[Class Review](MDA_강필성) 3. Logistic Regression

- 본 글은 서울대학교 산업공학과 DSBA 연구실 강필성 교수님의 "다변량데이터분석" 학부강의의 review 입니다.
1. Logistic Regression: Formulation
1.1. What is Logistic Regression?
Logistic Regreesion은 이진분류(Binary Classification)문제를 해결하기 위한 회귀 기법이다. 지난 시간까지 다루었단 선형회귀(Linear Regression)와는 달리, 로지스틱 회귀는 [0, 1] 까지의 제한된 범위의 확률값을 예측하는 기법이며, 종속변수 가 특정 범주에 속할 가능성을 모델링 하거나, 특정 확률을 가질 가능성을 계산한다.
왜 로지스틱 회귀를 이용해야 하는가?
이진 분류 문제에서 선형회귀를 사용할 경우에는 아래와 같은 문제가 발생할 수 있기 때문이다.
- 선형 회귀 모델의 예측 값이 0과 1사이를 벗어날 수 있다
- 실제 데이터에서 확률은 일직선의 곧은 형태보다는, S자 모양(Sigmoid Curve) 형태를 따르는 경우가 더 많다.
따라서, 이러한 문제들을 해결하기 위해 로지스틱 회귀에서는 Sigmoid 함수를 적용하여 예측값을 확률 형태로 변환하는 방법을 사용한다.
참고!
로지스틱 회귀라는 명칭은 “논리적(로지컬)”이라는 의미와는 무관하고, 모델에서 사용하는 함수가 바로 로지스틱(시그모이드) 함수이기 때문에 붙여진 이름이다.
로지스틱 함수는 모든 실수값을 0과 1 사이의 값으로 매핑하는 S자 형태의 함수로, 아래와 같이 정의된다.
1.2. Logistic Regression: Formulation
Logistic Regression은 확률 를 예측하는 모델이며, 이를 위해 승산(Odds)과 로그 변환(Log Transformation) 개념을 활용한다.
Step 1: Define Probability and Odds
-
확률(Probability)과 승산(Odds)의 정의
- : 주어진 입력 에 대해 이 될 확률이다
- 따라서,
- 승산(Odds) 는 해당 사건이 발생할 확률을 발생하지 않을 확률로 나눈 값으로 정의된다. -
로 정의된다.
- 예를 들어 승산이 3이면 해당 사건이 3번 발생할 때, 1번 발생하지 않음을 의미한다.
Step 2: Log-Odds (Logit Function) 적용
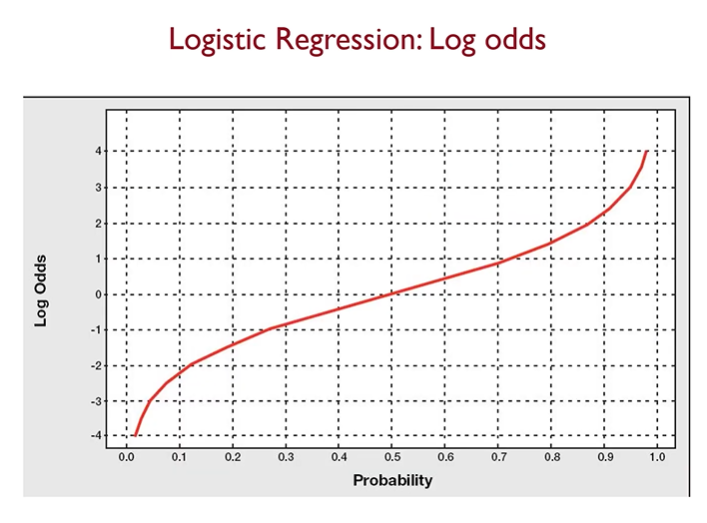
-
로지스틱 회귀는 승산(Odds)을 로그 변환(Log Transformation) 한 후, 선형 회귀 모델을 적용한다.
-
-
위 식에서 좌변은 Log-Odds 또는 Logit 함수이며, 이를 통해 예측 값이 모든 실수 값(-∞, ∞)을 가질 수 있도록 변환된다.
Step 3: Sigmoid Function을 사용하여 확률 예측
-
Log-Odds 식을 정리하면 최종적으로 Sigmoid 함수(로지스틱 함수, Logistic Function) 형태를 얻을 수 있게 된다.
-
-
이 과정까지 거치게 되면, 모든 실수 입력값을 받아 0~1 범위의 확률값을 출력하는 함수가 완성된다!
1.3. Example: Predicting Binary Outcomes
Example: 지하철 자리찾기 알고리즘
로지스틱 회귀를 이용하여 만원 지하철에서 승객이 다음 역에서 내릴 확률을 예측해볼 수 있다.
- 입력 변수 : 승객의 행동 및 특징
- = 목적지가 가까운지 여부
- = 손에 든 물건의 개수
- = 신문을 보고 있는지 여부
- 종속 변수 : 하차 여부
- 다음 역에서 하차
- 하차하지 않음
- 로지스틱 회귀를 이용하면 각 승객이 다음 역에서 내릴 확률을 조건부확률을 이용해서 을 계산할 수 있다.
2. Logistic Regression: Learning
2.1. Overview of Learning
- 로지스틱 회귀 모델을 학습하는 과정은 선형 회귀와 다르게 비선형적인 확률 모델을 다루기 때문에, 수식적으로 해석 가능한 해(Closed-form solution)가 존재하지 않는다. 따라서 최적화 알고리즘(Optimization Algorithm)을 사용하여 회귀 계수(β)를 학습해야 한다.
2.2. Maximum Likelihood Estimation (MLE)
2.2.1. 모델 평가 기준: 좋은 모델이란?**
-
좋은 로지스틱 회귀 모델은 정답 범주(0 또는 1)에 가까운 확률을 예측해야 한다.
-
예를 들어, 다음과 같은 두 모델이 있다고 하자.
샘플 정답 (Y) 모델 A의 예측 확률 모델 B의 예측 확률 1 1 0.9085 0.5 2 0 0.79 0.57 -
모델 A는 정답 범주(0 또는 1)에 더 가까운 확률을 예측했으므로 '모델 A가 더 우수한 모델'이라고 평가 가능하다. 이때 우도가 크다는 표현을 사용한다. 따라서 우리의 목표는 우도를 최대화 하는 것이다. 우도의 정의와 우도를 크게 만드는 방법에 대해서는 후술하기로 한다.
2.2.2. 우도 함수(Likelihood Function) 정의
우도(Likelihood)는 모델이 주어진 데이터를 얼마나 잘 설명하는지를 평가하는 함수이다. 즉, 각 샘플 의 우도는 정답 클래스에 속할 확률을 의미한다.
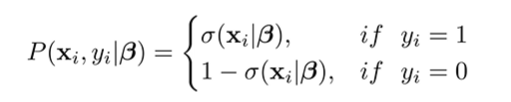
- 정답이 1일 경우:
- 정답이 0일 경우:

즉, 전체 데이터셋의 우도(Likelihood)는 모든 샘플의 확률을 곱한 값으로 정의된다. (각각의 객체가 생성될 확률을 독립으로 가정할 시!)
2.2.3. 로그 우도 함수(Log-Likelihood) 변환
- 우도 함수는 확률 값(0~1)을 반복적으로 곱하는 형태이므로, 데이터 개수가 많아질수록 값이 매우 작아져 수치적으로 취약한 문제가 발생하게 된다.
- 이를 해결하기 위해 로그 변환을 적용하여 로그 우도(Log-Likelihood)를 최적화하는 방식을 채택했다.
이제 최적의 회귀 계수(β)는 로그 우도(Log-Likelihood)를 최대화하는 값이 되었다. 하지만 로그 우도 식을 해석적으로 미분하여 β 값을 구할 수 있는 방식은 없으므로 최적화 알고리즘을 사용해야 한다.
2.3. Gradient Descent (경사 하강법)
2.3.1. 최적화 문제 해결 방법
로그 우도 함수를 최대화하기 위해 경사 하강법(Gradient Descent) 을 활용한다. 미분 가능한 비용함수를 최소화 하는 방향으로 주로 진행한다.
-
기본 원리:
- 초기 회귀 계수(β)를 랜덤하게 설정한다.
- 로그 우도 함수의 기울기(Gradient)를 계산한다.
- 기울기가 가리키는 방향의 반대 방향으로 이동시킨다.(gradient의 역방향으로 가야지 cost function이 최소화 되는 방향으로 나아갈 수 있기 때문!)
- 최적의 β 값이 나올 때까지 이를 반복한다.
-
β 값 업데이트 공식
- : 학습률(Learning Rate)
- : 로그 우도의 기울기
- 산 정상에서 가장 낮은 지점(최소 비용)을 찾아가는 과정과 유사하다. 현재 위치에서 기울기(Gradient)를 확인하며 천천히 이동하게 된다. 이때 학습률(α)을 신중하게 설정해야하는데, 학습률이 너무 크면 최적점을 지나칠 위험이 있고, 학습률이 너무 작으면 수렴 속도가 너무 느려지게 된다.
2.3.2. Cut-off (Thresholding)
- 로지스틱 회귀 모델의 예측값
- 지금까지 말했듯, 로지스틱 회귀는 0 또는 1로 직접 분류하는 것이 아니라 확률 값(0~1)을 예측하는 것이다.
- 따라서, 특정 임계값(Threshold)을 설정하여 확률이 일정 기준을 넘으면 1, 아니면 0으로 분류하게된다.
- 기본적인 임계값 (Threshold) 설정
- 일반적으로 0.5를 기본 임계값으로 사용한다.
- → 1로 분류
- → 0으로 분류
- 도메인 별 임계값 조정
- 제조업(불량 탐지):
- 불량을 더 민감하게 탐지하기 위해 임계값을 0.3~0.2로 낮출 수 있다.
- 금융 대출 심사(사기 탐지):
- False Positive를 최소화하기 위해 임계값을 0.7 이상으로 높일 수 있다.
- 이처럼 산업군별로 그 산업에 최적화된 임계값을 설정하여 성능을 최대한으로 끌어올리는 방법이 주요하다.
3. Logistic Regression: Interpretation
3.1. Understanding Logistic Regression Coefficients
로지스틱 회귀는 로그 승산(Log-Odds)을 예측하는 모델이며, 선형 회귀와 다르게 회귀 계수(β)의 해석이 직관적이지 않은 문제가 존재한다. 따라서 승산비(Odds Ratio, OR)를 활용하여 계수를 해석하는 방법을 사용한다. 또한 다범주 로지스틱 회귀(Multinomial Logistic Regression)를 이용하여 세 개 이상의 클래스를 분류하는 방법도 존재한다.
3.2. Logistic Regression vs. Linear Regression
- 선형 회귀 (Linear Regression)
- 종속변수 가 연속적인 값(예: 가격, 키, 무게 등)일 때 사용한다.
-
- 해석이 직관적이다. 예를 들어, 이 1 증가하면 는 만큼 증가한다.
- 로지스틱 회귀 (Logistic Regression)
- 종속변수가 이진(0 또는 1)일 때 사용.
- 예측 확률을 직접 구하지 않고, 로그 승산(Log-Odds)을 예측하는 모델**.
-
- 직접적인 해석이 어렵기에 승산비(Odds Ratio)를 사용하여 해석하게 된다.
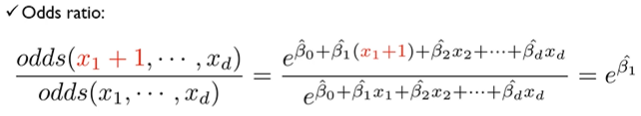
회귀 계수(β)의 의미
-
선형 회귀에서 은 이 1 증가할 때 가 변화하는 양을 의미한다. 로지스틱 회귀에서는 이 Log-Odds의 변화량을 의미하게 다.
-
로그 승산(Log-Odds)을 확률로 해석하기 어려우므로, 지수를 취한 값인 을 사용하게 되는데, 공식은 다음과 같다.
- → 이 증가하면 성공 확률 증가.
- → 이 증가하면 성공 확률 감소.
<예시>
- 신용카드 사용 잔액(Balance)이 1000 증가할 때, 디폴트(연체) 확률 증가 여부를 확인해볼 수 있다.
- 회귀 계수는 로 가정한다. 이때, 가 됨.
- 즉, 카드 사용 금액이 1000 증가할 때 디폴트(연체) 확률이 0.5% 증가하는 것으로 해석 가능하다는 것.
3.3. Multinomial Logistic Regression (다범주 로지스틱 회귀)

윗 그림 아랫쪽 수식에서 '~~ Class2 -> ~~ Class3' 오타 유념!
3.3.1. 개념
- 로지스틱 회귀는 기본적으로 이진 분류(Binary Classification) 를 수행하는 모델이지만, 실제 문제에서는 종속변수가 세 개 이상의 범주(Class)를 가지는 경우가 많다. 이러한 경우 다범주 로지스틱 회귀(Multinomial Logistic Regression) 를 사용하여 확장할 수 있다. 다범주 로지스틱 회귀는 여러 개의 클래스 중 하나를 예측하는 문제를 해결하는 확률 모델이며, 각 범주에 대한 확률을 추정하여 특정 입력에 대해 가장 가능성이 높은 클래스를 선택하는 방식으로 동작한다.
3.3.2. 다범주 로지스틱 회귀의 핵심 원리
- 이진 분류를 수행하는 일반적인 로지스틱 회귀는 단 하나의 회귀 방정식을 기반으로 를 계산하지만, 다범주 로지스틱 회귀에서는 여러 개의 범주(class)에 대한 확률을 각각 계산해야 한다. 이를 위해 특정 기준이 되는 하나의 베이스라인(Base Class) 을 정하고, 나머지 범주들을 이 기준과 비교하는 방식으로 확률 모델을 구성한다. 즉, 각 범주에 대해 별도의 로지스틱 회귀 방정식을 정의하고, 이를 통해 각 클래스가 선택될 확률을 계산하는 방식이다.
- 다범주 로지스틱 회귀에서는 모든 클래스에 대해 독립적으로 회귀 계수를 추정하며, 특정 클래스에 속할 확률은 소프트맥스(Softmax) 함수를 이용해 정규화된다. 이는 모델이 출력하는 각 클래스의 점수를 확률 값의 형태(0~1 범위) 로 변환하여 비교할 수 있도록 한다. 결과적으로, 다범주 로지스틱 회귀는 한 개의 선형 방정식이 아닌 여러 개의 회귀 방정식을 통해 각 범주에 대한 상대적인 확률을 추정하는 방식으로 동작하며, 이를 통해 주어진 입력이 어떤 범주에 속할 가능성이 가장 높은지를 예측한다.
4. Classification Performance Evaluation
이 부분에서는 꼭 로지스틱 회귀분석이 아닌, 조금 더 보편적인 범위에서의 Classification Model에 통용되는 평가 방식에 대해서 설명할 것이다.
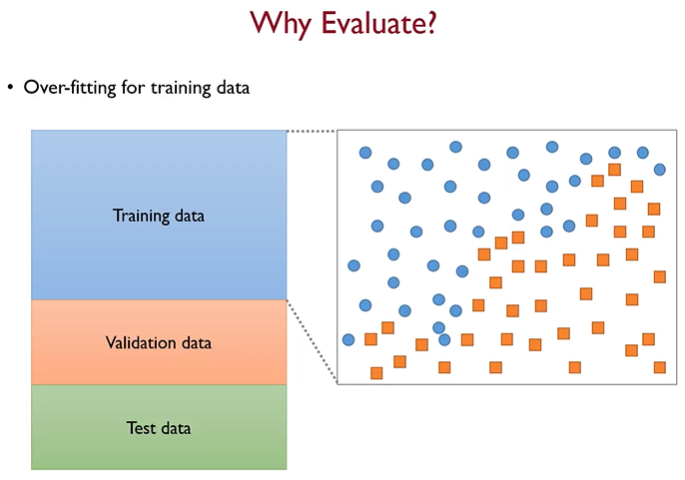
4.1. Why should we Evaluate?
-
우리의 목적은 위 그림에서 파란색 동그라미와 주황색 네모를 분리하는 것이다.
-
단순히 생각하기에는 왼쪽 하단과 우측 상단을 일직선으로 잇는 직선이 가장 이상적이라고 생각할 수 있지만, 현실세계의 데이터에서는 항상 오차(에러)가 존재하므로 무작성 Training data의 모든 것을 전부 다 학습해서는 안된다.
-
우리가 특정 기준을 가지고 Model을 Evaluate해야하는 이유는, Training data뿐만아니라, Test data에 대해서도 높은 예측력을 유지할 수 있느냐를 확인해야하기 때문이다!
-
데이터 분석에서는 주어진 데이터를 분류(Classification) 하거나 예측(Prediction) 하는 두 가지 방식이 있으며, 각각의 목적에 따라 적절한 알고리즘이 사용된다. 분류는 데이터를 특정 범주(Class)로 구분하는 작업으로, Naïve Bayes, K-NN, 의사결정 트리 등이 대표적인 알고리즘이다. 반면, 예측은 연속적인 값을 추정하는 작업으로, 다중 선형 회귀, 신경망, 회귀 트리 등이 사용된다.
-
각 모델을 사용할 때는 다양한 설정을 조정해야 하며, 특히 신경망에서는 은닉층 노드 수나 활성화 함수와 같은 하이퍼파라미터 튜닝이 필요하다. 최적의 모델을 선택하기 위해서는 먼저 Validation 을 통해 동일한 알고리즘의 여러 설정값을 비교한 후, Test를 통해 다양한 알고리즘 간의 성능을 평가해야 한다. 이를 통해 특정 데이터에 가장 적합한 모델을 찾을 수 있으며, 모델의 일반화 성능을 보장할 수 있다.
4.2. Confusion Matrix
- Confusion Matrix(혼동 행렬) 은 머신러닝의 분류 모델의 성능을 평가하는 데 사용되는 행렬 형태의 표이다. 모델이 실제 클래스와 예측한 클래스 간의 관계를 정리하여, 정확도뿐만 아니라 오류 유형(즉, 오분류 패턴)을 파악할 수 있도록 도와준다.
4.2.1. Confusion Matrix 구조
Confusion Matrix는 다음과 같은 2×2 행렬로 구성된다. (이진 분류 기준)
| 실제 \ 예측 | Positive(1) 예측 | Negative(0) 예측 |
|---|---|---|
| Positive(1) 실제 | True Positive (TP) | False Negative (FN) |
| Negative(0) 실제 | False Positive (FP) | True Negative (TN) |
각 용어의 의미는 다음과 같다.
- True Positive (TP): 실제 값이 Positive(1) 이고, 모델도 Positive(1)으로 예측한 경우 (정답을 맞춤).
- False Negative (FN): 실제 값이 Positive(1) 인데, 모델이 Negative(0)으로 예측한 경우 (실제 Positive를 놓침).
- False Positive (FP): 실제 값이 Negative(0) 인데, 모델이 Positive(1)으로 예측한 경우 (잘못된 Positive 경보 발생).
- True Negative (TN): 실제 값이 Negative(0) 이고, 모델도 Negative(0)으로 예측한 경우 (정답을 맞춤).
4.2.2. Confusion Matrix를 활용한 주요 평가 지표
- ✔ Accuracy (정확도)
전체 샘플 중에서 정확하게 예측한 비율을 의미한다.
하지만 클래스 불균형(Class Imbalance)이 있는 경우에는 정확도만으로 모델 성능을 평가하는 것은 적절하지 않음.
- ✔ Precision (정밀도)
모델이 Positive(1)으로 예측한 것 중에서 실제로 Positive(1)인 비율을 의미한다.
Precision이 높은 경우, False Positive (FP) 가 적다는 것을 의미하므로, 잘못된 Positive 예측을 줄이는 것이 중요한 경우에 유용하다. (예: 스팸 필터링)
- ✔ Recall (재현율, 민감도)
실제 Positive(1)인 데이터 중에서 모델이 Positive(1)으로 올바르게 예측한 비율을 의미한다.
Recall이 높은 경우, *alse Negative (FN) 가 적다는 것을 의미하므로, 놓치는 경우(False Negative)를 줄이는 것이 중요한 경우에 유용하다. (예: 암 진단 모델)
- ✔ F1 Score (조화 평균)
Precision과 Recall의 균형을 맞추기 위한 조화 평균(Harmonic Mean) 값이다.
F1 Score가 높은 경우, Precision과 Recall이 적절히 균형을 이루고 있음을 의미한다.
4.2.3 AUROC
- 알고리즘을 비교할 때, cut-off에 영향을 받을 수 있기때는에 이때는 다른 평가방식이 필요하게 된다. cut-off에 독립적인 평가방식인 AUROC를 알아보자.
AUROC (Area Under ROC Curve)란?
-> AUROC는 ROC(Receiver Operating Characteristic) 곡선 아래 면적(AUC)을 계산하여 모델의 성능을 평가하는 방법이다. ROC 곡선은 True Positive Rate (TPR, Recall)과 False Positive Rate (FPR)의 관계를 나타낸 그래프이며, cut-off 값을 다양하게 조정하면서 모델의 분류 성능을 평가할 수 있도록 한다.
- True Positive Rate (TPR, 재현율) =
- False Positive Rate (FPR) =
ROC 곡선은 FPR을 x축, TPR을 y축으로 하여 여러 cut-off 값에서의 성능 변화를 나타낸다. AUROC는 이 ROC 곡선 아래 면적을 계산한 값으로, 값이 1에 가까울수록 모델의 성능이 좋음을 의미한다. 일반적으로는 0.5보다 크고 1보다는 작게 나타나며, 1에 가까울수록 좋은 모델이라고 얘기한다.
AUROC의 해석
- AUROC = 1: 완벽한 모델 (모든 Positive와 Negative를 정확하게 분류)
- AUROC = 0.5: 랜덤 모델 (동전을 던지는 것과 동일한 성능)
- AUROC < 0.5: 잘못된 모델 (예측이 오히려 정반대로 작동)
일반적으로 AUROC가 0.8 이상이면 좋은 모델로 간주되며, 0.9 이상이면 매우 우수한 성능을 가진다고 평가한다.
5. Reference
[1] Korea University - Multivariate Data Analysis 03_part_1 ~ 03_part_4
- https://www.youtube.com/watch?v=PsVyx6erzrU&list=PLetSlH8YjIfWKLpMp-r6enJvnk6L93wz2&index=9
- https://www.youtube.com/watch?v=vGMMulhLoYE&list=PLetSlH8YjIfWKLpMp-r6enJvnk6L93wz2&index=10
- https://www.youtube.com/watch?v=3sZx4O2aQs8&list=PLetSlH8YjIfWKLpMp-r6enJvnk6L93wz2&index=11
- https://www.youtube.com/watch?v=fhaXt0llHG4&list=PLetSlH8YjIfWKLpMp-r6enJvnk6L93wz2&index=12
[2] 로지스틱 회귀 이름 유래
[3] AUROC, AUC-ROC 이해하기
