LLaVAs : Next Steps in Generalist Multimodal Models

해당 내용은 이용재 교수님의 Invited Talk: Next Steps in Generalist Multimodal Models 에 참석하여 정리한 내용입니다
Introduction
Prevailing Paradigm
Specialist Models : Single Model - Single Task
(Detection Only)
Can I print my documents? 와 같은 문제를 SM 로 어떻게 해결할 수 있는가? 이런 문제들을 잘 해결하지 못한다
Generalist Foundation Models : Single Model - Multi Task
! Steerable(Aligned) models that produce desirable outputs for wide concept knowledge
LLaVA
Understand Visual Data
Follows Human Instructions
Communicates in natural Language
Q : <Vision language models are blind> 논문
기존의 VLM 벤치마크는 주로 고차원적인 시각 이해 능력을 평가하는 데 초점을 맞추고 있습니다. 그러나 BlindTest는 기본적인 시각적 인식 능력을 평가하는 첫 번째 벤치마크로, VLM이 단순한 시각적 과제에서 어떤 한계를 가지는지를 명확히 보여줍니다.
어떤 점을 보완?
모델의 능력
Strong Visual Reasoning Capability
Emergent Multilingual Capability
LLaVA-1.5
Key : 모델을 더 좋게 만들려면
1. 모델의 파라미터 수 증가 (크기 증가)
2. 데이터 수 증가 (Scale Up)
3. Image Input Resolution 증가
Other LLaVAs
ViP-LLaVA
LLaVA that understands visual prompt
Can we make it ?
-> ViP LLaVA : Understanding Freeform Visual Prompts
Prior/Concurrent Work
- Text to denote box coordinates : Shikra, MiniGPT-v2, Ferret
- Region of Interest feature : GPT4ROI
- Learned vocabularies or positional embedding : GPT4ROI, KOsmos -2
-> Bounding Box Form 말고 Freeform Visual Prompt 는 이해하지 못한다는 문제를 확인
Visual Prompt Annotation 을 Overlay 해서 하나의 이미지로 합쳐서 Visual Prompt 로 넣어주는 방법
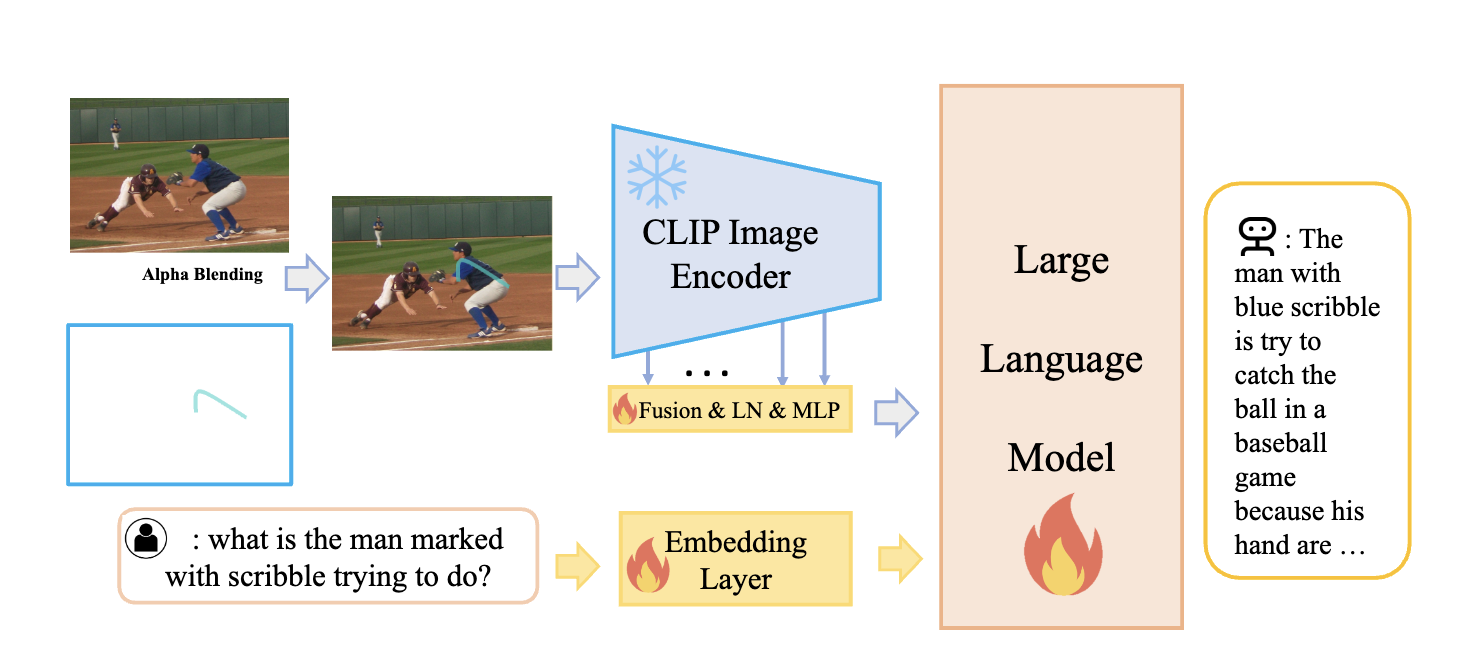
교수님왈 : 주변 랩실에서 ICCV 에 이런 Visual Prompt 관련 논문을 제출했었다. 해당 아이디어 발전
( 학습이나 실험에 활용하는 데이터는 어떻게 구성하였는지? 이런 데이터가 원래 존재하긴하는데 Elipse 같은 없는 조건에 대한 이미지는 휴리스틱하게 그냥 만들어서 사용했다)
Visual Prompt Understanding Benchmark 도 만들었다
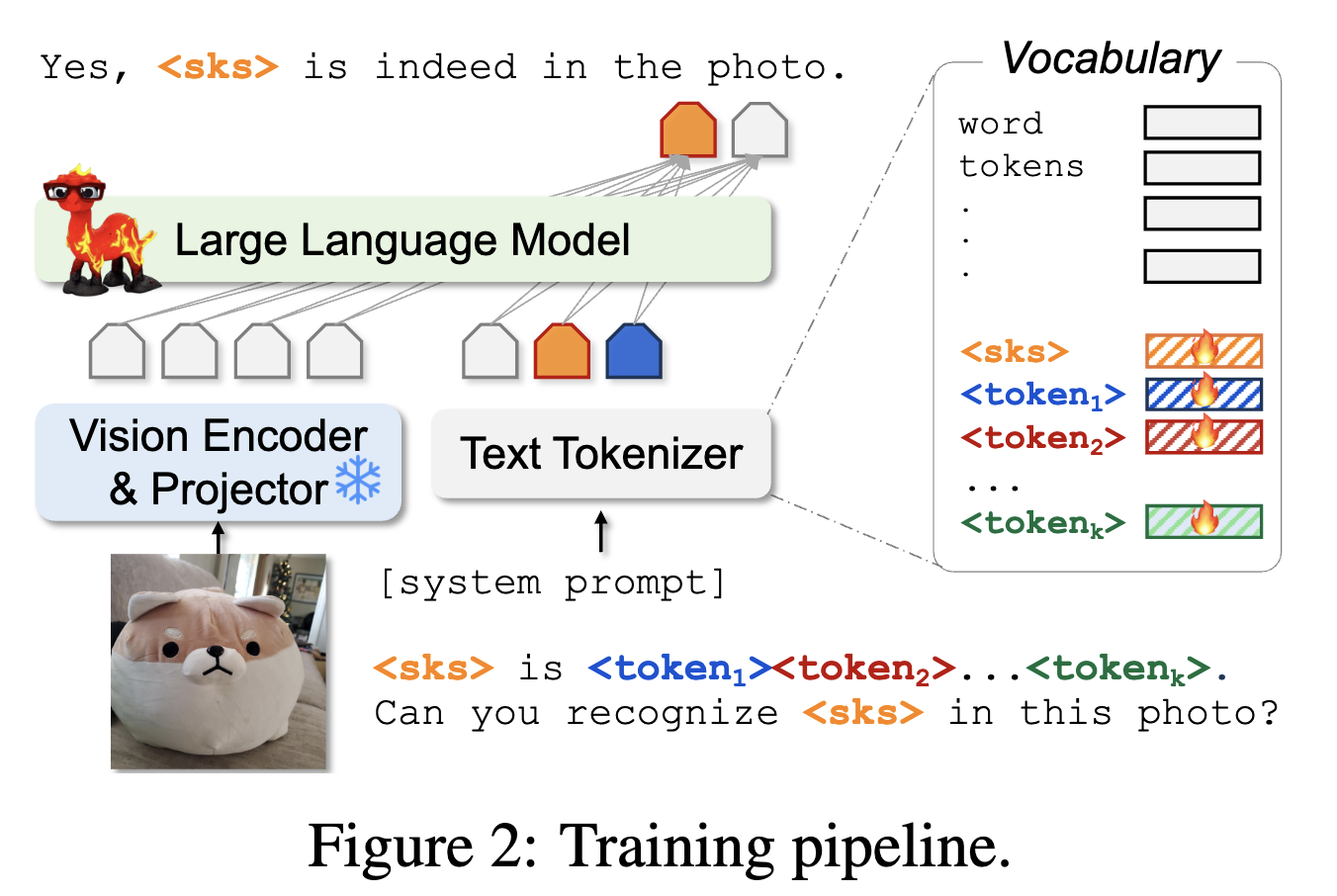
Yo'LLaVA
Your Personalized LMM
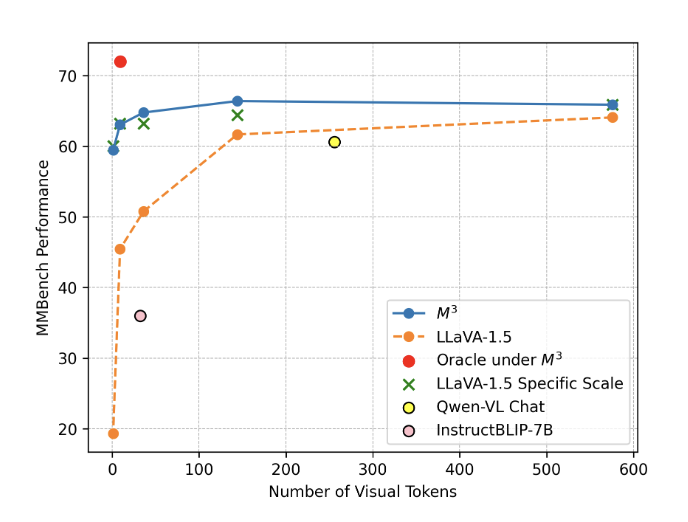
Matryosha Multimodal Models
Bottleneck of Current Multimodal Models
Quadratic 하게 증가하는 token 에 대한 문제가 항상 존재
Video 를 입력으로 받게 된다면 1초당 Image 개수가 기하급수적으로 늘어나기 때문에 이런 문제가 더더욱 심화된다
-> Long HD Video 와 같이 token 이 너무 많으면 Model 이 distract 될 수 있지 않냐
Inspiration 을 어떻게 받았냐?
Matryosha Learning 에서는 Feature Space Embedding 에서 활용하는 그런 것에서 Inspiraton 을 받아서 Token space 에서 진행을 해봤다

다른 Token set 으로 학습하면서 Regularization - Augmentation 이 되지 않았나 이런 영향도 있을 것?
어떤 Token 을 고르는 것이 효율적인지 Adaptive 하게 선택할 수 있는 모델에 대한 연구가 필요하지 않나
Looking forward : Is visual Understanding Solved?
Limitations of Current Models
- Capabilities
- Hallucination (https://arxiv.org/abs/2309.14525)
Video Understanding, Smaller Models (다양한 연구 진행 중 -> 보통은 LM Training 시 Clean 한 데이터를 HQ 데이터를 뽑아낼 수 있으면, 그 데이터로 모델을 Training 하면 large data 로 Training 한 것 보다 좋은 성능을 낸다 -> 나의 연구 관점?) - Multimodal Agents
- etc..
Generalist 모델이 Special 한 task 를 잘 해결하지 못하는 문제점은 항상 고민해야함
Conclusion
From specialist to generalist 가 가장 크게 연구하고 있는 방향성
LLaVA-Next Interleaved 와 같은 Video Model 에 대한 질문
디테일한 부분을 어떻게 수정하고 개선하고 이런 문제보다는 전반적으로 아직 Video Model 에 대해서는 연구가 부족하다는 의견
복잡한 비디오 데이터에 대해서 잘 연구를 못하고 있기 때문에 해결해야할 문제 중 하나
Image 생성 모델에서 Text 만을 입력으로 받는 것은 매우 아쉽다
Visual Prompt 를 충분히 받는 것 또한 중요한 문제이기 때문에 Conditioning 이나 Prompt 의 입력 확장 또한 꼭 필요하다
- Internet Scale 데이터를 받을 수 있는 모델들이 있어서 발전이 있었다
- Transformer 모델의 등장이 매우 큰 영향
-> 어떤 모달리티든지 토크나이즈만 해주고 해당 토큰에 대한 학습을 하면 되니까
Data driven 의 방향성이 맞다 -> 데이터가 적을 때를 해결하는 것은 Algorithmic 한 문제이다.
Foundation model 을 따라가지 못하는 이 상황을 어떻게 해결하고 있는지?
Sora 같은 건 절대 못함 Video 가 어마무시하게 많아야하기 때문에 그것 부터 불가능한 Setup
Smaller Model 만드는 것이 연구실 단위에서는 충분히 가능한 분야이자 필요한 방향성 중 하나라고 생각한다.
PEFT LoRA 같은 것도 사실 Academic 에서 하기 좋은 분야이다
어느정도 HW 는 있어야한다는 기본적인 조건은 존재한다.
