 native 설치 방법을 다루었지만, 로컬 환경에 직접 설치할 경우 삭제가 완전히 이루어지지 않거나 백그라운드에서 프로세스가 계속 실행되는 등 관리가 번거로울 수 있다고 하셨다.
그래서 이 부분은 강의를 한 번 보고 넘어가기로 했다.
+ 근데 그냥 별거 아니었다! :
% brew uninstall redis
If desired, remove them manually with 'rm -rf':
/opt/homebrew/etc/redis-sentinel.conf
/opt/homebrew/etc/redis.conf
$ sudo systemctl stop redisWindows
Windows에서는 Redis를 직접 설치하는 방식이 공식적으로 지원되지 않기 때문에, 주로 WSL(Windows Subsystem for Linux) 환경에서 설치하여 사용한다.
-
WSL 설치 후 Ubuntu 환경 실행
-
패키지 관리자(APT)를 통해 Redis 설치
-
service redis-server start로 실행
macOS
-
macOS에서는 Homebrew를 사용하여 간단하게 설치할 수 있다.
-
brew install redis로 설치 -
brew services start redis로 백그라운드 실행
Docker를 이용한 Redis 설치
Docker를 사용하면 별도의 설치 과정 없이 컨테이너로
Redis를 빠르게 실행할 수 있다.
특히 Redis 공식에서는 Redis Stack 이미지 사용을 권장하며,
이는 JSON, Graph 등 다양한 기능과 함께
관리 도구인 Redis Insight를 제공한다.
+ 강사님 화면이랑 달라져서 조금 당황했는데,
설치 페이지에서 제품 선택 → 제품별 설치 페이지 로 바뀌어 있었다.
Redis Docker 이미지 종류
-
redis
→ 가장 기본적인 Redis 서버 (가벼운 실습용) -
redis/redis-stack-server
→ Redis + 확장 기능 (JSON 등), Insight 없음 -
redis/redis-stack
→ Redis + 확장 기능 + Redis Insight 포함 (권장)
+Redis Insight : redis 전용 IDE?
실행 방법 (Docker Compose)
-
Redis 서버 실행
-
기본 포트:
- Redis:
6379 - Insight:
8001
- Redis:
--requirepass 옵션으로 비밀번호 설정 가능
redis는 기본 사용자 이름이 default
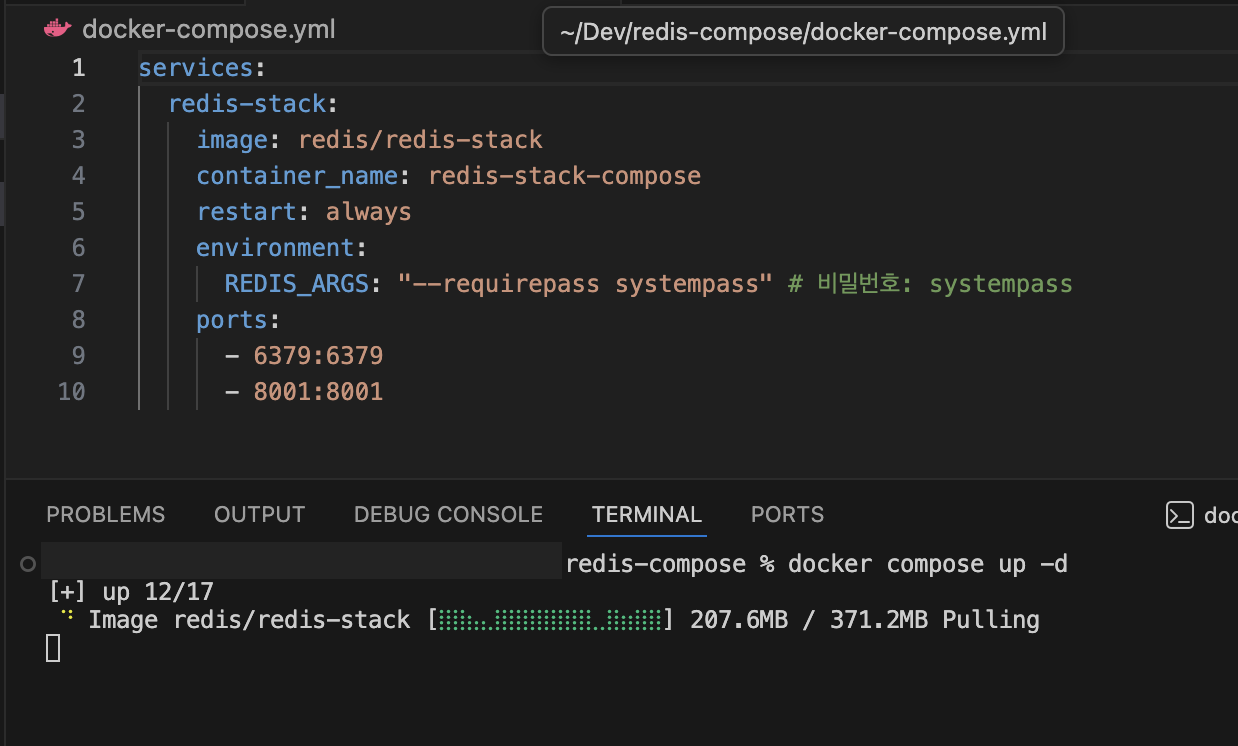
docker compose up -d실행 확인
현재 compose 프로젝트에 속한 컨테이너만 조회
docker compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
redis-stack-compose redis/redis-stack "/entrypoint.sh" redis-stack About a minute ago Up About a minute 0.0.0.0:6379->6379/tcp, [::]:6379->6379/tcp, 0.0.0.0:8001->8001/tcp, [::]:8001->8001/tcpRedis 접속하기
InteliJ로 접속하기
(생략)
Docker exec로 Redis접속하기 (redis-cli)
docker exec -it <컨테이너> /bin/bash# redis-cli
127.0.0.1:6379> AUTH systempass
# redis-cli -a systempass
127.0.0.1:6379>
# redis-cli -u redis://:systempass@localhost:6379
127.0.0.1:6379>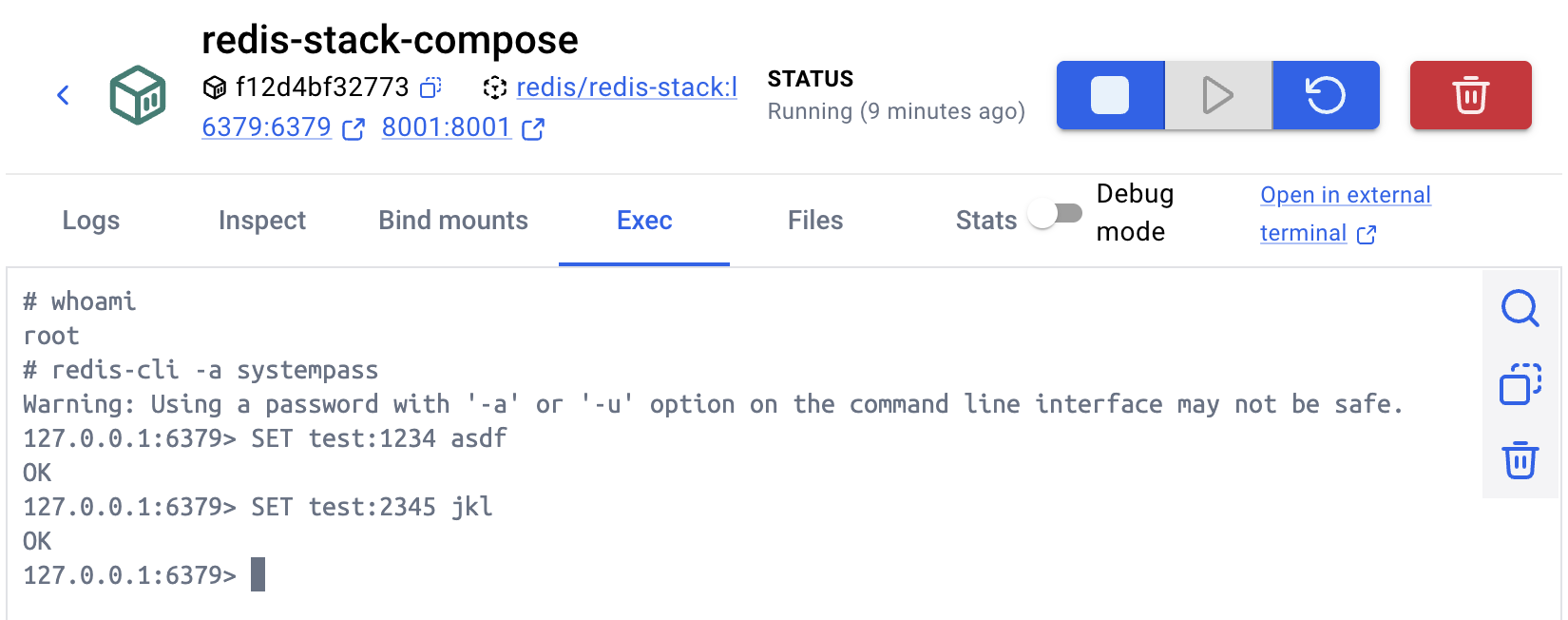
Redis Insight 사용하기
Redis Insight는
Redis 데이터를 시각적으로 관리할 수 있는 공식 GUI 도구이다.
주요 기능:
- Key-Value 데이터 시각화
- 명령어 실행
- 샘플 데이터 제공
- 여러 Redis 인스턴스 관리
설치 방법:
- App Store / Microsoft Store
- 설치 파일 (DMG, exe 등)
- Docker
Docker로 Redis Insight 실행
docker run -d --name redisinsight -p 5540:5540 redis/redisinsight:latest해당 컨테이너와 매핑된 호스트 포트로 브라우저 접속:
http://localhost:5540- Redis와 Insight를 별도 컨테이너로 실행할 경우
→ 기본적으로 서로 통신 불가하다. (Docker 네트워크 설정 필요)
Redis Stack 사용 시
이미 redis/redis-stack 컨테이너를 사용 중이라면
Redis Insight가 포함되어 있으므로
별도의 Redis Insight 컨테이너를 실행할 필요가 없다.
브라우저 접속:
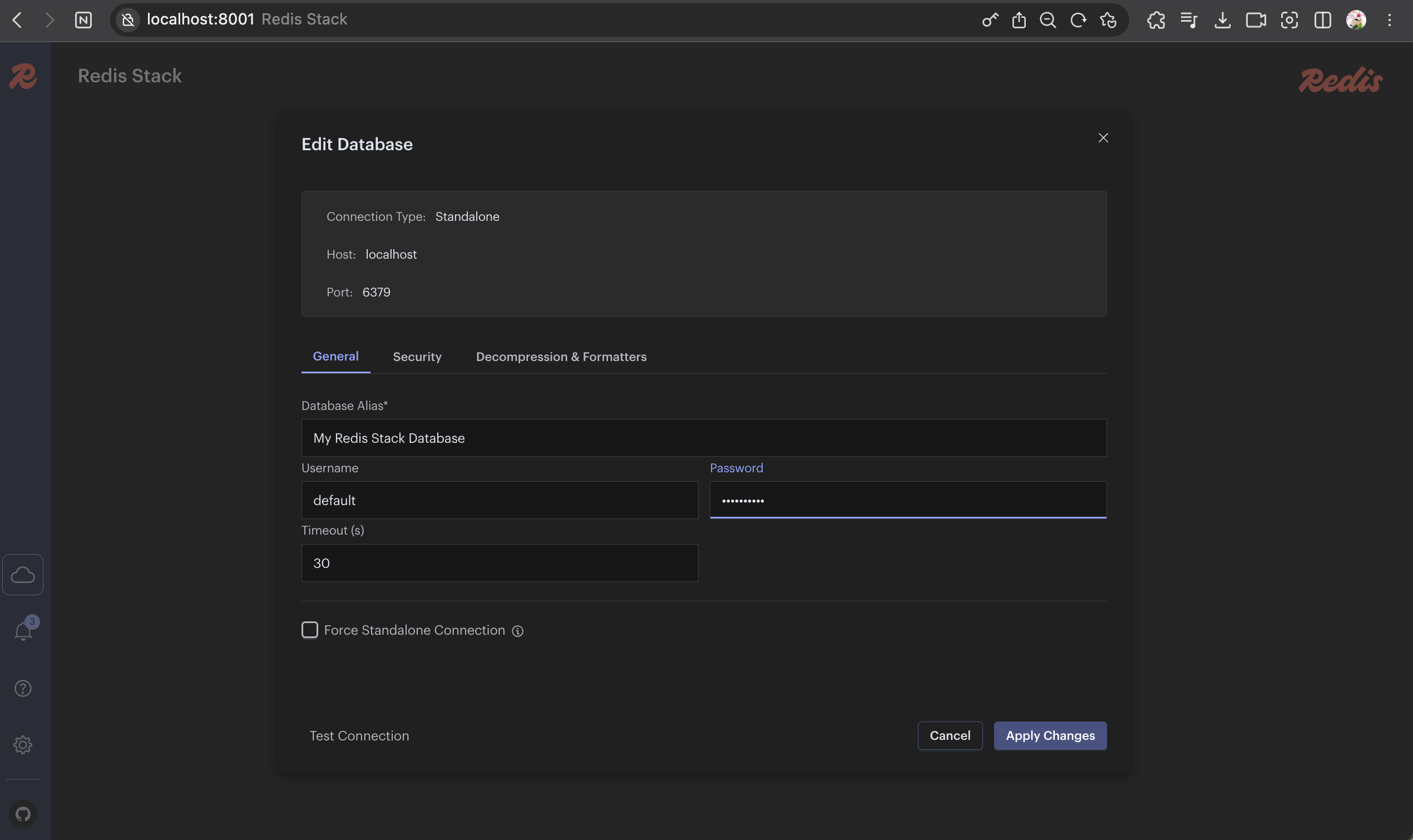
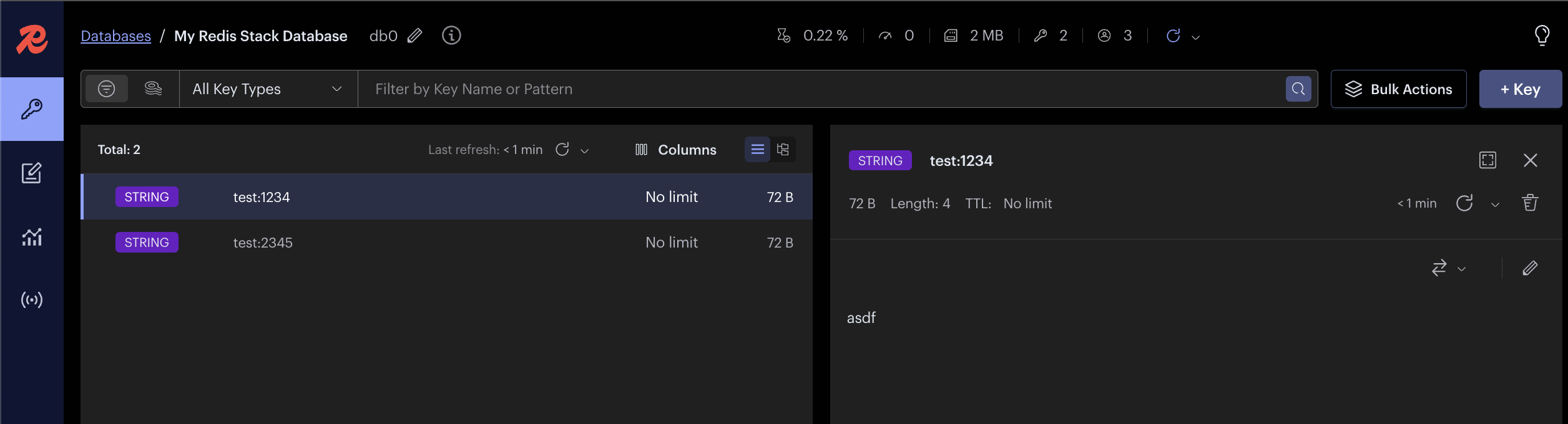
Workbench나 redis-cli를 사용할 수 있다.
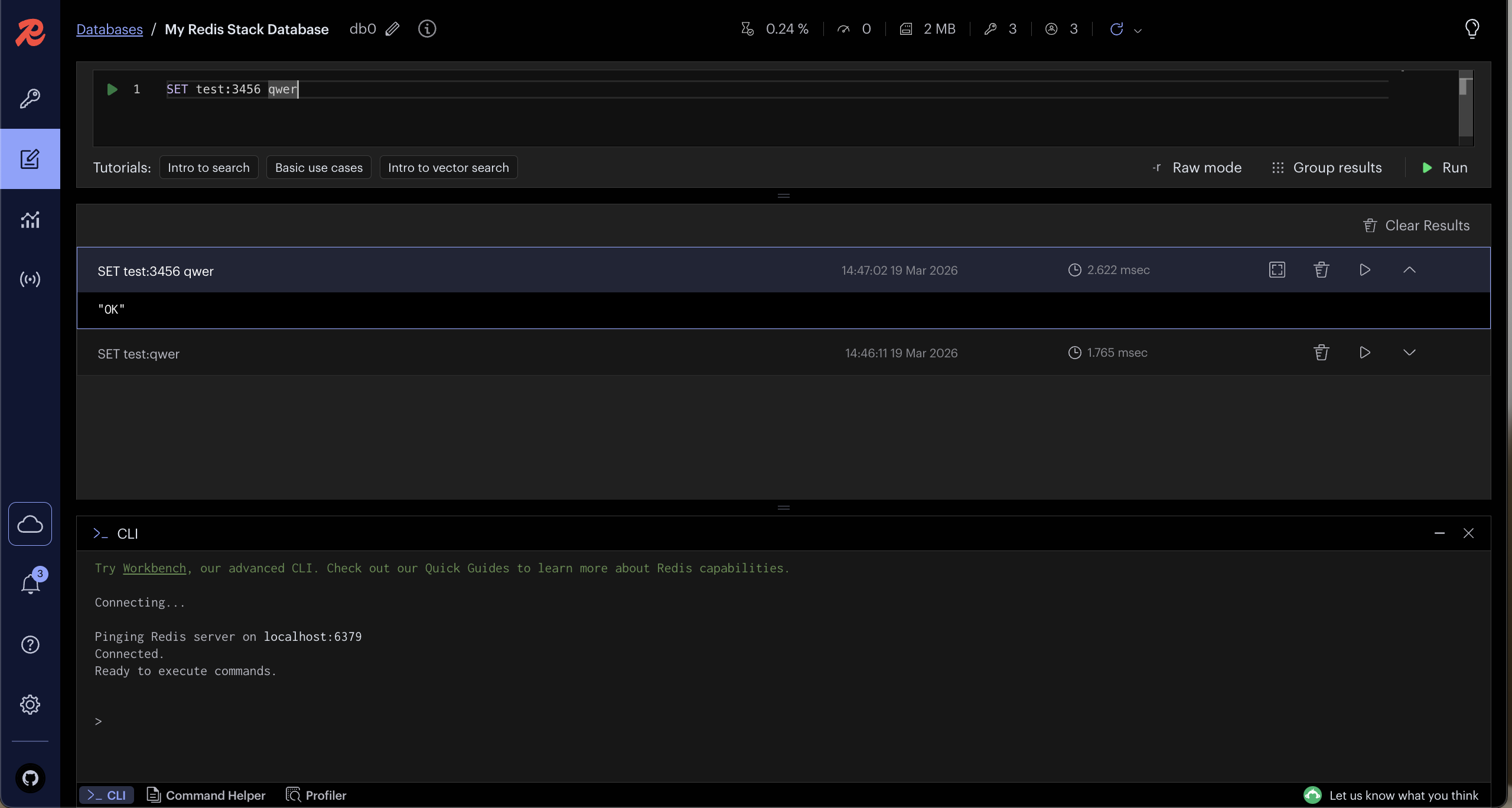
사이드바 메뉴
-
열쇠 아이콘 🔑
Databases / 연결된 Redis 데이터베이스 목록으로 이동
여기서 DB 연결 추가/삭제, 연결 정보 확인 가능 -
연필 아이콘 ✏️
Query Editor: 명령어 입력창
실제 Redis 명령어 작성하고 실행하는 공간 -
그래프 아이콘 📊
Analytics / Insights: Redis 데이터 분석, 키/메모리 사용 통계, 패턴 시각화 등 -
Wi-Fi 같은 아이콘
Pub/Sub 또는 Streams 모니터링 기능
Redis의 실시간 이벤트, 메시지 스트림 모니터링 가능
쿼리 입력창
- 한 줄씩 입력할 수 있고, 여러 줄도 입력 가능
- 입력된 명령어 앞에 있는 초록색 화살표 ▶️
- 각 줄 별 실행 버튼 역할
- 클릭하면 해당 줄만 서버에 전송 → 실행 결과 하단에 표시
- 줄 단위로 별도 실행이 가능하므로, 키보드 단축키 안 먹힐 때도 마우스로 한 줄만 실행 가능
에디터 하단 옵션
-
Raw Mode (-r)
결과를 원본 Redis 응답 형태 그대로 보여줌
예: 문자열, 리스트, 해시 등 Redis 내부 포맷 그대로 출력
체크 해제 시 사람이 보기 좋은 형태로 가공해서 표시 -
Group Results
한 번에 여러 명령어를 실행했을 때 결과를 그룹별로 묶어서 표시
예: 여러 GET 명령어를 연속 실행 → 각 결과별로 구분 가능 -
Run 버튼 (우측 하단 초록색 ▶️)
선택 여부 상관없이 전체 입력창 실행
키보드 단축키가 안 되는 경우 클릭해서 실행 가능
하단 결과창
-
각 명령어 실행 결과가 별도의 카드 형식으로 표시.
-
결과 카드 오른쪽 아이콘들:
</>: 결과를 코드 형태로 복사- 네모 겹친 아이콘: 전체 화면 모드로 확대
- 휴지통 아이콘: 해당 결과 삭제
- ▶️: 해당 명령어 재실행
- ↑: 결과 카드 접기/펼치기
로컬이 아닌 외부 레디스에서 insight 사용 방법
- SSH 터널링으로 외부 포트를 로컬호스트 포트에 연결
ssh -i 키.pem -L 8001:localhost:8001 ubuntu@서버IP- Redis Insight 앱 설치해서 사용
Add connection details manually메뉴를 통해 연결 정보를 입력해 접속한다.
Redis 자료형
"WRONGTYPE Operation against a key holding the wrong kind of value"
Redis에서는 어떤 명령어를 사용했는지에 따라 key의 자료형이 정해지고,
이후 사용 가능한 명령어도 그 자료형에 따라 달라진다.
String
Map<String, String>
- 기본 명령어:
SET/GET
# SET <key> <value>
# Redis key 관습적으로 논리적 구분을 위해 : 사용, 하나의 문자열임
# key에 value 문자열 데이터를 저장 (공백으로 구분)
SET user:email alex@example.com
# GET <key>
# key에 저장된 문자열 값을 반환
GET user:email- 문자열이지만 정수 연산(
INCR/DECR) 가능:
# 초기 값 설정 (문자열이지만 정수 형태로 저장)
SET user:count 1
# INCR <key>
# key에 저장된 값을 1 증가 (Increase)
INCR user:count
# DECR <key>
# key에 저장된 값을 1 감소 (Decrease)
DECR user:count- 다중 데이터 처리:
MSET/MGET
# Multi (여러 개)
# MSET key value [key value ...]
# 여러 key-value 데이터를 한 번에 저장
MSET user:name alex user:email alex@example.com
# MGET key [key ...]
# 여러 key에 해당하는 값을 한 번에 조회
MGET user:name user:email💡 핵심 포인트 (요약)
Redis String = Map<String, String> 구조
key는 식별자, value는 실제 데이터
문자열이지만 정수 연산(INCR/DECR) 가능
여러 데이터는 MSET / MGET으로 효율 처리
내부적으로는 바이트 배열 → 파일/이미지 저장 가능
인코딩을 사용해 이미지, 파일 등을 저장하기도 한다. (512MB)List
Map<String, List<String>>
1. 기본 명령어: LPUSH / RPUSH / LPOP / RPOP
Redis List는 Linked List 구조
# → 양쪽 끝에서 데이터 추가/삭제가 빠름 (스택/큐처럼 사용)
# LPUSH <key> <value>
# 리스트의 왼쪽(앞)에 데이터 추가
LPUSH user:list alex # 결과: [alex]
# LPUSH <key> <value>
# 다시 왼쪽에 추가 (앞에 쌓임)
LPUSH user:list brad # 결과: [brad, alex]
# RPUSH <key> <value>
# 리스트의 오른쪽(뒤)에 데이터 추가
RPUSH user:list chad # 결과: [brad, alex, chad]
# RPUSH <key> <value>
# 뒤쪽에 계속 추가
RPUSH user:list dave # 결과: [brad, alex, chad, dave]
# LPOP <key>
# 리스트의 왼쪽(앞)에서 값을 반환하고 제거
LPOP user:list # 반환: brad
# RPOP <key>
# 리스트의 오른쪽(뒤)에서 값을 반환하고 제거
RPOP user:list # 반환: dave- 리스트 조회:
LLEN/LINDEX/LRANGE
# LLEN <key>
# 리스트의 길이 반환
LLEN user:list
# LINDEX <key> <index>
# 특정 인덱스 값 조회 (삭제 X)
# 존재하지 않으면 null 반환 (nil)
# 맨 앞 (LPOP 대신 확인용)
LINDEX user:list 0
# 맨 뒤 (RPOP 대신 확인용)
LINDEX user:list -1
# LRANGE <key> <start> <end>
# start부터 end까지 범위의 요소 반환 (0부터 시작)
LRANGE user:list 0 3
# LRANGE <key> 0 -1
# 전체 리스트 조회 (-1은 마지막 요소 의미)
LRANGE user:list 0 -1
# - 존재하지 않는 key → LLEN = 0, LRANGE = 빈 리스트 반환
# - 다른 자료형 key → 오류 발생
# - start > end → 빈 리스트 반환
# - end가 길이를 초과해도 오류 없음
# - 음수 인덱스 → 뒤에서부터 접근 (-2 = 뒤에서 두 번째)💡 핵심 포인트 (요약)
Redis List = Map<String, List<String>>
Linked List 구조 → 양끝 처리에 최적화
주요 사용 패턴
스택 (LPUSH + LPOP)
큐 (LPUSH + RPOP 또는 RPUSH + LPOP)
범위 조회 가능 (LRANGE)
길이 조회 가능 (LLEN)
🚀 활용 예시
최근 게시글 목록
메시지 큐
소셜 서비스에서 활용 - 타임라인 (예: X (구 Twitter))Set
Map<String, Set<String>>
1. 기본 명령어: SADD / SREM / SMEMBERS / SISMEMBER / SCARD
# Redis Set은 문자열의 집합
# → 중복 허용 ❌, 순서 없음
# → 내부적으로 매우 빠른 연산 지원
# SADD <key> <value>
# 집합에 값 추가 (중복이면 무시됨) SET ADD
SADD user:java alex # 결과: [alex]
SADD user:java brad # 결과: [alex, brad]
SADD user:java chad # 결과: [alex, brad, chad]
# SREM <key> <value>
# 집합에서 특정 값 제거 (REMOVE)
SREM user:java alex # 결과: [brad, chad]
# SMEMBERS <key>
# 집합의 모든 원소 반환
SMEMBERS user:java # 결과: [brad, chad]
# SISMEMBER <key> <value>
# 특정 값이 집합에 존재하는지 확인 (O(1))
SISMEMBER user:java brad # true
SISMEMBER user:java dave # false
# SCARD <key>
# 집합의 크기(원소 개수) 반환 (CARDINALITY)
SCARD user:java- 집합 연산:
SINTER/SUNION/SINTERCARD
# 다른 Set 생성
SADD user:python alex
SADD user:python dave
# SINTER <key1> <key2>
# 두 집합의 교집합 반환 (Intersection)
SINTER user:java user:python # 결과: [alex]
# SUNION <key1> <key2>
# 두 집합의 합집합 반환 (Union)
SUNION user:java user:python # 결과: [alex, brad, chad, dave]
# SINTERCARD <numkeys> <key1> [key2 ...]
# 여러 집합의 교집합 원소 개수 반환
SINTERCARD 2 user:java user:python # 결과: 1💡 핵심 포인트 (요약)
Redis Set = Map<String, Set<String>>
중복 제거 자동 처리
순서 없음
포함 여부 확인 (SISMEMBER) → O(1) 매우 빠름
집합 연산 지원 (교집합, 합집합 등)🚀 활용 예시
방문자 중복 제거 (url 키 , set 요소: 방문자)
좋아요 누른 사용자 목록
JWT 토큰 블랙리스트
태그/카테고리 관리Hash
Map<String, Map<String, String>>
1. 기본 명령어: HSET / HGET / HMGET / HGETALL / HKEYS / HLEN
# Redis Hash는 field-value 구조 → 하나의 key 아래 여러 속성 저장 가능
# HSET <key> <field> <value> [field value ...]
# Hash에 field-value 쌍 저장 (여러 개 한 번에 가능)
HSET user:alex name alex age 25
HSET user:alex major CSE
# HGET <key> <field>
# 특정 field의 value 조회 (없으면 null)
HGET user:alex name
HGET user:alex age
# HMGET <key> <field> [field ...]
# 여러 field의 value 한 번에 조회
HMGET user:alex age major
# HGETALL <key>
# 모든 field-value 쌍 조회
HGETALL user:alex
# HKEYS <key>
# 모든 field 목록 조회
HKEYS user:alex
# HLEN <key>
# field 개수 반환
HLEN user:alex💡 핵심 포인트 (요약)
Redis Hash = Map<String, Map<String, String>>
하나의 key로 객체 단위 데이터 관리
여러 속성(field)을 구조적으로 저장 가능
개별 필드 단위 조회/수정 가능
여러 Key로 쪼개는 것보다 Hash 사용 권장🚀 활용 예시
사용자 정보 저장
# user:alex 라는 하나의 key에
# 다양한 속성을 field로 저장
HSET user:alex name alex age 25 email alex@example.com장바구니
# user:cart:1 → 사용자 1의 장바구니
# field: 상품명, value: 수량
HSET user:cart:1 apple 2
HSET user:cart:1 banana 5
HSET user:cart:1 orange 1
# 특정 상품 수량 조회
HGET user:cart:1 apple
# 전체 장바구니 조회
HGETALL user:cart:1# ❌ 잘못된 방식 (여러 객체를 하나의 key에 혼합)
HSET users alex:age 25 bob:age 30
# ✅ 권장 방식 (key 하나 = 객체 하나)
HSET user:alex age 25
HSET user:bob age 30Sorted Set
- 기본 명령어:
ZADD/ZINCRBY/ZRANK/ZRANGE/ZREVRANK/ZREVRANGE
# Redis Sorted Set은 정렬된 집합
# → 중복 허용 ❌ (member 기준)
# → 각 값에 score(점수)를 부여하여 자동 정렬
# ZADD <key> <score> <member> [score member ...]
# score와 함께 데이터 추가 (이미 존재하면 score만 갱신)
ZADD user:ranks 10 alex
ZADD user:ranks 9 brad 11 chad
ZADD user:ranks 8 dave
# ZINCRBY <key> <increment> <member>
# 특정 member의 score를 증가 (음수면 감소)
# 변경된 score가 반환됨
ZINCRBY user:ranks 2 alex
# ZRANK <key> <member>
# 오름차순 기준 순위 반환 (0부터 시작)
ZRANK user:ranks alex
# ZRANGE <key> <start> <stop>
# 오름차순 기준으로 범위 조회
ZRANGE user:ranks 0 3
# ZREVRANK <key> <member>
# 내림차순 기준 순위 반환 (0부터 시작)
ZREVRANK user:ranks alex
# ZREVRANGE <key> <start> <stop>
# 내림차순 기준으로 범위 조회
ZREVRANGE user:ranks 0 3💡 핵심 포인트 (요약)
Redis Sorted Set = Map<String, SortedSet>
Set + score(점수) → 자동 정렬
중복은 member 기준으로 제거
점수(score)는 실수(double) 가능
순위 조회 및 범위 조회에 최적화
score 기준 정렬 → 랭킹 시스템 구현에 최적
score 대신 timestamp 사용 가능
→ 시간 기반 처리 (Rate Limiting 등)🚀 활용 예시
✔ 리더보드 (순위표)
# 점수 기반 랭킹 시스템
ZADD game:rank 100 player1
ZADD game:rank 200 player2
ZADD game:rank 150 player3
# 상위 3명 조회 (내림차순)
ZREVRANGE game:rank 0 2✔ Rate Limiter (요청 제한)
# timestamp를 score로 사용
# → 시간 기반 요청 기록
ZADD api:user:1 1710000000 request1
ZADD api:user:1 1710000010 request2
# 특정 시간 범위 조회
ZRANGE api:user:1 0 -1공용 명령어
- 삭제 및 만료 설정:
DEL/EXPIRE/EXPIRETIME
# DEL <key>
# 어떤 자료형이든 key와 해당 데이터를 삭제
SET somekey "to be deleted"
DEL somekey
# EXPIRE <key> <seconds>
# key의 TTL(Time To Live)을 초 단위로 설정
# 지정된 시간이 지나면 자동 삭제
SET expirekey "to be expired"
EXPIRE expirekey 5
# EXPIRETIME <key>
# key가 만료되는 시각을 Unix Timestamp로 반환
EXPIRETIME expirekey- Key 조회:
KEYS(패턴 검색)
# KEYS <pattern>
# glob pattern(와일드카드)을 사용해 key 검색
# 모든 key 조회
KEYS *
# 패턴 예시:
# ? → 문자 하나 대체
# * → 여러 문자 대체
# [abc] → a, b, c 중 하나
# [^a] → a 제외
KEYS h?llo # hello, hallo, hxllo
KEYS h*llo # hllo, heeeello
KEYS h[ae]llo # hello, hallo
KEYS h[^e]llo # hallo, hbllo (hello 제외)
KEYS h[a-b]llo # hallo, hbllo- 전체 데이터 삭제:
FLUSHDB
# FLUSHDB
# 현재 데이터베이스의 모든 key 삭제 (초기화)
# ⚠️ 주의: 운영 환경에서 사용 시 매우 위험
FLUSHDB💡 핵심 포인트 (요약)
DEL → key 삭제 (모든 자료형 공통)
EXPIRE → TTL 설정 (자동 만료)
EXPIRETIME → 만료 시점 확인 (Unix Timestamp)
KEYS → 패턴 기반 key 조회 (glob 사용)
FLUSHDB → 전체 데이터 삭제⚠️ 실무 주의 사항
KEYS *
전체 탐색 → 대용량 환경에서 성능 문제
👉 실무에서는 SCAN 사용 권장
FLUSHDB
전체 데이터 삭제 → 운영 환경에서는 매우 위험