오늘 학습 내용
1. Model with Pytorch
1. Model with Pytorch
- Model 은 객체, 사람 또는 시스템에 대한 정보의 표현이며, 모형이라고도 부를 수 있다.
Pytorch
- Pytorch 는 Low-level, Pythonic, Flexibility 의 특징을 가진다.

-
Pytorch의 Model의 모든 Layer는 nn.Module Class를 상속 받는다.

-
하나의 Module 즉, 하나의 Layer 마다 각각의 Parameter를 가진다.
-
forward() 는 Model이 호출 되었을 때 실행 되는 함수이며, Model은 Module이 Sequential 하게 겹쳐져 있는 구조이기 때문에, Module 각각 또한 forward()를 갖는다.
-
Parameter 는 각 Module(Layer) 가 가지고 있는 Weight들이며,
data(값), requires_grad(학습여부) 변수를 가진다.
Pre-trained Model
-
모델 일반화를 위해 매번 수 많은 데이터를 학습시키는 것을 비효율적이다.
→ Pre-trained Model 등장 배경

-
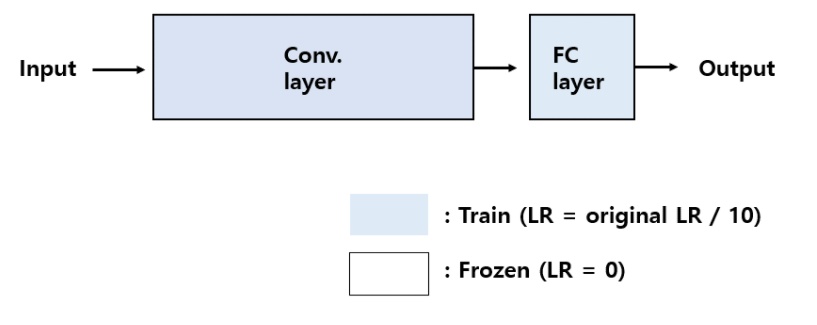
CNN 기반의 분류 모델의 기본 구조는 다음과 같다.

Freeze
-
Pre-trained Model을 사용 시, 현재 가진 Dataset의 Size나 Similarity 를 판단하여,
Layer의 Trainable 이나 Non-Trainable(Freeze) 여부를 결정해야한다. -
공통적으로 LR(Learning Rate) 는 기존 학습된 내용이 급격하게 새로운 학습 내용에 맞춰지는 것을 방지하기 위해 기존 Pre-trained Model 의 LR 의 약 1/10 수준을 사용한다.
1. Small Dataset and Similar to the Pre-trained Model's Dataset
-
데이터 수가 적어, 모든 Layer의 Weight를 Update 하게 되면 Overfitting 될 위험이 있음.
-
하지만, Pre-trained Model 학습 시 사용한 데이터와 현재 학습 시킬 데이터가 유사하여, 기존 CNN Layer가 특징들을 잘 추출할 확률이 높음.
-
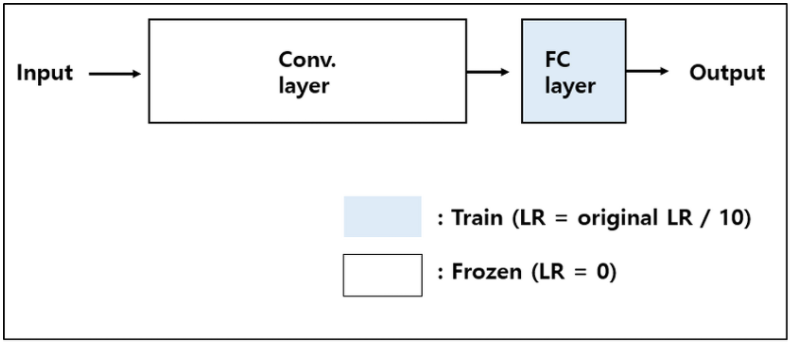
따라서, CNN Layer는 Freeze 시켜 기존 Weight를 그대로 사용하고, FC(Classifier) 부분만 학습 진행.
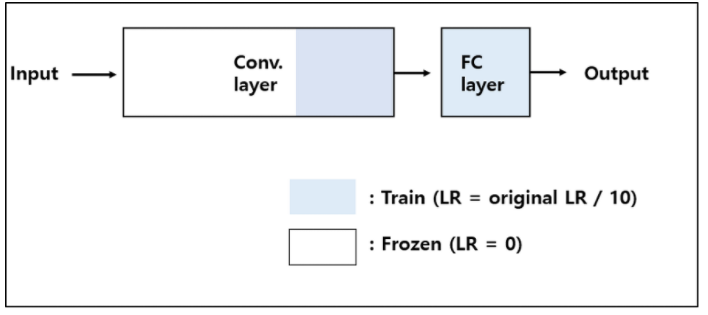
2. Large Dataset and Similar to the Pre-trained Model's Dataset
-
데이터 수가 많기에, Overfitting 위험이 적음.
-
또한, Pre-trained Model의 학습 데이터와 현재 학습 시킬 데이터가 유사하기에 기존 CNN Layer의 학습이 어느정도 불필요.
-
1번 케이스와 다르게, 학습 데이터가 많음으로 더욱 정확한 분류를 위해 FCDHK CNN Layer의 일정 부분도 학습 진행.
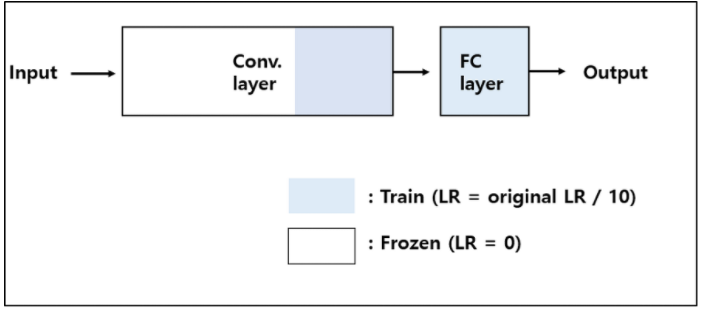
3. Large Dataset and Different to the Pre-trained Model's Dataset
-
데이터 수가 많기에, Overfitting 위험이 적음.
-
하지만, Pre-trained Model의 학습데이터와 현재 학습 시킬 데이터가 유사하지 않음.
-
학습 데이터가 충분하기에, 전체 Layer를 학습시킴.
4. Small Dataset and Different to the Pre-trained Model's Dataset
-
데이터 수가 적고, 기존 학습 데이터와 유사하지도 않음.
-
Overfitting의 위험때문에, 전체 Layer 학습 또한 불가.
-
절충안으로 일정 부분의 CNN Layer와 FC를 학습시킴.
-
사실상, 제대로된 결과를 기대하기 어려움.