
음성데이터/이미지데이터를 활용한 머신러닝 성별분류 프로젝트입니다.
머신러닝 성별분류 프로젝트 (2)에 이어서 발표 PPT 및 설명 글입니다.🧐🧐🧐
발표 설명 및 PPT

안녕하십니까. 저는 2조 발표를 맡게 된 임정민입니다. 발표 바로 시작하겠습니다. 저희 프로젝트 주제는 이미지, 음성데이터를 활용한 머신러닝 남녀 성별 분류입니다.

목차입니다. 순서대로 주제/팀원 소개, 음성 데이터를 활용한 남녀 분류,이미지 데이터를 활용한 남녀 분류, 결론 , 마무리 목차대로 진행하겠습니다.

소개입니다.

저희 조는 총 5명 준호님, 현우님, 저 , 다온님 그리고 율님으로 구성되어 있습니다.

주제 선정 배경입니다. 보통 인간은 생김새 혹은 목소리를 듣고 남녀를 구분합니다. 이에 반해 컴퓨터는 어떤 특징들을 기반으로 구별하며 어느정도의 정확도를 분류할 수 있는지 알아보고자 현 프로젝트를 시작하게 되었습니다.

먼저 음성 데이터를 통한 성별 분류입니다.

데이터는 kaggle에서 가져왔습니다. 데이터 자체는 전반적으로 가공이 잘 되어있어 활용하기에 편한 형태였습니다.

원본 데이터를 잠깐 보자면 음성, 주파수와 관련된 피처들이 많고 마지막에 라벨은 남,녀로 구분되어있습니다. 다음으로 Null 값이나 0값을 전처리하기 위해 살펴보았습니다.

먼저 Null 값은 없었습니다. 이렇게 0인 값들은 mode, dfrange, modindx 라는 칼럼에 있었습니다.
샘플 3000개중 mode는 200여개, dfrange와 modindx는 65개씩 포함되어있을 것을 알 수 있습니다.
보통 몇개의 행에 0값이 있으면 평균값으로 대체하였는데, 이 경우는 저희가 직접 데이터를 만든 것은 아니기 때문에 해당 피처들에 대한 개념을 알고 그에 대한 근거로 0인 값이 존재할 수 있는지에 대해 판단하고자 하였습니다.
먼저 mode라는 피처의 개념은 공진현상 생각하시면 됩니다. 공진이란 비유하자면 소프라노가 고음을 내서 유리잔을 깨뜨리는 고유진동수인데 이게 0값을 가질 수 있느냐에 대해서 correlation 상관관계를 통해서 근거를 찾고자 하였습니다.
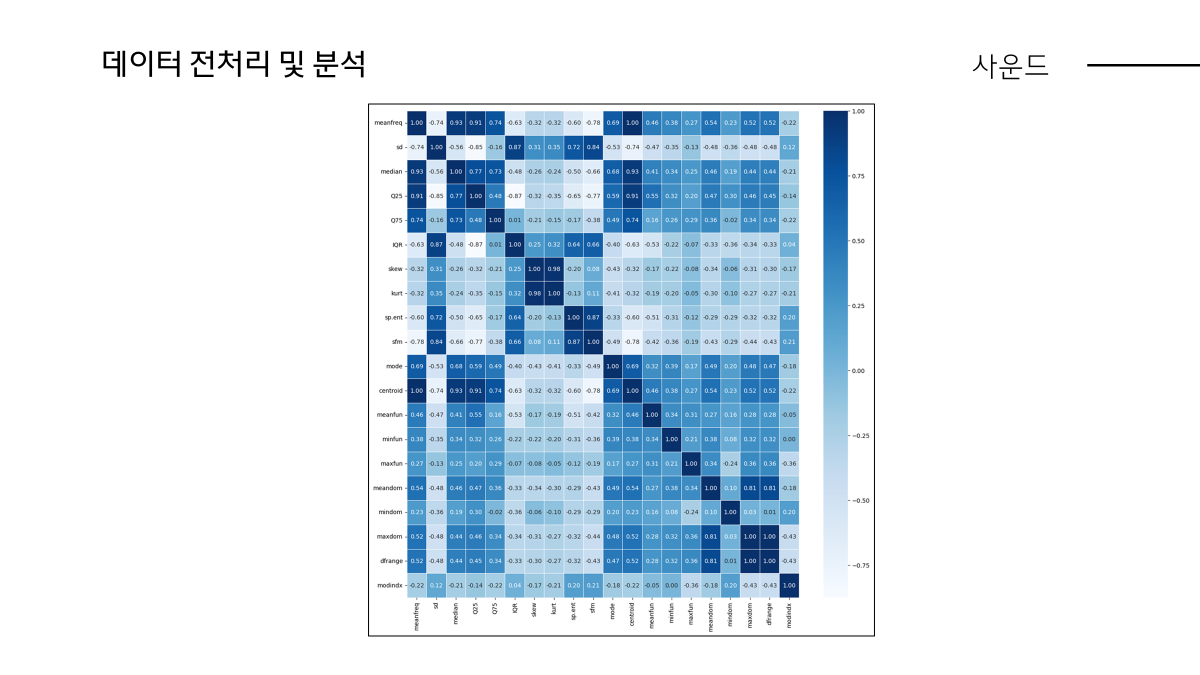
Mode과 가장 관련있는 피처는 0.69 median입니다.
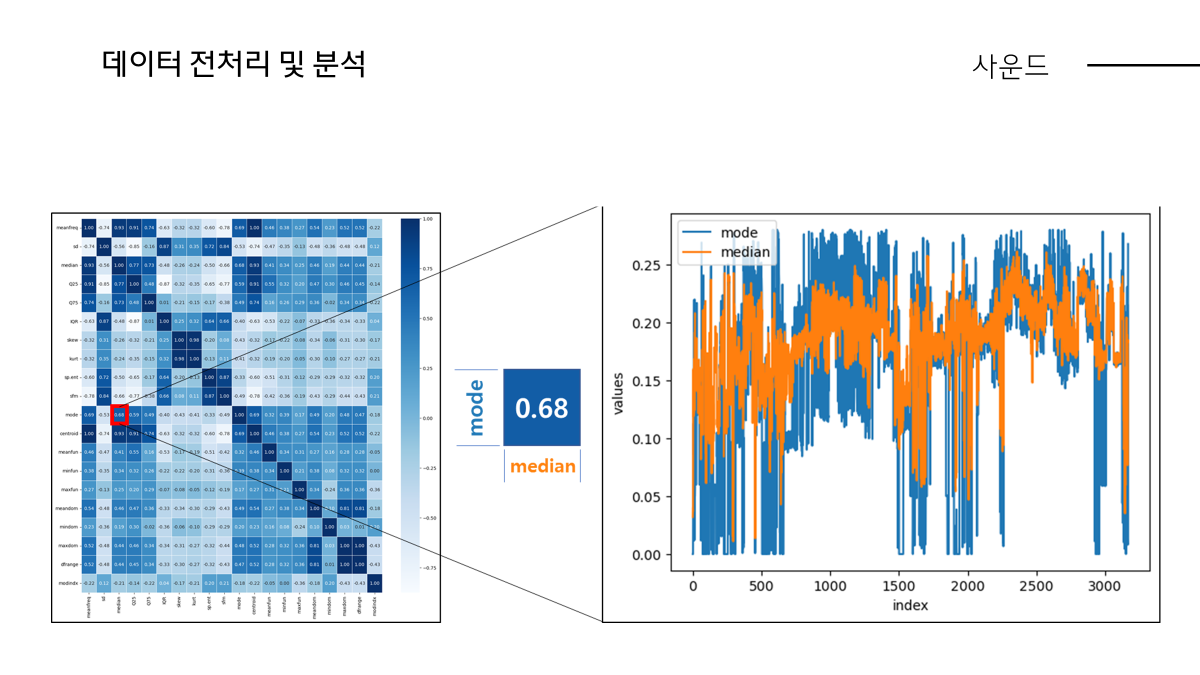
Median은 주파수의 중앙값입니다. 스스로 판단하기에 median의 경향에 따라 mode 값도 변화하겠다고 생각하여 0값이 누락되거나 손실된 값이 아니다라고 판단하여 따로 전처리하지는 않았습니다.

두번째로 dfrange입니다. dfrange는 수식을 통해 어느정도 이해가 가능합니다. dfrange는 maxdom-mindom인데 바로 앞피처에 maxdom,mindom이 있으니 이것을 뺀값이 dfrange이고 때에 따라 정확히 0이 나올수있어 이부분도 그대로 사용했습니다.

다음으로 modindx입니다. modindx는 개념과 수식자체가 복잡한데 수식적으로 dfrange가 분모로 들어가는 식으로 dfrange==0 이면 modindx도 계산할 수 없어 0이기 때문에 ( value count == 0 )( dfrange와 modindx는 65개씩) 것을 확인하여 이 modindx 값도 그대로 사용하였습니다.
이외 추가적인 전처리 과정으로는 label 값들은 레이블인코딩으로, 피처별 값들이 균등하지 않기 때문에 StandardScaler 처리했습니다.

다음으로 이 피처 분석에 관한 그래프인데 각 피처별로 어떻게 남자, 여자별 value가 어떻게 분포해있는지에 대한 그래프인데, 사실 이 그래프들을 보면 남녀간의 목소리의 어떤점이 다른지 알 수 있습니다. 초록색, 빨간색 그래프가 많이 다른 것이 남녀간의 차이라고 보시면 되겠고 전체 다보기에는 복잡하실 것 같아서 다음과 같이...
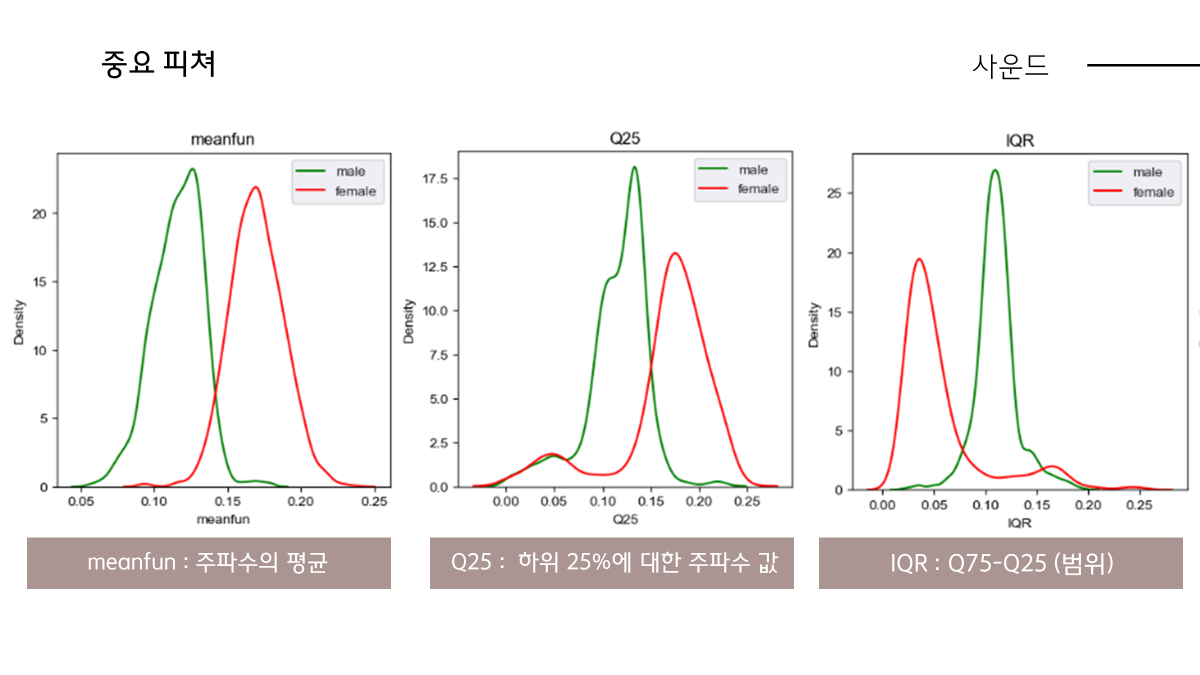
Menafun,Q25 그리고 IQR 그래프 기준으로 말씀드리겠습니다. meanfun은 음향 주파수의 평균값들입니다. 초록선이 남자, 빨간선이 여자로 보통 직관적으로 남녀 목소리를 구분하는데 음의 높이가 높으면 여자 낮으면 남자라고 생각하는데 그 부분이 데이터로 드러난 그래프라고 보시면 되겠습니다.
Q25 개념적으로는 전체 측정값을 4등분하여 오름차순으로 상위 25%인 값, 남자가 좀더 낮은 음을 낼 수 있는 것으로 나옵니다. IQR 어떤 범위라고 보시면 되는데 방금 말씀드린 Q25 수식적으로 들어가는데 Q75-Q25 입니다.
Q25는 남자가 더 낮고 Q75는 거의 비슷한 값으로 남자가 더 큰 범위를 갖습니다.
결론적으로 모델 돌리기전 그래프만 봤을 때 이런 요인들이 중요하게 작용하지 않을까에 대해 추측할 수 있었습니다.

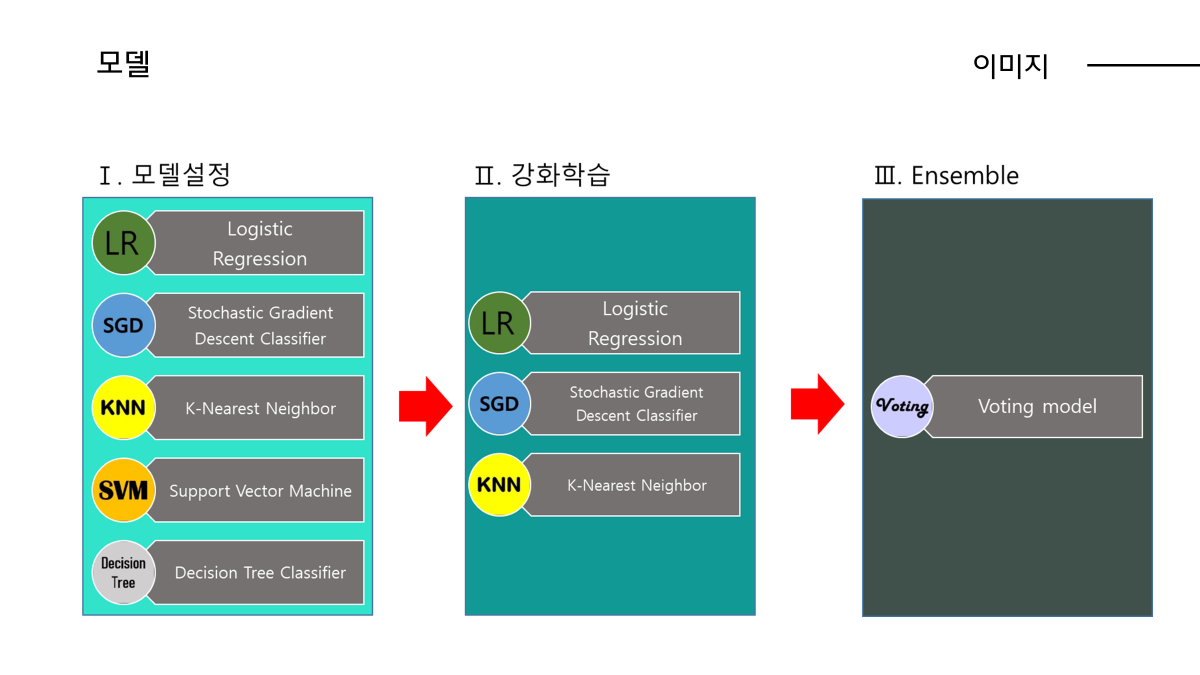
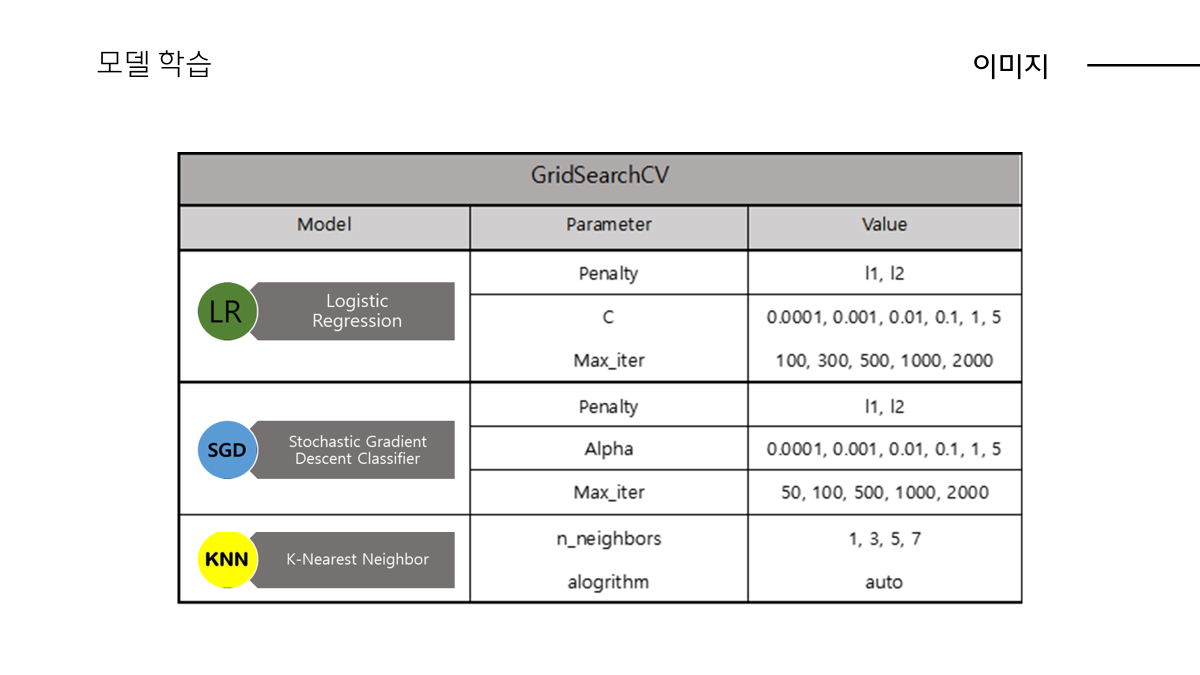
다음으로 활용한 모델은 조기중단, 교차검증이 내장된 XGBoost,LightGMB입니다.
모두 트리 기반 앙상블 알고리즘이고 둘 다 조기중단, 교차검증이 내장되어있는 XGBoost, LightGBM 모델사용하였습니다.
XGBoost : 균형 트리 분할
LightGBM : 리프 중심 트리 분할
이 모델들을 기반으로 학습한 결과는 다음과 같습니다.

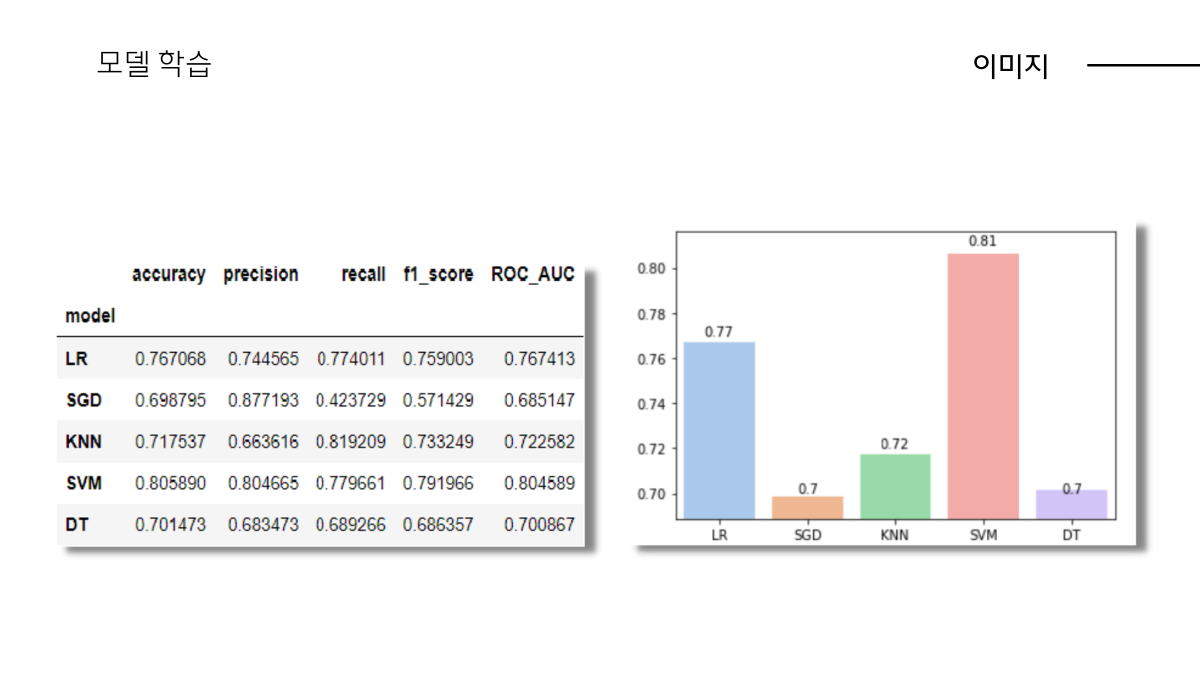
평가항목은 정확도,정밀도,재현율,f1스코어,roc_auc입니다.
정확도는 당연히 높을수록 좋은 성능을 나타냅니다. 정밀도,재현율은 저희 주제가 성별 분류이고 남자만 혹은 여자만 잘 분류하는 것이 좋은 것이 아니기 때문에 균등하게 가져가고자 하였고 이에 따라 f1스코어가 높을 때, 그리고 roc_auc는 1에 가까운 모습입니다.
좀더 구체적으로 ( accuracy ) 정확도는 다음과 같이 두 모델 모두 97%이상으로 나옵니다. 이를 보면 머신러닝, 녹음실에서 깔끔하게 녹음된 음성데이터를 통해 성별 분류하는 작업이 크게 어려운 작업은 아닌 것으로 보입니다.
( roc_auc ) 다음으로 roc_auc 그래프는 높은 정확도와 같이 왼쪽상단 테두리에 가까운 형태로 나옵니다.

( 피처 중요도 )
각 모델별 feature importance 입니다. 앞서 그래프에서 보신 내용처럼 평균 주파수 meanfun이 결과가 가장 영향을 많이 미치는 피처이고 다음으로 IQR, minfun 등입니다.
여기서 알 수 있는 점은 모델마다 분류하는 방식이 다르기 때문에 피처 중요도가 모델별로 다를 수 있다는 점입니다.
여기까지 해서 kaggle 데이터 기반으로 측정해보았는데 수집한 데이터가 잘 정제된 데이터이기 때문에...
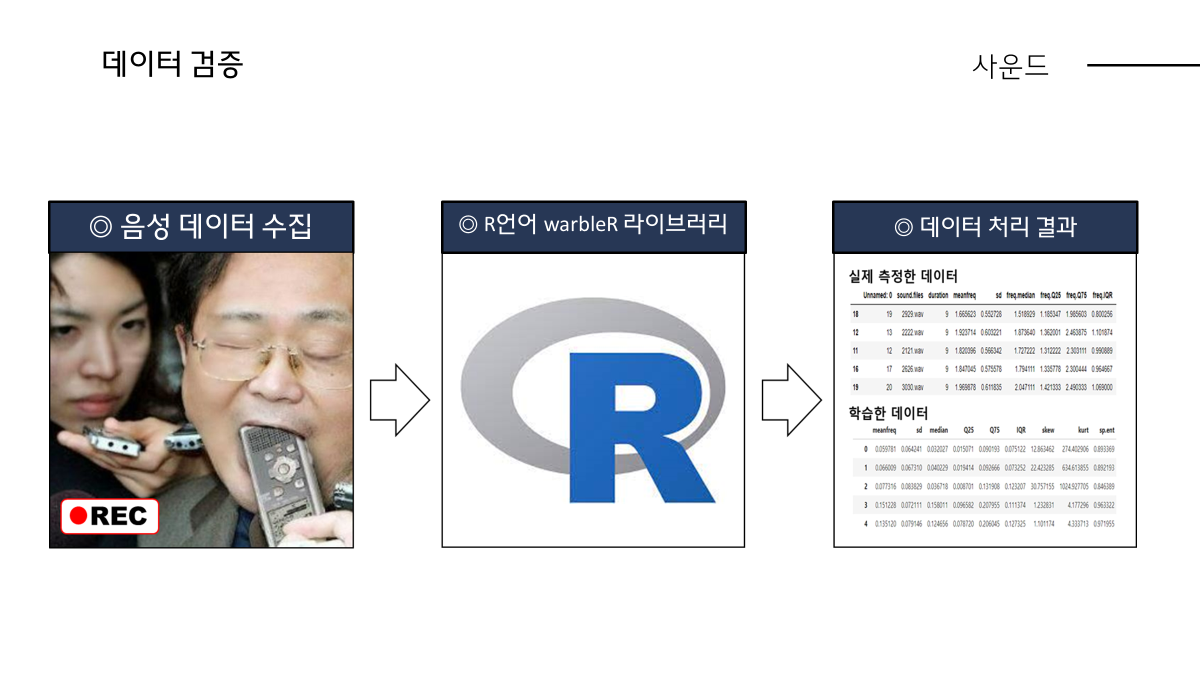
저희는 이 학습된 모델을 기반으로 어제와 그저께 직접 학생분들 목소리 녹음한 20개의 데이터을 통해 검증해보고자 하였습니다.
핸드폰으로 직접 녹음하여 수집했습니다. 또 학습된 모델에 데이터를 넣어 검증하려면 학습했던 데이터 형식의 데이터프레임에 맞게 전처리 해주는 과정이 필요하여 kaggle에서 언급한 R이라는 언어의 음향분석 라이브러리 warbleR의 함수를 이용하여 형식을 맞추어 주었습니다.

( 실제 측정 데이터 vs 학습 데이터 )
실제로 추출한 데이터는 20개 정도로 했고 남녀 레이블 10개씩 준비했습니다.
저희가 녹음한 파일들을 모델에 넣어 검증하려면 학습한 데이터프레임과 같은 형식으로, 주파수와 관련된 칼럼으로 만든뒤 돌려야하기 때문에 따로 전처리했습니다.

Pickle로 저장한 모델을 다시 불러서 검증하면 XGB, LGBM 두 모델 기준으로 각 60%, 65% 정확도가 나옵니다. 저희 예상보다는 높은 정확도는 아니였습니다.
이에 대한 이유를 찾아보자면 학습/검증하는 데이터들을 측정하는 장비나 환경이 일정하지 않은 것, 그리고 동일한 문장으로 녹음하지 않았던 것이 원인이라고 생각합니다.

실제 데이터로 보면 좌측에 있는 데이터프레임에 보면 원본데이터 기준 남자의 평균 주파수, 가장 중요한 피처인 meanfun기준으로 남자는 116Hz , 여자는 170hz 정도를 가져야 정상인데 실측 데이터 기준으로는 남자 188hz, 여자 267hz로 학습한 데이터와 크게 차이나는 것이 보입니다.
이에 따라 LGBM 모델 검증 기준으로 남자이지만 meanfun이 크게 측정됌으로써 여자로 분류되어 틀린 경우가 많았고 측정 데이터의 퀄리티에 따라 모델 성능이 저하된 것을 깨달았습니다. 이에 대한 시각화 그래프를 보여드리면 다음과 같습니다.
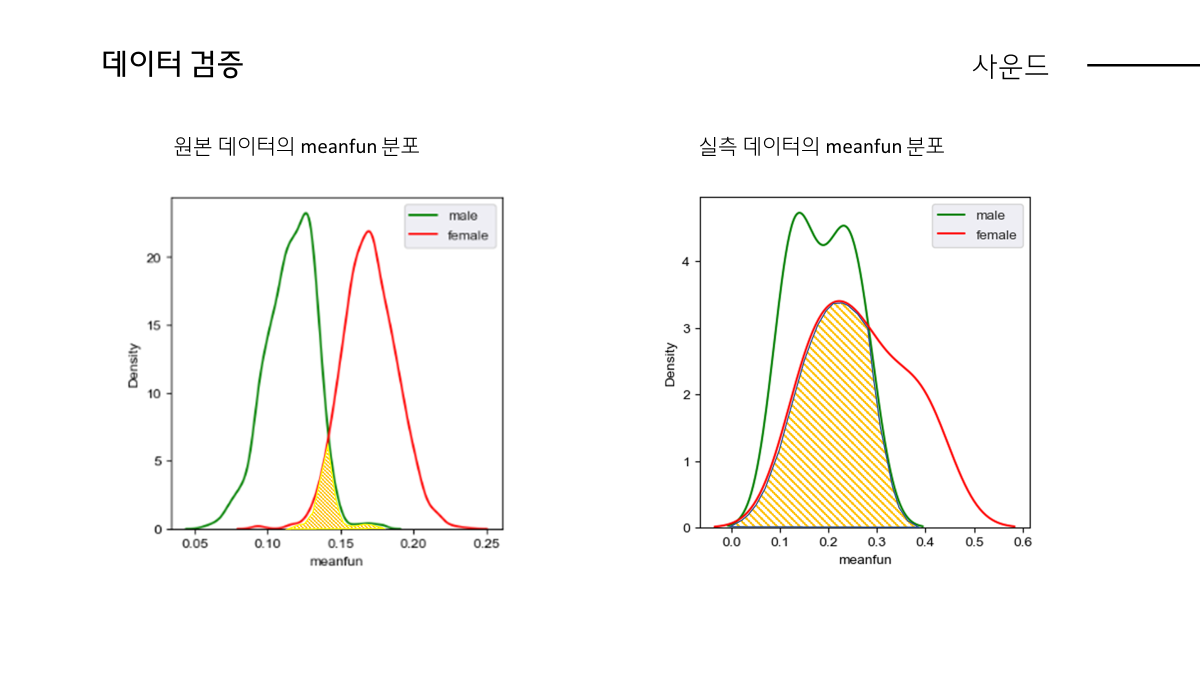
(meanfun 그래프)
학습한 데이터는 남자와 여자가 meanfun으로 구분되는데 반해 실측 데이터 기준으로는 남자의 meanfun 범위가 전반적으로 넓어지고 여자의 meanfun과 겹치는 부분이 많아 모델이 혼동한것이 증명됩니다.

이렇게 해서 음성 데이터 성별 분류는 크게 3가지로 정리됩니다.
-
정제된 녹음실에서 녹음한 음성 데이터를 활용한 다면 높은 정확도로 성별을 분류할 수 있다.
-
컴퓨터가 목소리로 성별을 구분하는 방식은 사람이 직관적으로 판단하는 것과 같이 남자목소리의 낮음 여자목소리의 높음으로 분류한다.
-
이는 사람들이 체감하는 '남녀 목소리의 가장 큰 차이는 음의 높이' 라는 주장을 뒷받침한다.
입니다. 이상으로 음성 데이터에 대한 부분은 마치고 다음으로 이미지를 통한 성별 분류 발표 이어서 진행하겠습니다.
(현우님의 이미지 데이터 기반 성별 분류 파트)

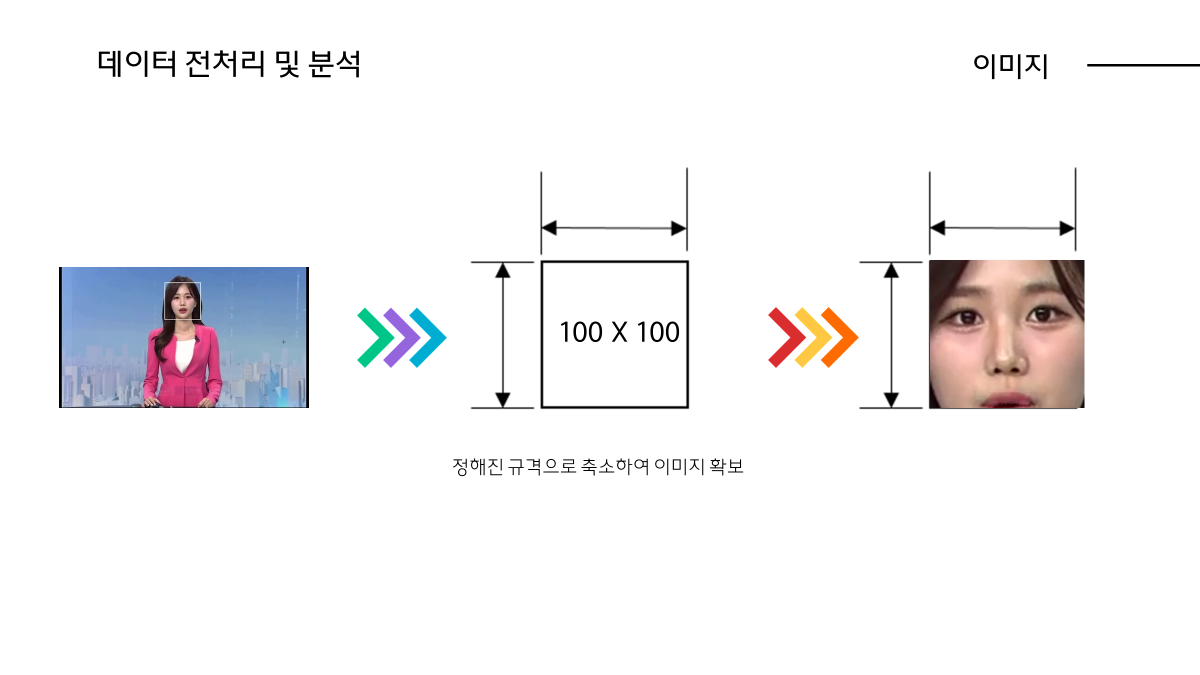
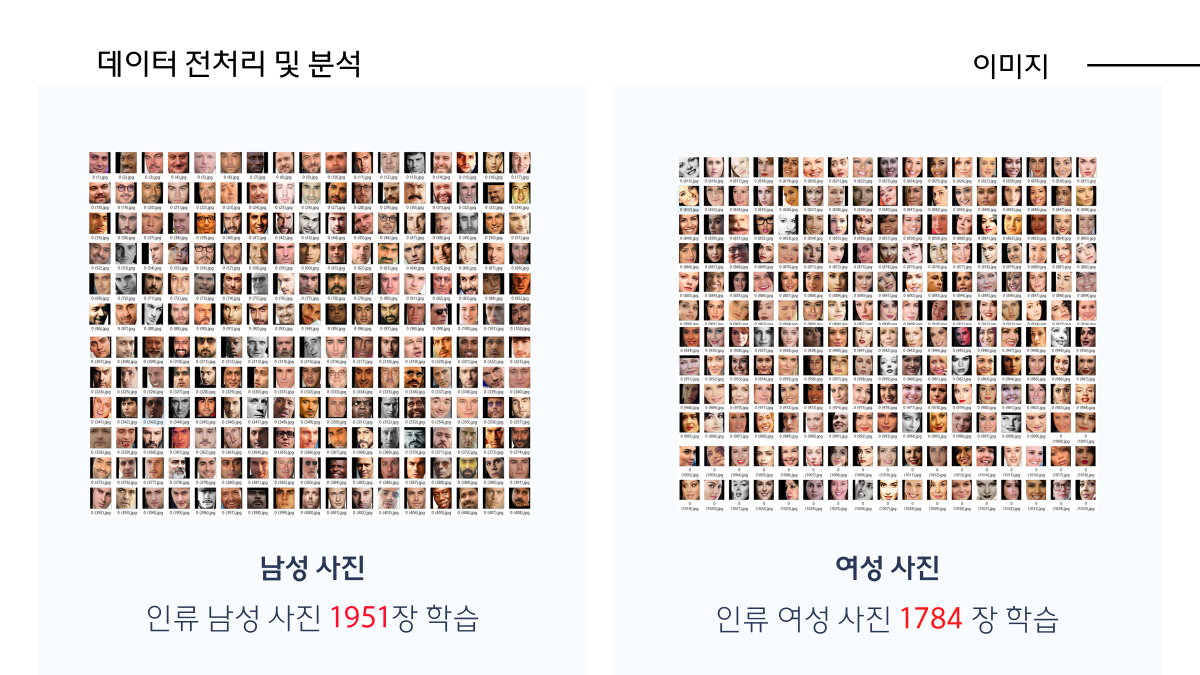


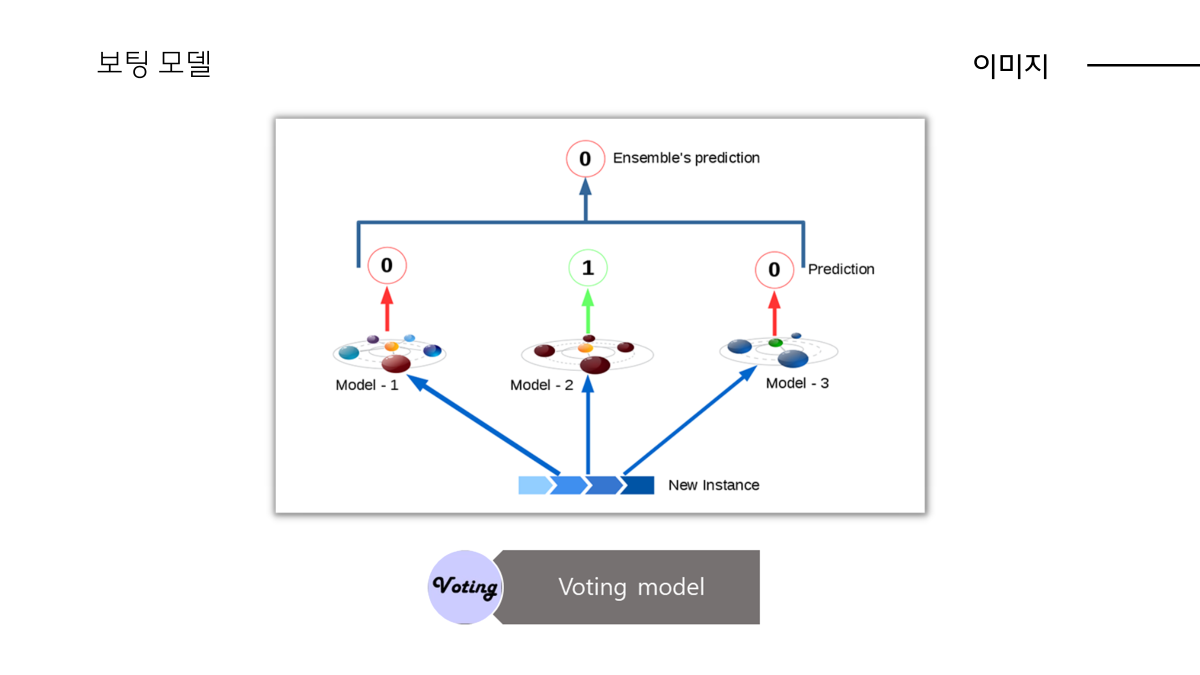






마치며...
긴 글 읽어주셔서 감사합니다. 이번 프로젝트는 초기에 팀회의 단계에서 팀원별로 이미지 분류 모델을 주제로 원하는 인원과 사운드 분류 모델을 주제로 원하는 인원으로 나눠어졌습니다. 그리하여 저희는 이를 둘다 반영하여 각각의 모델을 만들어보고 반대로 바꾸어 리뷰하는 방식으로 진행하였습니다.
저는 음성 분류에 관심이 있어 남녀간 음성데이터를 주파수적인 특징들로 분석하고 분류하여 비정형데이터를 정형데이터화시키는 전처리 작업을 진행하였습니다. 가장 기억에 남는 점은 핸드폰으로 실제 강의장 학생들/강사님 목소리를 녹음하여 데이터화 시킬 때 배워본 적 없는 'R' 이라는 데이터 분석언어를 활용했다는 점입니다. 이때 경험을 토대로, 이전에 다루어 본 적이 없는 언어이더라도 직접 Document를 찾아보고 코딩해보며 새로운 언어를 활용하는데에 두려움이 없어진 것 같습니다.✌✌✌ 이후 opencv를 활용한 이미지 분류 모델의 코드를 보며 이미지 데이터를 배열로 바꾸어 모델이 학습시키기 적합한 데이터 형식으로 바꾸는 작업에 대해 알게 되었습니다.
첫 인공지능 프로젝트인 만큼 기대반,걱정반으로 준비하였는데 모든 팀원들이 믿고 따라주었고 원하는 기능들을 구현하여 뜻깊은 시간이였습니다. 감사합니다.👨👧👧👨👧👧👨👧👧
