
한국인 안면 이미지 데이터를 활용한 얼굴 인신 출석 시스템 프로젝트입니다.
- 딥러닝안면 인식 시스템프로젝트 (1)에 이은 코드리뷰 글입니다.🍑🍑🍑
코드 리뷰
-
원본데이터 전처리
1) 학습 속도 및 모델 성능을 고려한 데이터 선별 (약 800만개 -> 9만개)
# 한국과학기술원 인공지능 연구단에서 제공한 전처리 API
# 고화질,가장 밝은 명도의 사진들만 모아 총 800만개의 데이터에서 약9만개의 데이터 추출
import glob
import os
import sys
from os import path
import shutil
import argparse
from tqdm import tqdm
def error(msg):
print('Error: ' + msg)
exit(1)
def create_kface(target_dir, kface_image_dir, light, resolution, bbox):#, resize_val, shuffle):
print('Loading images from "%s"' % kface_image_dir)
resolution_nm = resolution + '_Resolution'
sessions = ['S001', 'S002', 'S003', 'S004', 'S005', 'S006']
emotions = ['E01', 'E02', 'E03']
cameras = ['C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'C7', 'C8', 'C9', 'C10', 'C11', 'C12', 'C13']
# 대상자 id폴더 리스트
pth_subj_data = []
pth_subj_data = sorted(glob.glob(os.path.join(kface_image_dir, resolution_nm, '*')))
len_subj_data = len(pth_subj_data)
subjid = []
for idx in range(len_subj_data):
subjid.append(pth_subj_data[idx].split('\\')[-1])
for session in tqdm(sessions, desc='Accessory'):
for emotion in tqdm(emotions, desc='Emotion'):
for camera in tqdm(cameras, desc='Camera'):
filenames = list()
if bbox == 'Y':
txtnames = list()
for idx in range(0, len_subj_data):
tmp_nm = []
tmp_nm = glob.glob(os.path.join(pth_subj_data[idx], session, light, emotion, camera+'.jpg'))
filenames.append(tmp_nm)
if bbox == 'Y' and session == 'S001':
txt_nm = []
txt_nm = glob.glob(os.path.join(pth_subj_data[idx], session, light, emotion, camera+'.txt'))
txtnames.append(txt_nm)
if len(filenames) == 0:
error('No input images found')
for idx in range(0, len_subj_data):
to_dir = target_dir+'\\'+kface_image_dir+'\\'+resolution_nm+'\\'+session+'_'+emotion
if not path.isdir(to_dir):
os.makedirs(to_dir)
if not path.exists(to_dir+'\\'+subjid[idx]+'_'+camera+'.jpg'):
shutil.copy(filenames[idx][0], to_dir+'\\'+subjid[idx]+'_'+camera+'.jpg')
if bbox == 'Y' and session == 'S001':
if not path.exists(to_dir+'\\'+subjid[idx]+'_'+camera+'.txt'):
shutil.copy(txtnames[idx][0], to_dir+'\\'+subjid[idx]+'_'+camera+'.txt')
2) 클래스 분류 및 Image Generator 활용에 적합한 형태의 경로로 구성
# 악세서리001_표정01..악세서리006_표정03 총 18개 클래스로 분리
# 약 9만개의 이미지 데이터들을 train,validation,test 폴더로 나눔
import os,shutil
original_dataset_dir = 'C:\pythonDir\Deep_Learning\High_Resolution'.replace('\\','/') # 원본 데이터 경로(고화질)
base_dir = 'C:\pythonDir\Deep_Learning\Korean_face'.replace('\\','/') # train,val,test 로 나눌 경로
os.mkdir(base_dir)
# 총 93600장
# train 45864 validation 19656 test 28080 로 분할
train_dir = os.path.join(base_dir,'train').replace('\\','/')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir,'validation').replace('\\','/')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir,'test').replace('\\','/')
os.mkdir(test_dir)
train_dir,validation_dir,test_dir
from glob import glob
class_paths = glob(original_dataset_dir+'\*')
class_names = []
for class_path in class_paths:
class_names.append(class_path.split('\\')[-1])
class_names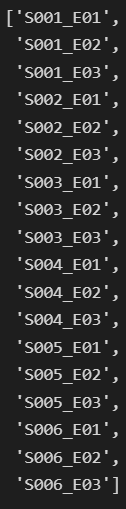
# 각클래스 별로 train 2912 validation 1248 test 1040
# train 0.8 test 0.2
# train 0.7 validation 0.3
for i in range(len(class_names)):
# 진행상황 파악
print(class_names[i])
# train/S001_E01 폴더 만듬
train_class_name_dir = os.path.join(train_dir,class_names[i]).replace('\\','/')
os.mkdir(train_class_name_dir)
# train/S001_E01 2912개만 넣기
one_class_datasets = glob(class_paths[i]+'/*.jpg')
train_datasets = one_class_datasets[:2912]
for train_dataset in train_datasets:
src = os.path.join(original_dataset_dir,train_dataset).replace('\\','/')
dst = os.path.join(train_class_name_dir,train_dataset.split('\\')[-1]).replace('\\','/')
shutil.copyfile(src,dst)
# validation/S001_E01 폴더 만듬
validation_class_name_dir = os.path.join(validation_dir,class_names[i]).replace('\\','/')
os.mkdir(validation_class_name_dir)
# validation/S001_E01 1248개만 넣기
train_datasets = one_class_datasets[2912:4160]
for train_dataset in train_datasets:
src = os.path.join(original_dataset_dir,train_dataset).replace('\\','/')
dst = os.path.join(validation_class_name_dir,train_dataset.split('\\')[-1]).replace('\\','/')
shutil.copyfile(src,dst)
# test/S001_E01 폴더 만듬
test_class_name_dir = os.path.join(test_dir,class_names[i]).replace('\\','/')
os.mkdir(test_class_name_dir)
# test/S001_E01 1040개만 넣기
train_datasets = one_class_datasets[4160:5200]
for train_dataset in train_datasets:
src = os.path.join(original_dataset_dir,train_dataset).replace('\\','/')
dst = os.path.join(test_class_name_dir,train_dataset.split('\\')[-1]).replace('\\','/')
shutil.copyfile(src,dst)
- yolo를 활용한 이미지 안면 박싱 모델
from google.colab import drive
drive.mount('/content/drive')
data_path = '/content/drive/MyDrive/Colab Notebooks/kface/Middle_Resolution.zip'
model_path = '/content/drive/MyDrive/Colab Notebooks/deep_learning/model/yolov5_kface'
# Yolo 모델 다운로드
%cd /content
!git clone https://github.com/ultralytics/yolov5
%cd yolov5
!pip install -qr requirements.txt
# 데이터셋 다운로드
import zipfile
%mkdir /content/yolov5/kface
%cd /content/yolov5/kface
path = data_path
data = zipfile.ZipFile(path, 'r')
data.extractall('/content/yolov5/kface')
data.close()
# !unzip '/content/drive/MyDrive/Colab Notebooks/kface/Middle_Resolution.zip'
# 바운딩 박스 좌표 정규화
import os
import glob
import shutil
from tqdm import tqdm
img_size = (230, 346) # (h, w)
classes=['S001_E01', 'S001_E02', 'S001_E03', 'S002_E01', 'S002_E02', 'S002_E03',
'S003_E01', 'S003_E02', 'S003_E03', 'S004_E01', 'S004_E02', 'S004_E03',
'S005_E01', 'S005_E02', 'S005_E03', 'S006_E01', 'S006_E02', 'S006_E03']
txt_paths = sorted(glob.glob('/content/yolov5/kface/*/*.txt'))
jpg_paths = sorted(glob.glob('/content/yolov5/kface/*/*.jpg'))
for txt_path in tqdm(txt_paths):
filename = txt_path.split('/')[-1]
label = txt_path.split('/')[-2]
num_label = classes.index(label)
with open(txt_path, 'rt') as f:
lines = f.readlines()
x, y, w, h = map(int, lines[7].split('\t'))
x = (x+w/2)/img_size[1]
y = (y+h/2)/img_size[0]
w = w/img_size[1]
h = h/img_size[0]
target_path = '/content/yolov5/kface/train/labels/'+label+'_'+filename
if not os.path.isdir('/content/yolov5/kface/train/labels/'):
os.makedirs('/content/yolov5/kface/train/labels/')
with open(target_path, 'wt') as f:
f.write(f'{num_label} {x} {y} {w} {h}')
for jpg_path in tqdm(jpg_paths):
filename = jpg_path.split('/')[-1]
label = jpg_path.split('/')[-2]
target_path = '/content/yolov5/kface/train/images/'+label+'_'+filename
if not os.path.isdir('/content/yolov5/kface/train/images/'):
os.makedirs('/content/yolov5/kface/train/images/')
shutil.move(jpg_path, target_path)
# 폴더 정리
for cls in classes:
shutil.rmtree('/content/yolov5/kface/'+cls+'/')
# 데이터 나누기
def split_img_label(data_valid, folder_valid): # yolo 모델에 들어갈 때, train & validation 경로 따로 지정해야함
os.makedirs(folder_valid+'images/')
os.makedirs(folder_valid+'labels/')
valid_ind = list(data_valid.index)
# Valid folder
for j in tqdm(range(len(valid_ind))):
shutil.move(data_valid[valid_ind[j]], folder_valid+'images/'+data_valid[valid_ind[j]].split('/')[-1])
shutil.move('/'+os.path.join(*data_valid[valid_ind[j]].split('/')[:-2])+'/labels/'+data_valid[valid_ind[j]].split('/')[-1].split('.jpg')[0]+'.txt', folder_valid+'labels/'+data_valid[valid_ind[j]].split('/')[-1].split('.jpg')[0]+'.txt')
import pandas as pd
import os
from sklearn.model_selection import train_test_split
txt_paths = sorted(glob.glob('/content/yolov5/kface/train/labels/*.txt'))
jpg_paths = sorted(glob.glob('/content/yolov5/kface/train/images/*.jpg'))
labels = []
for txt_path in txt_paths:
with open(txt_path, 'rt') as f:
lines = f.readlines()
labels.append(lines[0].split(' ')[0])
labels = pd.DataFrame(labels)
df = pd.DataFrame(jpg_paths)
df = pd.concat([df, labels], axis=1)
df.columns = [0, 1]
# split
data_train, data_valid, labels_train, labels_valid = train_test_split(df[0], df[1], test_size=0.2, stratify=df[1], random_state=42)
folder_valid_name = '/content/yolov5/kface/valid/'
# Function split
split_img_label(data_valid, folder_valid_name)
# Yolo 데이터 준비
train_img_list = glob.glob('/content/yolov5/kface/train/images/*.jpg')
valid_img_list = glob.glob('/content/yolov5/kface/valid/images/*.jpg')
# 파일 목록 실제 파일로 저장
with open('/content/yolov5/kface/train.txt', 'w') as f: # 한 txt파일에 정리함
f.write('\n'.join(train_img_list)+'\n')
with open('/content/yolov5/kface/valid.txt', 'w') as f:
f.write('\n'.join(valid_img_list)+'\n')
# yaml 파일 수정을 위한 함수
from IPython.core.magic import register_line_cell_magic
@register_line_cell_magic
def writetemplate(line, cell):
with open(line, 'w') as f:
f.write(cell.format(**globals()))
%%writetemplate /content/yolov5/kface/data.yaml # yaml에다가 작성한다.
tarin: ../kface/train/images
val: ../kface/valid/images
nc: 18
names: ['None_Netural', 'None_Happy', 'None_Frown', 'Nomal_Glass_Netural', 'Nomal_Glass_Happy', 'Nomal_Glass_Frown',
'Horn_rimmed_Glass_Netural', 'Horn_rimmed_Glass_Happy', 'Horn_rimmed_Glass_Frown',
'Sunglasses_Netural', 'Sunglasses_Happy', 'Sunglasses_Frown',
'Netual_with_cap', 'Happy_with_cap', 'Frown_with_cap',
'Horn_rimmed_Glass_Netural_with_cap', 'Horn_rimmed_Glass_Happy_with_cap', 'Horn_rimmed_Glass_Frown_with_cap']
%cat /content/yolov5/kface/data.yaml
# Yolo 모델 구성
import yaml
with open('/content/yolov5/kface/data.yaml', 'r') as stream: # as stream == as f
num_classes = str(yaml.safe_load(stream)['nc']) # 클래스 갯수 불러오기
# 사본 커스텀 저장
%%writetemplate /content/yolov5/models/kface_yolov5s.yaml
# Parameters
nc: {num_classes} # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
# 수정 확인
%cat /content/yolov5/models/kface_yolov5s.yaml
# 딥러닝 모델 학습 실행
%cd /content/yolov5/
%%time
!python train.py --img 346 --batch 32 --epochs 20 --data ./kface/data.yaml \
--cfg ./models/kface_yolov5s.yaml --name kface_result --cache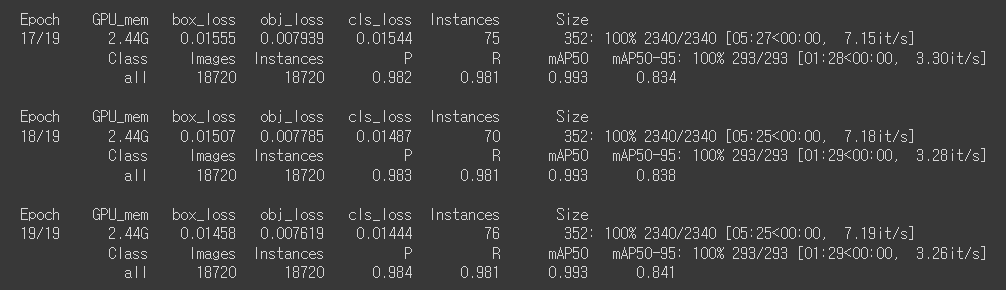
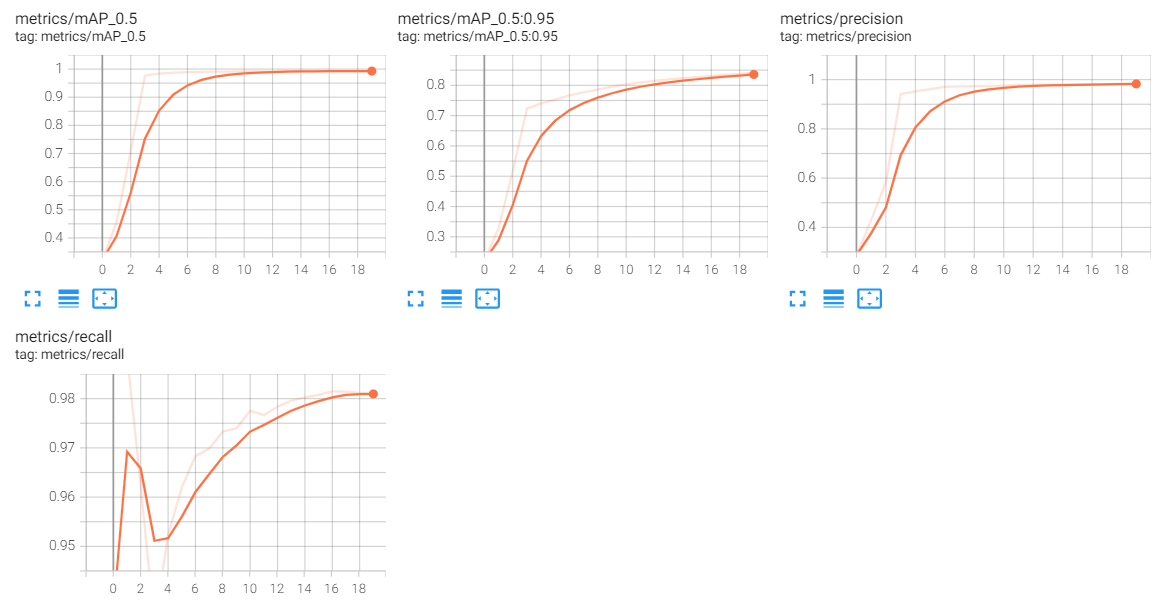
from IPython.display import Image
Image(filename='/content/yolov5/runs/train/kface_result/results.png', width=800)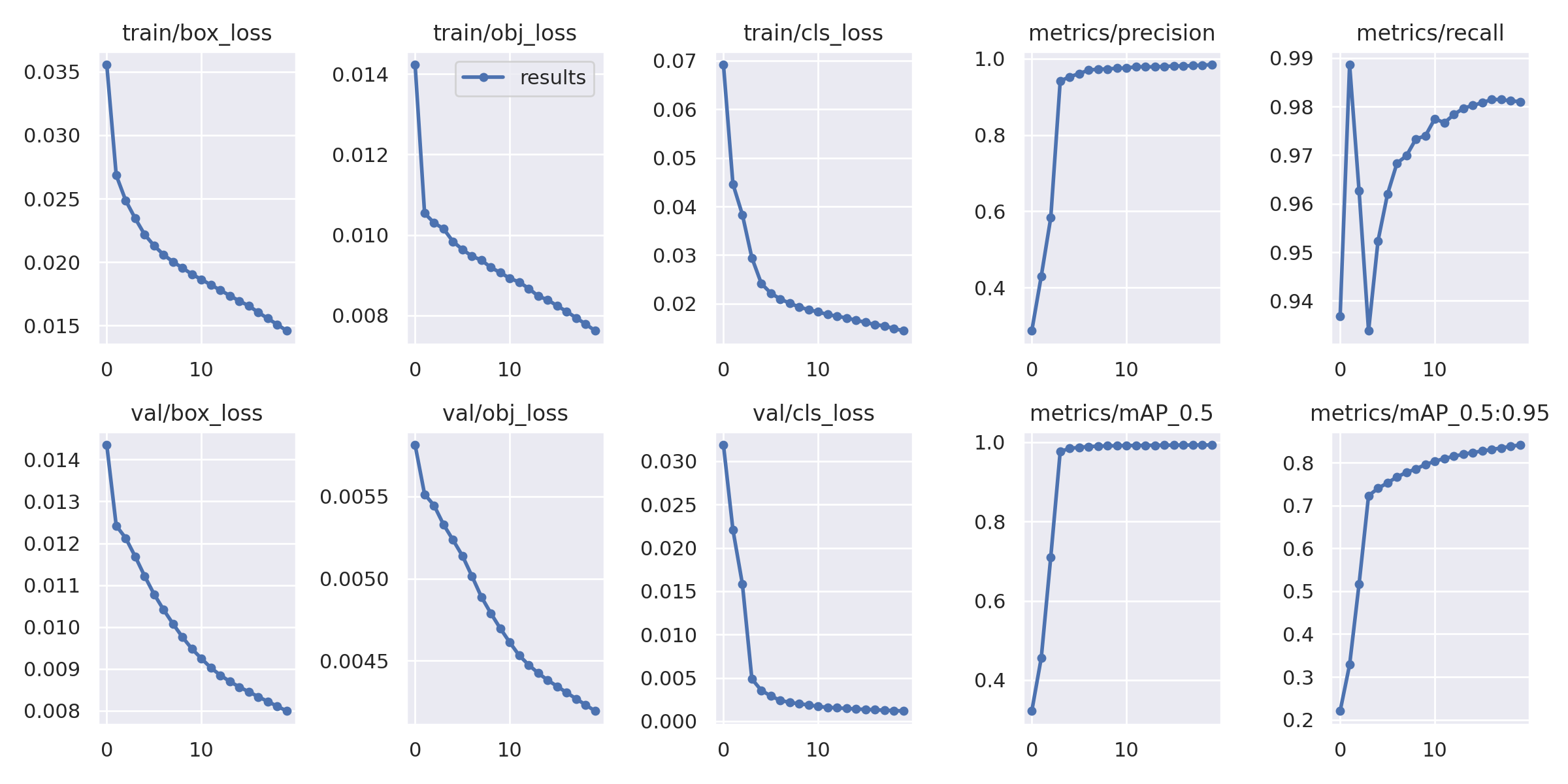

- 악세서리,표정 분류 모델
# 전처리된 데이터셋 압축해제
import zipfile
import time
start = time.time()
path = '/content/drive/MyDrive/Colab Notebooks/deep_learning_pjt/Korean_face_zip.zip'
zip_ref = zipfile.ZipFile(path, 'r')
zip_ref.extractall('/Korean_face_data')
zip_ref.close()
# 이미지 데이터 총 93600 개
test : 52416개 ( 93600 * 0.8 * 0.7 )
val : 22464개 ( 93600 * 0.8 * 0.3 )
test : 18720개 ( 93600 * 0.2)
import numpy as np
from sklearn.model_selection import train_test_split
train_dir = '/content/drive/MyDrive/Colab Notebooks/deep_learning_pjt/Korean_face/train'
val_dir = '/content/drive/MyDrive/Colab Notebooks/deep_learning_pjt/Korean_face/validation'
test_dir = '/content/drive/MyDrive/Colab Notebooks/deep_learning_pjt/Korean_face/test'
from glob import glob
class_paths = glob(train_dir+'/*')
class_names = []
for class_path in class_paths:
class_names.append(class_path.split('/')[-1])
class_names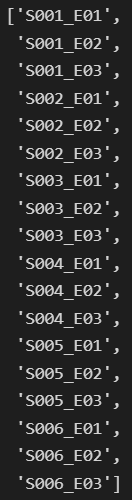
# Image Generator 정의
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
train_datagen = ImageDataGenerator(rescale=1/255)
val_datagen = ImageDataGenerator(rescale=1/255)
test_datagen = ImageDataGenerator(rescale=1/255)
train_generator = train_datagen.flow_from_directory(train_dir, # target directory
classes=class_names, # S001_E01...S006_E03 순서로 label 0..17을 설정
target_size=(200,300),
batch_size= 32,
class_mode='categorical')
val_generator = val_datagen.flow_from_directory(val_dir, # target directory
classes=class_names, # S001_E01...S006_E03 순서로 label 0..17을 설정
target_size=(200,300),
batch_size= 32,
class_mode='categorical')
test_generator = test_datagen.flow_from_directory(test_dir, # target directory
classes=class_names, # S001_E01...S006_E03 순서로 label 0..17을 설정
target_size=(200,300),
batch_size= 32,
class_mode='categorical')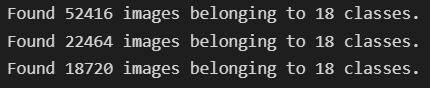
<사진 해상도>
최초 100x100 으로 시행했지만 학습속도도 빠르고
test후 정답을 확인하기 위해 알아보기 쉽고 원본파일 비율을 맞추기 위해 300x200으로 적용하였다.
<규제>
* 규제의 필요성
train에 비해 test 성능이 낮으면 과적합이 발생한 것이다.
이에 따라 다양한 규제를 적용하여 test 성능을 높이고자 한다.
=> 배치정규화 이미 적용함
=> 가중치감소(Weight Decay),L1,L2,드롭아웃(dropout) 등
* 규제가 없을 시
train_acc = 0.99 val_acc = 0.86이고
test_acc = 0.85였다.
* L2(0.001) 규제 적용 시
train_acc = 0.97 val_acc = 0.85이고
test_acc = 0.86였다.
* L2(0.01),드롭아웃(dropout) 규제 적용 시 (현재 파일)
train_acc = 0.93 val_acc = 0.89이고
test_acc = 0.89였다.
# 모델 정의 및 학습
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D,MaxPool2D,Dense,Flatten,Activation,BatchNormalization,Dropout
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.regularizers import l2
# from keras.layers import Conv2D,MaxPool2D,Dense,Flatten,Dropout
import time
start = time.time()
with tf.device('/device:GPU:0'):
model = Sequential([
Conv2D(filters=32,kernel_size=3,padding='same',input_shape=(200, 300, 3)),
BatchNormalization(),
Activation('relu'),
Conv2D(filters=32,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Conv2D(filters=64,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
Conv2D(filters=64,kernel_size=3,padding='same'),
BatchNormalization(),
Activation('relu'),
MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
# Conv2D(filters=128,kernel_size=3,padding='same'),
# BatchNormalization(),
# Activation('relu'),
# Conv2D(filters=128,kernel_size=3,padding='same'),
# BatchNormalization(),
# Activation('relu'),
# MaxPool2D(pool_size=(2,2),strides=2,padding='same'),
Flatten(),
Dense(256,kernel_regularizer=l2(0.01)),
Dropout(0.2),
# Dense(256),
BatchNormalization(),
Activation('relu'),
Dense(18,activation='softmax')
])
model.compile(optimizer=Adam(1e-4),loss='categorical_crossentropy',metrics=['acc'])
# def get_step(train_len,batch_size):
# if(train_len % batch_size > 0 ):
# return train_len // batch_size +1
# else:
# return train_len // batch_size
history = model.fit(train_generator,
epochs=10,
steps_per_epoch=1638, # 52416 / 32 = 1638
validation_data=val_generator,
validation_steps=702) # 22464 / 32 = 702# acc_loss 그래프 비교
hist_dict = history.history
import matplotlib.pyplot as plt
loss = hist_dict['loss']
val_loss = hist_dict['val_loss']
epochs = range(1,len(loss)+1) # len(val_loss) 써도됌
fig = plt.figure(figsize=(10,5))
ax1 = fig.add_subplot(1,2,1)
ax1.plot(epochs,loss,color='blue',label='train_loss')
ax1.plot(epochs,val_loss,color='orange',label='val_loss')
ax1.legend()
acc = hist_dict['acc']
val_acc= hist_dict['val_acc']
ax2 = fig.add_subplot(1,2,2)
ax2.plot(epochs,acc,color='blue',label='train_acc')
ax2.plot(epochs,val_acc,color='orange',label='val_acc')
ax2.legend()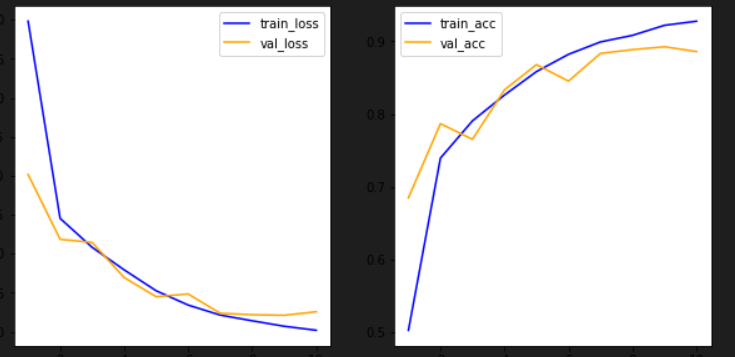
#검증하기
#test : 18720개 ( 93600 * 0.2)
test_datagen = ImageDataGenerator(rescale=1/255)
test_generator = test_datagen.flow_from_directory(test_dir, # target directory
classes=class_names, # S001_E01...S006_E03 순서로 label 0..17을 설정
target_size=(200,300),
batch_size= 32,
class_mode='categorical',
shuffle=True) # shuffle = True가 defalut
imgs,labels = next(test_generator)
test_preds = model.predict(imgs)
test_loss,test_acc = model.evaluate_generator(test_generator)
print(f"정확도: {np.round(test_acc,2)*100}%")
4. 실시간 카메라 및 웹페이지 로그 시스템 구축
import cv2
from keras.models import load_model
import numpy as np
from PIL import ImageFont, ImageDraw, Image
import cvlib as cv
import face_recognition
# style
# styles=["Gogh","Kandinsky","Monet","Picasso","Na","Mario"]
# style_transfer=StyleTransfer(1280,720)
# style_transfer.load()
# style_transfer.change_style(styles.index("Na"))
# image_segmentation=ImageSegmentation(1280,720)
# window option
cv2.namedWindow("test", cv2. WINDOW_NORMAL)
cv2.setWindowProperty("test", cv2. WND_PROP_FULLSCREEN, cv2. WINDOW_FULLSCREEN)
# label
class_names_hangul = ['보통_무표정','보통_활짝웃음','보통_찡그림',
'일반안경_무표정','일반안경_활짝웃음','일반안경_찡그림',
'뿔테안경_무표정','뿔테안경_활짝웃음','뿔테안경_무표정_찡그림',
'선글라스_무표정','선글라스_활짝웃음','선글라스_찡그림',
'모자_무표정','모자_활짝웃음','모자_찡그림',
'모자+뿔테_무표정','모자+뿔테_활짝웃음','모자+뿔테_찡그림',]
fontpath = "fonts/gulim.ttc"
font = ImageFont.truetype(fontpath, 24)
b,g,r,a = 0,255,0,255
# load model
class_model = load_model('korean_face_classification_all_c_generator_200x300_l2(0.01)_dropout_model.h5')
#window on
def webon(video, size) :
# webcam on
webcam = cv2.VideoCapture(video)
webcam.set(cv2.CAP_PROP_FRAME_WIDTH, 1920)
webcam.set(cv2.CAP_PROP_FRAME_HEIGHT, 1200)
if not webcam.isOpened():
print("Could not open webcam")
exit()
while webcam.isOpened():
ret, img = webcam.read()
# style_image = style_transfer.predict(img)
# seg_mask = image_segmentation.predict(img)
# seg_mask = cv2.cvtColor(seg_mask, cv2.COLOR_GRAY2RGB)
# result_image = np.where(seg_mask, style_image, img)
faces, confidences = cv.detect_face(img)
glass, hat = 0, 0
if len(faces) :
for (x, y, w, h), conf in zip(faces, confidences) :
face = img[max(0,y-size):h+size,max(0,x-size):w+size]
face = np.array(cv2.resize(face,(200,300)))/255
pred = class_model.predict(face.reshape(1,200,300,3))
cv2.rectangle(img, (max(0, x - size), max(0, y - size)), (w + size, h + size), (255, 0, 0), 2)
img_pillow = Image.fromarray(img)
draw = ImageDraw.Draw(img_pillow, 'RGBA')
draw.text((x, y), class_names_hangul[np.argmax(pred)], font=font, fill=(b, g, r, a))
if np.argmax(pred) <= 2 :
pass
if 3<= np.argmax(pred) <= 11 or 15<=np.argmax(pred)<=17:
glass += 1
if 12<= np.argmax(pred) <= 17 :
hat += 1
img = np.array(img_pillow)
img_pillow = Image.fromarray(img)
draw = ImageDraw.Draw(img_pillow, 'RGBA')
draw.text((0, 0), f'총 사람 수 : {len(faces)}', font=font, fill=(b, g, r, a))
draw.text((0, 25), f'모자 쓴 사람 수 : {hat}', font=font, fill=(b, g, r, a))
draw.text((0, 50), f'안경 쓴 사람 수 : {glass}', font=font, fill=(b, g, r, a))
img = np.array(img_pillow)
if ret:
cv2.imshow("test", img)
if cv2.waitKey(10) == 27 :
break
webcam.release()
cv2.destroyAllWindows()
webon(0, 30)
(웹캠 로그 코드 추가 예정)
참고
딥러닝안면 인식 출석 시스템프로젝트 (3) 글에 기재된 발표 PPT 및 설명 글 참고하시면 되겠습니다.

https://github.com/min731