
1. LLaVA (Visual Instruction Tuning)
문제 정의
- 기존 Multimodal task 에 사용하는 Image-text 쌍 데이터(COCO Dataset) 에서 텍스트가 caption 에 국한되는 문제
이런 데이터로 학습하는 모델 특성 상 이미지에 대해 질의응답을 하고 대화를 하는데 한계가 존재

접근 방법
- Visual 에 대해서도 Instruction Tuning 을 해보자!
최근 LLM 들이 Instruction Following sample 들을 활용하여 LLM 의 Alignment 능력을 개선할 수 있다는 사례들이 등장
Contribution
-
Multimodal Instruction Data
- 기존 Image-Text Datasest(COCO) 과 GPT-4 를 활용하여 Image-Text 에 대한 Instruction Data 를 만들기 위한 Data reformation Perspective 및 Data Pipeline 제안
-
Large Multimodal Model
- CLIP 의 Vision Encoder 와 Vicuna 의 Text Encoder 를 연결하여, 생성한 Image-Text Instruction Data 를 End-to-End 로 Fine tuning 한 LMM (Large Multimodal Model) 개발
Methods
1. Instruction Data Generation
기존 COCO Dataset 의 Text 형태

Data Generation 을 위한 Prompt

제작한 Instruction Data 의 종류
- Conversation
- 사진에 대해 질문하는 사람과 이에 답하는 Assistant 사이의 대화 형식. 대답은 Assistant가 이미지를 보고 질문에 대답하는 것과 같은 어조이며, 이미지의 시각적인 정보(객체의 유 형, 수, 행동, 위치, 객체간의 상대적인 위치 등)에 대해 다양한 질문이 존재. 또한 명확하게 답변이 있 는 질문만 고려합니다.
- Detailed description
- 이미지에 대한 풍부하고 포괄적인 설명으로 구성. 이러한 자세한 설명을 요구하는 여러 prompt 리스트를 만든 뒤 그중 하나로 답을 생성
- Complex reasoning
- 위의 두 가지 유형은 시각적 content 자체에 중점을 두며, 이를 기반으로 심층 추론 질문을 추가로 생성합니다. 답변은 일반적으로 엄격한 논리를 따르는 단계별 추론 프로세스를 요구합니다.
2. Visual Instruction Tuning
Model Information
이 연구의 주요 목표는 사전 훈련된 LLM과 vision 모델의 각 모달에 대한 능력(capability)을 효과적으로
leverage 하는 것
LM에 해당하는 는 LLaMA를 기반으로 finetuning한 Vicuna 를 사용
Vision Encoder는 CLIP visual encoder ViT-L/14를 사용
이때 기존 last layer를 제거하고, 이미지 feature를 word embedding space에 연결하기 위해 간단한 linear layer(Projection W) 를 추가
linear layer의 output dimension은 언어 모델의 word embedding space와 같게 설정
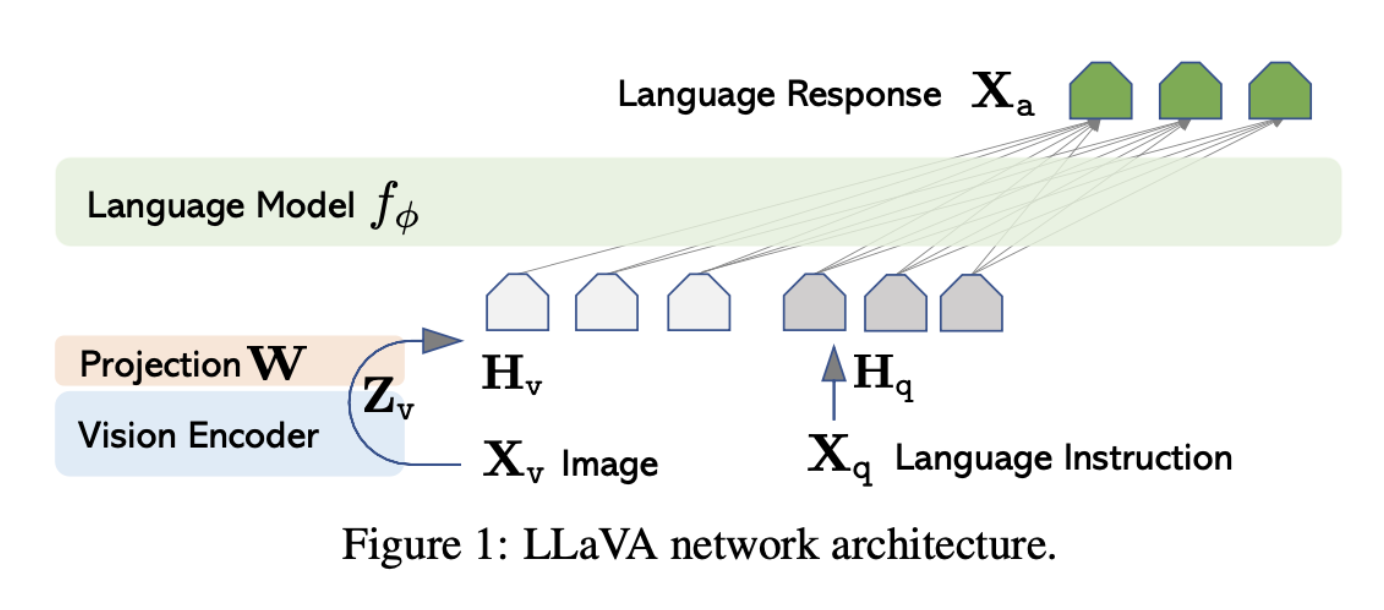
Training Process
Stage 1: Pre-training for Feature Alignment
- concept coverage와 학습의 효율성 사이의 밸런스를 맞추기 위해, 저자들은 CC3M 데이터를 595K image-text pair로 필터링 합니다(기존 CC3M은 약 300만장으로 너무 크기 때문에 이중 적합한 데이터를 사용). 이 데이터들을 instruction-following data로 형식으로 변환합니다. 하지만 이전과 같이 여러 턴의 대화가 아니라 single-turn 대화로 만들었으며, 이미지에 대해 간략하게 설명하도록 요청하는 instruction을 주면 기존의 실 제 캡션을 대답으로 사용합니다. 이때 질문에 해당하는 예는 "Describe the image concisely.", "Provide a brief description of the given image."
Stage1 에서는 visual encoder와 LLM의 weight은 모두 학습하지 않으며(frozen), 오직 linear layer인 projection matrix만 학습합니다. 이를 통해, 이미지 feature는 사전 학습된 LLM의 word embedding과 align 될 수 있습니다. 이 단계는 frozen LLM에 호환되는 visual tokenizer를 학습하는 과정으로 이해할 수 있습니다.
Stage 2: Fine-tuning End-to-End
- 이때는 visual encoder만 frozen하고, LLM과 projection layer 두 모듈을 학습합니다. 저자들은 두 가지 시나리오에 대해 고려했습니다.
- 1) Multimodal Chatbot : 앞에서 설명한 158K language-image instruction-following data를 이용 해 fine-tuning한 Chatbot 입니다. 세 가지 타입의 응답 중 대화는 multi-turn이고 나머지 두 개는 Single-turn입니다. 이 타입들은 훈련 과정에서 uniform하게 샘플되어 학습에 사용됩니다.
- 2) Science QA : 저자들은 ScienceQA benchmark에서 고안한 방법을 테스트 했습니다. 이 데이터셋의 각 질문에는 언어 혹은 이미지로 이루어진 context가 주어지고, 모델은 자연어로 추론 과정을 답하고 객관식 에서 답을 선택하는 테스크입니다. 이를 위해 데이터를 단일(single-turn) 대화 형식으로 구성하는데, 이때 질 문과 context를 지시(instruct)로 주고, 맞춰야 하는 답변으로 추론과 정답 데이터를 줍니다.
즉 전체 학습과정에서
Vision Encoder 는 항상 Freeze 되어 Feature 만 제공
Language Model 은 Pre-trained model 이므로 Stage 2 에서 Fine tuning 만 진행
Linear Layer 는 아예 학습이 안되어 있으니까 Pre-training + Fine tuning 까지 진행
2. LLaVA-1.5 (Improved Baselines with Visual Instruction Tuning)
문제 정의
- LLaVA 라는 성능 좋은 LMM 을 발전시킬 수 있는 방법은?
1. 더 효율적으로 모델을 학습시킬 수는 없나?
2. 더 좋은 성능을 내게 만들 수 있는 방법은 없나? (+ 고해상도 이미지 입력으로 확장) - 비슷한 방식을 활용하는 InstructBLIP 의 문제점은 뭐지? 왜 그런문제가 생겼지?
Preliminaries
LLaVA
장점 : Visual Reasoning 성능이 뛰어남
단점 : Academic Benchmark 에서 성능이 떨어짐
InstructBLIP
장점 : Academic Benchmark 를 포함한 VQA Task 에서 좋은 성능
단점 : Real-life visual conversation task 에서 문제 발생
이 두개가 왜 그런지 파악하고 적절히 섞으면 되지 않겠느냐
접근 방법
Key : 모델을 더 좋게 만들려면
1. 모델의 파라미터 수 증가 (크기 증가)
2. 데이터 수 증가 (Scale Up)
3. Image Input Resolution 증가
Methods
1. Response Format Prompting
InstructBLIP 의 경우
응답 형식이 명확하지 않아서 답만 뱉는 짧은 형식으로 Overfit 할 수 있음
LM 을 Finetuning 하지 않고 Adapter 인 Qformer 만 finetuning 하기 때문에 발생하는 문제도 존재

"Answer the question using a single word or phrase." 와 같은 프롬프트 추가
2. Scaling the Data and Model
- Adapter 를 기존 Linear 에서 Two-layer MLP 로 변경
- 다양한 VQA, GQA, ShareGPT 데이터셋 추가
- CLIP-ViT-L-336px 비전인코더 사용
- LLM 을 Vicuna 13B 모델로 확장

3. Scaling to Higher Resolutions
고해상도의 입력을 받을 수 있도록 모델 개선

Divide image into smaller patch : 원래 해상도로 훈련된 vision encoder로 처리 가능한 작은 이미지 크기로 나눔.
Encode independently : 각 패치를 독립적으로 인코딩
Combine into single large feature map : 개별 패치의 특성 맵을 큰 특성 맵으로 결합한 후 LLM에 입력.
Concatenate downsampled image to feature map : 분할-인코딩-결합 작업의 인공물을 줄이기 위해 다운샘플링된 이미지의 특성도 결합됨.
Reference
LLaVA Part 참고 :
cocoa Tistory
LLaVA 1.5 Part 참고 :
Blog by rubatoyeong
전생했더니 인공지능이었던 건에 대하여
