
*본 게시글은 유튜브 '김성범[ 교수 / 산업경영공학부 ]' [ 핵심 머신러닝 ]뉴럴네트워크모델 2 (Backpropagation 알고리즘) 자료를 참고한 점임을 알립니다.
Neural Network
1. 전체 뉴럴 네트워크 정의
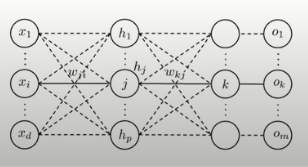
- 한번에 바로 미분하기에는 복잡
- 출력층과 은닉층, 은닉층과 입력층 단위로 구분
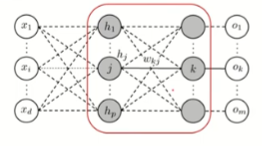
2. 출력층과 은닉층 사이
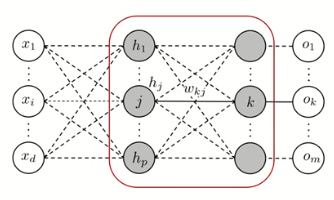
- Forward 진행 과정
- Backpropagation를 통해 을 업데이트 하기 위해 를 계산
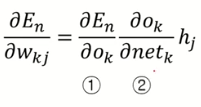
- 위를 (단일 k에 대해) 자세히 전개하면
- 최종적으로 가중치를 업데이트할 때
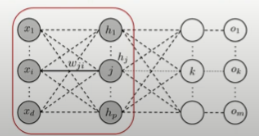
3. 은닉층과 입력층 사이
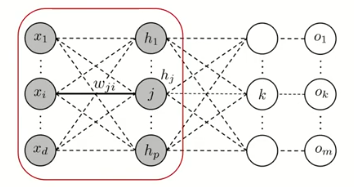
- Forward 진행 과정
- Backpropagation를 통해 을 업데이트 하기 위해 를 계산
- 이를 자세히 전개하면
- 위 수식을 구체적으로 풀어쓰자면
- 이를 정리하자면
- 최종적으로 가중치를 업데이트할 때
4. 출력층과 은닉층 / 은닉층과 입력층 정리
참고 자료

https://github.com/min731