[Class Review](MDA_강필성) 2. Multiple Linear Regression

- 본 글은 서울대학교 산업공학과 DSBA 연구실 강필성 교수님의 "다변량데이터분석" 학부강의의 review 입니다.
1. Multiple Linear Regression
1.1. Overview
당신이 중고차를 구매하려 한다고 가정해보자. 한정된 예산 내에서 가장 가치있고 합리적인 소비를 하기 위해, 각 매물의 가성비를 따져볼 것이다. 이때 연식, 누적주행거리, 마력, 배기량, 색깔 등이 고려대상으로 선정될텐데, 각 항목이 가격결정에 얼마만큼의 영향을 미치느냐를 파악하는 것이 가성비 판단에 핵심이 될 것이다.
이때 우리가 사용하는 것이 다중선형회귀분석(Multiple Linear Regression)이며, 여러 개의 설명 변수(독립 변수, X, Independent variables = attributes = features)와 하나의 종속 변수(Y, =dependent variable) 간 선형 관계를 모델링하는 기법이다.
즉, 충분히 많은 와 의 조합들이 주어졌을때, 와 사이의 관계를 맺어주는 β를 찾는게 목적이다.
"다중선형회귀분석의 회귀계수를 찾는다" 라고도 표현
독립 변수(X): 설명 변수 (예: 자동차의 주행거리, 연식, 마력 등)
종속 변수(Y): 예측하고자 하는 변수 (예: 중고차 가격)
베타 계수(β): 회귀계수. 각 독립 변수가 종속 변수에 미치는 영향의 크기
노이즈(ε): 우리가 어찌할 수 없는 변동성
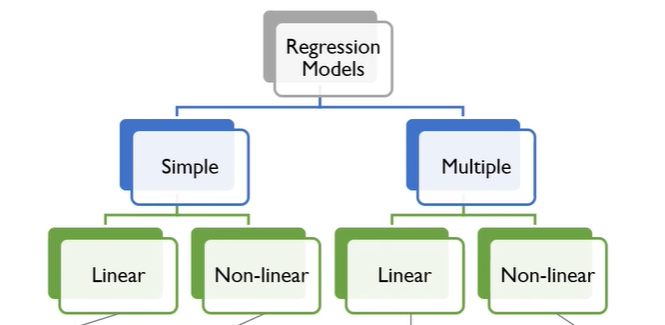
우리가 살펴보려는건 Regression Models - Multiple - Linear 이다. 회귀분석에 설명변수는 여러개를 가지면서, 독립 변수와 종속 변수의 관계는 선형으로 가정하는 경우를 살펴볼 것이다.
1.2. Ordinary Least Square(OLS, 최소자승법)
그렇다면, 다중선형회귀분석에서의 최적의 회귀계수를 추정하는 방법이 필요한데, 가장 대표적인 것은 Ordinary Least Square(이하 OLS)이다. 실제 타겟값과 회귀식에 의해서 추정된 값의 차이를 최소화하는데에 그 목적이 있다.
- Actual target :
- Predicted target :
- Goal : minimize the difference between the actual and predicted target.
다변량데이터분석과 머신러닝 관점에서는 Matrix soultion으로 접근하는 방법을 익혀두는 것이 훨씬 편리하다.
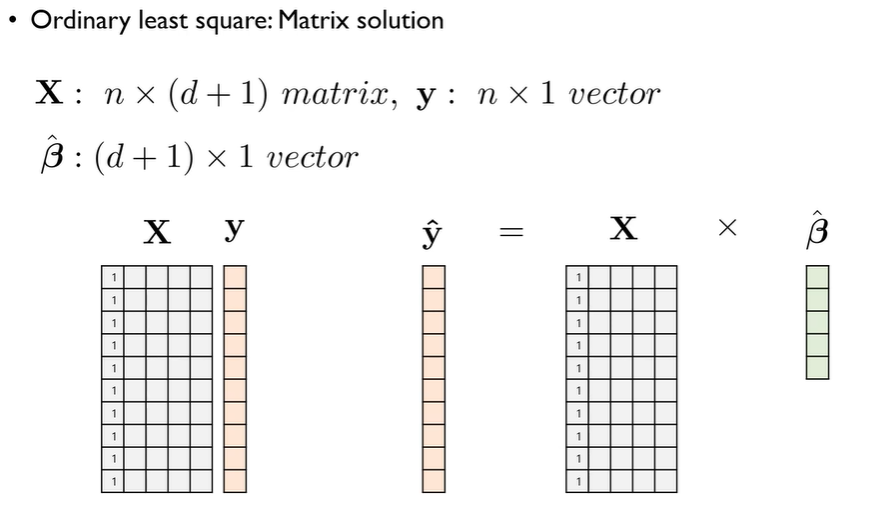
이 식이 의미하는 바는, 수식을 꼭 암기해야 한다기 보다는 Uniqe and explicit solution 이 존재한다는 것이다. 강조한 되는 것은 그냥 공식만 외우는 것이 아니라, 이 공식을 사용할 수 있는 조건(유일성, 명시성)을 이해하는 것이 중요하다는 것이다.
- 유일성(Unique Solution): 해가 존재하고 하나로 결정됨 → 가 가역이여야 함.
- 명시성(Explicit Solution): 반복적인 최적화 없이 직접 해를 구할 수 있음 → 선형 대수적 계산 가능.
즉, 공식을 무작정 외우는 것이 아니라, 언제 이 공식을 적용할 수 있고, 언제 적용할 수 없는지 이해해야 한다는 뜻이다.
1.2.1. Ordinary Least Squares (OLS) 회귀의 조건
앞서 설명한대로, Ordinary Least Squares (OLS) 회귀는 주어진 데이터에서 가장 적합한 선형 회귀 계수(β)를 찾는 방법이다. 그러나 OLS가 최적의 추정값을 보장하려면 몇 가지 중요한 가정(assumptions)이 충족되어야 한다.
- The noise (ε) follows a normal distribution.
(잔차(오차항)는 정규분포를 따른다.) - The linear relationship is correct.
(독립변수와 종속변수 사이의 관계는 선형적이어야 한다.) - The cases are independent of each other.
(각 데이터 포인트(샘플)는 서로 독립적이어야 한다.) - The variability in Y values for a given set of predictors is the same regardless of the values of the predictors (homoskedasticity).
(등분산성: 예측 변수 값에 관계없이 종속 변수의 변동성이 일정해야 한다.)
하지만 2번째와 3번째 조건은 머신러닝 관점에서 검증을 엄격하게 할 수 없다. 따라서 1번째와 4번째 조건에 집중해서 부가 설명을 덧붙여본다.
1) The noise (ε) follows a normal distribution (잔차 정규성 가정)
- OLS 회귀의 중요한 가정 중 하나는 오차항(Noise, ε)이 정규분포를 따라야 한다는 것이다. 즉, 회귀 모델이 예측한 값과 실제 값 간의 차이(잔차)가 정규분포를 따른다면, OLS는 신뢰할 수 있는 추론을 제공할 수 있다는 것이다.
이 가정이 필요한 이유:
- 회귀 분석에서 β의 신뢰구간(confidence interval)과 p-value를 정확히 계산하기 위해 필요하다. 만약 오차항이 정규성을 따르지 않으면, t-검정과 F-검정 같은 통계적 검정의 유효성이 떨어질 수 있다.
- 특히, 표본 크기가 작을 때 정규성을 따르는 것이 더 중요하다. (표본 크기가 크면 중심극한정리에 의해 덜 중요하다.)
2) The variability in Y values for a given set of predictors is the same regardless of the values of the predictors (Homoskedasticity, 등분산성 가정)
- 등분산성(Homoskedasticity)은 독립변수(X)가 변해도 종속변수(Y)의 분산이 일정해야 한다는 것을 의미한다. 즉, 데이터의 어느 부분에서든 잔차(Residuals)의 변동성이 일정해야 한다는 뜻이다.
이 가정이 필요한 이유:
- 만약 분산이 일정하지 않다면(즉, 이분산성 Heteroskedasticity 발생), 회귀 계수의 추정값이 효율적이지 않게 되고, 신뢰구간(confidence interval)과 p-value의 신뢰성이 떨어지며, 일반적인 OLS 표준오차(Standard Errors)가 과소/과대 추정될 수 있다.
2. Evaluating Regression Models
2.1. Preview of Evaluation
2.1.1. 결정 계수 (Coefficient of Determination)
- 값이 0에서 1 사이의 값을 가진다.
- 값이 1에 가까울수록 회귀 모델이 데이터를 잘 설명함을 의미한다.
- → 완벽한 선형 관계이다 (모든 변동을 설명).
- → 독립 변수가 종속 변수를 전혀 설명하지 못한다.
공식 유도
결정 계수 는 총 변동(SST) 중에서 회귀식으로 설명 가능한 변동(SSR)의 비율을 의미하며, 아래와 같이 정의됨:
각 항목 설명
- SST (Total Sum of Squares): 전체 데이터의 총 변동성
- SSR (Regression Sum of Squares): 회귀 모델이 설명하는 변동
- SSE (Sum of Squared Errors): 잔차의 변동성 (모델이 설명하지 못하는 부분)
따라서, 값이 클수록 모델이 데이터를 잘 설명하고 있음을 의미하며, 1에 가까울수록 좋은 모델임을 나타냄. 🚀
2.1.2. 수정 결정 계수
- 변수 개수가 증가할 때 발생하는 문제를 보정한 결정 계수이다.
- 불필요한 변수를 추가했을 때에도 단순 는 증가할 수 있으므로 (사실은 오히려 쓸모없는 변수가 증가한 것이므로 긍정적이지는 않음) 이를 보정한 지표.
Adjusted 공식
Adjusted 의 핵심 개념
- 는 단조 증가(monotonically increasing) 특성이 있기때문에, 변수 개수가 증가하면 무조건 증가하게 된다. 하지만 추가된 변수가 의미 없는 변수(Insignificant Variable)라면, 는 증가하지 않도록 설계할 필요가 있다.
- Adjusted 는 불필요한 변수를 추가할 때, 페널티를 적용하여 보정된 결정 계수를 제공 하는데 그 의의가 있다.
- 이는 회귀 모델이 불필요한 변수를 추가하여 단순히 값을 높이는 문제를 해결하기 위한 방법이다.
Adjusted 의 특성
- 는 단순히 변수를 추가할수록 증가하지만, Adjusted 는 그렇지 않다.
- 설명력이 없는 변수를 추가하면 Adjusted 는 감소하거나 유지된다.
- 그래프에서 보듯이, Adjusted 는 적절한 변수 개수에서 수렴하며 급격히 증가하지 않는다.
2.1.3. p-value (유의 확률)
- p-value < 0.05 이면 해당 변수는 유의미한 영향을 미친다고 판단한다.
- p-value가 크면(예: 0.5 이상) 해당 변수가 모델에 크게 기여하지 않음을 의미한다.
2.2. Performance measure - Metric
2.2.1. Average Error
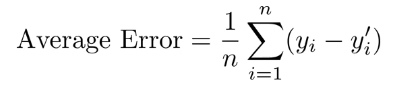
- 실제 값과 모형에 의해 예측된 값 차이의 평균을 산출하는 지표이다 (평균 오차)
- 양의 값과 음의 값을 구분해서 계산할 수 없기에, 사용해서는 안되는 지표이다. (부호문제 상쇄 불가능)
2.2.2. Mean Absolute Error (MAE)
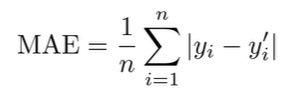
- 실제 값과 예측 값 간의 차이(오차)의 절대값 평균을 구하는 방식이다.
- 단점으로는 오차가 큰 수에서 발생할 때와 작은 수에서 발생할 때를 동일한 중요도로 평가함. (0과 1, 100과 101, 두 가지 예시 모두 1의 차이가 발생하므로 동일하게 평가함)
2.2.3. Mean Absolute Percentage Error (MAPE)
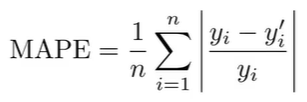
- 오차를 원래 값(Y)과 비교하여 상대적인 오차 비율을 구하는 방식이다. 단위에 영향을 받지 않아 비교하기 용이하며, MAE의 단점을 극복하였다.
- 단점으로는 실제 값 Y가 0에 가까운 경우 오차 비율이 매우 커지는 문제 발생한다.
2.2.4. Mean Squared Error (MSE)
2.2.5. Root Mean Squared Error (RMSE)

-
MSE(Mean Squared Error)와 RMSE(Root Mean Squared Error)는 회귀 모델의 예측 성능을 평가하는 가장 대중적이고 많이 사용하는 지표이다. 두 지표는 기본적으로 오차(Error)를 제곱하여 평균을 구하는 방식을 따르지만, RMSE는 MSE의 단위를 보정하기 위해 제곱근을 취해준다.
-
MSE는 모델의 학습(최적화) 과정에서 손실 함수로 많이 활용되며, 오차가 큰 값을 강조하는 특성이 있고, RMSE는 평가 과정에서 더 직관적인 지표로,
모델이 예측한 값이 실제 값과 얼마나 가까운지를 해석하기에 적합하다. 두 지표 모두 큰 오차를 강조하는 특성이 있으므로, 이상치(Outlier)에는 민감하다.
AE는 제외하고서, 어느 Metric을 사용하는 것이 가장 합리적일지는 상황에 따라 다르다. 따라서 이 네 가지의 지표를 모두 잘 알아두어야 한다!
3. Reference
[1] Korea University - Multivariate Data Analysis 02_part_1 ~ 01_part_2
