
음성데이터/이미지데이터를 활용한 머신러닝 성별분류 프로젝트입니다.
머신러닝 성별분류 프로젝트 (1)에 이은 코드리뷰 글입니다.🧐🧐🧐
코드 리뷰
- 음성 분류 모델
1) Kaggle에서 받은 음성데이터 전처리 및 시각화
https://www.kaggle.com/datasets/primaryobjects/voicegender
import pandas as pd
df_voice = pd.read_csv('data/voice.csv')
df_voice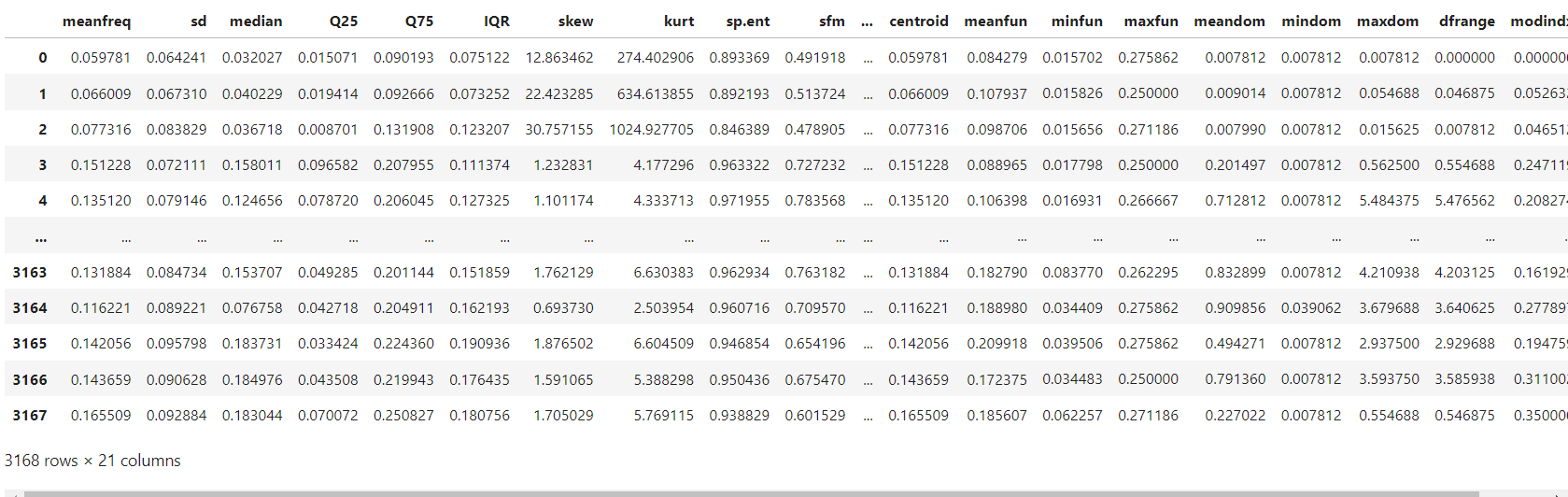
# features간 상관관계
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(15,15))
sns.heatmap(data = df_voice.corr(), annot=True,
fmt = '.2f', linewidths=.5, cmap='Blues')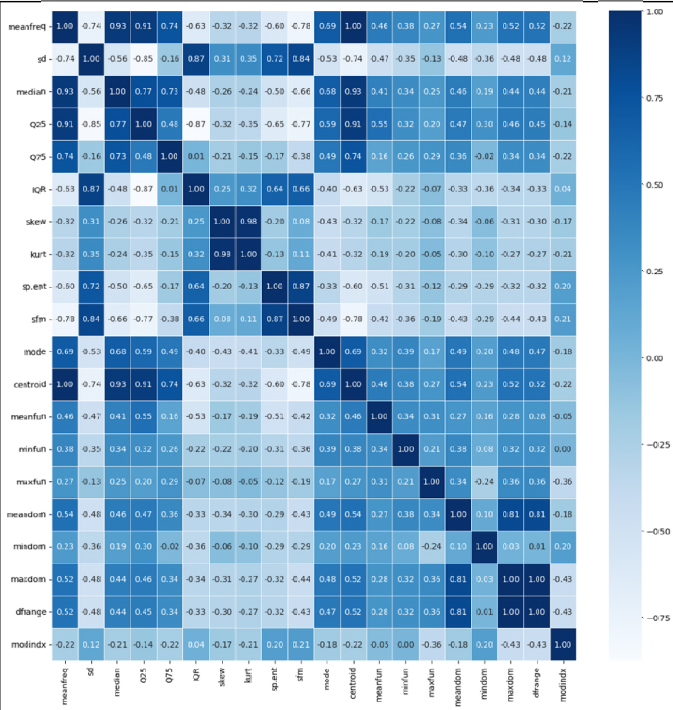
# mode 피처와 meanfreq 피처의 비슷한 경향성
df_voice[['mode','meanfreq']].plot(xlabel='index',ylabel='values')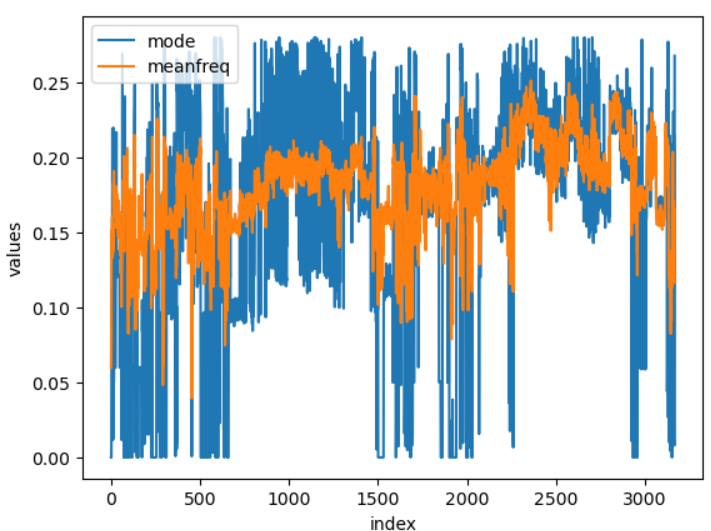
# 남녀간 features 값들의 분포
plt.subplots(4,5,figsize=(25,20)) # subplots 갯수, 크기
sns.set_style('darkgrid') # 격자무늬
for k in range(1,21):
plt.subplot(4,5,k) # 위치 지정
plt.title(df_voice.columns[k-1]) # 제목지정
sns.kdeplot(df_voice.loc[df_voice['label'] == 'male', df_voice.columns[k-1]], color= 'green',label='male')
sns.kdeplot(df_voice.loc[df_voice['label'] == 'female', df_voice.columns[k-1]], color= 'red',label='female')
plt.legend() # 그래프의 label 명 표시해줌
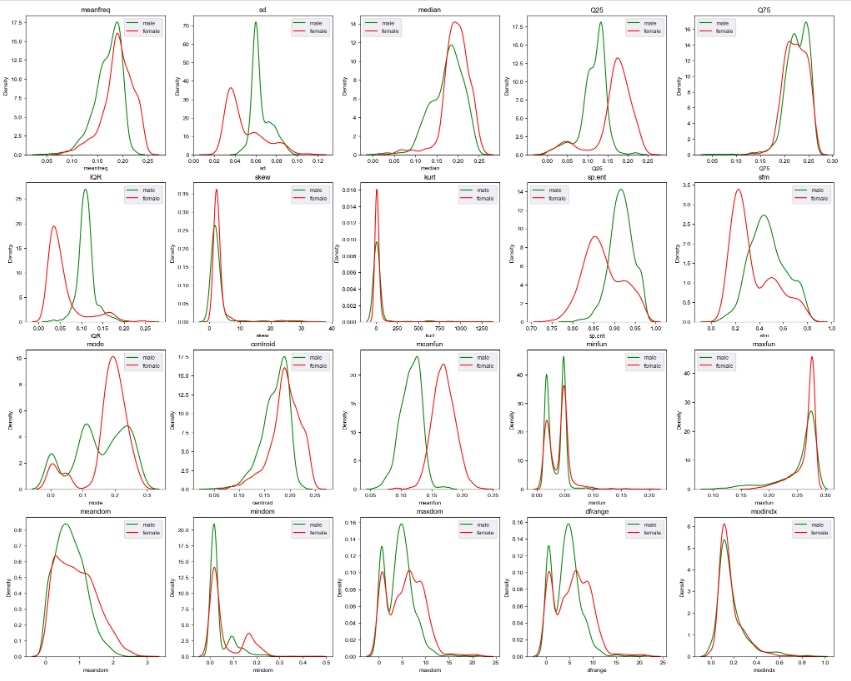
def get_preprocessing_df():
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler
df_old = pd.read_csv('data/voice.csv')
df_new = pd.read_csv('data/voice.csv')
# Nan,0 처리
# 일반적으로 한 feature에 대해 몇몇개의 값이 Nan or 0 이라면 평균값 처리를 했지만
# feature 개념상 Nan or 0 이 정상적인 값인 경우도 있었다.
# 확인 결과 mode,dfrange,modindx의 0값들 모두 정상적인 값이므로 따로 전처리할 필요가 없다.
# 이는 데이터 전처리 시 해당 분야에 대한 feature 도메인 지식이 있어야 함을 깨닫게 했다.
# df_new['mode'] = df_old['mode'].replace(0.0,old_df['mode'].mean())
# df_new['dfrange'] = df_old[['dfrange','maxdom','mindom']].apply(lambda x:x[1]-x[2] if x[0]==0 else x[0],axis=1)
# df_new['modindx'] = = df_old['modindx'].replace(0.0,old_df['modindx'].mean())
# 레이블 인코딩
# 남자 1, 여자 0
encoder = LabelEncoder()
items = df_old['label']
encoder.fit(items)
labels_endcoded = encoder.transform(items)
df_labels_encoded = pd.DataFrame(data=labels_endcoded,columns=['label'])
df_new['label'] = df_labels_encoded
# 정규화스케일링
# 원본데이터가 균등하면 MinmaxScaler
# 원본데이터가 균등하지않으면 StandardScaler
columns_list = list(df_old.columns)
columns_list.remove('label')
scaler = StandardScaler()
items = df_old.drop(columns='label')
scaler.fit(items)
features_scaled = scaler.transform(items)
df_features_scaled = pd.DataFrame(data=features_scaled,columns=columns_list)
df_new_label = pd.DataFrame(df_new['label'])
df_new = pd.concat([df_features_scaled,df_new_label],axis=1)
return df_new
df_voice = get_preprocessing_df()2) 모델 정의
# XGBoost : GBM기반, GBM보다 빠른 속도(병렬 수행), 일반적으로 다른 머신러닝보다 뛰어난 예측 성능, 과적합 해결(Tree pruning:이득이 없는 분할 가지치기),cv 내장, 조기 중단
# LightGBM : XGBoost보다 훨씬 빠른 속도, 비슷한 성능
3) 모델 학습
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from xgboost import plot_importance
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
def get_dataset_df(df_voice):
X = df_voice.iloc[:,:-1]
y = df_voice.iloc[:,-1]
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=156)
X_tr,X_val,y_tr,y_val = train_test_split(X_train,y_train,test_size=0.1,random_state=156)
return X_train,X_test,y_train,y_test,X_tr,X_val,y_tr,y_val
X_train,X_test,y_train,y_test,X_tr,X_val,y_tr,y_val = get_dataset_df(df_voice)
def get_clf_models():
list_models = []
xgb_wrapper = XGBClassifier(n_estimators=1000,learning_rate=0.05)
list_models.append(xgb_wrapper)
lgbm_wrapper = LGBMClassifier(n_estimators=1000,learning_rate=0.05)
list_models.append(lgbm_wrapper)
return list_models
list_models = get_clf_models()
def get_clf_predict(list_models):
list_pred = []
list_pred_proba = []
for i in range(len(list_models)):
print(f"{list_models[i].__class__}")
evals = [(X_tr,y_tr),(X_val,y_val)]
list_models[i].fit(X_tr,y_tr,early_stopping_rounds=50,eval_metric='logloss',eval_set=evals,verbose=True)
pred= list_models[i].predict(X_test)
list_pred.append(pred)
pred_proba = list_models[i].predict_proba(X_test)[:,1]
list_pred_proba.append(pred_proba)
# XGBoost 기준
# xgb_wrapper = XGBClassifier(n_estimators=1000,learning_rate=0.05)
# evals = [(X_tr,y_tr),(X_val,y_val)]
# xgb_wrapper.fit(X_tr,y_tr,early_stopping_rounds=50,eval_metric='logloss',eval_set=evals,verbose=True)
# pred_xgb = xgb_wrapper.predict(X_test)
# pred_proba_xgb = xgb_wrapper.predict_proba(X_test)[:,1]
return list_pred,list_pred_proba
list_pred,list_pred_proba = get_clf_predict(list_models)4) 모델 평가
def get_clf_eval(y_test,list_pred,list_pred_proba,list_models):
from sklearn.metrics import accuracy_score,precision_score
from sklearn.metrics import recall_score,confusion_matrix
from sklearn.metrics import f1_score,roc_auc_score
import time
list_confusion = []
list_accuray = []
list_precision = []
list_recall = []
list_f1 = []
list_roc_auc = []
df_evaluation = pd.DataFrame(columns=['accuracy','precision','recall','f1_score','ROC_AUC'])
for i in range(len(list_pred)):
print(f"i는 {i}")
print(f"{str(list_models[i]).split('(')[0]}")
start = time.time()
# 혼동행렬(오차행렬),정확도, 정밀도, 재현율,f1,roc_auc
confusion = confusion_matrix(y_test,list_pred[i]) # 혼동행렬
list_confusion.append(confusion)
accuracy = accuracy_score(y_test,list_pred[i]) # 정확도
list_accuray.append(accuracy)
precision = precision_score(y_test,list_pred[i],pos_label=1) # 정밀도
list_precision.append(precision)
recall = recall_score(y_test,list_pred[i],pos_label=1) # 재현율
list_recall.append(recall)
f1 = f1_score(y_test,list_pred[i],pos_label=1)
list_f1.append(f1)
roc_auc = roc_auc_score(y_test,list_pred_proba[i])
list_roc_auc.append(roc_auc)
end = time.time()
df_evaluation = df_evaluation.append({'accuracy':accuracy,'precision':precision,'recall':recall,'f1_score':f1,'ROC_AUC':roc_auc},ignore_index=True)
print(f"{list_models[i].__class__}")
print('오차행렬')
print(confusion)
print(f'정확도:{accuracy:.4f}, 정밀도:{precision:.4f}, 재현율:{recall:.4f}, f1스코어:{f1:.4f}, roc_auc:{roc_auc:.4f}') # :.4f 소수 4자리까지
print(f'실행 시간:{end-start:.6f}')
print("\n")
df_evaluation = df_evaluation.set_axis([str(list_models[i]).split('(')[0] for i in range(len(list_models))], axis='index')
return df_evaluation
df_evaluation = get_clf_eval(y_test,list_pred,list_pred_proba,list_models)
df_evaluation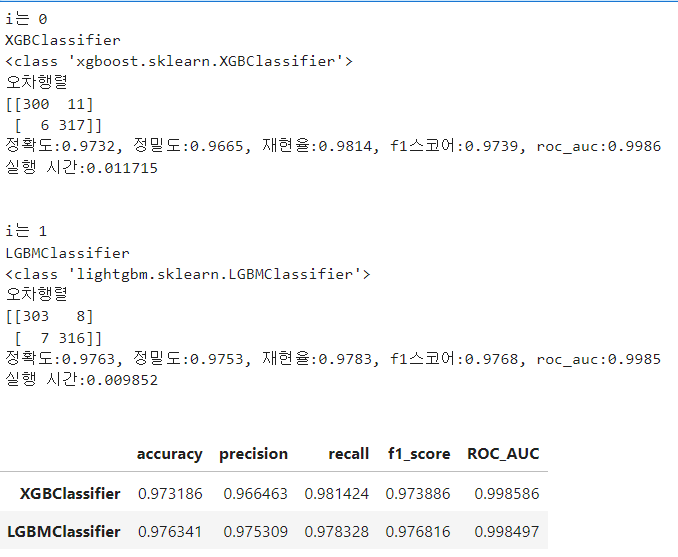
plt.figure(figsize=(4,4))
sns.set_palette("pastel")
g = sns.barplot(x=df_evaluation.index,y=df_evaluation['accuracy'],ci=None,errwidth=50)
for i in range(len(df_evaluation.index)):
print(i)
g.text(x = i, y=np.round(df_evaluation['accuracy'].values[i],4),s=np.round(df_evaluation['accuracy'].values[i],4),ha='center')
plt.show()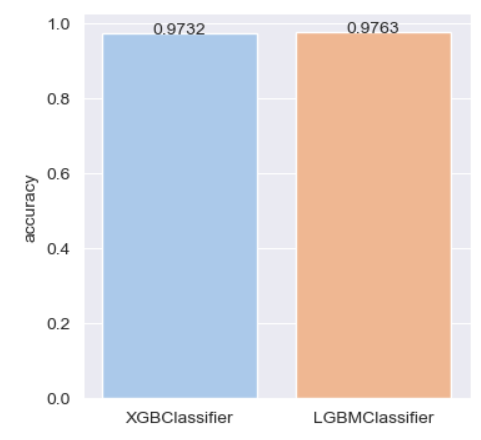
5) 모델 평가 시각화 및 해석
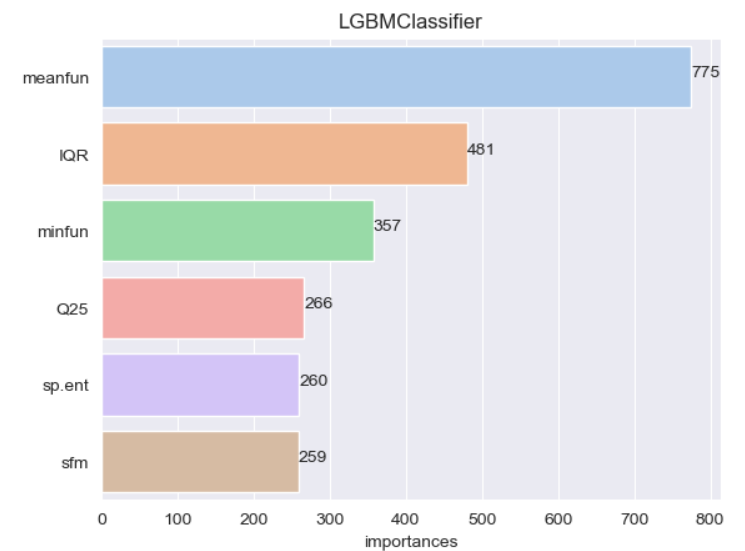
def get_feature_importances(list_models,X_train):
import matplotlib.pyplot as plt
import seaborn as sns
for i in range(len(list_models)):
features_importance_values = list_models[i].feature_importances_
features_importance_df = pd.DataFrame(features_importance_values,index=X_train.columns)
features_importance_df = features_importance_df.rename(columns={0:'importances'})
features_importance_df = features_importance_df.sort_values('importances',ascending=False)
sns.set_palette("pastel")
g = sns.barplot(x=features_importance_df['importances'][:6],y=features_importance_df.index[:6],ci=None)
g.set_title(str(list_models[i]).split('(')[0])
for i in range(len(features_importance_df.index[:6])):
g.text(x = np.round(features_importance_df['importances'][:6].values[i],4), y=i,s=np.round(features_importance_df['importances'][:6].values[i],4))
plt.show()
get_feature_importances(list_models,X_train) # 모델별로 importances 표현방식이 다름을 알 수 있다.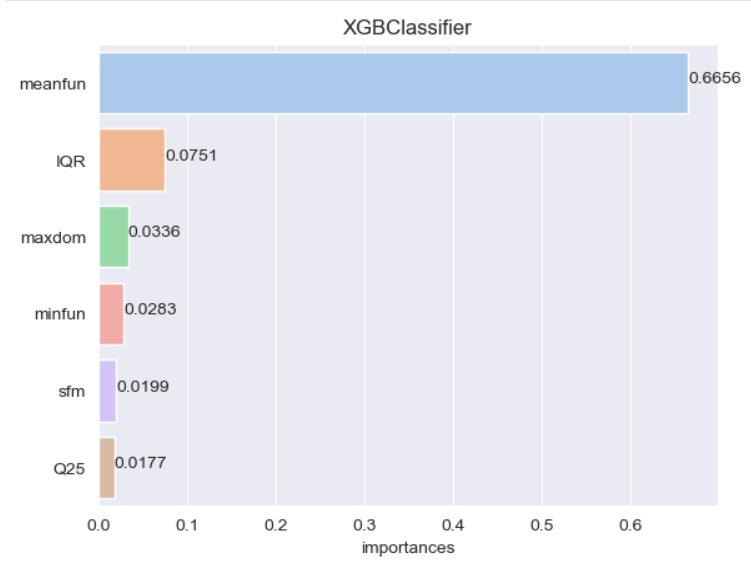
# roc curve
import matplotlib.patches as patches
from sklearn.metrics import roc_curve,auc
def get_roc_curve(list_models,X_test,y_test):
for i in range(len(list_models)):
plt.figure(figsize=(8,8))
fpr, tpr, thresholds = roc_curve(y_test, list_models[i].predict_proba(X_test)[:,1])
plt.plot(fpr, tpr, label='ROC')
plt.plot([0,1], [0,1], "k--", label="Random")
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.title(str(list_models[i]).split('(')[0] + ' ROC curve')
plt.legend()
plt.grid()
plt.show()
get_roc_curve(list_models,X_test,y_test)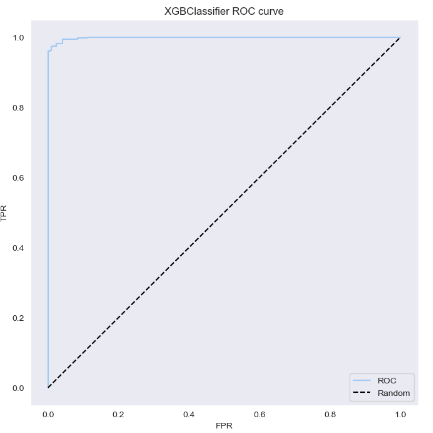
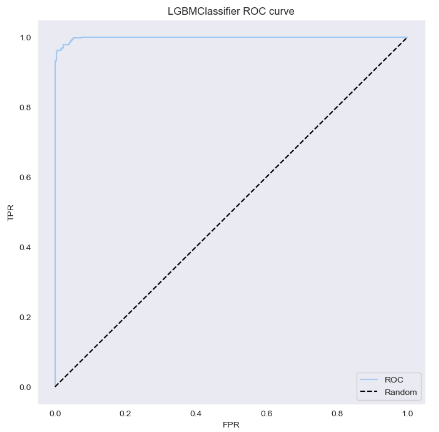
# list_models : 모델이 저장된 list
import pickle
with open('XGBoost.pickle','wb') as fw:
pickle.dump(list_models[0],fw)
with open('LightGBM.pickle','wb') as fw:
pickle.dump(list_models[1],fw)6) 실제 측정 데이터 전처리/검증/평가 (*R 언어 활용)
# R 코드
library(warbleR) # 음성분석 라이브러리 warbleR 설치
# 데이터프레임 객체 생성1
dataframe <- data.frame("13.wav", 1, 1, 10)
# 데이터프레임 객체 생성2
names(dataframe) <- c("sound.files", "selec", "start", "end")
# 주파수 분석 함수 사용
# 음성데이터 벡터화
# a라는 객체에 저장
a <- specan(X=dataframe, bp=c(1, 3),harmonicity = TRUE)
# 음성데이터 a 객체 csv파일에 'w'
write.csv(a,file='custom.csv') # 학습된 모델로 실제 측정한 데이터 분류하기
import pandas as pd
import numpy as np
# 실제 측정한 음성데이터 불러오기
df_custom = pd.read_csv('data/custom_final.csv')
df_custom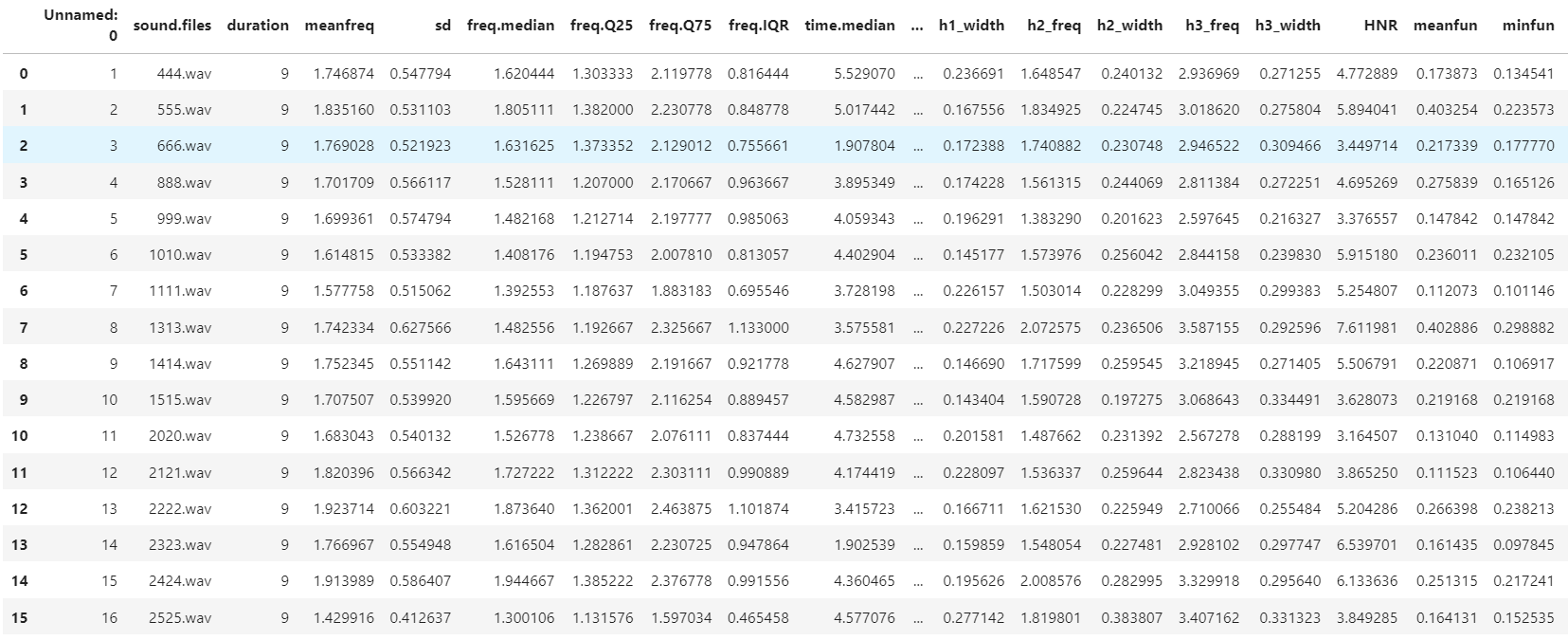
# 실제 측정한 음성데이터 df 모델에 맞게 전처리
df_custom = df_custom.drop(columns='Unnamed: 0')
df_custom = df_custom.drop(columns=['sound.files','duration','time.median','time.Q25'])
df_custom = df_custom.drop(columns=['time.Q75','time.IQR','time.ent','entropy','startdom','enddom','dfslope'])
df_custom = df_custom.drop(columns=['meanpeakf','h1_freq','h1_width','h2_freq','h2_width','h3_freq','h3_width','HNR'])
df_custom = df_custom.rename(columns={'freq.median':'median','freq.Q25':'Q25','freq.Q75':'Q75','freq.IQR':'IQR'})
# custom의 빈 mode 값들은
# 원본데이터의 mode-meanfreq 상관관계를 파악해서 대입
df_custom.insert(11,'mode',df_custom['meanfreq']*0.8834946753096443)
df_custom.insert(11,'centroid',df_custom['meanfreq'])
df_custom = df_custom[['meanfreq', 'sd', 'median', 'Q25', 'Q75', 'IQR', 'skew', 'kurt',
'sp.ent', 'sfm', 'mode', 'centroid', 'meanfun', 'minfun', 'maxfun',
'meandom', 'mindom', 'maxdom', 'dfrange', 'modindx','label']]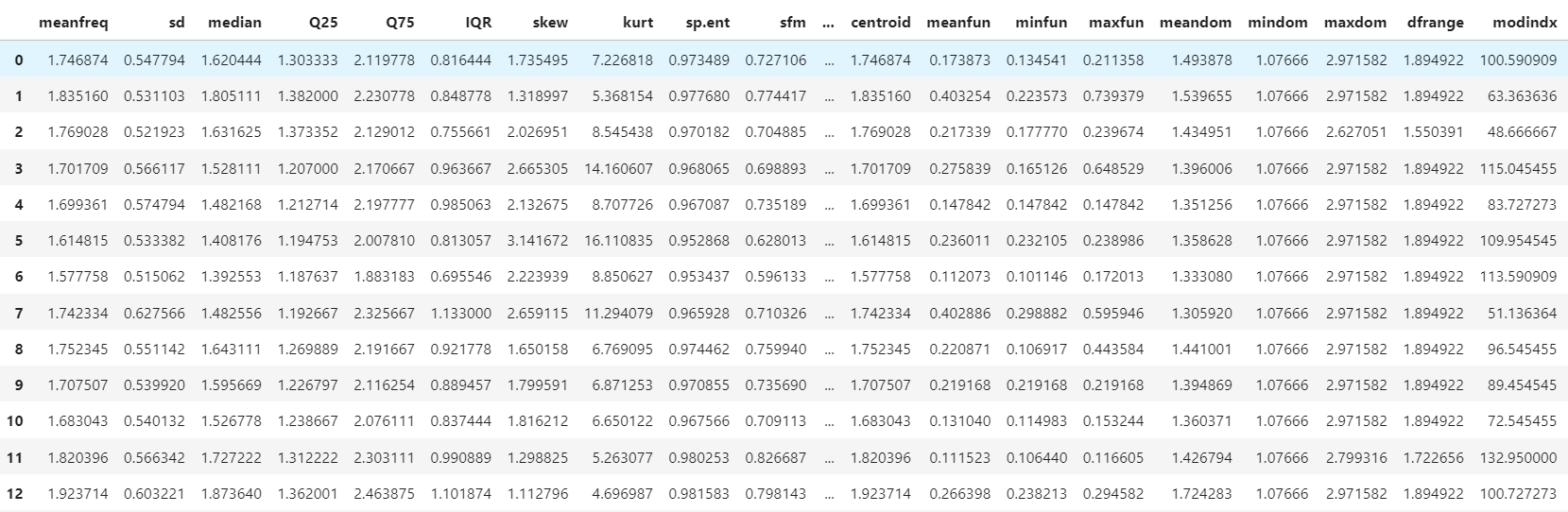
# 저장된 모델 pickle 불러오기
list_models = []
list_pred = []
list_accuracy = []
import pickle
with open('XGBoost.pickle', 'rb') as f:
model = pickle.load(f)
list_models.append(model)
with open('LightGBM.pickle', 'rb') as f:
model = pickle.load(f)
list_models.append(model)# 실제 측정 음성데이터 평가
from sklearn.metrics import accuracy_score
X_test = df_custom.drop(columns='label')
y_test = df_custom['label']
df_evaluation = pd.DataFrame(columns=['accuracy'])
for i in range(len(list_models)):
pred = list_models[i].predict(X_test)
list_pred.append(pred)
pred_proba = list_models[i].predict_proba(X_test)
accuracy = accuracy_score(y_test,list_pred[i]) # 정확도
list_accuracy.append(accuracy)
print(list_models[i].__class__.__name__)
print(f"(남자=1, 여자=0)\n")
print(f"예측값 : {pred}")
print(f"실제값 : {df_custom['label'].values}")
print(f"(각 인덱스 값이 같으면 정답, 다르면 오답)")
print(f"\npred_proba: \n{pred_proba}")
print(f"\n정확도: {list_accuracy[i]}")
print("--------------------------------")
df_evaluation = df_evaluation.append({'accuracy':list_accuracy[i]},ignore_index=True)
df_evaluation = df_evaluation.set_axis([str(list_models[i]).split('(')[0] for i in range(len(list_models))], axis='index')

df_evaluation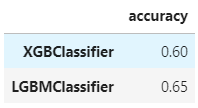
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(4,4))
plt.title("Accuracy of models\n(Sesac Students)\n")
plt.ylim(0.0,1.0)
sns.set_palette("pastel")
g = sns.barplot(x=df_evaluation.index,y=df_evaluation['accuracy'],ci=None,errwidth=50)
for i in range(len(df_evaluation.index)):
g.text(x = i, y=np.round(df_evaluation['accuracy'].values[i],4),s=np.round(df_evaluation['accuracy'].values[i],4))
plt.show()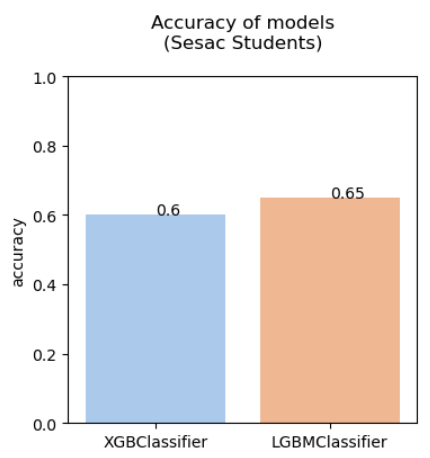
-
이미지 분류 모델
1) 이미지데이터 전처리
#라이브러리 추가
# 이미지 처리 opencv
import cv2
# 파일 접근 os path
import os
import os.path
# dataframe
import numpy as np
# 경고무시
import warnings
warnings.filterwarnings('ignore')
# 시각화
import matplotlib.pyplot as plt
#Data 읽기
# 남자 얼굴 데이터 읽기
# label = '남자' : 0, '여자' : 1
X, y = list(), list()
male_dir = './data/male/'
female_dir = './data/female/'
# male_dir 폴더의 사진(male) 하나씩 접근
for male in os.listdir(male_dir) :
img = male_dir + male
# 이미지 load 불가 시
if cv2.imread(img) is None :
print(male)
continue
# img -> 사이즈 100*100 총 10000칸의 pixel, gray 컬러로 convert
img = cv2.cvtColor(cv2.resize(cv2.imread(img), dsize=(100, 100), interpolation = cv2.INTER_LINEAR), cv2.COLOR_BGR2GRAY)
# numpy로 pixel들 1차원 배열로 변경
X.append(np.array(img).reshape(10000)/255)
# 남자 -> label = 0
y.append(0)
# 여자도 동일
for female in os.listdir(female_dir) :
img = female_dir + female
if cv2.imread(img) is None :
print(female)
continue
img = cv2.cvtColor(cv2.resize(cv2.imread(img), dsize=(100, 100), interpolation = cv2.INTER_LINEAR), cv2.COLOR_BGR2GRAY)
X.append(np.array(img).reshape(10000)/255)
y.append(1)
from sklearn.model_selection import train_test_split
# 최종 X, y 데이터 전처리 완료
X, y = np.array(X), np.array(y)
# 약 3000개의 이미지 데이터 test를 0.2비율로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=156)2) 모델 정의
# 1. Logistic Regression (LR)
from sklearn.linear_model import LogisticRegression
# Logistic Regression 모델
def LR(X_train, y_train) :
model = LogisticRegression(random_state=156)
model.fit(X_train, y_train)
return model
# 2. Stochastic Gradient Descent Classifier (SGD)
from sklearn.linear_model import SGDClassifier
# SGD 모델
def SGD(X_train, y_train) :
model = SGDClassifier(random_state=156)
model.fit(X_train, y_train)
return model
#3. K-Nearest Neighbor (KNN)
from sklearn.neighbors import KNeighborsClassifier
# KNN 모델
def KNN(X_train, y_train) :
model = KNeighborsClassifier()
model.fit(X_train, y_train)
return model
#4. Support Vector Machine (SVM)
from sklearn.svm import SVC
def SVM(X_train, y_train) :
model = SVC(random_state=156)
model.fit(X_train, y_train)
return model
#5. Decision Tree Classifier
from sklearn.tree import DecisionTreeClassifier
def DT(X_train, y_train) :
model = DecisionTreeClassifier(random_state=156)
model.fit(X_train, y_train)
return model3) 모델 평가
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import precision_score, recall_score
# confusion matrix로 결과 확인
def C_Matrix(model, X_test, y_test) :
y_pred = model.predict(X_test)
print(confusion_matrix(y_test, y_pred))
# Classification_Report로 결과 확인
def C_Report(model, X_test, y_test) :
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred, target_names=['남자','여자']))
def PrintResult(LR_clf, SGD_clf, KNN_clf, SVM_clf, DT_clf, X_test, y_test) :
print(f"======Confusion_Matrix======")
print(f"1. Logistic_Regression")
C_Matrix(LR_clf, X_test, y_test)
print(f"2. Stochastic_Gradient_Descent")
C_Matrix(SGD_clf, X_test, y_test)
print(f"3. K-Nearest_Neighbors")
C_Matrix(KNN_clf, X_test, y_test)
print(f"4. Support_Vector_Machine")
C_Matrix(SVM_clf, X_test, y_test)
print(f"5. Decision_Tree")
C_Matrix(DT_clf, X_test, y_test)
print(f"======Classification_Report======")
print(f"1. Logistic_Regression")
C_Report(LR_clf, X_test, y_test)
print(f"2. Stochastic_Gradient_Descent")
C_Report(SGD_clf, X_test, y_test)
print(f"3. K-Nearest_Neighbors")
C_Report(KNN_clf, X_test, y_test)
print(f"4. Support_Vector_Machine")
C_Report(SVM_clf, X_test, y_test)
print(f"5. Decision_Tree")
C_Report(DT_clf, X_test, y_test)
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score
def GetAcc(model, X_test, y_test):
y_pred = model.predict(X_test)
return accuracy_score(y_test, y_pred)
def GetF1(model, X_test, y_test):
y_pred = model.predict(X_test)
return f1_score(y_test, y_pred)
def GetRoc(model, X_test, y_test):
y_pred = model.predict(X_test)
return roc_auc_score(y_test, y_pred)
def GetScore(model, X_test, y_test) :
result = list()
y_pred = model.predict(X_test)
result.append(accuracy_score(y_test,y_pred))
result.append(precision_score(y_test,y_pred))
result.append(recall_score(y_test,y_pred))
result.append(f1_score(y_test,y_pred))
result.append(roc_auc_score(y_test,y_pred))
return result
LR_clf = LR(X_train, y_train)
SGD_clf = SGD(X_train, y_train)
KNN_clf = KNN(X_train, y_train)
SVM_clf = SVM(X_train, y_train)
DT_clf = DT(X_train, y_train)
import pandas as pd
model_arr = [LR_clf, SGD_clf, KNN_clf, SVM_clf, DT_clf]
score_1 = ['model','accuracy', 'precision', 'recall', 'f1_score', 'ROC_AUC']
model_str = ['LR', 'SGD', 'KNN', 'SVM', 'DT']
df = pd.DataFrame(columns=score_1)
for idx, mo in enumerate(model_arr) :
df.loc[idx] = [model_str[idx]]+GetScore(mo, X_test, y_test)
df.set_index('model', inplace=True)
df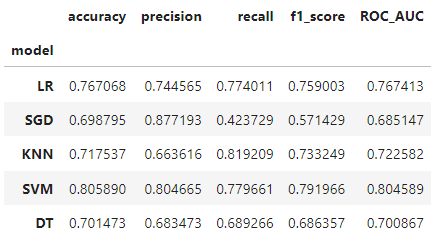
4) 모델 튜닝
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import GridSearchCV
def PrintTuning(model, model_tuning, X_test, y_test):
y_pred = model.predict(X_test)
y_pred_tuning = model_tuning.predict(X_test)
print(f"1. No_tuning")
print(f"roc_auc_score : {roc_auc_score(y_test, y_pred)}")
print(f"2. tuning")
print(f"roc_auc_score : {roc_auc_score(y_test, y_pred_tuning)}")
# 1. Logistic Regression
---
- Parameter
1. Penalty(규제)
- l1, l2 -> l2
2. C(규제 강도)
- 0.0001, 0.001, 0.01, 0.1, 1, 3, 5, 10 -> 0.01
3. Max_iter(수렴을 위한 반복 횟수)
- 100, 300, 500, 1000, 2000 -> 300
def LR_tuning(X_train, y_train, params) :
model = LogisticRegression(random_state=156)
grid = GridSearchCV(model, params, scoring = 'roc_auc')
grid.fit(X_train, y_train)
print(grid.best_params_)
print(grid.best_score_)
return grid.best_estimator_
param = {'penalty':['l2'],
'C':[0.01],
'max_iter':[300]}
#{'C': 0.01, 'max_iter': 300, 'penalty': 'l2'}
#0.8537162852371398
LR_tuning_clf = LR_tuning(X_train, y_train, param)
PrintTuning(LR_clf, LR_tuning_clf, X_test, y_test)
#1. No_tuning
#roc_auc_score : 0.7674127743994479
#2. tuning
#roc_auc_score : 0.7746258679432441
### 2. Stochastic Gradient Descent Classifier (SGD)
---
- Parameter
1. Penalty(규제)
- l1, l2 -> l1
2. Alpha(가중치)
- 0.0001, 0.001, 0.01, 0.1, 1, 3, 5 -> 0.001
3. Max_iter(반복 횟수)
- 50, 100, 500, 1000, 2000 -> 500
def SGD_tuning(X_train, y_train, params) :
model = SGDClassifier(random_state=156)
grid = GridSearchCV(model, params, scoring = 'roc_auc')
grid.fit(X_train, y_train)
print(grid.best_params_)
print(grid.best_score_)
return grid.best_estimator_
param = {'penalty':['l1'],
'alpha':[0.001],
'max_iter':[500]}
SGD_tuning_clf = SGD_tuning(X_train, y_train, param)
#{'alpha': 0.001, 'max_iter': 500, 'penalty': 'l1'}
#0.85569778011757
PrintTuning(SGD_clf, SGD_tuning_clf, X_test, y_test)
#1. No_tuning
#roc_auc_score : 0.6851468495277526
#2. tuning
#roc_auc_score : 0.7853646439815414
### 3. K-NearestNeighbors (KNN)
---
- Parameter
1. n_neighbors(이웃의 개수)
- 1, 3, 5, 7 -> 7
2. algorithm
- auto
def KNN_tuning(X_train, y_train, params) :
model = KNeighborsClassifier()
grid = GridSearchCV(model, params, scoring = 'roc_auc')
grid.fit(X_train, y_train)
print(grid.best_params_)
print(grid.best_score_)
return grid.best_estimator_
param = {'n_neighbors':[7],
'algorithm':['auto']}
KNN_tuning_clf = KNN_tuning(X_train, y_train, param)
#{'algorithm': 'auto', 'n_neighbors': 7}
#0.7828699572417434
PrintTuning(KNN_clf, KNN_tuning_clf, X_test, y_test)
#1. No_tuning
#roc_auc_score : 0.7225816190106524
#2. tuning
#roc_auc_score : 0.72936343640833225) 모델 튜닝 후 평가
print(f"=== 1. LR ===")
C_Report(LR_tuning_clf, X_test, y_test)
print(f"=== 2. SGD ===")
C_Report(SGD_tuning_clf, X_test, y_test)
print(f"=== 3. KNN ===")
C_Report(KNN_tuning_clf, X_test, y_test)
print(f"=== 4. SVM ===")
C_Report(SVM_clf, X_test, y_test)
print(f"=== 5. DT ===")
C_Report(DT_clf, X_test, y_test)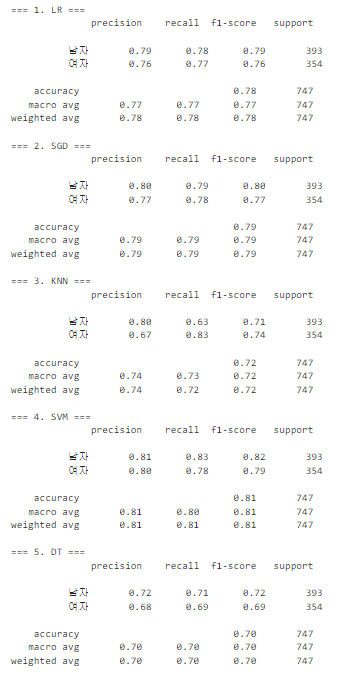
6) 모델 앙상블
from sklearn.ensemble import VotingClassifier
from sklearn.calibration import CalibratedClassifierCV
def PrintRoc(model, X_test, y_test):
y_pred = model.predict(X_test)
print(f"roc_auc_score : {roc_auc_score(y_test, y_pred)}")
models = [
('LR', LR_tuning_clf),
('SGD', SGD_tuning_clf),
('KNN', KNN_tuning_clf),
('SVM', SVM_clf),
('DT', DT_clf)
]
Hard_VC = VotingClassifier(models, voting='hard')
# Soft_VC = VotingClassifier(models, voting='soft')
Hard_VC.fit(X_train, y_train)
# Soft_VC.fit(X_train, y_train)
PrintRoc(Hard_VC, X_test, y_test)
#roc_auc_score : 0.81672920170785357) 모델 평가 시각화
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score
def GetAcc(model, X_test, y_test):
y_pred = model.predict(X_test)
return accuracy_score(y_test, y_pred)
def GetF1(model, X_test, y_test):
y_pred = model.predict(X_test)
return f1_score(y_test, y_pred)
def GetRoc(model, X_test, y_test):
y_pred = model.predict(X_test)
return roc_auc_score(y_test, y_pred)
def GetScore(model_arr, X_test, y_test) :
Acc_S, F1_S, Roc_S = list(), list(), list()
for model in model_arr :
Acc_S.append(GetAcc(model, X_test, y_test))
F1_S.append(GetF1(model, X_test, y_test))
Roc_S.append(GetRoc(model, X_test, y_test))
return Acc_S, F1_S, Roc_S
model_arr = [LR_tuning_clf, SGD_tuning_clf, KNN_tuning_clf, SVM_clf, DT_clf, Hard_VC]
Acc, F1, Roc = GetScore(model_arr, X_test, y_test)
model_str = ['LR', 'SGD', 'KNN', 'SVM', 'DT', 'Hard_VC']
plt.bar(model_str, Acc)
plt.ylim(min(Acc)-0.01, max(Acc)+0.01)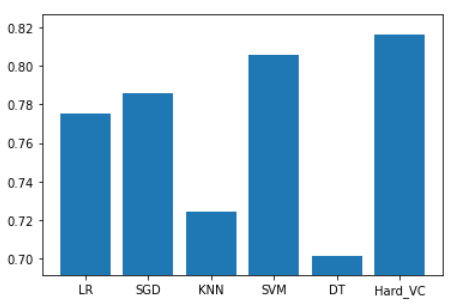
plt.bar(model_str, F1)
plt.ylim(min(F1)-0.01, max(F1)+0.01)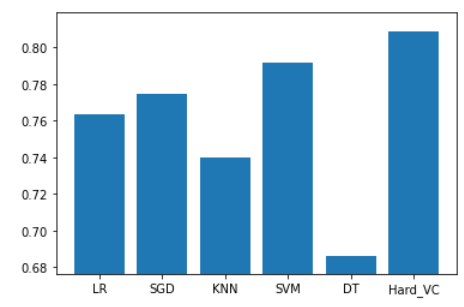
plt.bar(model_str, Roc)
plt.ylim(min(Roc)-0.01, max(Roc)+0.01)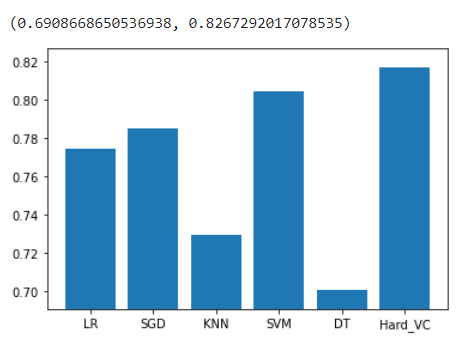
8) 모델 검증 시각화
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
#Test 준비, 데이터 읽기
# 남자 얼굴 데이터 읽기
# label = '남자' : 0, '여자' : 1
test_X, test_y = list(), list()
test_male_dir = './data/male/'
test_female_dir = './data/test/female/'
# male_dir 폴더의 사진(male) 하나씩 접근
for test_male in os.listdir(test_male_dir) :
test_img = test_male_dir + test_male
# 이미지 load 불가 시
if cv2.imread(test_img) is None :
print(test_male)
continue
# img -> 사이즈 100*100 총 10000칸의 pixel, gray 컬러로 convert
test_img = cv2.cvtColor(cv2.resize(cv2.imread(test_img), dsize=(100, 100), interpolation = cv2.INTER_LINEAR), cv2.COLOR_BGR2GRAY)
# numpy로 pixel들 1차원 배열로 변경
test_X.append(np.array(test_img).reshape(10000)/255)
# 남자 -> label = 0
test_y.append(0)
# 여자도 동일
for female in os.listdir(test_female_dir) :
img = test_female_dir + female
if cv2.imread(img) is None :
print(female)
continue
img = cv2.cvtColor(cv2.resize(cv2.imread(img), dsize=(100, 100), interpolation = cv2.INTER_LINEAR), cv2.COLOR_BGR2GRAY)
test_X.append(np.array(img).reshape(10000)/255)
test_y.append(1)
test_y_pred = Gender_Model.predict(np.array(test_X))
for idx, num in enumerate(test_y_pred) :
plt.imshow(test_X[idx].reshape(100,100),cmap='gray')
plt.show()
if num == 0 :
print("===== 남자 =====")
else :
print("===== 여자 =====")
참고
발표 PPT 및 설명은 머신러닝 성별 분류 프로젝트 (3)을 참고하시면 되겠습니다.

https://github.com/min731
6개의 댓글

2023년 10월 19일
안녕하세요.
올려주신 프로젝트 참고해서 공부하고 있는 사람입니다.
혹시 해당 코드들이 구글 코랩에서 문제 없이 작동 되는 게 맞나요?
지금 구글 코랩을 이용하고 있는데, 여러 문제가 많이 발생해서 질문드립니다..!
감사합니다.
1개의 답글
안녕하세요, 글을 보다가 궁금한 점이 있어 댓글남깁니다. R언어로 어떻게 피쳐들을 분석하였는지 코드가 궁금한데, 혹시 공유 가능할까요??