지난 시간 복습
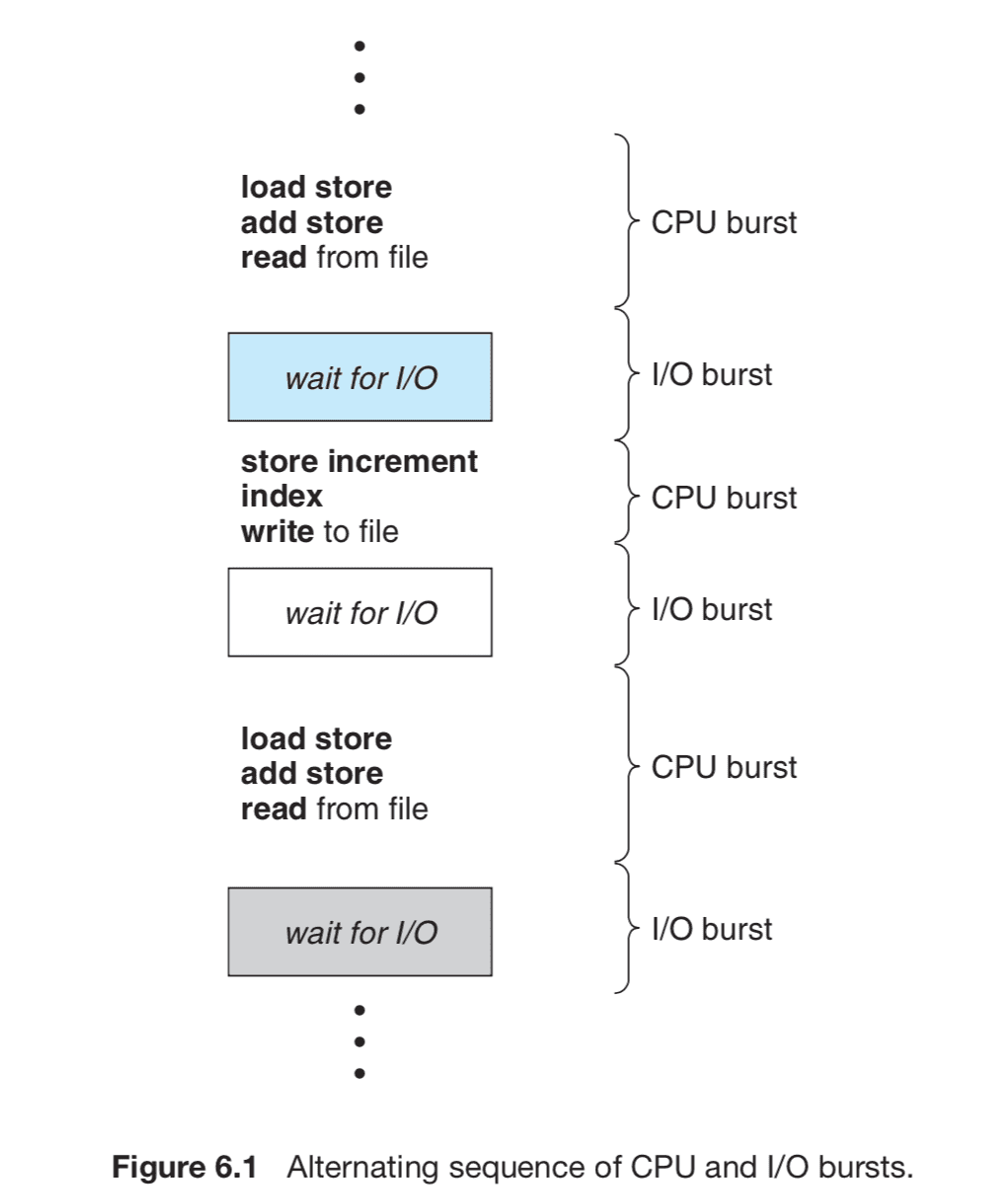
프로그램이 수행된다는 것은 위 그림과 같이 CPU만 사용하는 단계(CPU burst)와 I/O를 실행하는 단계(I/O burst)를 번갈아가면서 수행하는 것을 말한다.
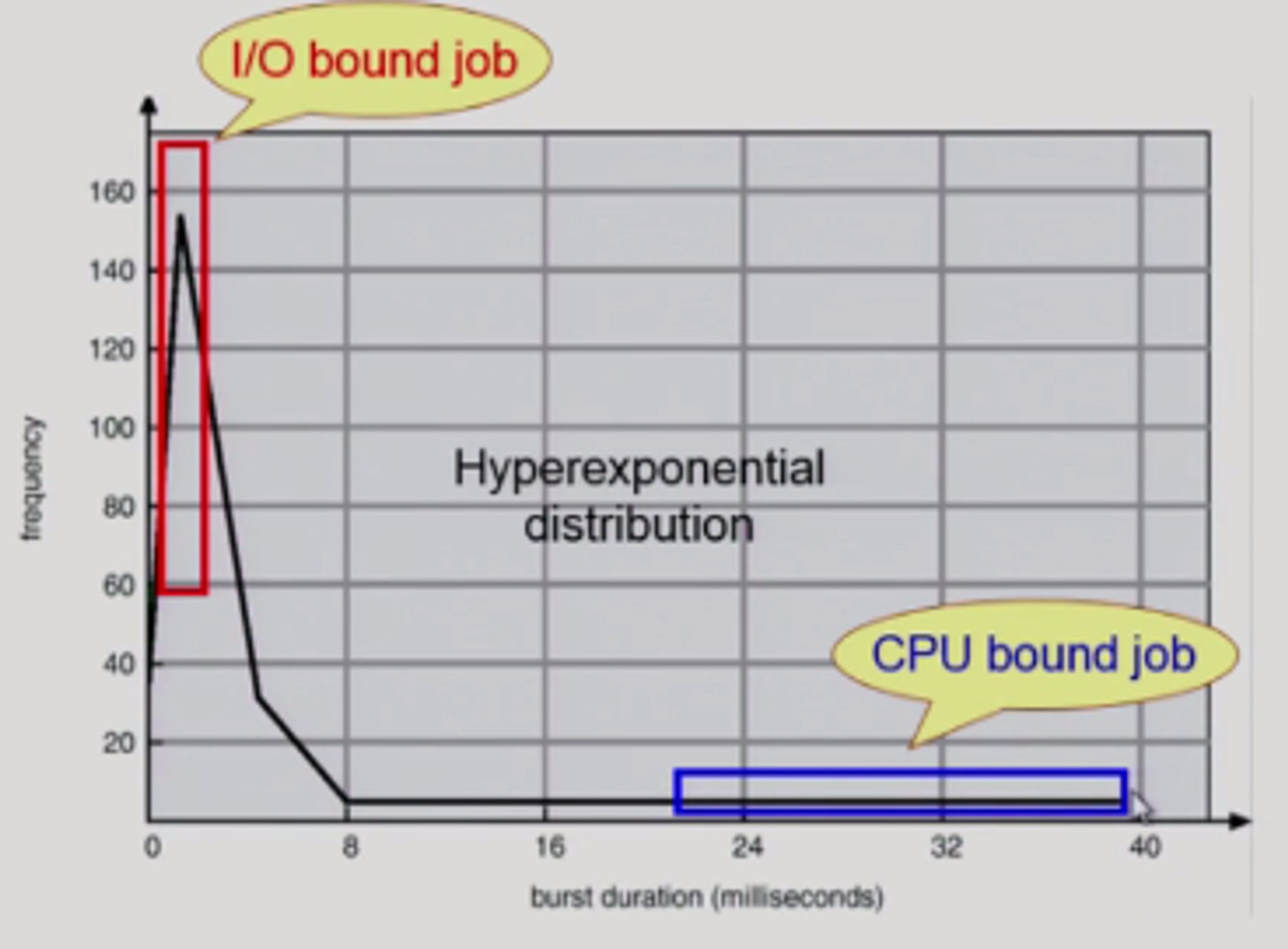
빈도나 길이의 차이는 프로그램마다 다르다. 사람과 interaction하는 프로그램(interactive)의 경우 I/O burst가 빈번히 일어난다(I/O bound job) (many short CPU bursts).
반면 과학 계산 프로그램처럼 계산 위주의 프로그램의 경우 복잡한 연산을 하게 되는 경우 연산 과정동안 CPU를 오래 쓰기 때문에 I/O burst가 잘 일어나지 않는다(CPU bound job) (few very long CPU burst).
이런 식으로 컴퓨터 안에는 I/O bound job과 CPU bound job이 섞여있다. 그렇기 때문에 자원을 적절히 쓰기 위해 CPU 스케줄링이 필요하다. 특히 I/O bound job의 경우 사람과 interaction을 하는 job이기 때문에 CPU를 CPU bound job만 잡고 있으면 I/O bound job과 interaction하는 사용자에게 불편함을 주게 된다. 따라서 CPU를 효율적이고 공평하게 사용하게 하기 위해 CPU 스케줄링이 필요한 것이다.
CPU 스케줄링에는 누구에게 우선해서 줄 것이냐, 그리고 언제 뺏을 것이냐의 이슈들이 중요하다.
CPU scheduler & Dispatcher
CPU scheduler
누구에게 CPU를 줄지 결정하는 일을 한다. Ready 상태의 프로세스 중에서 이번에 CPU를 줄 프로세스를 고른다.
CPU scheduler는 독립적인 하드웨어나 소프트웨어가 아니라 운영체제 안의 CPU scheduling을 하는 코드이다.
Dispatcher
CPU scheduler가 누구에게 넘겨줄지 결정하면 Dispatcher가 그 프로세스에게 CPU를 넘겨준다. 이 과정을 문맥교환(context switch)라고 한다.
마찬가지로 운영체제 안의 코드이다.
CPU 스케줄링이 언제 필요할까?
- Running → Blocked(ex. I/O 같이 오래걸리는 작업을 하러 간 경우, I/O 요청하는 시스템 콜)
- Running → Ready(ex. 할당 시간 만료로 timer interrupt) : 계속 CPU 쓰고 싶은데 너무 오래 갖고 있어서 CPU를 빼앗긴다.
- Blocked → Ready(ex. I/O 완료 후 인터럽트) : CPU를 얻을 수 있는 권한을 다시 준다.
priority에 기반한 스케줄링을 할 때 I/O를 하러 갔던 프로세스가 우선순위가 가장 높은 프로세스라면 I/O가 끝나자마자 CPU를 가지게 된다. 이때가 CPU 스케줄링이 필요한 상황이다. - Terminate
여기서 1, 4는 강제로 빼앗지 않고 자진반납하는 경우(nonpreemptive)이고 2,3은 계속 쓰고 싶은데 강제로 빼앗기는 경우(preemptive)이다.
nonpreemptive, preemptive는 자주 등장하는 용어이기 때문에 이 용어를 정확히 알아둘 필요가 있다.
CPU Scheduling 이란?
CPU Scheduling은 Ready Queue에 들어와 있는(CPU를 얻고자 하는) 프로세스 중 어떤 프로세스에게 CPU를 줄지 결정하는 메커니즘이다.CPU burst로 들어온 프로세스들 중에 누구에게 줄지 결정해야 한다.
컴퓨터 안에는 I/O bound job과 CPU bound job이 섞여있다. 그렇기 때문에 자원을 적절히 쓰기 위해 CPU 스케줄링이 필요하다. 특히 I/O bound job의 경우 사람과 interaction을 하는 job이기 때문에 CPU를 CPU bound job만 잡고 있으면 I/O bound job과 interaction하는 사용자에게 불편함을 주게 된다. 따라서 CPU를 효율적이고 공평하게 사용하게 하기 위해 CPU 스케줄링이 필요한 것이다.
CPU 스케줄링에는 어떤 프로세스에게 CPU를 줄 것인가, 그리고 언제 뺏을 것이냐의 이슈들이 중요하다.
CPU Scheduling에서 중요한 이슈
- 어떤 프로세스에게 CPU를 줄 것인가
- 언제 뺏을 것인가
CPU를 다 쓰고 I/O하러 갈 때까지 CPU를 계속 보장해 줄지, 중간에 빼앗아서 다른 프로세스에게 넘겨줄지에 대한 이슈이다.
전자의 경우, CPU burst가 굉장히 긴 CPU bound job 프로세스가 CPU를 잡고 안 놔주면 다른 프로세스들은 CPU를 오랫동안 사용하지 못한다. CPU를 오래 쓰지 않는 I/O bound job(특히 사람과 interaction하는) 프로세스가 너무 오래 기다리지 않도록 스케줄링하는 것이 중요하다.
이런 이슈들에 따라 공평하고 효율적으로 스케줄링해야 한다.
Scheduling Algorithms에 대한 분류 기준 및 성능 척도
선점 여부에 따른 분류
nonpreemptive 스케줄링(비선점형)
CPU를 다 쓰고 나갈 때까지 CPU를 보장한다.(오래 사용해도 중간에 빼앗지 않는다.)
preemptive 스케줄링(선점형)
CPU를 중간에 타이머 인터럽트를 걸어 강제로 빼앗을 수 있다.
현재 사용하는 스케줄링은 이 스케줄링이 거의 대부분이다.
Scheduling Criteria(성능 척도)
performance index, performance measure 와 같이도 표현한다.
시스템 입장에서 성능 척도
시스템 입장에서는 CPU 하나로 최대한 많은 일을 시키는 것이 좋기 때문에 이를 기준으로 성능을 측정한다.
-
CPU utilization
CPU 이용률을 나타낸다. 전체 시간 중에서 CPU가 놀지 않고 일한 시간의 비율이다.
CPU는 비싼 자원이기 때문에 놀리지 말고 최대한 많은 시간을 일을 시키기 위한 성능 척도이다. -
Throughput
처리량 또는 산출량이라고도 표현한다. 주어진 시간 동안에 몇 개의 작업을 완료했는지를 나타낸다.
주어진 CPU를 가지고 주어진 시간 동안 많은 일을 처리할수록 좋다.
프로세스 입장에서 성능 척도
고객 입장에서 내가 CPU를 빨리 얻어서 빨리 수행할 수 있는 것이 중요하기 때문에 시간 관련 성능 척도를 나타낸다.
시간의 개념을 아래와 같이 3가지로 나눌 수 있다.
Turnaround time
CPU를 쓰러 들어와서 다 쓰고 나갈 때까지 걸린 시간을 나타낸다.
즉, CPU를 얻어 쓰고 다 쓰고 나서 I/O를 하러 나갈 때까지 걸리는 시간이다.
= 프로세스가 CPU를 쓰러 들어왔다가 I/O를 하러 나갈 때까지 걸리는 총 시간
≠ 프로세스가 시작되었다가 종료될 때까지의 총 시간
waiting time
CPU를 쓰기 위해 ready queue에서 기다린 총 시간이다.
Response time
ready queue에 들어와서 처음으로 CPU를 얻기까지 걸리는 시간이다.
차이점 비교
preemptive인 경우 한번의 CPU burst 동안에도 CPU를 얻었다 뺏겼다 할 수 있다.
그렇게 얻었다 뺏겼다 하면서 기다리는 총 시간이waiting time이고
반면response time은 ready queue에 들어와 처음으로 CPU를 얻기까지 걸리는 시간이다.
turnaround time은 CPU 기다리는 시간, 쓰는 시간을 다 합친 총 시간이다.
⇒ 특히 Response time의 경우 time sharing 환경에서는 사용자 응답과 관련하여 굉장히 중요한 지표이다.
실생활에 비유해보자.
-
utilization
중국집 주인 입장(=시스템 입장)에서는 주방장에게 일을 많이 시키면 좋다. -
throughput
중국집에서 단위 시간 당 몇명의 손님에게 밥을 먹여 내보내느냐. 손님이 많을수록 주인 입장에서 좋다. -
turnaround time
고객입장에서 식사하러 들어와서 다 먹고 나갈 때까지 걸리는 시간(코스요리라고 생각했을 때 먹고 다음 음식 나올 때까지 기다리고 ..) -
waiting time
손님이 밥 먹을 시간 말고 음식을 기다리는 시간(코스요리) -
response time
첫 번째 음식이 나올 때까지 기다리는 시간. 너무 오래 걸리면 배고파. 제일 먼저 단무지라도 내주세요
Scheduling Algorithm 의 종류
FCFS(First-Come First-Served)
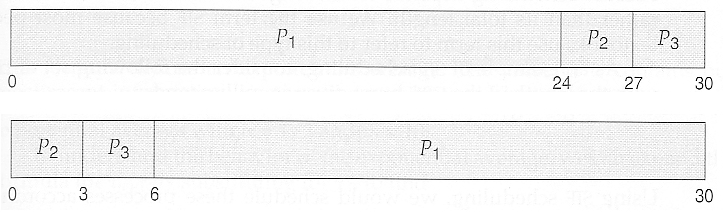
먼저 온 순서대로 처리한다.
비선점형 스케줄링이다. 먼저 와서 CPU를 얻으면 내어놓을 때까지 빼앗기지 않는다.
CPU를 짧게 쓰는 job들이 먼저 도착하게 된다면 평균 waiting time이 짧아진다.
하지만 CPU를 오래 쓰는 프로세스가 먼저 CPU를 잡으면 CPU를 짧게 쓰는 job이 후에 도착하면 CPU를 오래 쓰는 프로세스가 CPU를 내놓을 때까지 기다린다.
즉, 앞에 어떤 프로세스가 먼저 도착했느냐에 따라 기다리는 시간에 상당한 영향을 미치게 된다.
따라서 FCFS는 효율적이지 않다. 이런 식으로 긴 프로세스가 먼저 도착해서 짧은 프로세스가 오래 기다려야 하는 현상을 convoy effect라고 한다. (부정적인 효과)
SJF(Shortest-Job-First)
CPU를 사용하고자 하는 시간이 짧은(CPU burst가 짧은) 프로세스를 먼저 스케줄한다.
SJF도 nonpreemptive한 버전과 preemptive한 버전에 차이가 있는데, 그 차이를 알아보자.
nonpreemptive의 경우 실행 중인 프로세스보다 더 짧은 프로세스가 도착하더라도 이미 쓰고 있는 프로세스가 CPU를 내놓을 때까지 사용권을 보장한다.
- 스케줄링 언제 할까?
프로세스가 CPU를 다 쓰고 나가는 시점에 CPU 스케줄링을 할지 안 할지 결정을 하게 된다.

반면 Preemptive의 경우 더 짧은 프로세스가 생긴다면 CPU를 넘겨준다(CPU를 써야하는 남은 시간이 가장 짧은 프로세스). SJF preemptive한 버전을 Shortest-Remaining-Time-First(SRTF)라고도 부른다. SRTF는 주어진 프로세스들에 대해 minimum average waiting time(전체적으로 기다리는 시간이 짧아지는 것)을 보장한다.
- 스케줄링 언제 할까?
새로운 프로세스가 도착하면 언제든지 스케줄링이 이뤄질 수 있다.

SRTF에서 얻을 수 있는 average waiting time이 가장 짧다. ( optimal)
문제점
- Starvation
SJF는 무조건적으로 CPU 사용시간이 짧은 작업을 선호한다. 따라서 CPU 사용 시간이 긴 프로세스의 경우 CPU를 얻을 기회를 얻지 못하는 일이 생길 수 있다. 이런 것을 starvation 현상(기아 현상)이라고 한다.
즉, Long Process가 starvation 될 수 있다는 것이 SJF의 첫번째 문제이다.
- CPU 사용시간을 미리 알 수 없다.
현실에서는 다음 CPU burst time을 미리 알 수 없다. 즉 본인이 얼만큼 사용하고 나갈지 정확하게 미리 알지 못한다.
SJF를 실제로 쓴다면 예측값을 사용한다. 프로그램의 종류에 따라 추정하는 추정값에 따라 예측을 할 수 있는데, 과거에 CPU를 얼마나 사용했는지를 기준으로 이번에 CPU를 얼마나 사용할지를 예측한다.
(n+1)번째 CPU 사용 예측값 = a*(n번째 실제 CPU 사용 시간) + (1-a)*(n번째 예측했던 CPU 사용시간)의 수식으로 구한다. 이때 알파는 0≤a≤1이다(두 가지를 일정 비율씩 반영하기 위함이다.)
점화식을 풀어보면 현재를 기준으로 최근과 가까운 과거일수록 가중치를 더 높게 두고 멀수록 가중치를 낮게 둔다는 것을 알 수 있다.
이렇게 구해진 예측값이 가장 적은 프로세스에게 우선순위를 준다.
Priority Scheduling
우선순위가 가장 높은 프로세스에게 CPU를 주겠다는 개념이다.
이 역시 Preemptive 버전과 Nonpreemptive 버전으로 나뉜다.
Preemptive의 경우 더 높은 우선순위의 프로세스가 도착하면 CPU를 빼앗을 수 있다.
Nonpreemptive의 경우 더 높은 우선순위의 프로세스가 도착해도 CPU를 빼앗지 않는다.
우선순위는 다양하게 정의할 수 있으며, 각 프로세스마다 우선순위를 나타내는 정수값이 주어진다. 우선순위가 가장 높은 프로세스를 보통 가장 작은 정수로 표현하는 것이 일반적이다.
SJF 스케줄링 역시 우선순위 스케줄링 중 일부이다. 이 경우, CPU 사용시간을 기준으로 우선순위를 정의한 것이다.
문제 : Starvation
우선순위가 낮은 프로세스가 지나치게 차별 받아 영원히 실행되지 않는 경우이다.
해결 : Aging
아무리 우선순위가 낮은 프로세스라 하더라도 오래 기다린 경우 우선순위를 높여 Starvation을 막는다.
Round Robin(RR)
현대 CPU 스케줄링은 Round Robin Scheduling을 기반으로 한다. 라운드로빈은 선점형 방식이다.
CPU를 줄 때 동일한 크기의 할당 시간(time quantum)을 설정한다. 그 시간이 끝나면 timer interrupt에 의해 CPU를 빼앗기고 다시 ready queue에 가서 줄을 선다.
장점
RR의 장점은 Response time(CPU를 처음 얻는 데 걸리는 시간)이 짧아진다는 것이다. 조금씩 CPU를 줬다 뺏었다하기 때문에 어떤 프로세스더라도 금방 CPU를 맛볼 수 있다.
또한 CPU 사용시간을 예측할 필요 없이 CPU를 짧게 쓰는 프로세스가 CPU를 짧게 쓰고 나갈 수 있도록 하는 것이 RR의 장점이다.
ready queue에 있는 프로세스의 개수를 n, 할당 시간을 q time unit이라 한다면 어떤 프로세스도 (n-1)q time unit 이상 기다리지 않는다. 만약 q보다 더 짧은 프로세스는 할당시간 안에 끝내고 나가게 되고 q보다 긴 프로세스는 q만큼 썼다가 뺏기는 과정을 반복한다.
또한 CPU를 길게 쓰는 프로세스는 대기시간도 그만큼 길어지고(그만큼 반복해서 기다려야 하니까) 짧게 쓰는 프로세스는 대기시간도 그만큼 짧아진다.
RR는 SJF보다 avg turnaround time이나 waiting time은 길어질 수 있지만 최초로 CPU를 얻는 데에 걸리는 response time은 짧아진다.
극단적인 상황
q가 지나치게 커지면⇒ FCFS와 같은 알고리즘이 된다.q가 지나치게 작아지면⇒ context switch가 너무 자주 일어나서 context switch 오버헤드가 커져 performance에 악영향을 준다.
따라서 q를 적당하게 정하는 것이 중요하다. (보통 10~100ms)
RR는 CPU 사용시간이 일정하지 않은 프로세스가 여러 개 섞여있을 때 효율적인 알고리즘이다. 만약 100초걸리는 프로세스가 4개 있고 RR로 짧게짧게 잘라 쓰면 400초 시점이 되었을 때 CPU를 다 쓰고 동시에 빠져나간다. 하지만 이렇게 하지 않고 비선점형으로 한번 CPU를 잡고 다 쓸 때까지 계속 쓰면 먼저 수행된 프로세스는 빨리 나갈 수 있다. (일반적으로는 섞여있기 때문에(heterogeneous) RR가 효과를 발휘한다.)
RR 예제 - Time Quantum = 20인 경우

P2의 경우 q보다 더 짧아서 자기가 쓸만큼만 쓰고 나간다.
