[논문리뷰] AtLoc: Attention Guided Camera Localization
Abstract
Camera localization 분야에서 Deep learning의 도입이 많은 성과를 내고있지만, 현재 single-image technique 다음 두 부분에서 부족함이 있다.
- Robustness
- Leading to large outliers
이러한 부분은 sequential (multi-images) 나 밝기나 움직이는 물체를 더 좋은 성능을 위해 무시하는 geometry constraint 접근법들을 통해 다뤄질 수 있다.
(본 논문에서 둘 다 사용)
본 논문에서는 attention 이 네트워크가 geometrically robust 한 물체에 더 집중하도록 한다.
Attention 을 도입한 모델은 오직 단 하나의 이미지만 input으로 넣었을 때도 benchmark 에서 다른 SOTA model 들보다 좋은 성들을 보였다.
Saliency map 을 만들어서, 저자들은 어떻게 네트워크가 dynamic object 들을 무시하고, 뛰어난 global camera pose regression performance 를 보이는지를 증명한다.
Introduction
위치 정보는 가상현실, 배달 드론에서 자율주행까지 넓은 애플리케이션 분야의 중요 요소이다.
위치 정보에 관한 유망한 연구 분야는 camera pose regression or localization이다.
- Camera pose regression, localization : 한개 또는 세트의 이미지로부터 3D position 이나 orientation 을 찾는 분야
Camera localization 분야 변화과정
-
초기 Camera localization
Hand crafted feature 들 (key points 나 lines) 등을 이용
문제) 실제 환경에서는 성능이 떨어짐, lighting, blur, scene dynamics 에 취약 => global matching 성능 안좋음 -
PoseNet
Deeplearning base
E2E 로 단일 이미지에서 자동으로 features 와 absolute camera pose를 추출
Hand crafted 작업 없어짐
=> 일반적인 환경에서는 좋은 성능을 보이나 dynamic object 나 illumination change 에 취약, outdoor 환경에서 성능 안좋음(dynamic object 많은 환경) -
VidLoc, MapNet (muliple images)
PoseNet 이 단일 이미지를 사용하고 robustness 문제가 있었음
=> Network input 으로 여러 이미지들을 사용
여러 frame들을 통해 네트워크는 연속적이지 않고 일시적인 특징들(dynamic object) 들을 무시할 수 있음
논문 작성 당시 Camera pose regression 에서 SOTA
=> 이 논문에서는 AtLoc (Attention Guided Camera Localization) 제시
Attention 기반 camera pose regression framework
- 단일 이미지로 multi-frame, sequential techniques 를 능가할 수 있는 모델
- Attentively focus -> 시간적으로 연속적이고 정보를 담고 있는 이미지 부분
- Reject -> Dynamic part of image
이전까지의 방법들과 다르게, AtLoc은 sequential(multiple) frame 과 사람에 의한 geometry 제약이 없다.
(Unlike previous methods, our proposed AtLoc does not require sequential (multiple) frame nor geometry constraints designed and enforced by humans.)
본 논문에서는 AtLoc 모델이 1) Benchmarks 에서 기존 SOTA 모델의 성능을 뛰어넘었고 2) 실내와 실외 시나리오 모두에서 사용 가능하고 3) 심플하고 어떤 handcrafted loss function 없이 e2e 로 학습이 가능하다고 제시한다.
The Main Contribution
- 단일 이미지 camera localization 을 위해 새로운 종류의 self-attention guided neural network 제시했고 정확하고 robust한 camera pose estimation 구현
- Attention 이후 feature saliency map 으로 시각화해서 어떻게 attention 기법이 안정적인 feature 를 얻기 위해 framework에서 역할하는지를 보여줌
- 실내, 실외 두 분야로 확장해서 우리 모델이 SOTA 모델들보다 좋고, multiple frame 기법보다 좋다고 보여줌
Related Work
Deep Neural Networks for Camera Localization
최근 DNNs을 이용해서 camera localization 을 연구한다.
연구경향변화
Traditional Structure-based method, Image Retrieval-based methods 등 이전 방식은 손으로 landmark의 feature들의 데이터베이스나 map 을 만들었다면
이후 DNN-based camera localization method 는 데이터로부터 자동으로 feature들을 학습한다.
PoseNet이 처음으로 단일 이미지로부터 camera pose를 추정하는데 DNN을 도입했다.
이후 RNNs (e.g. LSTM) 이 도임되어 공간, 시간적으로 위치정확도가 상승했다.
Bayesian CNN에서 global camera pose의 불확실성을 추정해서 localization 성능이 더 향상하였고, feature 추출 아키텍쳐를 RNN 으로 대체하였다.
그러나 앞서말한 접근법들은 학습과정에서 Position 과 rotation loss 의 비율을 조절하기 위해 직접 조종해야 하는 인자를 가지고 있다.
(ex. PoseNet 에서 hyperparameter 인 alpha, alpha(position) + (1-alpha)(rotation))
이러한 문제를 다루기 위해 learning weighted loss 와 geometric reprojection loss 가 더 높은 정확도를 위해 도입되었다.
최근엔 한쌍의 이미지들을 사용해 geometric constraints 를 도입하고, training data를 synthetic generation 으로 augment 하는 추가적인 노력이 있었다
본 논문의 모델은 이전 연구들처럼 시간적 정보나 geometry constraints를 사용하기 보단, DNN 기반 camera localization 모델에 attention mechanism을 도입해서 스스로 self-regulate를 하도록 했다. (자동으로 DNN을 constrain 하도록 학습해서 geometrically robust features 에 모델이 집중하도록)
Attention Mechanism
Self-attention mechanism 은 Long-term dependencies 를 포착하는 여러 모델들에서 넓게 사용된다.
처음 Self-attention 은 기계번역을 위해 고안되었고, SOTA 의 성능을 보이고있다.
또한 Image Transformer 에서도 사용한다. (autoregressive model to generate image)
다른 분야에서의 사용은 국소적이지 않은 조작(non-local operation) 인데 공간-시간적 의존성을 video sequence 에서 포착한다.
비슷한 non-local architecture는 GAN 에 도입되어 global long range dependencies을 추출하는데 사용한다.
또한 SLAM system에서 attention 기반 RNN을 back-end optimization 을 위해 사용하지만, camera relocalization 을 위한 것은 아니다.
컴퓨터 비전 분야에서 많은 분야에서 성공적으로 attention 이 사용되고 있지만 아직 camera pose regression 에서는 사용되지 않았다.
이 논문은 non-local style self-attention mechanism 을 camera localization model 에 도입해서 robust key feature들간 관계를 보여는 것의 유효성을 보여주고 모델 성능 향상을 보여준다.
Attention Guided Camera Localizatoin
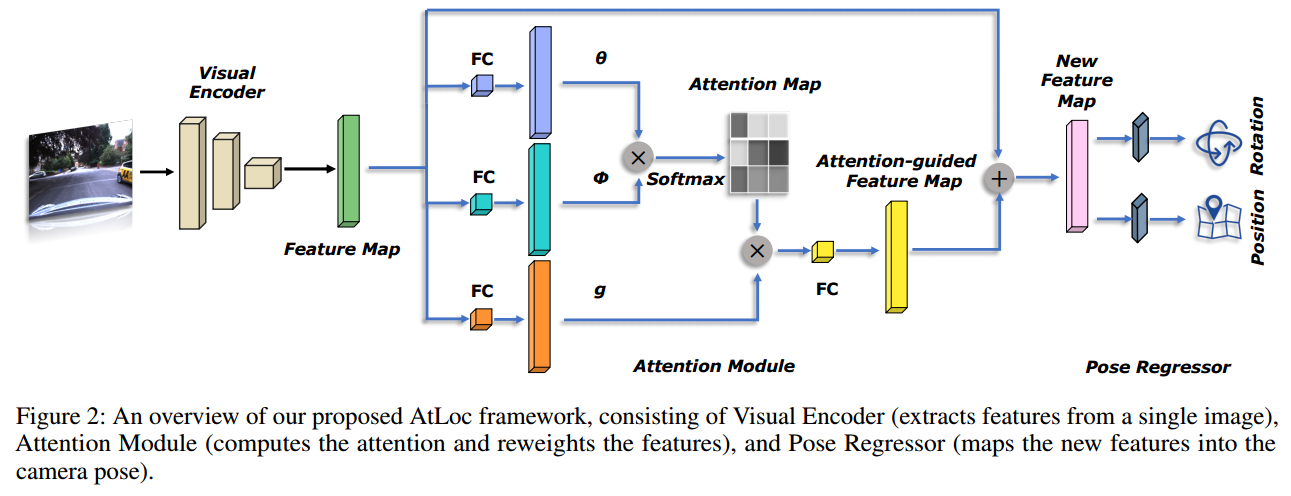
이 파트에서는 Attention Guided Camera Localization (AtLoc) 을 소개하고, self-attention based DNN architecture를 통해 단일 이미지에서 camera pose를 학습하는 것을 보여준다.
이 이미지는 제시한 framework의 모듈적인 개요를 보여주고, visual encoder, attention module, pose regressor로 구성되어있다.
단일 이미지의 내용은 visual encoder를 통해 implicit representation 으로 압축된다.
추출된 features에 따라, attention module은 self-attention map을 계산해서, 앞선 representation을 새로운 feature space로 다시 가중치를 부여한다.
Pose Regressor는 attention operation 이후의 새로운 features를 camera pose로 매핑한다. (3-dimension localtion and 4-dimension quaternion)
Visual Encoder
Visual Encoder는 단일 이미지에서 pose regression 작업에 필요한 features를 추철하는 역할을 한다.
이전 PoseNet 은 GoogLeNet으로, 이루 모델은 ResNet CNN모델을 성공적으로 사용했다. 그중 ResNet 기반 framework는 ResNet의 더 깊은 모델과 gradient vanishing을 막는다는 특징으로 더 안정적이고 정확한 localization 결과를 내놓았다.
그러므로 본 논문은 ResNet34를 AtLoc model의 visual encoder 기반으로 사용했다. ResNet34의 weights는 ImageNet에서 pretrained 된 ResNet34로 초기화했다.
Pose regression 에 의미있는 features를 더 잘 학습할 수 있도록, 기반 네트워크는 마지막 1000dimensional fully connected layer를 C dimension fully connected layer로 대체했고, classification 에서 사용하는 softmax를 제거했다.
C 는 outptu feature의 dimension이다.
모델의 효율성과 성능을 고려했을 때, C=2048 의 dimension 선택하였다.
입력 이미지 , feature 는 visual encoder 를 통해 추출된다.
Attention Module
비록 ResNet34 기반 visual encoder가 camera localization 에 필요한 features를 자동으로 추출하는데 유용하지만, 특정 장면에서 학습된 NN은 featureless appearance 나 동적인 환경에 overfitting 될 수 있다.
이러한 점은 모델의 일반화 성능에 영향을 주고, testing set 에서 모델 성능을 저하시킨다. (특히 변화하는 환경이 튼 outdoor 환경에서)
시간적 정보나 geometric constrains를 도입한 이전 모델과 다르게,
본 논문에서는 self-attention mechanism을 framework에 도입하였다.
Framework 그림에서 self attention module은 visual encoder에서 나온 feature들을 조건화하고, 모델이 안정적이고 geometry meaningful features에 집중할 수 있도록 attention map을 생성한다.
이러한 과정은 그 어떠한 hand-engineering geometry나 prior information 없이 self-regulate 가 가능하도록 한다.
본 논문은 video 분석과 이미지 생성에 사용되는 non-local style self-attention을 attention module로 도입했다.
이러한 모듈의 목적은 long-range dependencies와 global correlations of the image features를 포착해서, 넓게 나누어진 공간으로부터 더 좋은 attention guided feature maps을 생성하는 것에 있다.
Visual encoder에서 추출된 특징 은 첫번째로 두개의 embedding spaces인 , 사이의 dot product의 유사성을 계산하는데 사용된다.
embedding 와 embedding 는 position i 와 j의 features를 두개의 feature space로 각각 선형변환을 한다.
Normalization factor 는 로 모든 feature position j에 대해 정의된다.
주어진 또다른 linear transformation 인 라 하면,
output attention vector 는 다음과 같이 계산된다.
Attention vector 는 신경망이 position 의 feature인 에 집중하는 정도를 나타낸다.
최종적으로, input features 에 대한 self-attention 은 다음과 같이 정의된다.
더 나아가, 본 논문은 self-attention vectors의 linear embedding에 residual connection을 다시 추가한다.
여기서 linear embedding 는 학습가능한 가중치인 를 통해 scaled self-attention vectors를 내놓는다.
제시된 모델에서, fully connected layers는 학습된 matrices 인 들을 생성하기 위해 구현된다. ( 공간에서) 여기서 는 input feature x 의 channel 수이고, n은 attention map 의 downsampling ratio 이다.
실험을 통해 n=8 일 때 가장 성능이 좋음을 알아냈다.
Learning Camera Pose
Pose regressor 는 atttention guided features Att(x) 를 MLPs를 통해 location 과 quaternion 로 각각 매핑한다.
주어진 training image 와 이미지에 대응하는 pose labels인 는 각각 3차원 camera position 과 4차원 orientation 로 표현된다
손실함수는 L1 Loss를 사용하고 아래 Loss function 을 사용한다.
여기서 와 는 position loss와 rotation loss의 balance에 대한 가중치이다.
는 quarternion q 에 대한 로그형식이고 아래와 같이 정의된다.
여기서, u 는 unit quaternion의 real part 이고 v는 imaginary part 이다.
모든 장면들에서, 와 들은 초기값 으로부터 동시에 training 동안 학습된다.
Camera pose regression task 에서 quaternion 은 자주 사용되는데, 연속적이고 미분가능한 수식에서 사용이 쉽기 때문이다.
모든 4D quaternion 을 unit length로 normalizing 하므로써, 논문에서는 쉽게 3D 공간의 rotation 을 valid unit quaternion으로 변환할 수 있었다.
그러나 이러한 작업은 한개의 main issue 가 있는데, quaternion이 unique 하지 않다는 것이다.
그래서 실전에서는, 하나의 rotation 이 두 구 공간에 매핑될 수 있어서 -q와 q가 같은 rotation 을 가질 수 있다. 각 roation 이 다른 값을 가지게 하기 위해서, 모든 quaternions들은 이 논문에서 같은 semishpere로 제한되었다.
Temporal Constraints
이건 시간적 constraints 를 추가한 AtLoc+ 에 관한 것
