[졸업프로젝트] PoseNet 경량화를 통한 Jetson Nano RC카의 실내 자율주행 구현
2022-2 졸업프로젝트를 시작하며 저희 팀은
PoseNet의 Camera Pose Estimation을 이용해 RC카의 실내 자율주행을 구현하고, PoseNet이 JetsonNano와 같은 mobile환경 (전력 소비량이 5W) 에서도 내장 GPU로 자율주행이 가능하도록 경량화를 하는 프로젝트를 진행하고 있습니다. 이때 경량화의 방법으로는 "Knowledge Distillation"이라는 지식증류법을 사용할 계획입니다.
자율주행의 방법으로 PoseNet을 통한 Camera Pose Estimation을 이용한 이유는 저희는 자율주행에서 전력사용량 감소를 통한 운행시간 증가에 주목을 하고 있는데, Camera Pose Estimation을 이용하여 실내자율주행에서 LiDAR없이 카메라만으로 자율주행을 구현하고, mobile환경의 전력소모량인 5W의 환경에서 자율주행이 가능함을 보여 최종적으로 경량화를 통해 전력소모량을 줄인 효율적인 모델을 제시한다는 것에 있습니다.
연구트랙이다보니 다소 프로젝트 설명이 긴데, 이번 프로젝트에서 하고자 하는걸 정리하면
- PoseNet을 사용하여 Camera Pose Estimation을 구현한다.
- 이 Camera Pose Estimation을 RC카가 LiDAR와 같은 부가 센서 없이 오직 카메라만으로 실내자율주행을 할 수 있도록 한다.
- Knowledge Distillation을 적용하여 5W 전력소모의 Jetson Nano에서 PoseNet이 동작할 수 있도록 한다.
- Jetson Nano를 장착한 JetsonBot 에서의 실내 자율주행을 구현한다.
가 됩니다.
우선 이번장에서는 프로젝트 주제를 세우고 프로젝트가 실현가능한지 탐색하는 단계이기에
- PoseNet 실외환경에 대한 demo 진행 (KingsCollege dataset 사용)
- PoseNet 실내환경에 대한 demo 진행 (7Scenes dataset 사용)
- PoseNet 개발환경 맞추기
세 포인트에 집중하여 포스팅을 했습니다.
참고한 논문(1)
PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization
https://arxiv.org/abs/1505.07427
1. PoseNet 으로 KingsCollege 와 7Scenes dataset demo 진행하기 (1) Colab 환경
PoseNet은 Pytorch로 구현됐고, Linux 환경을 사용합니다.
(1) Colab에서 구현한 부분과
(2) Local 에서 개발하기 위해 WSL (Window Service Linux) 환경에서 구현한 부분
두 방법을 모두 소개하려고 합니다.
특히 Window에서 인공지능을 개발하시는 분들은 Linux환경때문에 고생을 많이 하셨을텐데 Window10이후부터는 Window에서도 WSL로 Ubuntu를 지원합니다.
뒷부분 내용을 참고하셔서 Window에서 Linux를 가상머신 없이 사용하는데 도움이 되길 바랍니다.
우선 앞서 보여드린
PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization
논문은 실외 dataset에서 Camera Pose Estimation을 구현한 논문입니다.
Dataset으로 "KingsCollege" 를 사용했습니다.
저희는 PoseNet이 실내 환경에서도 잘 돌아가는지 점검하기 위해 Microsoft에서 제공하는 dataset인 7Scene를 사용했습니다. 해당 dataset을 선택한 이유는 7Scenes는 이미지와 함께 카메라 위치 좌표값과 6-DOF값 label을 제공하기 때문입니다.

참고한 논문(2)
[Mixture Density-PoseNet and its Application to
Monocular Camera-Based Global Localization]
위 MD-PoseNet을 이용한 실내 자율주행 논문에서는 KingsCollege와 7Scenes둘 다 사용했습니다.
1.KingsCollege Dataset (실외 Dataset에 PoseNet 적용하기)
Dataset Download link
https://www.repository.cam.ac.uk/handle/1810/251342#dataset
압축된 파일이 5G정도니까 용량 잘 확인하고 다운받으세요.
이 부분은 논문에서 이미 잘 구현되있기 때문에 위 Github의 PoseNet이 잘 동작하는지 점검하는 정도로 사용했습니다.
Colab 개발환경을 맞추는 용도로 봐주시면 됩니다.
우선 위 깃허브 링크에서 gitclone 을 이용해서 구글클라우드에 필요한 파일들을 가져올 것입니다.
원하는 위치에 Colab .ipynb 파일을 하나 만들고

프로젝트 디렉토리가 생성되기 원하는 곳으로 cd command를 이용해 이동합니다.
cd "/content/drive/MyDrive/ml_workplace"
원하는 폴더에 잘 도착했는지 pwd 를 사용해서 확인하고
git clone을 합니다. (colab에서 script언어를 쓰려면 앞에 ! 를 붙이면 됩니다.)
!git clone https://github.com/hazirbas/posenet-pytorch
그러면 원하는 위치에 posenet-pytorch 디렉토리가 생긴 것을 확인할 수 있습니다.

새로 디렉토리가 생겼으니 이동을 합니다.
cd posenet-pytorch
이제 본격적으로 train을 하기 전에 앞서 다운로드받은 Kingscollege dataset을 posenet-pytorch로 이동시켜야하는데요.
posenet-pytorch/dataset/
하위에 KingsCollege 디렉토리를 업로드 하시면 됩니다.
사실 dataset폴더 이름을 datasets 으로 s를 붙여야 수정없이 코드가 돌아가니 참고하세요...저는 그냥 dataset으로 하고 코드 수정하며 했습니다.
구글 드라이브에 업로드할 때 KingsCollege/seq-01 이런 디렉토리들 압축 풀고 올리는거 잊지마세요! 업로드가 왤케 빠르지? 했으면 압축이 안풀린것입니다.
Installation
이제 다시 colab으로 돌아와서 dataset까지 준비가 됐으면 필요한 package들을 install합니다.
!pip install -r requirements.txt설치하면 마지막에 ERROR: Could not find a version that satisfies the requirement torch==0.4.0 (from versions: 1.0.0, 1.0.1, 1.0.1.post2, 1.1.0, 1.2.0, 1.3.0, 1.3.1, 1.4.0, 1.5.0, 1.5.1, 1.6.0, 1.7.0, 1.7.1, 1.8.0, 1.8.1, 1.9.0, 1.9.1, 1.10.0, 1.10.1, 1.10.2, 1.11.0, 1.12.0, 1.12.1, 1.13.0) ERROR: No matching distribution found for torch==0.4.0
라고 에러가 뜨는데 걱정 안해도 됩니다. 참고한 코드가 2017년에 작성되어서 torch 버전이 너무 옛날거라... local에서 직접 pip install할거면 1.13.0 버전도 잘 돌아가고,
colab에서는 pytorch를 지원하기 때문에 직접 설치 안해도 괜찮습니다.

위 실행결과를 보면 dominate-2.3.1.tar.gz 가 압축이 안풀렸는데 직접 pip 로 설치하는게 편합니다.
!pip install dominate
Resize Image
이제 PoseNet을 본격적으로 Training하기 전에
우선 train과 test data 모두 PoseNet에서 돌아갈 수 있도록 image resize가 필요합니다.
!python util/compute_image_mean.py --dataroot dataset/KingsCollege --height 256 --width 455 --save_resized_imgsposenet-pytorch/util/compute_image_mean.py 파일을 보면
def params():
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--dataroot', type=str, default='datasets/KingsCollege', help='dataset root')
parser.add_argument('--height', type=int, default=256, help='image height')
parser.add_argument('--width', type=int, default=455, help='image width')
parser.add_argument('--save_resized_imgs', action="store_true", default=False, help='save resized train/test images [height, width]')
return parser.parse_args()option이 이렇게 정리되어있습니다.
즉,
!python util/compute_image_mean.py --dataroot dataset/KingsCollege --height 256 --width 455 --save_resized_imgs
이 코드는 dataset이미지를 256 x 455 로 변형시킨다는 것을 알 수 있습니다.
그리고 compute_image_mean.py인 만큼 dataset의 mean image를 생성하는데요.
mean_image /= len(imlist)
Image.fromarray(mean_image.astype(np.uint8)).save(jpath(dataroot, 'mean_image.png'))
np.save(jpath(dataroot, 'mean_image.npy'), mean_image)

KingsCollege의 mean image가 생긴 것을 확인할 수 있습니다.
Training
이제 Train을 시작해보면
!python train.py --model posenet --dataroot dataset/KingsCollege --name posenet/KingsCollege/beta500 --beta 500 --gpu 0train은 colab 환경에서 약 3시간 정도 걸렸습니다.
#train options
------------ Options -------------
adambeta1: 0.9
adambeta2: 0.999
batchSize: 75
beta: 500.0
checkpoints_dir: ./checkpoints
continue_train: False
dataroot: dataset/KingsCollege
dataset_mode: unaligned_posenet
display_freq: 100
display_id: 0
display_port: 8097
display_single_pane_ncols: 0
display_winsize: 224
epoch_count: 1
fineSize: 224
gpu_ids: [0]
init_weights: pretrained_models/places-googlenet.pickle
input_nc: 3
isTrain: True
loadSize: 256
lr: 0.0005
lr_decay_iters: 50
lr_policy: lambda
lstm_hidden_size: 256
max_dataset_size: inf
model: posenet
nThreads: 8
name: posenet/KingsCollege/beta500
niter: 500
niter_decay: 0
no_dropout: False
no_flip: True
output_nc: 7
phase: train
pool_size: 50
print_freq: 100
resize_or_crop: scale_width_and_crop
save_epoch_freq: 5
save_latest_freq: 5000
seed: 0
serial_batches: False
update_html_freq: 1000
use_html: False
which_epoch: latest
-------------- End ----------------Train option은
\posenet-pytorch\checkpoints\posenet\KingsCollege\beta500\train_opt.txt 에서 확인할 수 있습니다.
위 train option을 보면 default값으로
Batchsize = 75
Learning rate = 0.0005
Pretrained model = Places에서 학습한 GoogLeNet
등이 설정되어 있음을 확인할 수 있습니다.
(나중에 finetuning할 때 사용할 예정)
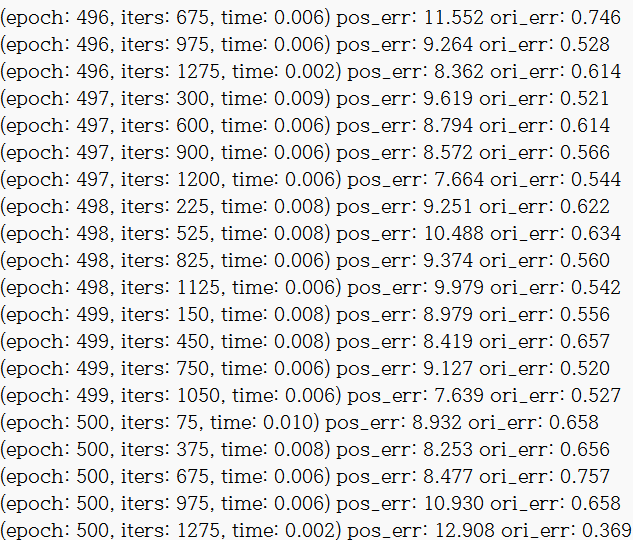
학습 결과는
posenet-pytorch\checkpoints\posenet\KingsCollege\beta500\loss_log.txt
에서 확인할 수 있습니다.
밑에 이미지는 loss_log.txt의 일부를 캡쳐한 것입니다.
또한 학습된 모델들이 같은 경로인
\posenet-pytorch\checkpoints\posenet\KingsCollege\beta500\
에 5 epoch마다 저장된 것을 확인할 수 있습니다.
Test
이제 training된 model로 test를 해보면
!python test.py --model posenet --dataroot dataset/KingsCollege --name posenet/KingsCollege/beta500 --gpu 0posenet-pytorch\results\posenet\KingsCollege\beta500\test_median.txt
에서 각 epoch의 pos_err(position error)와 ori_err(pose error)의 iteration당 평균값 결과를 확인할 수 있습니다.

2. 7Scenes Dataset (실내 Dataset에 PoseNet 적용하기) - fire dataset
실내에서 PoseNet을 적용하기 위해 Microsoft에서 제공하는 7Scenes dataset을 사용했습니다.
저는 이 중 Chess, fire dataset을 맡았는데요. fire는 colab에서 돌리고 chess는 wsl을 이용하여 local 환경에서 돌렸습니다.
7Scenes dataset
https://www.microsoft.com/en-us/research/project/rgb-d-dataset-7-scenes/
여기서 다운받으면 되고 다운로드 링크가 http로 되어있어서 링크복사 후 https로 변경해서 다운받으면 됩니다.
Dataset
새로운 dataset을 받았으니 이제 저희의 기존 코드에 돌아갈 수 있게 만들어줘야 합니다.
이전 KingsCollege를 돌리기 위해서는 posenet-pytorch\dataset\KingsCollege 디렉토리에
- train data의 파일 이름
- position(X,Y,Z) & Orientation quaternion(W,P,Q,R) 좌표값이 있는
dataset_train.txt,dataset_test.txt파일이 필요합니다.
KingsCollege는 해당 텍스트 파일들을 제공하지만 7Scene는 해당 파일을 제공하지 않고, 이미지마다 position과 orientation값을 7dimension vector이 아닌 4 x 4 matrix로 각각 제공합니다!
즉 아래와 같은 txt파일을 만들기 위해 4x4 => position(X,Y,Z) & Orientation quaternion(W,P,Q,R) 로 변환하는 과정이 필요합니다.
(KingsCollege 예시- dataset_train.txt)

다행이도! 아래 깃허브 링크에서 7Scenes의 모든 dataset의 dataset_train.txt, dataset_test.txt를 만들어져있는데요.
https://github.com/alexgkendall/caffe-posenet/tree/master/posenet/7Scenes_PoseNet_TrainVal
(caffe-posenet/posenet/7Scenes_PoseNet_TrainVal/)
Paper with Code에 저희가 참고한 논문을 검색하면 가장 상단에 나오는 깃허브 주소입니다.
여기서 dataset_train.txt 와 dataset_test.txt 다운받거나 복붙하면 됩니다.
Dataset - (나중에 오류 뜰 때 참고)
사실 이러고 코드가 바로 잘 돌아갈 줄 알았는데 dataset의 이미지 파일을 인식하지 못하는 오류가 뜰 수 있습니다.
이것저것 디버깅하고 이전 KingsCollege랑 비교하면서 찾아봤는데
- 위 깃허브 주소에서 만든
dataset_train.txt랑dataset_test.txt은 주소가 '/' 로 시작합니다. - dataset의 이미지파일의 이름이 "frame-000000.color.png" 처럼 파일 이름에 확장자로 착각할만한 "." 이 있습니다.
이 두 지점에서 문제가 생긴 것 같았습니다.
ex) fire의 dataset_train.txt 파일을 보면
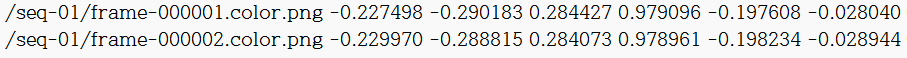
로 '/' 슬래쉬로 시작하고 있고, png 파일 이름에 .color로 확장자로 착각할 만한 부분이 있습니다.
1번 문제의 경우 그냥 write_txt.py 라는 코드를 짜서 텍스트라인의 가장 앞 '/'들을 없앴습니다.
#text_file_path = 'C:\\Users\\min10\\posenet-pytorch\\datasets\\fire\\dataset_train_2.txt'
text_file_path = 'C:\\Users\\min10\\posenet-pytorch\\datasets\\chess\\chess\\dataset_test.txt'
#text_file_path = 'C:\\Users\\min10\\posenet-pytorch\\datasets\\fire\\dataset_test_2.txt'
with open(text_file_path, "r") as f:
lines = f.readlines()
with open(text_file_path, "w") as f:
for i, line in enumerate(lines):
if i < 6 :
print("\nline[0] :", line[0])
if line[0] == '/':
line = line[1:]
f.write(line)
else:
f.write(line)2번 문제는 해결이유가 확실하진 않는데, train과 test 각각 첫번째 이미지들만 이름을 frame-000000_color.png 로 .color부분을 _color로 바꿔줬습니다.
이러니까 잘 돌아갔는데 다른 분들도 이런 문제가 뜰지는 모르겠습니다.
Train
이제 fire dataset을 학습시켜봅니다.

fire dataset은 위와 같은 표지판을 중심으로 한바퀴를 도는 영상을 frame별로 나누어 만든 dataset 입니다.
fire는 2000개의 train dataset과 2000개의 test dataset으로 이루어져 있습니다.
!python util/compute_image_mean.py --dataroot dataset/fire --height 256 --width 455 --save_resized_imgs위 코드로 이미지들을 resize한 후 (--dataroot 경로를 fire로 변경해주세요.) colab에서 약 32분정도 걸렸습니다.

생성된 mean_image.png
!python train.py --model posenet --dataroot dataset/fire --name posenet/fire/beta500 --beta 500 --gpu 0위 코드로 학습시켜줍니다.
2000개의 train dataset을 500epoch로 학습시키는데 약 3시간 정도 걸렸습니다.
posenet-pytorch\checkpoints\posenet\fire\beta500\loss_log.txt
에서 학습결과를 확인해보면
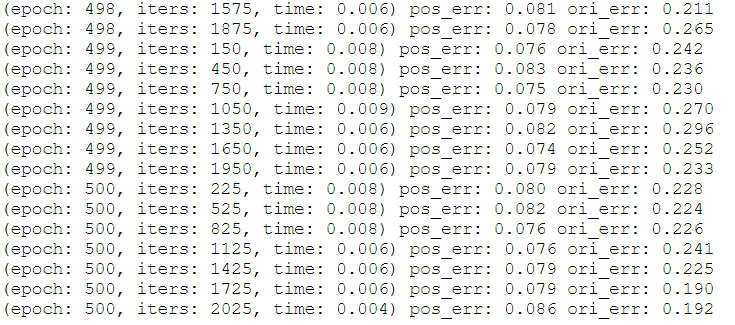
다음과 같이 확인할 수 있습니다.
똑같이 checkpoint 디렉토리에 각 epoch마다 네트워크값들이 저장된 것을 확인할 수 있습니다.
Test
이제 test입니다.
!python test.py --model posenet --dataroot dataset/fire --name posenet/fire/beta500 --gpu 0pytorch\results\posenet\fire\beta500\test_median.txt에서 test결과를 확인해보면
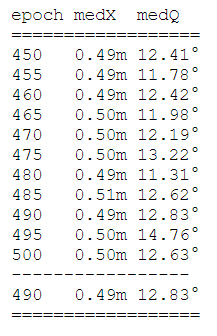
train 결과에 비해서 test에서 orientation error 값이 높게 나온 것을 볼 수 있네요. 나중에 프로젝트를 진행할때는 Batch size나 lr와 같은 하이퍼파라미터의 조정이 필요할 것 같습니다.
2. PoseNet 으로 7Scenes dataset- chess demo 진행하기 (2) WSL Ubuntu 환경
Colab 환경에서 안하고 local 환경에서 chess dataset을 진행한 이유는 colab의 gpu 사용량 제한 때문입니다.
colab에서 딥러닝 머신을 몇시간정도 돌리면 gpu 사용량 초과로 gpu사용이 제한되는데, 우리가 사용하는 PoseNet의 경우 컴퓨팅값이 많아 다른 프로젝트때보다 gpu사용이 금방 끊겼습니다.
게다가 fire dataset는 4000data를 가지고 있던 것과 달리, chess dataset은 6000data를 가지고 있어서 train 진행 중 중간에 항상 gpu 사용이 끊겼습니다.
local에서 PoseNet을 돌리려면 Linux환경을 사용해야 하는데 가상 머신을 이용하기에는 딥러닝 모델에 적절한 CPU와 가상 GPU를 할당값이 무엇인지 알기 어려웠습니다.
그래서 가상 머신을 사용하기 보단 Microsoft에서 Window10이상에서 지원하는 Ubuntu인 WSL2(Window service Linux) 를 사용하기로 결정했습니다.
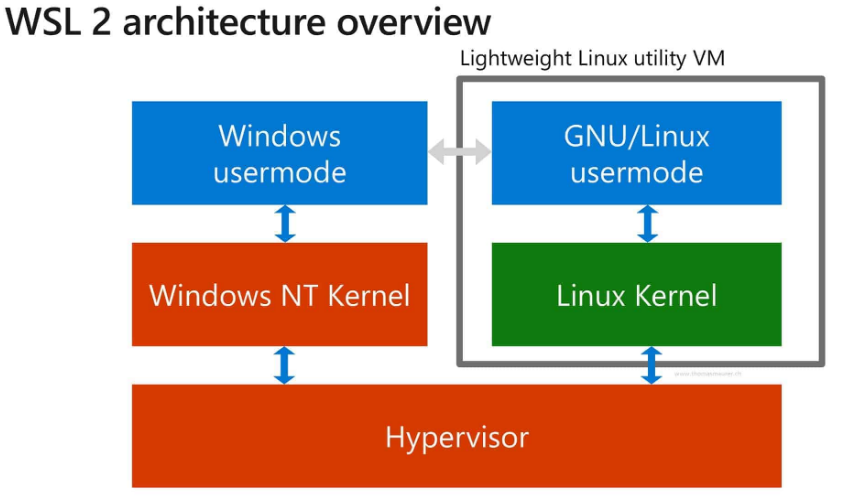

가상머신처럼 할당된 CPU일부를 사용하는 것이 아니라 윈도우와 통합된 환경에서 Linux를 사용할 수 있으므로 I/O 출력 속도가 더 빨라 딥러닝 모델을 돌리기에 적합하다.
WSL2 설치 및 개발환경 설정
PowerShell을 관리자 권한으로 실행해서 wsl을 설치합니다.
wsl --install설치가 완료하면 reboot하고, wsl이 잘 설치되었는지 확인합니다.
wsl --status이제 윈도우 검색창에 Ubuntu가 있고, 선택해서 ubuntu에 진입하면 됩니다.
CUDA의 경우 이미 Window환경에 설치되어 있어서 굳이 재설치 하지 않았습니다.
CUDA 및 GPU 사용 가능한지 확인합니다.
nvidia-smi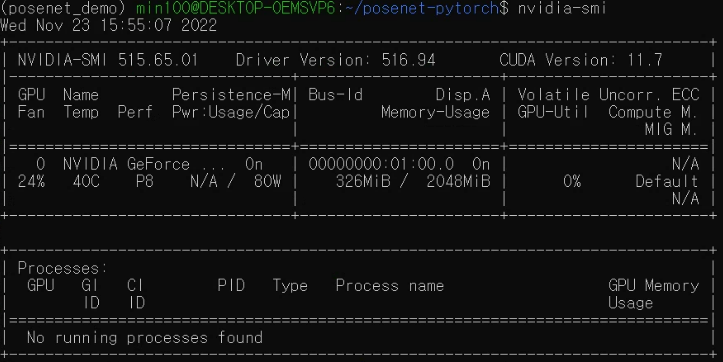
위 사진을 보면 (posenet_demo) 라는 가상환경을 WSL2에서 사용하고 있는 것을 확인할 수 있습니다. 이제 WSL2에서 가상환경을 설정하는 방법을 알아봅시다.
WSL2에 가상 환경 설치
virtualenv 를 home directory 타겟으로 설치합니다(-H).
sudo -H pip install virtualenv이제 virtualenv를 사용해서 가상환경을 만듭니다.
virtualenv [가상환경이름] --python=python[원하는 버전]가상환경을 activate합니다.
activate [가상환경이름]Cdrive의 posenet-pytorch 디렉토리를 WSL2로 옮기기
(cdrive에 posenet-pytorch git-clone을 우선 하고)
우선 wsl 저장공간 위치를 확인합니다.
explorer.exe .. 마지막에 꼭 찍어줘야합니다! 이러면 윈도우 창으로 저장공간이 뜨게 됩니다.
\\wsl\Ubuntu\home\[계정이름]
저장 위치를 알았으니 Cdrive의 posenet-pytorch 디렉토리를 원하는 wsl위치 디렉토리에 copy합니다.
- 우선 wsl폴더에 posenet-pytorch 디렉토리를 만듭니다.
mkdir posenet-pytorchcp -Rcommand로 c 드라이브에서 wsl로 디렉토리 이동시킨다.
이때 wsl에서 c 드라이브는 \mnt\c에 위치한다!
cp -R /mnt/c/Users/[원하는 디렉토리] [원하는 wsl 디렉토리]/- c-drive에서 온 디렉토리는 권한 설징이 안되어있어서
sudo chmod -R로 전체 권한 설정을 해준다.
sudo chmod -R a+rwx [원하는폴더이름]이러면 posenet을 돌릴 준비가 끝났다.
Train (batchsize = 25, epoch = 100)
우선 compute_mean_image.py 로 이미지 사이즈 조절합니다.
python3 util/compute_image_mean.py --dataroot dataset/fire --height 256 --width 455 --save_resized_imgs

Training
chess dataset의 경우 6000data이기 때문에 500epoch는 시간이 너무 오래걸려서 100epoch로 바꿔주었습니다.
또한 local desktop의 gpu는 Nvidia Geforce GTX1050으로 default batch size인 75로 training을 하려 하면 다음과 같은 error code를 볼 수 있는데요,

Batch size가 너무 커서 발생하는 문제이니 Batch size를 적절하게 줄여줍니다.(저는 25로 맞춤)
- Epoch # 변경법
이 경우는posenet-pytorch\options\TrainOptions파일에서 확인할 수 있습니다.
class TrainOptions(BaseOptions):
def initialize(self):
BaseOptions.initialize(self)
self.parser.add_argument('--display_freq', type=int, default=100, help='frequency of showing training results on screen')
self.parser.add_argument('--display_single_pane_ncols', type=int, default=0, help='if positive, display all images in a single visdom web panel with certain number of images per row.')
self.parser.add_argument('--update_html_freq', type=int, default=1000, help='frequency of saving training results to html')
self.parser.add_argument('--print_freq', type=int, default=100, help='frequency of showing training results on console')
self.parser.add_argument('--save_latest_freq', type=int, default=5000, help='frequency of saving the latest results')
self.parser.add_argument('--save_epoch_freq', type=int, default=5, help='frequency of saving checkpoints at the end of epochs')
self.parser.add_argument('--continue_train', action='store_true', help='continue training: load the latest model')
self.parser.add_argument('--epoch_count', type=int, default=1, help='the starting epoch count, we save the model by <epoch_count>, <epoch_count>+<save_latest_freq>, ...')
self.parser.add_argument('--phase', type=str, default='train', help='train, val, test, etc')
self.parser.add_argument('--which_epoch', type=str, default='latest', help='which epoch to load? set to latest to use latest cached model')
self.parser.add_argument('--niter', type=int, default=500, help='# of iter at starting learning rate')
self.parser.add_argument('--niter_decay', type=int, default=0, help='# of iter to linearly decay learning rate to zero')
self.parser.add_argument('--adambeta1', type=float, default=0.9, help='first momentum term of adam')
self.parser.add_argument('--adambeta2', type=float, default=0.999, help='second momentum term of adam')
self.parser.add_argument('--lr', type=float, default=0.0005, help='initial learning rate for adam')
self.parser.add_argument('--pool_size', type=int, default=50, help='the size of image buffer that stores previously generated images')
self.parser.add_argument('--use_html', action='store_true', help='save intermediate training results to [opt.checkpoints_dir]/[opt.name]/web/')
self.parser.add_argument('--lr_policy', type=str, default='lambda', help='learning rate policy: lambda|step|plateau')
self.parser.add_argument('--lr_decay_iters', type=int, default=50, help='multiply by a gamma every lr_decay_iters iterations')
self.parser.add_argument('--init_weights', type=str, default='pretrained_models/places-googlenet.pickle', help='initiliaze network from, e.g., pretrained_models/places-googlenet.pickle')
self.isTrain = True위 코드에서 --niter option을 통해 epoch 수를 조절할 수 있다는 것을 확인할 수 있습니다.
- Batch Size 변경법
이 경우는posenet-pytorch\options\baseoption.py파일에서 확인할 수 있습니다.
def initialize(self):
self.parser.add_argument('--dataroot', required=True, help='path to images (should have subfolders trainA, trainB, valA, valB, etc)')
self.parser.add_argument('--batchSize', type=int, default=75, help='input batch size')
self.parser.add_argument('--loadSize', type=int, default=256, help='scale images to this size')
self.parser.add_argument('--fineSize', type=int, default=224, help='then crop to this size')
self.parser.add_argument('--input_nc', type=int, default=3, help='# of input image channels')
self.parser.add_argument('--output_nc', type=int, default=7, help='# of output image channels')
self.parser.add_argument('--lstm_hidden_size', type=int, default=256, help='hidden size of the LSTM layer in PoseLSTM')
self.parser.add_argument('--gpu_ids', type=str, default='0', help='gpu ids: e.g. 0 0,1,2, 0,2. use -1 for CPU')
self.parser.add_argument('--name', type=str, default='experiment_name', help='name of the experiment. It decides where to store samples and models')
self.parser.add_argument('--dataset_mode', type=str, default='unaligned_posenet', help='chooses how datasets are loaded. [unaligned | aligned | single]')
self.parser.add_argument('--model', type=str, default='posenet', help='chooses which model to use. [posenet | poselstm]')
self.parser.add_argument('--nThreads', default=8, type=int, help='# threads for loading data')
self.parser.add_argument('--checkpoints_dir', type=str, default='./checkpoints', help='models are saved here')
self.parser.add_argument('--serial_batches', action='store_true', help='if true, takes images in order to make batches, otherwise takes them randomly')
self.parser.add_argument('--display_winsize', type=int, default=224, help='display window size')
self.parser.add_argument('--display_id', type=int, default=0, help='window id of the web display')
self.parser.add_argument('--display_port', type=int, default=8097, help='visdom port of the web display')
self.parser.add_argument('--no_dropout', action='store_true', help='no dropout for the generator')
self.parser.add_argument('--max_dataset_size', type=int, default=float("inf"), help='Maximum number of samples allowed per dataset. If the dataset directory contains more than max_dataset_size, only a subset is loaded.')
self.parser.add_argument('--resize_or_crop', type=str, default='scale_width_and_crop', help='scaling and cropping of images at load time [resize_and_crop|crop|scale_width|scale_width_and_crop]')
self.parser.add_argument('--no_flip', action='store_true', default=True, help='if specified, do not flip the images for data augmentation')
self.parser.add_argument('--seed', type=int, default=0, help='initial random seed for deterministic results')
self.parser.add_argument('--beta', type=float, default=500, help='beta factor used in posenet.')
self.initialized = True
위 코드에서 line3를 보면 --batchSize option을 통해 batchsize를 조절할 수 있음을 알 수 있습니다.
--ntier 와 --batchSize 옵션을 사용한 train command는 다음과 같다.
python train.py --model posenet --dataroot ./dataset/chess --name posenet/chess/beta500 --beta 500 --gpu 0 --batchSize 20 --niter 100

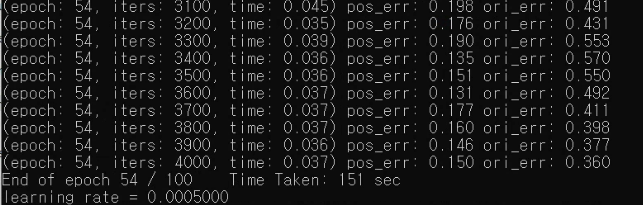
epoch 100만 해도 한 4시간 걸린 거 같습니다.
Training 결과
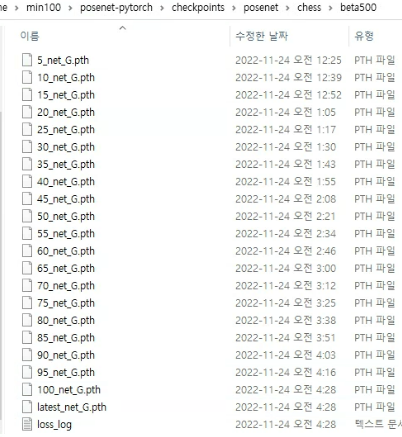
위 경로에 학습 결과가 저장되었습니다.
(#_net_G.pth 파일들은 추후 test.py에서 사용하니 참고)
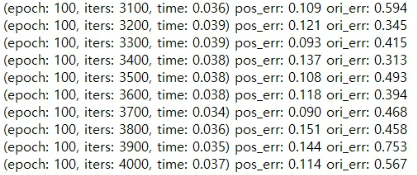
Test
앞서 training 단계에서 epoch수를 100으로 바꿨기 때문에 test.py 파일에서 변경할 부분이 있는데, test.py 는 test epoch의 수가 train epoch 500을 기준으로 코드가 짜졌기 때문입니다.
(왜 이부분을 동적으로 안하고 500으로 고정했는지는 의문)
test.py 를 보면
############### 생략 ###############
results_dir = os.path.join(opt.results_dir, opt.name)
if not os.path.exists(results_dir):
os.makedirs(results_dir)
besterror = [0, float('inf'), float('inf')] # nepoch, medX, medQ
if opt.model == 'posenet':
testepochs = numpy.arange(450, 500+1, 5)
else:
testepochs = numpy.arange(450, 1200+1, 5)
testfile = open(os.path.join(results_dir, 'test_median.txt'), 'a')
testfile.write('epoch medX medQ\n')
testfile.write('==================\n')
model = create_model(opt)
visualizer = Visualizer(opt)
for testepoch in testepochs:
model.load_network(model.netG, 'G', testepoch)
visualizer.change_log_path(testepoch)
############# 생략 ###############testepochs = numpy.arange(450, 500 + 1, 5) 코드를 보면 epoch 500을 기준으로 450, 455, 460 ... 이렇게 총 10번의 test epoch를 가진다고 되어있습니다.
밑에 model.load_network(model.netG, 'G', testepoch) 를 보면 학습된 network가 testepoch 번호를 기준으로 load되는데 문제는 우리는 epoch 100으로 학습을 했기 때문에 450, 455... 번호를 갖는 epoch가 없습니다.
그렇기때문에 위의 코드를
############### 생략 ###############
if opt.model == 'posenet':
testepochs = numpy.arange(50, 100+1, 5)
############# 생략 ###############
다음과 같이 값을 변형해줘야 합니다.
test
python test.py --model posenet --dataroot ./dataset/chess --name posenet/chess/beta500 --gpu 0

결과
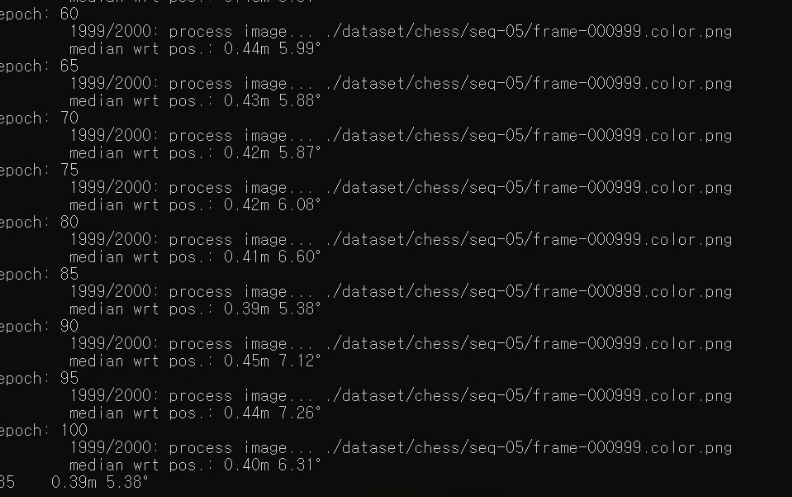
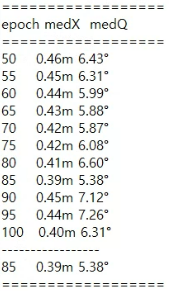
epoch를 줄였는데도 fire보다 더 좋은 성능을 보이고 있는데요. 아마 dataset수가 더 많고 batchsize를 줄인 영향이 있지 않을까 싶습니다.
결론
PoseNet demo를 7Scenes와 같은 실내 dataset에 돌려보며 해당 PoseNet모델이 실내 Camera pose estimation에 적절하게 사용할 수 있다는 것을 확인했습니다. 7Scenes dataset의 경우 실내의 특정 물체 주변에 관한 영상을 기반으로 만들어진 dataset이라 좌표에 비해 orientation이 error값이 크게 나왔지만 우리 프로젝트는 좀 더 넓은 환경에서 Pose estimation을 적용할 것이라 더 좋은 결과가 나오길 기대하고 있습니다.
다음 포스팅은 이번 코드를 기반으로 knowledge distillation을 구현하고, Jetson nano 자율주행 구현 방법에 관해 올리겠습니다.

잘 읽었어요~