
Dataframe , Matplotlib 을 활용한 데이터사이언스 프로젝트입니다.
- 2022-11-23 현 시점 한창 뜨거운 World을 주제로 16강 진출팀 승부예측 및 자료 시각화를 중심으로 진행하였습니다.⚽⚽⚽
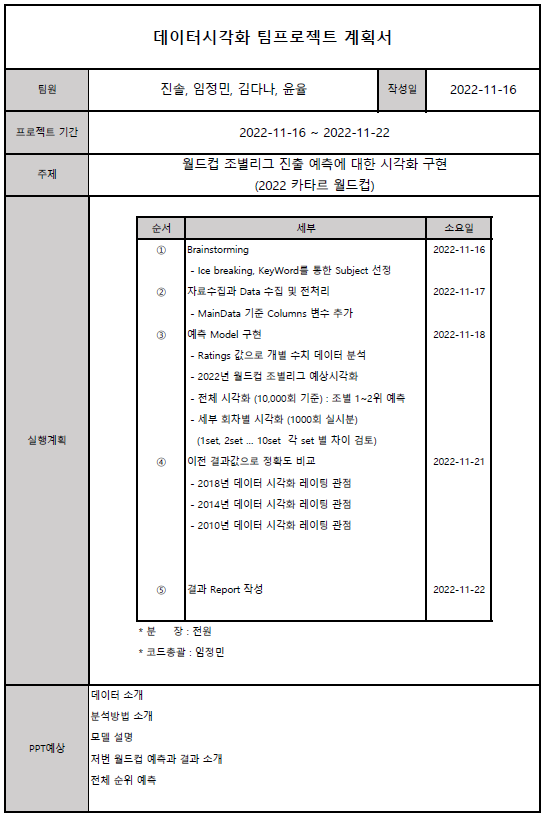
프로젝트 계획서
-
프로젝트 계획서입니다. 총 4명의 조원이 협업했습니다.🙋♂️🙋♂️🙋♂️
-
프로젝트 진행 기간은 2022-11-16 ~ 2022-11-22 일주일 소요되었습니다.
-
모든 팀원이 주제선정 - 데이터 수집/전처리 - 예측 Model - 결과값 시각화 등 전 과정에 관여하며 데이터 사이언티스트의 전반적인 역할에 대해 경험해보았습니다.
-
월드컵을 주제로 데이터를 가공하여 과거를 분석하고 미래를 예측하는 프로젝트입니다. 🧐🧐🧐
프로젝트 내용
프로젝트 진행 순서는 다음과 같습니다.👉👉👉
- Dataframe과 Matplotlib 활용하기 적합한 주제 선정 : '월드컵'
- Worldcup 규칙, Elo Rating 등 도메인 지식 습득
- 월드컵 승부예측에 활용되는 데이터 수집 및 전처리
- 분석/예측의 정확성을 위한 1000~10000개의 표본 수집/통계
- 표본을 기준으로 과거 월드컵 분석 및 미래의 월드컵 예측 자료 시각화
- 결론 도출 및 PT 발표
핵심 주제는 다음과 같이 두가지입니다.🎯🎯🎯
- 스포츠 통계 지표로 활용되는 Elo Rating 개념은 얼마나 근거있는 지표인지 검증하기
- Elo Rating이 신빙성있는 지표라면 이를 통해 과거 Worldcup 조별리그 결과를 분석하고 미래 Worldcup 조별리그 예측하기
본 프로젝트의 결론은 다음과 같이 요약됩니다.🧐🧐🧐
-
Elo Rating은 2018, 2014, 2010 Worldcup 조별리그 기준 16강 진출팀 예측 시 13개의 팀, 즉 평균 81.25%의 준수한 적중률을 보이며 충분히 신뢰할만한 지표임이 확인되었습니다.
-
이를 통해 올해 2022 카타르 월드컵의 16강 진출팀 중 13개의 팀 이상(81.25%) 적중할 것으로 예상됩니다. 구체적으로 우리나라의 16강 진출 확률은 26%로 90%의 포르투갈, 80%의 우루과이에 비해 상대적으로 열세인 상황임을 알 수 있었고 더불어 월드컵을 참가한 모든 국가에 대한 16강 진출 확률(1등으로 진출할 확률+2등으로 진출할 확률)을 시각화 자료를 통해 확인할 수 있었습니다.
데이터 및 코드

- 모든 코드, 표본, DB가 압축된 '데이터사이언스 코드배포 블로그.zip' 입니다.
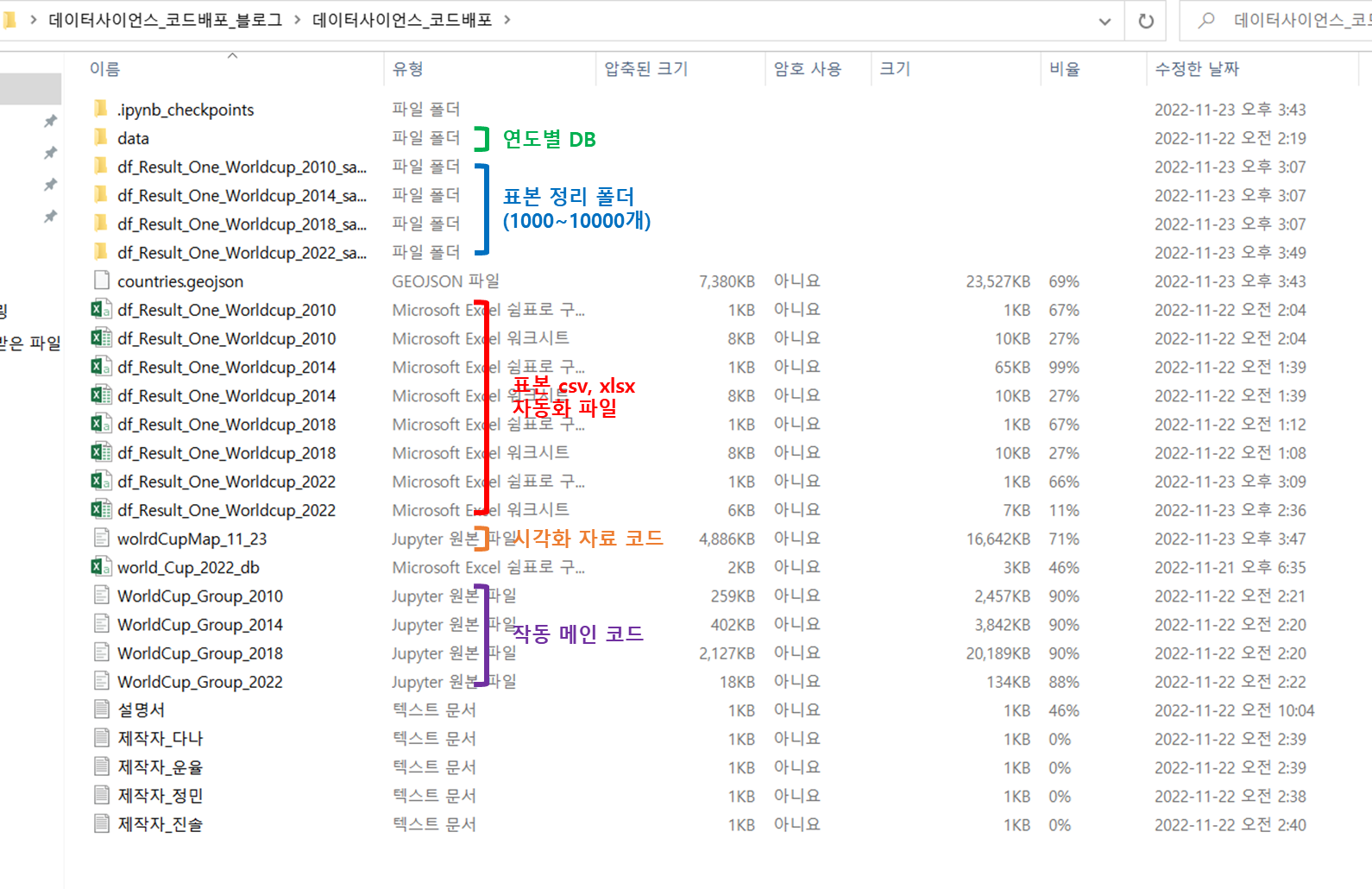
- 압축해제 시 위와 같은 구성으로 되어있습니다.
[연도별 DB]
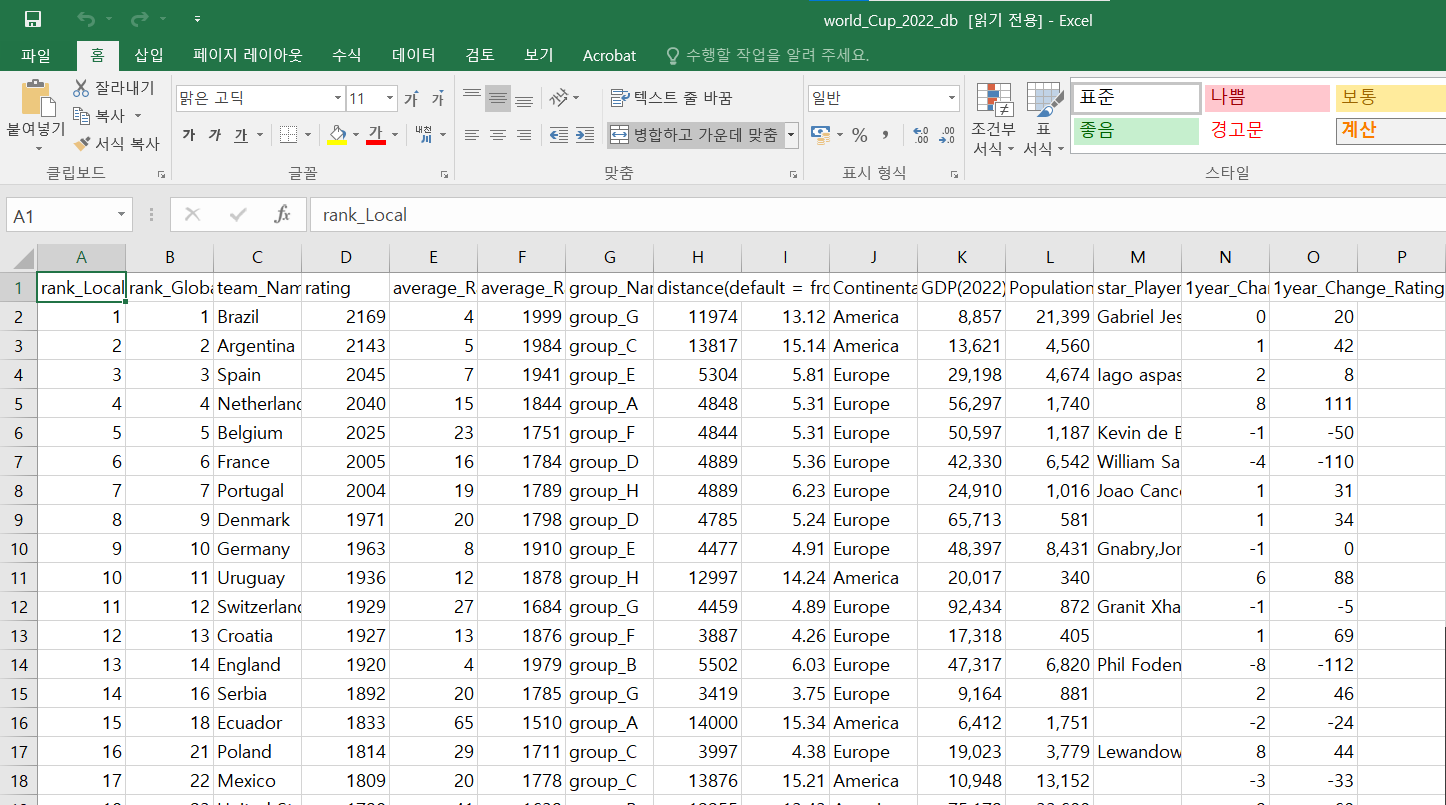
- 2022년 월드컵 db 입니다. team_Name(국가명), rating (종합실력 or 전투력), group_Name(조별리그 그룹명) 등 수집/전처리가 완료된 excel 파일입니다.
[표본 정리 폴더]
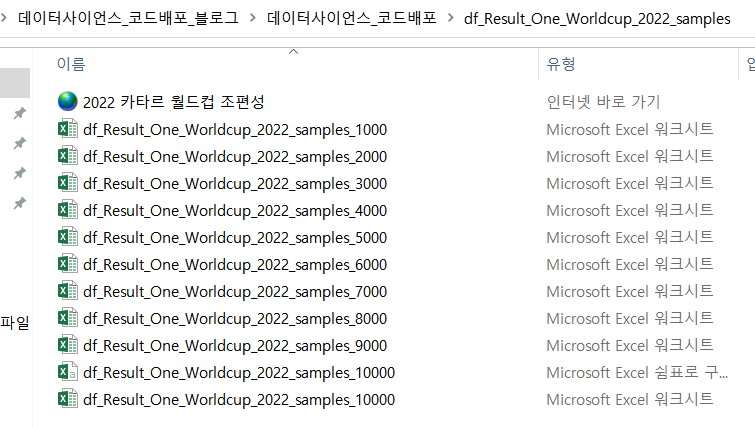
- 2022년의 표본 정리 폴더입니다. 1000~10000개의 월드컵 조별리그 표본을 누적하며 평균치에 수렴하는 결과값(16강 진출 확률)을 구하고자 하였습니다.
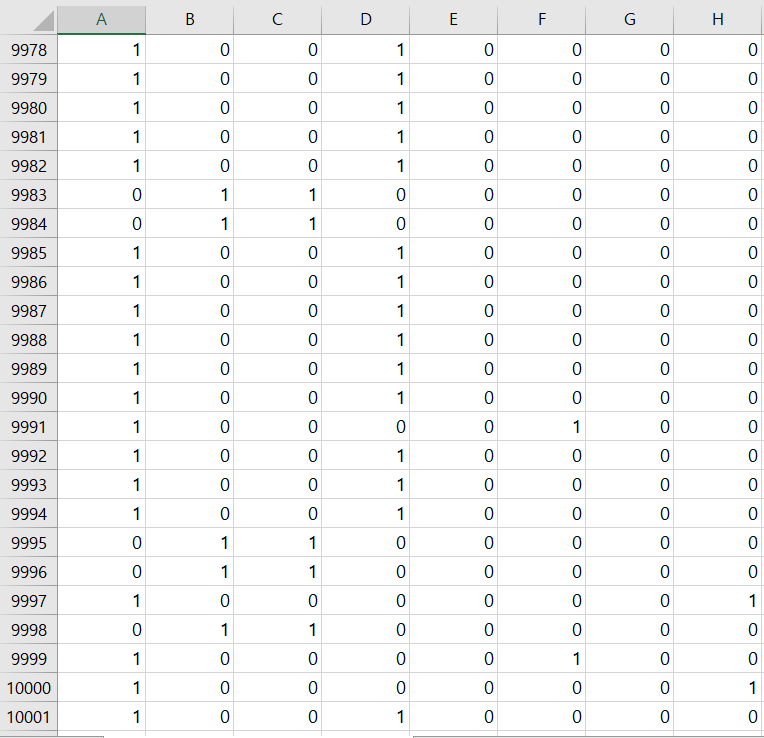
-
10000개의 표본이 기록된 csv 파일입니다. 특정팀이 16강에 진출시 1, 탈락시 0으로 표시하였습니다.

-
2022년 조별리그 A조의 팀별 16강 진출확률입니다. 첫번째 행의 '국가명_seed1'은 16강을 1등으로 진출할 확률이며 '국가명_seed2'는 16강을 2등으로 진출할 확률입니다. 두번째 행은 해당국가의 16강 진출확률(1등 진출 확률+ 2등 진출 확률)입니다.예를 들어 1만개의 표본 기준 네덜란드는 81.74%로 1등으로 진출하며 13.41%로 2등으로 진출합니다. 이에 따라 총 95.15%로 16강에 진출한다고 예측할 수 있습니다.
[표본 csv,xlsx 자동화 파일]
- 해당 파일은 사전에 정리한 1000~10000개 표본에 다시 누적하며 확률을 보정할 수 있는 파일입니다.
[시각화 자료 코드]
import json
import pandas as pd
jsonfile = open('countries.geojson','r',encoding='utf-8').read()
jsondata = json.loads(jsonfile)
json_pick = []
json_result = {"type":"FeatureCollection"}
for item in jsondata['features']:
#print(item['properties']['sidonm']
if item['properties']['ADMIN'] in ['Netherlands',
'Senegal',
'Ecuador',
'Qatar',
'England',
'United States',
'Iran',
'Wales',
'Argentina',
'Poland',
'Mexico',
'Saudi Arabia',
'France',
'Denmark',
'Australia',
'Tunisia',
'Spain','Germany',
'Japan',
'Costa Rica',
'Belgium',
'Croatia',
'Canada',
'Morocco',
'Brazil',
'Switzerland',
'Serbia',
'Cameroon',
'Portugal',
'Uruguay',
'South Korea',
'Ghana',]:
#print(item['properties']['sidonm']
item['id'] = item['properties']['ADMIN']
json_pick.append(item)
json_result['features'] = json_pick
json_result
data = pd.read_csv('world_Cup_2022_db.csv', encoding='cp949')
wolrdCupNations = data[['team_Name','rating','group_Name']]
wolrdCupNations
import folium
import folium
from folium.plugins import MarkerCluster
loc = [0,0]
m = folium.Map(loc,zoom_start=1)
folium.Choropleth(geo_data=json_result,
data = wolrdCupNations,
columns = ['team_Name','rating'],
fill_color='Reds',
fill_opacity=0.7,
line_opacity=1,
key_on='feature.id').add_to(m)
m
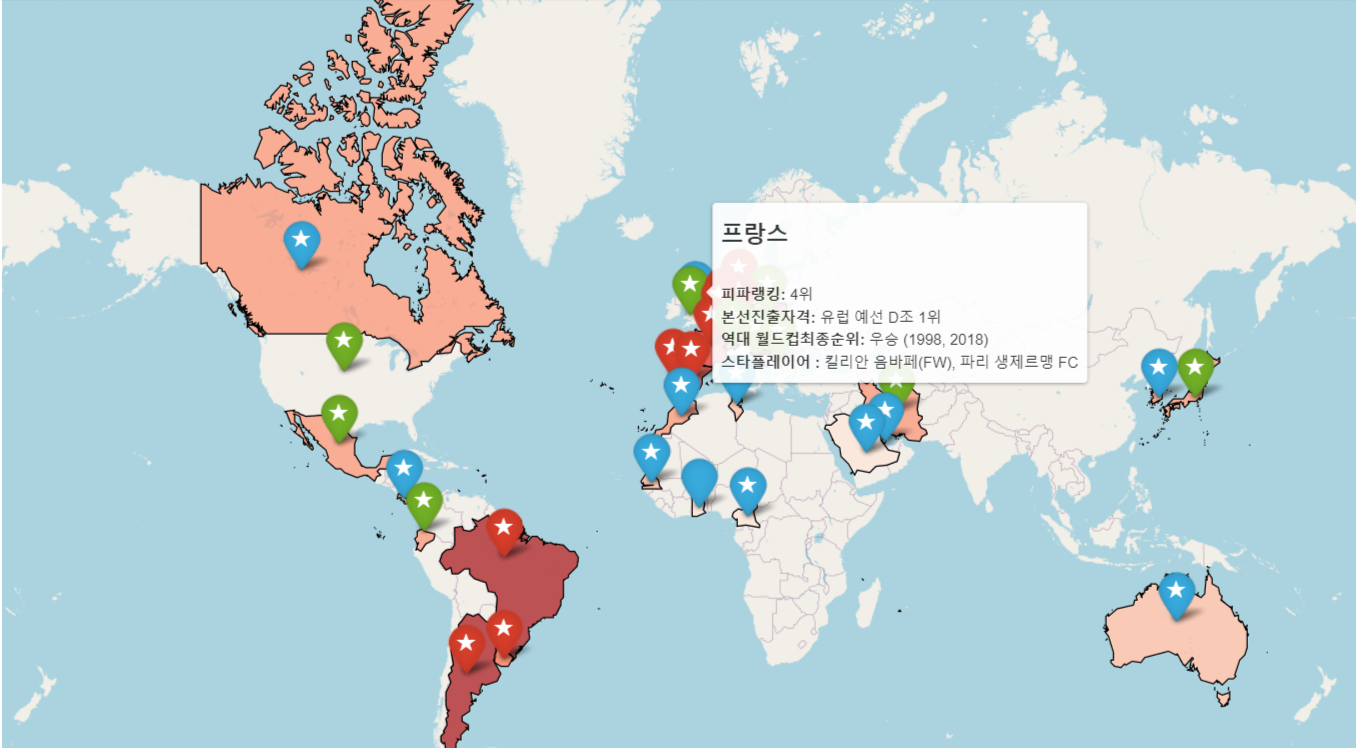
- 세계지도를 배경으로 국가별 월드컵 경쟁력을 확인할 수 있는 자료입니다. 빨간색이 진한 국가일 수록 rating(종합전력)이 높은 국가이며 빨간색-초록색-파란색 순으로 나타납니다. 원하는 국가에 마우스 커서를 갖다대면 피파랭킹,본선진출자격, 역대 월드컵최종순위, 스타플레이어 등의 정보가 나타납니다.
[작동 메인코드]
import pandas as pd
import numpy as np
import math
import random
from itertools import combinations
import time
import matplotlib.pyplot as plt
import openpyxl
from openpyxl.utils.dataframe import dataframe_to_rows
df = pd.read_csv('data/world_Cup_2022_db.csv')
df
def rating_Upd(team_A,team_B,win_Rate_A,df_group_Alphabet) :
before_team_A_rating=df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_A,'rating'].values
before_team_B_rating=df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_B,'rating'].values
df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_A,'rating'] = int(df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_A,'rating'].values) + int(24*(1-(win_Rate_A))) # 32 는 k값임
df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_B,'rating'] = int(df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_B,'rating'].values) + int(24*(0-(1-win_Rate_A))) # k = 32,24,16 등 승부가 낫을 때, k값이 클수록 변동이 커짐
print(f"""
승리한 {team_A} 의 rating :{df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_A,'rating'].values[0]} (+{df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_A,'rating'].values[0]-before_team_A_rating[0]})
패배한 {team_B} 의 rating :{df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_B,'rating'].values[0]} ({df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_B,'rating'].values[0]-before_team_B_rating[0]})
""")
def run_One_Game(team_A,team_B,rating_A,rating_B,df_group_Alphabet,n):
win_Rate_A = 1 / (1 + 10**( (rating_B-rating_A) / 400) )
num_Rand = random.random()
print("------------------------------------")
print(f"""
{df_group_Alphabet['group_Name'].unique()} 조 {n+1}번째 경기시작
{team_A} vs {team_B}
{team_A}의 승리 확률 : {win_Rate_A*100}
{team_B}의 승리 확률 : {(1-win_Rate_A)*100}
{team_A}의 rating : {df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_A,'rating'].values}
{team_B}의 rating : {df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_B,'rating'].values}
난수 : {num_Rand}
""")
if num_Rand <= win_Rate_A:
print(f"""
{team_A} (이)가 승리했습니다.
{team_B} (이)가 패배했습니다.
""")
df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_A,'win'] += 1
df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_A,'point'] += 3
df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_B,'lose'] += 1
rating_Upd(team_A,team_B,win_Rate_A,df_group_Alphabet)
else :
print(f"""
{team_B} (이)가 승리했습니다.
{team_A} (이)가 패배했습니다.
""")
df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_A,'lose'] += 1
df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_B,'win'] += 1
df_group_Alphabet.loc[df_group_Alphabet['team_Name']==team_B,'point'] += 3
rating_Upd(team_B,team_A,1-win_Rate_A,df_group_Alphabet)
print("------------------------------------")
def run_Group_Games(df_group_Alphabet): # df_Group_A 이라는 Datafrme 파라미터로 받음
print("-------------------------------------------------------------------------------")
print(f"{df_group_Alphabet['group_Name'].unique()} 조 모든 경기 시작")
group_Teams = [team_Name for team_Name in df_group_Alphabet['team_Name']]
# ['Netherlands', 'Ecuador', 'Senegal', 'Qatar']
group_games = list(combinations(group_Teams, 2))
# [('Netherlands', 'Ecuador'), ('Netherlands', 'Senegal'), ('Netherlands', 'Qatar'), ('Ecuador', 'Senegal'), ('Ecuador', 'Qatar'), ('Senegal', 'Qatar')]
for i in range(len(group_games)):
run_One_Game(group_games[i][0],
group_games[i][1],
df_group_Alphabet.loc[df_group_Alphabet['team_Name']==group_games[i][0],'rating'].values,
df_group_Alphabet.loc[df_group_Alphabet['team_Name']==group_games[i][1],'rating'].values,
df_group_Alphabet,
i)
print(f"{df_group_Alphabet['group_Name'].unique()} 조 모든 경기 종료")
print("-------------------------------------------------------------------------------")
def run_All_Group_Games(all_Group_Name):
print("============================================= 2022 World Cup 조별예선이 시작되었습니다 ============================================= ")
for i in range(len(all_Group_Name)):
run_Group_Games(all_Group_Name[i]) # df_Group_A
print("============================================= 2022 World Cup 조별예선이 종료되었습니다 ============================================= ")
def result_All_Group_Games(all_Group_Df):
df_Result_One_Worldcup = pd.DataFrame(index=['result'])
#df_Result_One_Worldcup = pd.DataFrame(columns=[ j for j in i['team_Name'] for i in all_Group_Df] ) # all_Group_Df = [df_Group_A,df_Group_B....]
for i in all_Group_Df:
for j in i['team_Name']:
df_Result_One_Worldcup[[j + '_seed1', j + '_seed2']] = [0,0]
for i in range(len(all_Group_Df)):
all_Group_Df[i] = all_Group_Df[i].sort_values(by=['point', 'rating'] ,ascending=False)
all_Group_Df[i] = all_Group_Df[i].reset_index(drop=True)
all_Group_Df[i].index += 1
all_Group_Df[i].loc[1,'seed'] = 'seed1'
all_Group_Df[i].loc[2,'seed'] = 'seed2'
if all_Group_Df[i].loc[1,'seed'] == 'seed1':
df_Result_One_Worldcup[all_Group_Df[i].loc[1,'team_Name'] + '_seed1'] = 1
if all_Group_Df[i].loc[2,'seed'] == 'seed2':
df_Result_One_Worldcup[all_Group_Df[i].loc[2,'team_Name'] + '_seed2'] = 1
print(f"{all_Group_Df[i]}\n")
df_Result_One_Worldcup.to_csv('df_Result_One_Worldcup_2022.csv', mode='a', header=False, index=False)
def make_All_Groups():
all_Group_Name = [group_Name for group_Name in df['group_Name'].unique()]
all_Group_Name.sort() # ['group_A', 'group_B', 'group_C', 'group_D', 'group_E', 'group_F', 'group_G', 'group_H']
all_Group_Df = ['df_Group_'+chr(65+i) for i in range(len(all_Group_Name))]
for i in range(len(all_Group_Name)) : # i = 0,1,2,3,4,5,6,7 #range(1,int(df['team_Name'].count()/4)+1) :# i = 1,2,3,4,5,6,7,8
all_Group_Df[i] = df[df['group_Name']==all_Group_Name[i]][['group_Name','team_Name','rating']].reset_index(drop=True)
all_Group_Df[i].index += 1
all_Group_Df[i][['win','draw','lose','point','seed']] = [0,0,0,0,'-']
print(f"{all_Group_Df[i]}\n")
return all_Group_Df
def probability_All_Teams(all_Group_Df):
all_Group_Name = [group_Name for group_Name in df['group_Name'].unique()]
all_Group_Name.sort() # ['group_A', 'group_B', 'group_C', 'group_D', 'group_E', 'group_F', 'group_G', 'group_H']
df_probability_All_Teams = pd.DataFrame(index=['result'])
df_Result_One_Worldcup = pd.read_csv('df_Result_One_Worldcup_2022.csv')
for i in all_Group_Name:
for j in df[df['group_Name']==i]['team_Name']:
df_probability_All_Teams[[j+'_seed1',j+'_seed2']] = [0,0]
df_probability_All_Teams[j+'_seed1'] = df_Result_One_Worldcup[j+'_seed1'].mean()
df_probability_All_Teams[j+'_seed2'] = df_Result_One_Worldcup[j+'_seed2'].mean()
df_probability_All_Teams.to_excel('df_Result_One_Worldcup_2022.xlsx', index=False,header=True)
# Main 문
start = time.time()
for _ in range(2):
all_Group_Df = make_All_Groups() # 월드컵 조편성 !
run_All_Group_Games(all_Group_Df) # 월드컵 시작 !
result_All_Group_Games(all_Group_Df) # 월드컵 결과 !
probability_All_Teams(all_Group_Df)
print(f"함수 실행 시간 :{time.time() - start}",)
- 월드컵 조별리그 결과 표본을 구하는 코드입니다. Main문의 for문 돌리는 횟수에 따라 한번에 여러개의 표본을 누적시킬 수 있습니다.
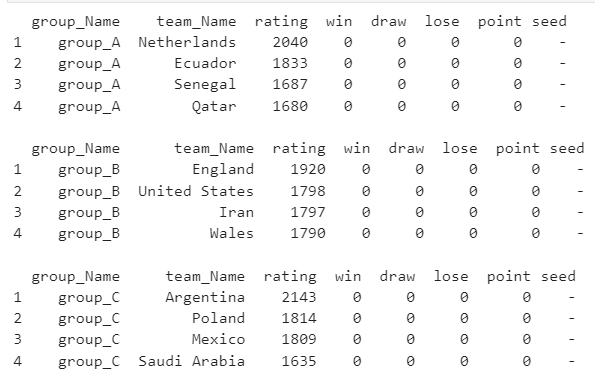
-
위와 같이 조편성 과정을 print()했습니다.

-
위와 같이 조별리그 모든경기에 대한 상대 정보, rating, 경기 결과를 print() 하였습니다.
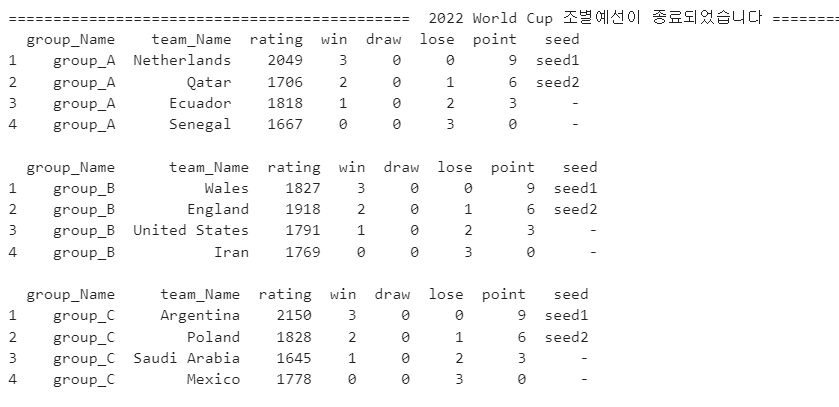
-
위와 같이 모든 조별리그 경기가 끝난 결과를 print()했습니다. point(승점),rating(종합전력) 순으로 상위2팀이 16강에 진출하게 됩니다.
-
해당 코드를 1000~10000번 반복하여 표본을 구한 뒤 평균치에 수렴하는 월드컵 16강 진출팀 확률을 구할 수 있었습니다.
참고
발표 PPT 및 설명은 데이터사이언스Worldcup승부예측_프로젝트 (2)을 참고하시면 되겠습니다.
