오늘 학습 내용
1. Multi-GPU 학습
2. Hyperparameter Tuning
3. PyTorch Troubleshooting
1. Multi-GPU 학습
- Single VS Multi
→ Sigle은 하나, Multi는 2개 이상을 의미.
- GPU VS Node
→ Node는 System 즉, Computer를 의미.
- Single Node Single Gpu
→ 하나의 노드안의 하나의 GPU
Model Parallel VS Data Parallel
-
Model Parallel
Model 간 파이프라인을 통해 병렬처리를 하는 것이다.
self.seq1 = nn.Sequential( # 첫번째 모델을 GPU0에 할당 self.conv1, self,bn1, self.relu, self.maxpool, self.layer1, self.layer2 ).to('cuda:0')self.seq2 = nn.Sequential( # 첫번째 모델을 GPU1에 할당 self.layer3, self.layer4, self.avgpool, ).to('cuda:1')def forward(self,x): x = self.seq2(self.seq1(x).to('cuda:1')) # 두 모델을 연결 ... ... ...
-
Data Parallel
Data 들을 나눠 GPU에 할당 후 평균을 구하는 방법.
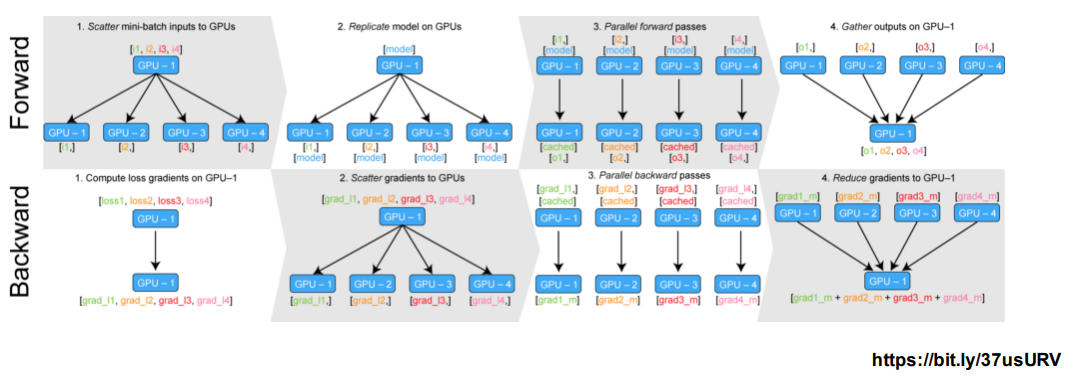
PyTorch에서 DataParallel, DistributedDataParallel 방법이 있다.- DataParallel
단순히 Data를 분배 후 평균을 구한다.
→ 분배 담당 GPU가 병목 (GPU 간 불균형) - DistributedDataParallel
개별 GPU 마다 각 CPU를 할당
→ 개별적으로 연산의 평균을 구한다.
#Data Parallel torch.nn.DataParallel(model)#DistributedDataParallel torch.utils.data.distributed.DistributedSampler(method) - DataParallel
2. Hyperparameter Tuning
-
Model의 Accuracy에 관여하는 대표적 3가지 요소
1 . Model
2 . Data
3 . Hyperparameter- Model
근래 대부분 이미 특정 Domain에서 좋은 성능지표를 보이는 모델이 존재 하기 때문에, 모델 변경을 통한 Accuracy 향상은 어느정도 한계가 있다.
- Data
위의 3가지 요소중 Accuracy에 미치는 영향이 가장 크다.
Data는 양이 많으면 많을수록 좋으며, 전처리 방법에 따라서도 많은 영향을 미친다.
- Hyperparameter
예전엔 Hyperparamter 값에 의해 Accuracy가 크게 좌우되기도 했었다.
(Google의 Recipe)
근래에는 학습 시, Data 양이 너무 많기에 Hyperparameter를 하나씩 바꿔가면서 실험이 불가능하다.
모델의 학습이 어느정도 완료된 뒤, 마지막 조금의 Accuracy 를 위하여 조정해볼만 하다.
- Model
-
Hyperparameter 가 Accuracy에 미치는 영향은 적지만, 분명 존재한다.
-
Tuning의 가장 기본적인 방법은 Grid Search와 Random Search 이다.
- Grid Seach
→ [0.1, 0.01, 0.001] , [32, 64, 128] 등 일정한 간격으로 Tuning 시도. - Random Search
→ Random 한 값으로 Tuning을 시도하며, 어느정도 Tuning이 안정화 되면 Grid Search로 전환하는 방법또한 존재한다.
- Grid Seach
-
Ray
- Multi-Node 에서의 Proceccing 모듈 지원.
- ML/DL 에서 병렬 처리를 위한 도구이며, 현재 분산병렬 모듈의 표준이다.
- Hyperparameter Search 를 위한 다양한 모듈 지원.
-
결국, 양질의 Data가 학습에 있어 가장 중요시 되어야 하며, Hyperparameter는 마지막 단계에서 Tuning 시도를 해볼법하다.
3. PyTorch Troubleshooting
OOM(Out of Memory)
Difficult
- 왜, 어디서 발생했는지 파악이 어려움.
- Error Backtracking 시, too-low-level 까지 들어간다.
- 이전의 메모리 상황 파악이 어렵다.
→ 기본적으로, Batch Size를 줄이고, GPU 를 Clear시킨다.
Solutions
1. GPUtil 사용
- nvidia-smi처럼 GPU 상태를 Monitoring
- Iter 마다 메모리가 늘어나는지 확인.
import GPUtil GPUtil.showUtilization()
2. torch.cuda.empty_cache() 사용
- 사용되지 않는 GPU 상의 Cache 정리
- 가용메모리 확보
- reset 대신 사용하기 좋다
torch.cuda.empty_cache()
3. Training Loop에 Tensor로 축적 되는 변수 확인
- Tensor 변수는 GPU 메모리 상에 축적된다.
total_loss = 0 for i in range(10000): y = model(x) loss = criterion(y) loss.backward() optimizer.step() total_loss += loss # Loop 마다 Tensor가 메모리 상에 계속 축적따라서, Tensor를 Python 기본 객체로 변환하여 처리한다.
total_loss = 0 for i in range(10000): y = model(x) loss = criterion(y) loss.backward() optimizer.step() total_loss += loss.item # item으로 선언하면, Python 객체로 변환되어 저장
4. del 명령어 적절히 사용
for-Loop 에서 loop가 종료되도 메모리 상에 변수가 계속 존재한다.
for x in range(10): i = x print(i) # 9가 출력된다.따라서,
del을 이용해 필요없어진 변수는 삭제해야 한다.
5. 가능한 Batch Size 실험
학습 시, OOM이 발생했다면 가능한 최대의 Batch Size를 찾는다.
is_oom = False try: run_model(batch_size) except: RuntimeError: # Occur OOM is_oom = True if oom: for _ in range(1,batch_size): run_model(_)
6. torch.no_grad() 사용
추론 시점에서는 torch.no_grad() 구문을 사용한다.
→ Backward 시, 추적으로 인한 메모리 축적이 없다.with torch.no_grad(): # torch.no_grad() 사용 for data, target in test_loader: output = model(data) ... ... ...
