[Class Review](MDA_강필성) 4. Dimensionality Reduction

- 본 글은 서울대학교 산업공학과 DSBA 연구실 강필성 교수님의 "다변량데이터분석" 학부강의의 review 입니다.
1. Dimensionality Reduction
1.1. Overview of Data Analytics Process
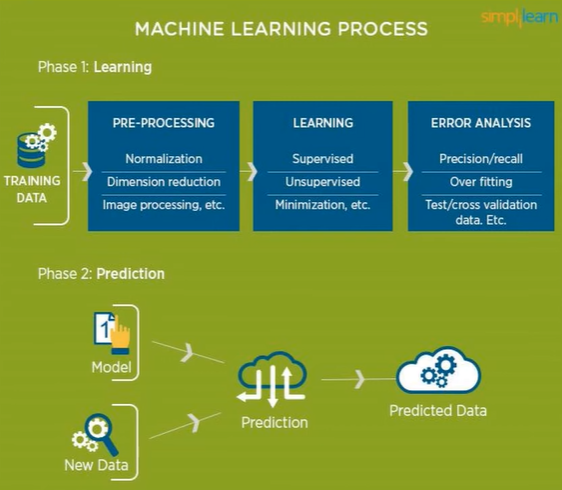
(데이터 분석의 과정: Pre-Processing -> Learning -> Error Analysis)
머신러닝이나 데이터 분석을 통한 Analytics Process를 보면 우선 데이터 확보가 이루어져야 한다. 그 데이터를 확보한 다음에는 전처리(Pre-Processing)이 수행된다.
이 전처리라는 것은 데이터에 어떤 Outlier는 없는지, 혹은 이상치나 에러가 존재하지는 않는지 확인하는 과정을 통해서 머신 러닝 알고리즘들이 잘 학습될 수 있도록 하는 여러가지 의미의 기초작업들을 의미한다. 그 중 가장 대표적인 것이 바로 차원축소(Dimension Reduction)이다.
우리가 의 총 d차원의 데이터가 존재한다고 가정할 때, 차원의 개수가 너무 많아서 알고리즘의 학습이 잘 안되는 등의 경우가 발생할 수 있다. 이 때, 우리가 원하는 task에 대한 모델의 성능은 저하시키지 않으면서, 적당한 size로 차원을 줄이는 작업을 수행하는 것이 유리하다. 즉, 모델링의 효율성을 추구하는 것이 차원축소의 궁극적인 목적이라고 할 수 있다.
신문 기사 분류 및 분석, OTT서비스에서의 영상추천 서비스, 유전체 분석 등의 다양한 task에서 수십만 수백만개의 차원이 존재할 수 있다. (왜냐하면 가능한 언어의 조합이나 영상의 특징들은 무한하다고 해도 과언이 아니기 때문이다.)
우리는 이러한 차원들을 하나하나 전부 분석할 수 없기 때문에, 차원축소는 데이터 분석 과정에서 필수적인 과정이다.
1.2. High-dimensional data and Curse of Dimensionality
1.2.1. Curse of Dimensionality
- 변수 차원이 선형적으로 1씩 증가하더라도, 낮은 차원과 동일한 정보량을 유지하려면 필요한 샘플의 수는 기하급수적으로 증가하게 된다.
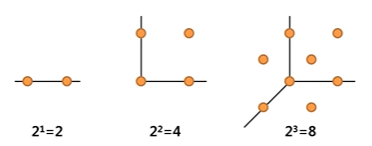
- 1차원에서는 수직선 상에 점이 두개만 있어도 거리 '1'이 보존되지만, 2차원 상에서는 거리 '1'이라는 정보를 보존하기 위해서는 정사각형의 네 꼭짓점이 전부 필요하다. 일반적으로 n차원에서는 개의 점이 필요하다. 따라서 높은 차원에서는 필요 샘플 수의 부족이나, 노이즈가 크게 증가하는 등의 문제가 필연적으로 발생하게 된다.
1.2.2. Simplest is The Best
"If there are various logical ways to explain a certain phenomenon, the simplest is the best." - Occam's Razor
- 오컴의 면도날(Occam's Razor)은 14세기 철학자 윌리엄 오컴(William of Ockham)이 제안한 원칙으로, 불필요한 가정을 제거하고 가장 단순한 설명을 선택해야 한다는 철학적 개념이다.
불필요한 가정이 많을수록 오류가 발생할 가능성이 크다. 같은 현상을 설명할 수 있는 여러 이론이 존재한다면, 가장 단순한 이론이 가장 신뢰할 만하다. 즉, 설명을 단순화하되, 핵심적인 내용을 유지하는 것이 중요하다.
이는 데이터 분석에도 적용되는데, 변수가 늘어날수록 노이즈나 변수간의 상호 상관관계 문제로 인해서 모델 예측 성능이 오히려 떨어지기도하고, 또 모델 예측 성능이 올라가긴 하지만 로그함수 그래프로 증가할 경우 input 대비(변수 증가 비용 대비) 유의미한 모델 성능의 향상이 없을 수 있다. 실제 데이터에서는 변수들이 독립적이지 않을 가능성이 크므로, 단순히 변수를 늘리는 것만으로 무조건 성능이 좋아지지 않는다는 것이다!
예시: MNIST 데이터
- 28×28(혹은 16×16) 손글씨 숫자 이미지는 256~784차원(픽셀 수)으로 표현 가능하다. 하지만, 실제로는 2차원 혹은 3차원 정도로 축소하더라도(예: PCA, Isomap 등) 어느 정도 숫자들 간 분류가 가능하다.
-> 이는 데이터에 내재된 “본질적 차원(intrinsic dimension)”이 실제 차원보다 훨씬 낮을 수 있음을 시사한다.

1.2.3. Supervised VS. Unsuperviesed
-
Supervised 차원 축소
- 레이블(타겟 값, Y)을 사용하여 유용한 피처(Feature)를 선택하는 방식이다.
- 즉, 출력값(Y)과 상관성이 높은 특성만 남기고 나머지는 제거한다.
- 지도학습 알고리즘이 학습할 때 보다 중요한 정보만 사용하도록 피처를 최적화환다. Feed back이 존재한다는 것을 명심하자.
-
Unsupervised 차원 축소
- 레이블(정답 데이터) 없이 데이터의 내재된 구조를 기반으로 차원을 축소하는 방식이다.
- 중간의 알고리즘의 개입 없이 one way로 차원 축소가 일어난다.
- 대표적인 기법: PCA(주성분 분석), t-SNE, Autoencoder 등.
2. Variable Selection Methods
2.1. Overview
차원 축소(Dimensionality Reduction)에서 변수 선택(Variable Selection) 은 모델의 성능을 향상시키고 해석 가능성을 높이는 중요한 과정이다.
변수 선택의 목적은 불필요한 변수를 제거하고, 예측력이 높은 변수만 남기는 것이다. 아래에서 가장 대표적인 방법들을 살펴보도록 하겠다.
2.2. Selection Methods
2.2.1. Exhaustive Search (전역 탐색)
Exhaustive Search는 모든 가능한 변수 조합을 테스트하여 최적의 변수 집합을 찾는 방법이다. 즉, 가능한 모든 조합을 고려하기 때문에 가장 정확한 결과를 제공하지만, 계산 비용이 매우 크다는 단점이 존재한다. 그리고 현실세계의 데이터셋의 경우에는 "단순히 계산하기 어렵고 계산에 비용이 많이 든다" 정도로 끝나지 않고 상상을 초월하는 차원개수를 자랑하기에 전역 탐색이 메인으로 쓰이는 경우는 거의 없다.
- 예제: 3개의 변수 가 있을 때, 가능한 부분집합:
- 장점: 최적의 변수 조합을 보장함.
- 단점: 변수 개수가 많아질수록 연산량이 기하급수적으로 증가함.
최적 변수 조합을 평가할 때는 AIC(Akaike Information Criteria), BIC(Bayesian Information Criteria), Adjusted 등을 활용한다.
2.2.2 Forward Selection (전진 선택)
Forward Selection은 처음에는 변수가 없는 모델에서 시작하여, 가장 유의미한 변수를 하나씩 추가하는 방식이다. 이 과정에서 변수 추가는 모델의 성능이 가장 개선되는 순서대로 이루어진다.
-
과정:
- 모든 변수를 제외한 상태에서 시작.
- 가장 영향력이 큰 변수 를 추가.
- 추가된 변수와 기존 변수를 함께 고려하면서, 가장 좋은 조합을 찾아 추가.
- 더 이상 성능이 개선되지 않을 때까지 반복.
-
특징:
- 한 번 선택된 변수는 제거되지 않음.
- 변수 개수가 적을수록 연산이 효율적.
- 중요한 변수를 빠르게 찾아낼 수 있음.
-
단점:
- 한 번 선택된 변수가 잘못된 선택일 경우, 이후 과정에서 수정할 방법이 없음.
- 최적의 변수 조합을 항상 보장하지는 않음.
2.2.3. Backward Elimination (후진 제거)
Backward Elimination은 처음에는 모든 변수를 포함한 모델에서 시작하여, 중요도가 낮은 변수를 하나씩 제거하는 방식이다.
-
과정:
- 모든 변수를 포함한 상태에서 시작.
- 가장 영향력이 적은 변수부터 하나씩 제거.
- 변수 제거 후, 모델 성능을 평가.
- 성능이 크게 저하되지 않는 한, 변수를 계속 제거.
-
특징:
- 한 번 제거된 변수는 다시 추가되지 않음.
- 처음부터 많은 변수를 사용하므로, 연산량이 많음.
- 모든 변수를 고려한 상태에서 시작하기 때문에, 더 정확한 변수 선택이 가능.
-
단점:
- 처음부터 모든 변수를 포함해야 하므로 계산량이 많음.
- 불필요한 변수가 많을 경우, 제거하는 데 시간이 오래 걸릴 수 있음.
2.2.4. Stepwise Selection (단계적 변수 선택)
Stepwise Selection은 Forward Selection과 Backward Elimination을 결합한 방법이다. 즉, 변수를 추가하는 동시에 불필요한 변수를 제거하여 가장 적절한 변수 조합을 찾는다.
-
과정:
- Forward Selection 방식으로 변수를 추가.
- 각 단계에서 추가된 변수가 유의미한지 평가하고, 필요 없는 경우 제거 (Backward Elimination 수행).
- 이 과정을 반복하여 최적의 변수 조합을 찾음.
-
특징:
- Forward Selection처럼 변수를 추가하지만, 필요 없는 변수는 제거될 수 있음.
- Backward Elimination처럼 변수를 제거하지만, 유용한 변수는 다시 추가될 수 있음.
- 변수 선택 과정에서 유연성이 높아 최적의 변수 조합을 찾을 가능성이 높음.
-
단점:
- Forward Selection이나 Backward Elimination보다 연산량이 많음.
- 과정이 복잡하여 모델 해석이 어려울 수 있음.
2.2.5. Comparison of Selection Methods
변수 선택 기법을 비교하면 다음과 같다.
| 기법 | 시작점 | 변수 추가 | 변수 제거 | 연산량 | 최적의 변수 조합 가능성 |
|---|---|---|---|---|---|
| Exhaustive Search | 모든 조합 탐색 | - | - | 매우 큼 | 높음 (최적 보장) |
| Forward Selection | 빈 모델 | O | X | 적음 | 중간 |
| Backward Elimination | 전체 변수 포함 | X | O | 많음 | 높음 |
| Stepwise Selection | 빈 모델 | O | O | 중간 | 높음 |
Exhaustive Search 는 연산량이 많지만 최적의 변수를 찾을 수 있는 반면,
Forward Selection과 Backward Elimination 은 계산 효율성이 높지만 최적의 변수를 보장하지 않을 수 있다.
Stepwise Selection 은 두 방법을 결합하여 유연성을 제공한다.
2.3. Performance Metrics
변수 선택 기법을 평가할 때는 모델의 성능을 객관적으로 측정할 수 있는 평가지표가 필요하다.
주로 사용되는 평가 방법으로 앞서 언급했듯, Akaike Information Criteria (AIC), Bayesian Information Criteria (BIC), Adjusted 등이 있다.
AIC정도만 알아도 괜찮다고 하셨지만, 나머지도 가볍게 정리하고 넘어가고자 한다.
Akaike Information Criteria (AIC)
-> AIC는 모델의 적합도(Fit)와 복잡도(Complexity) 사이의 균형을 평가하는 지표이다.
-
수식
- : 데이터 샘플 수
- : 오차 제곱합 (Sum of Squared Error)
- : 변수 개수 (모델의 복잡도)
-
해석
- (오차)가 작을수록 좋은 모델이지만, 변수 수 가 많아지면 과적합 위험이 있음.
- 따라서, SSE가 작으면서도 변수 수가 적은 모델을 선호하도록 패널티()를 부여한다.
- 즉, AIC 값이 낮을수록 더 좋은 모델이라고 해석 가능하다.
Bayesian Information Criteria (BIC)
BIC도 AIC와 유사한 방식으로 모델을 평가하지만, 패널티 항을 다르게 설정하여 더 강한 모델 선택 기준을 적용한다.
-
수식
-
AIC와 BIC의 차이
- AIC는 모델의 예측 성능을 최적화하는 방향으로 작동.
- BIC는 더 강한 패널티를 부여하여 단순한 모델을 더 선호하는 경향이 있음.
- 데이터 샘플 수가 많아질수록 BIC가 더 강력한 기준이 됨.
Adjusted
기본적인 는 모델이 데이터를 얼마나 잘 설명하는지를 나타내는 지표지만, 변수 개수가 많아질수록 자연스럽게 증가하는 특성이 있다.
이를 보정하기 위해 Adjusted 를 사용한다.
-
수식
- : 데이터 샘플 수
- : 독립 변수 개수
- : 오차 제곱합
- : 총 변동량
-
해석
- 변수 수 를 고려하여 불필요한 변수가 추가될 경우, Adjusted 가 증가하지 않도록 보정한다.
- 단순한 보다 변수가 증가하는 효과를 반영하여 모델을 평가하는 데 적절한 기준이 된다.
2.4. Genetic Algorithm (GA)
전통적인 변수 선택 방법(Exhaustive Search, Forward Selection, Backward Elimination 등)은 검색 공간이 제한적이거나 연산량이 많아지는 문제가 있다. 이를 해결하기 위해 유전 알고리즘(Genetic Algorithm, GA) 을 활용할 수 있다.
2.4.1. GA Step 1: Initialization
유전 알고리즘은 생물학적 진화의 원리를 모방한 최적화 알고리즘이다.
- 초기 단계에서 랜덤한 변수 조합(Chromosome, 염색체)을 생성하여 검색을 시작한다.
- 염색체는 0과 1로 표현되며, 1이면 선택된 변수, 0이면 제외된 변수를 의미한다.
2.4.2. GA Step 2: Model training
- 각 염색체에 대해 모델을 학습하여 성능을 평가한다.
- 일반적으로 회귀 분석, 머신러닝 모델 등을 사용하여 변수 조합의 적합도를 측정한다.
2.4.3. GA Step 3: Fitness Evaluation
- 각 염색체(변수 조합)의 성능을 평가하는 과정이다.
- 평가 기준은 AIC, BIC, Adjusted 등을 사용한다.
- 좋은 성능을 가진 개체(변수 조합)일수록 높은 적합도(Fitness Score)를 부여한다.
2.4.4. GA Step 4: Selection
- 적합도가 높은 개체를 다음 세대로 전달하기 위해 선택한다.
- 일반적으로 Roulette Wheel Selection, Tournament Selection 등의 방법을 활용한다.
- 높은 성능을 가진 개체일수록 선택될 확률이 높아진다.
2.4.5. GA Step 5: Crossover & Mutation
-
Crossover (교차 연산)
- 두 개의 개체(변수 조합)를 섞어 새로운 조합을 생성한다.
- 예를 들어, 부모 A와 부모 B의 변수 조합을 섞어 새로운 개체를 만든다.
-
Mutation (돌연변이 연산)
- 일부 변수를 랜덤하게 바꿔 탐색 공간을 확장한다.
- 기존 방법보다 로컬 최적해(Local Optimum)에 빠질 위험을 줄일 수 있다.
2.4.6. GA Step 6: Find the best solution
- 반복적인 세대 교체 과정을 통해 최적의 변수 조합을 찾는다.
- 특정 종료 조건(예: 세대 수, 성능 개선 여부 등)을 만족하면 알고리즘을 종료한다.
- 최종적으로 성능이 가장 높은 변수 조합을 선택하여 최적의 모델을 구축한다.
3. Shrinkage Methods
Shrinkage Methods는 모델의 회귀 계수(Regression Coefficients)를 축소(Shrinkage)하여 과적합(Overfitting)을 방지하고 모델을 정규화(Regularization)하는 방법이다.
이러한 방법들은 특히 변수 선택(Feature Selection)과 예측 성능 개선을 동시에 고려할 수 있다.
3.1. Ridge Regression
Ridge Regression은 L2 정규화(L2 Norm Regularization)를 적용한 회귀 분석 기법이다. 모델의 복잡도를 줄이기 위해 회귀 계수(β)의 크기를 제어한다.
-
목적: 과적합 방지, 다중공선성(Multicollinearity) 해결
-
추가적인 L2 패널티:
- : 정규화 강도를 조절하는 하이퍼파라미터
- : 회귀 계수의 제곱합
-
Ridge Linear Regression 수식
-
Ridge Logistic Regression 수식
- 회귀 계수의 크기를 제한하므로 다중공선성을 줄일 수 있음
- 하지만, 모든 계수를 0에 가깝게 줄이는 특성이 있어 변수 선택(Feature Selection)에는 적합하지 않음
- 변수 간 상관관계(Correlation)가 높은 경우에도 효과적으로 작동한다
3.2. LASSO (Least Absolute Shrinkage and Selection Operator)
LASSO는 L1 정규화(L1 Norm Regularization)를 적용하여 일부 회귀 계수를 정확히 0으로 만드는 특성을 가진다. 즉, Ridge와 달리 변수 선택(Feature Selection) 기능을 수행할 수 있다.
-
추가적인 L1 패널티:
- 절대값(Absolute Value)을 사용하여 계수를 직접적으로 감소시킴.
-
LASSO Linear Regression 수식
- LASSO Logistic Regression 수식
- 불필요한 변수를 정확히 0으로 만들어 변수 선택 기능 수행이 가능하다
- Ridge와 달리 특정 변수를 완전히 제거할 수 있다 → 모델 해석에 용이하다.
- 변수 간 상관관계가 높을 경우, 특정 변수만 선택하는 경향이 있다 → 즉, 중요한 변수를 놓칠 가능성이 있다는 것이다.
3.3. Elastic Net
개념
Elastic Net은 Ridge와 LASSO의 장점을 결합한 방법으로,
L1과 L2 정규화를 동시에 적용하여 변수 선택과 다중공선성 문제를 동시에 해결한다.
-
추가적인 패널티 (L1 + L2 Regularization)
- : LASSO 효과 조절
- : Ridge 효과 조절
-
Elastic Net Linear Regression 수식
- Elastic Net Logistic Regression 수식
- LASSO처럼 변수 선택 기능을 가지면서도, Ridge처럼 다중공선성을 완화할 수 있음
- LASSO의 단점(변수 간 상관관계가 높을 때 특정 변수만 선택하는 문제)을 해결할 수 있음
- Ridge와 LASSO의 조합이므로, 두 개의 하이퍼파라미터 ( \lambda_1 ) 과 ( \lambda_2 ) 를 조정해야 함
3.4. Shrinkage Motheds 비교 및 선택 방법
| Method | Regularization | Feature Selection | 다중공선성 해결 | 주요 특징 |
|---|---|---|---|---|
| Ridge | L2 | X | O | 모든 변수 사용, 회귀 계수 축소 |
| LASSO | L1 | O | X | 불필요한 변수를 0으로 만들어 선택 기능 수행 |
| Elastic Net | L1 + L2 | O | O | LASSO와 Ridge의 장점을 결합 |
- 변수가 많고 다중공선성이 강하면 Ridge
- 변수 선택이 필요하면 LASSO
- 둘 다 고려해야 하면 Elastic Net
4. Reference
[1] Korea University - Multivariate Data Analysis 04_part_1 ~ 04_part_3
- https://www.youtube.com/watch?v=2aTdOGJg7ys&list=PLetSlH8YjIfWKLpMp-r6enJvnk6L93wz2&index=15
- https://www.youtube.com/watch?v=sknO5ygAZ4Q&list=PLetSlH8YjIfWKLpMp-r6enJvnk6L93wz2&index=16
- https://www.youtube.com/watch?v=sknO5ygAZ4Q&list=PLetSlH8YjIfWKLpMp-r6enJvnk6L93wz2&index=16
[2] L1 Regularization & L2 Regularization
