[Class Review](MDA_강필성) 7-1. Ensemble Learning-1

- 본 글은 서울대학교 산업공학과 DSBA 연구실 강필성 교수님의 "다변량데이터분석" 학부강의의 review이다.
1. Overview of Ensemble Learning
앙상블 학습(Ensemble Learning)은 여러 개의 모델을 결합하여 단일 모델보다 더 좋은 예측 성능을 내는 기법이다. 앙상블이 필요한 이유와 이를 뒷받침하는 이론을 심층적으로 살펴보고, 오류를 줄이는 관점에서 앙상블의 역할을 수학적으로 분석한다.
1.1. Why Ensemble is Needed?
1.1.1. 공짜 점심은 없다
No Free Lunch Theorem(NFLT, 공짜 점심 정리)에 따르면, 어떤 단일한 학습 알고리즘이 모든 문제에서 항상 최적의 성능을 보일 수는 없다. 즉, 특정 데이터셋에서는 선형 회귀가 최적일 수 있지만, 다른 데이터셋에서는 랜덤 포레스트나 신경망이 더 나을 수 있다.
- 이는 모델의 편향(Bias)과 분산(Variance)이 트레이드오프 관계에 있기 때문이다.
- 하나의 모델은 어떤 문제에서는 강력하지만, 특정한 경우에는 성능이 저하될 수 있다.
- 따라서 여러 개의 서로 다른 모델을 결합하면 서로의 약점을 보완할 가능성이 높아진다.
예제: 모델의 강점과 약점
| 알고리즘 | 장점 | 단점 |
|---|---|---|
| 선형 회귀(Linear Regression) | 해석이 용이하고 계산이 빠름 | 비선형 관계를 학습하지 못함 |
| 결정 트리(Decision Tree) | 데이터 구조를 직관적으로 표현 가능 | 과적합(overfitting) 가능성이 높음 |
| 랜덤 포레스트(Random Forest) | 결정 트리보다 일반화 성능이 뛰어남 | 계산량이 많음 |
| 신경망(Neural Networks) | 복잡한 패턴 학습 가능 | 많은 데이터와 연산이 필요 |
따라서 여러 모델을 조합하여 앙상블을 구성하면 개별 모델의 단점을 보완하고, 더 강력한 성능을 기대할 수 있다.
1.1.2. Experimental Case
여러 연구에서 앙상블 기법이 단일 모델보다 우월한 성능을 보인다는 점이 밝혀졌다.
- Dietterich (2000): 앙상블이 단일 모델보다 일반적으로 오류율이 낮음을 증명.
- Caruana et al. (2006): 179개 알고리즘을 비교한 연구에서, 랜덤 포레스트, 부스팅, 배깅과 같은 앙상블 방법이 상위권을 차지함.
- 넷플릭스(Netflix) 추천 시스템 대회 (2009): 우승팀이 사용한 기법은 다양한 모델을 결합한 앙상블 방법이었으며, 단일 모델보다 월등한 성능을 보임.
- 이미지넷(ImageNet) 챌린지 (2014): 딥러닝 기반의 앙상블 모델이 우승.
결론적으로, 실제 데이터 분석과 머신러닝 대회에서도 앙상블 기법이 단일 모델보다 더 높은 성능을 보이는 경향이 있다.
1.1.3. Principle that Ensembles work well
앙상블이 좋은 성능을 내기 위해서는 다음 세 가지 조건이 필요하다.
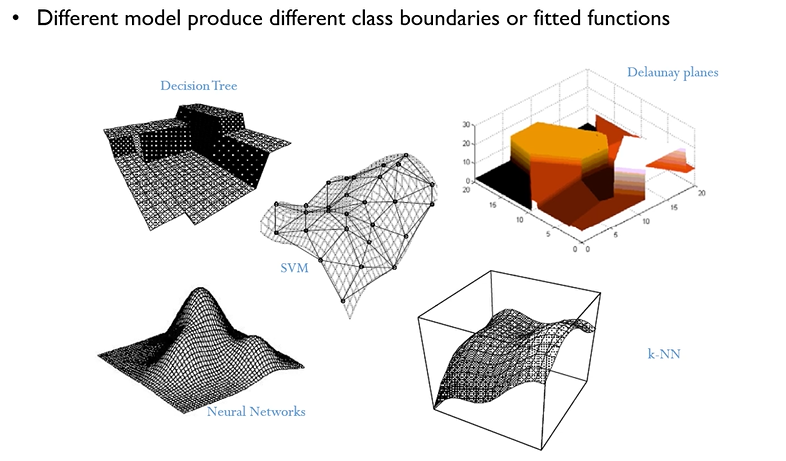
똑같은 데이터를 가지고도 각각의 알고리즘이 정답을 찾아가는 과정은 전부 다르다!
-
다양성(Diversity)
- 여러 모델이 서로 다른 방식으로 예측해야 한다.
- 동일한 데이터셋에서 훈련된 완전히 동일한 모델을 조합하면 의미가 없다.
- 데이터 샘플링을 달리하거나, 서로 다른 알고리즘을 사용할 필요가 있다.
- 각자가 가진 단점을 상쇄할 수 있다는 뜻이다.
-
개별 모델의 기본 성능
- 모델이 일정 수준 이상의 예측력을 가져야 한다.
- 모든 모델이 랜덤 예측(50%) 수준이라면 앙상블을 해도 개선 효과가 없다.
-
결합(Aggregation) 방식
- 분류 문제에서는 다수결 투표(Majority Voting), 확률 평균(weighted sum) 등을 사용할 수 있다.
- 회귀 문제에서는 평균(Mean), 가중 평균(Weighted Mean) 등이 효과적이다.
이 세 가지 요소가 충족되면, 단일 모델보다 더 강력한 앙상블 모델을 만들 수 있다.
1.2. 오류(E) 분해: Bias-Variance 관점
1.2.1. 오차의 분해 (Bias-Variance Decomposition)
모델의 예측 오류 는 다음과 같이 분해할 수 있다.
- Bias(편향): 모델이 평균적으로 실제 값에서 벗어난 정도. (단순한 모델일수록 편향이 높음)
- Variance(분산): 데이터 샘플링에 따라 모델이 얼마나 예측을 들쭉날쭉하게 하는지.
- Noise(노이즈): 본질적으로 제거할 수 없는 무작위 오차.
1.2.2. Bias-Variance Decomposition (바이어스-분산 분해)
Bias-Variance Decomposition은 모델의 예측 오차를 세 가지 주요 구성 요소인 Bias(편향), Variance(분산), 그리고 Irreducible Error(비감소 오류, (\sigma^2)) 로 분해하는 과정이다. 이를 통해 모델의 성능을 분석하고, 적절한 조정을 통해 일반화 성능(Generalization Performance) 을 향상시킬 수 있다.
1.2.2.1. 데이터 생성 과정과 기본 모델
(1) Additive Error Model
일반적으로 데이터를 다음과 같은 Additive Error Model로 가정한다.
- : 우리가 학습하고자 하는 진짜 함수 (Target Function)
- : 랜덤 노이즈로, 평균이 0이고 분산이 인 가우시안 분포를 따른다.
즉, 실제 관측값 는 진짜 함수 에 노이즈가 더해진 형태이다.
(2) 모델 학습 및 추정 과정
주어진 데이터셋을 이용하여 여러 개의 모델 을 학습할 수 있다. 가령, 개의 서로 다른 데이터셋이 있을 경우, 각각에 대해 개별 모델 을 학습할 수 있다.
이때, 모든 데이터셋에서 평균적으로 학습된 모델을 다음과 같이 정의한다.
여기서 는 다양한 데이터셋 를 고려한 평균을 의미한다. 즉, 다양한 데이터셋을 통해 학습된 모델들의 평균적인 추정치이다.
1.2.2.2. 예측 오차(Error) 정의
일반적으로 Mean Squared Error (MSE, 평균 제곱 오차) 를 이용하여 모델의 예측 오류를 정의한다.
즉, 특정 입력 ( x_0 )에서의 예측 오차를 기대값으로 측정한다.
1.2.2.3. Bias-Variance 분해 과정
(1) 오류 표현을 변형
위의 식을 을 이용해 변형하면 다음과 같이 정리할 수 있다.
이를 다시 정리하면,
(2) 기대값의 성질을 이용한 분리
기대값의 성질을 활용하여 위의 식을 다시 전개하면,
여기서 이므로,
(3) Bias와 Variance로 분리
이제 모델의 편향(Bias)와 분산(Variance)을 구분하여 표현해보자.
위의 식에서 Bias와 Variance를 정의할 수 있다.
우리가 배우는 방법론들은 보통 여기서 두번째 아니면 세번째에 속하는 경우가 많다. 적절한 trade-off 조정과정이 필요한 것!
- Bias 정의
Bias는 평균적인 모델 예측 값 ( \bar{F}(x) )과 실제 함수 ( F^(x) ) 간의 차이로 정의된다.
즉, 모델이 진짜 함수와 얼마나 차이가 나는지를 나타내는 척도이다.- Variance 정의
Variance는 개별 모델 이 평균 모델 에서 얼마나 변동하는지를 의미한다.
즉, 데이터셋이 바뀔 때마다 모델이 얼마나 요동치는지를 나타낸다.
1.2.2.4. 최종 Bias-Variance Tradeoff
결과적으로 MSE를 Bias와 Variance로 표현하면,
이는 다음과 같은 의미를 가진다.
- Bias(편향): 모델이 본질적으로 진짜 함수 를 얼마나 잘 추정하는지.
- Variance(분산): 데이터 샘플이 바뀔 때마다 모델이 얼마나 민감하게 반응하는지.
- Irreducible Error(비감소 오류, ): 본질적인 노이즈로, 학습을 통해 줄일 수 없다.
1.2.2.5. Bias-Variance Tradeoff의 의미**
Bias와 Variance는 서로 반대 방향으로 작용하는 경향이 있다.
-
Bias가 높은 모델
- 단순한 모델 (예: 선형 회귀)일 경우, 진짜 함수 를 충분히 표현하지 못해 Bias가 크다.
- 일반적으로 학습 데이터와 관계없이 동일한 패턴을 유지하며, Underfitting이 발생할 가능성이 높다.
-
Variance가 높은 모델
- 복잡한 모델 (예: 딥러닝, 높은 차원의 다항식 회귀)일 경우, 데이터에 민감하게 반응하며 Variance가 크다.
- 학습 데이터에 지나치게 맞춰지는 Overfitting이 발생할 가능성이 높다.
이 때문에 Bias와 Variance 사이에서 최적의 균형점을 찾는 것이 중요하다.
이때, 앙상블 기법은 Bias와 Variance를 조절하여 성능을 개선하는 역할을 한다.
- 배깅(Bagging, Random Forest 등): Variance(분산)를 줄이는 효과 → 모델이 안정적이 됨.
- 부스팅(Boosting, XGBoost 등): Bias(편향)를 줄이는 효과 → 강력한 예측 모델이 됨.
즉, 앙상블은 오류를 최소화하는 방향으로 동작한다.
1.3. 앙상블의 수학적 성질
앙상블은 다수의 독립적인 모델을 결합하면 평균적으로 개별 모델보다 성능이 좋아진다는 이론적 근거를 가진다.
가정:
- 개의 모델이 있고, 개별 모델의 평균 예측 오류가 라고 하자.
- 이 모델들을 단순 평균으로 결합하면 앙상블의 평균 오류는 가 된다.
즉, 모델 수가 증가할수록 오차가 줄어들게 된다.
하지만 모델이 서로 완전히 독립적이지 않다면 성능 향상은 제한적일 수 있다.
따라서 적절한 다양성을 유지하는 것이 중요하다.
1.4. 앙상블 구현 시 고려해야 할 요소

1.4.1. 개별 모델의 다양성 확보(매우중요)
앙상블을 효과적으로 만들려면 개별 모델이 서로 다르게 학습해야 한다.
-
데이터 샘플링 차별화:
- 부트스트래핑(Bootstrapping)을 이용해 모델마다 다른 데이터셋을 학습.
- 배깅(Bagging) 기법에서 활용됨.
-
모델 차별화:
- 서로 다른 알고리즘(예: 랜덤 포레스트 + 신경망 + SVM)을 조합.
- 서로 다른 하이퍼파라미터를 사용하여 다양성을 부여.
Q: 팀 10명이 모여서 퀴즈쇼 경연대회를 나간다고 했을 때, 당신은 어떻게 팀을 구성할 것인가?
1. 산업공학부 10명의 학생으로 팀을 짠다
2. 산업공학부, 경영학부, 생명공학부, 컴퓨터공학부, 역사학부,,, 등의 다양한 전공을 조합하여 팀을 짠다.
-> 하지만 무작정 다양성을 챙기기 이전에, 기본적으로 각 개별 모델의 성능이 일정 수준 이상의 성능을 확보되어야만 한다!
1.4.2. 결합(Aggregation) 방식
-
분류(Classification) 문제:
- 다수결 투표(Majority Voting)
- 확률 평균(Weighted Probability)
-
회귀(Regression) 문제:
- 단순 평균(Simple Mean)
- 가중 평균(Weighted Mean)
또한, 메타모델(Meta-model, Stacking)을 추가로 학습하여 각 모델의 예측을 조합하는 방식도 효과적이다.
2. Bagging: Reducing Variance
배깅(Bagging, Bootstrap Aggregating)은 앙상블 학습 기법 중 하나로, 분산(Variance) 감소에 초점을 맞춘 대표적인 방법이다. 특히 개별 모델이 고분산 특성을 가지는 경우(신경망 등) 배깅을 활용하면 과적합을 줄이면서도 예측력을 높일 수 있다.
2.1. Bagging의 목표
배깅의 목표는 동일한 모델을 여러 개 학습한 후, 그 결과를 결합(aggregation)하여 개별 모델보다 더 강건한(robust) 예측 모델을 구축하는 것이다. 이때 앞서 설명했듯 적절한 다양성도 갖춰야하는 동시에, 성능을 보장할 수 있는 모델들을 확보하기 위해, 양질의 데이터셋을 사용해야만 한다.
이를 위해 아래와 같은 순서대로 배깅을 진행한다.
2.1.1. 부트스트랩(Bootstrap) 데이터 구성
배깅의 첫 번째 단계는 원본 데이터에서 부트스트랩 샘플을 생성하는 것이다. 부트스트랩 샘플링은 복원추출 방식으로 이루어지며, 다음과 같은 특징이 있다.
- 원본 데이터셋의 크기가 일 때, 동일한 크기 의 샘플을 복원추출하여 새로운 데이터셋을 만든다.
- 같은 데이터가 여러 번 중복 포함될 수도 있으며, 일부 데이터는 선택되지 않을 수도 있다.
- 이 과정을 번 반복하여, 서로 다른(하지만 중복을 포함하는) 부트스트랩 샘플 을 생성한다.
📌 복원추출의 직관적 이해
주어진 원본 데이터셋 에서, 각각의 샘플이 부트스트랩 샘플에 선택될 확률은 다음과 같다.
- 각 데이터 포인트는 총 번 샘플링이 수행되는 동안 매번 선택될 확률이 이다.
- 따라서 특정 데이터 포인트가 한 번도 선택되지 않을 확률은
- 일 때, 이 값은 대략 에 수렴한다.
- 즉, 원본 데이터의 약 36.8%는 부트스트랩 샘플에 포함되지 않고 제외된다.
복원추출을 이용하여 Dataset을 구성하는 것이, 단순히 하나씩 block을 배제하며 Dataset을 구성하는 방식보다 훨씬 더 다양성을 담보할 수 있기에 주로 사용된다.
2.1.2. 개별 모델 학습
부트스트랩 샘플을 생성한 후, 각 샘플을 이용하여 베이스 모델(base model) 을 학습한다.
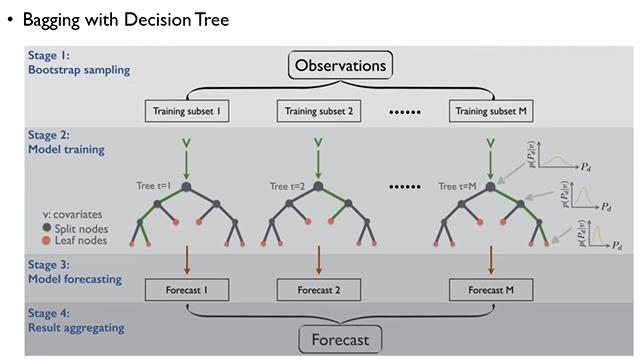
의사결정나무를 베이스 모델로 사용했을 경우
- 일반적으로 의사결정나무를 베이스 모델로 많이 사용하지만, 다른 알고리즘(SVM, 신경망 등)에도 적용 가능하다.
- 결과적으로 개의 서로 다른 모델 이 학습되며, 각각의 모델은 약간씩 다른 데이터로 학습되므로 서로 독립적인 예측을 수행할 가능성이 높아지는 것이다.
2.1.3. 결합(Aggregation) 방식
배깅(Bagging)은 여러 개의 개별 모델을 학습한 후, 최종적으로 이를 결합(aggregation)하여 최종 예측값을 산출하는 방식이다. 개별 모델들의 예측을 결합하는 방식은 문제의 특성(분류 or 회귀)에 따라 다르게 적용된다.
2.1.3.1. 분류(Classification) 문제에서의 결합 방식
배깅을 활용한 분류 문제에서는 다수결(Majority Voting) 혹은 가중 투표(Weighted Voting) 를 사용한다.
1) 다수결(Majority Voting)
- 개별 모델들이 예측한 클래스 중에서 가장 많이 선택된 클래스를 최종 예측값으로 결정한다.
- 개별 모델이 서로 다른 부트스트랩 샘플을 기반으로 학습되었기 때문에, 독립적인 모델들이 서로 다른 판단을 내릴 가능성이 존재한다.
- 최종 예측은 다수의 모델이 일치하는 결과를 선택함으로써 분산을 줄이는 역할을 한다.
수식으로 표현하면,
여기서
- 는 모델 가 클래스 를 예측했을 경우 1, 그렇지 않으면 0을 반환하는 지표이다.
- 즉, 각 클래스에 대한 투표 수를 계산한 후, 가장 많은 투표를 받은 클래스를 최종 예측값으로 결정하는 것이다.
2) 가중 투표(Weighted Voting)
단순 다수결 방식 대신, 각 모델의 신뢰도를 반영한 가중치(weight)를 부여하여 예측값을 결합하는 방식이다.
- 가중치는 일반적으로 모델의 훈련 정확도(Training Accuracy) 또는 검증 정확도(Validation Accuracy) 에 기반하여 설정된다.
- 훈련 정확도가 높은 모델일수록 더 높은 가중치를 부여하며, 이는 약한 모델들의 영향을 줄여준다.
수식으로 표현하면,
여기서
-
는 모델 의 훈련 정확도
-
가중치를 적용한 예측값을 계산한 후, 가장 높은 값을 가지는 클래스를 선택한다.
-
훈련 정확도가 높은 모델일수록 더 높은 가중치를 가지며, 최종적으로 가중된 투표 결과가 1에 가까운 경우, 클래스 1이 선택되었다.
2.1.3.2. 회귀(Regression) 문제에서의 결합 방식
회귀 문제에서는 개별 모델의 예측값을 단순 평균(Averaging) 하거나 가중 평균(Weighted Averaging) 하여 최종 결과를 산출한다.
1) 단순 평균(Averaging)
- 개별 모델이 출력한 값들의 평균을 계산하여 최종 예측값으로 설정한다.
- 개별 모델의 편향이 크더라도, 모델이 다양성을 가진다면 분산을 줄여 일반화 성능을 향상시킬 수 있다.
수식으로 표현하면,
여기서
- 는 모델 의 예측값이다.
2) 가중 평균(Weighted Averaging)
- 개별 모델의 예측값을 신뢰도(예: 훈련 정확도, 모델의 성능)에 따라 가중치를 부여하여 평균을 계산하는 방식이다.
- 신뢰도가 높은 모델일수록 더 큰 가중치를 부여하여 최종 예측을 결정한다.
수식으로 표현하면,
여기서
- 는 모델 의 신뢰도를 나타내는 가중치이며, 일반적으로 훈련 정확도 혹은 검증 정확도를 기준으로 설정한다.
2.1.3.3. 확률 기반 결합(Probability-based Aggregation)
분류 문제에서 각 모델이 예측한 클래스 확률을 기반으로 결합하는 방식이다.
- 각 모델이 특정 클래스 를 예측할 확률을 출력할 수 있는 경우, 개별 모델들의 확률 평균을 계산하여 가장 높은 확률을 갖는 클래스를 최종 예측값으로 선택한다.
2.1.3.4. 스태킹(Stacking)
스태킹(Stacking)은 개별 모델들의 예측값을 또 다른 메타 모델(meta-model) 에 입력하여 최종 예측을 수행하는 방식이다.
- 개별 모델들이 서로 다른 패턴을 학습할 수 있도록 설계되며, 최종적으로 메타 모델이 이러한 예측값들을 결합하여 더욱 정밀한 예측을 수행한다.
각 개별 모델의 예측값이 메타 분류기(meta-classifier)에 입력되어 최종적으로 가 결정된다.
2.2. Out-of-Bag(OOB) 에러 추정
배깅을 사용할 때 모델 성능을 평가하는 일반적인 방법 중 하나가 OOB(Out-of-Bag) 에러 추정이다.
- 부트스트랩 샘플링(복원추출) 방식으로 인해, 전체 훈련 데이터 중 일부 샘플(약 63.2%)만이 특정 모델의 학습 데이터에 포함된다.
- 나머지 36.8%의 샘플은 해당 모델의 학습에 사용되지 않으며, 이를 OOB 데이터라고 한다.
- 각 모델이 자신의 OOB 데이터를 사용하여 검증을 수행할 수 있으며, 이를 통해 별도의 검증 데이터셋 없이도 모델의 성능을 추정할 수 있다.
<계산방식>
1. 각 개별 모델이 훈련되지 않은 OOB 샘플에 대해 예측값을 출력한다.
2. 모든 모델의 OOB 예측을 취합하여 최종 예측값을 결정한다.
3. OOB 데이터의 실제 정답과 비교하여 오류율을 계산한다.
수식으로 표현하면,
이다.
2.3. 배깅의 장점과 단점
2.3.1. 배깅(Bagging)의 장점
✔ 고분산 모델의 분산을 감소시킨다
- 배깅은 원래 고분산(high variance) 모델을 안정적으로 만드는 기법이다.
- 개별 모델이 약간씩 다른 데이터로 학습되므로, 모델이 과적합(overfitting)될 위험이 줄어든다.
- 따라서 의사결정나무(Decision Tree)처럼 과적합 위험이 큰 모델과 궁합이 좋다.
✔ 데이터 노이즈에 강하다
- 개별 모델이 일부 노이즈 데이터에 영향을 받더라도, 앙상블 평균을 내면 노이즈 효과가 감소한다.
✔ OOB 에러를 활용하여 별도 검증 데이터 없이 모델 성능을 추정할 수 있다.
✔ 병렬 처리(parallelization)가 가능하다
- 모든 베이스 모델은 독립적으로 학습되므로, 병렬 연산이 가능하여 학습 속도를 높일 수 있다.
2.3.2. 배깅(Bagging)의 단점
❌ 바이어스(Bias)를 줄이지 못한다
- 배깅은 분산을 줄이는 방법이지만, 바이어스를 줄이는 효과는 없다.
- 따라서 바이어스가 높은 선형 모델에는 큰 효과가 없다.
❌ 부트스트랩 샘플링이 항상 충분한 다양성을 보장하지는 않는다
- 데이터 크기가 작으면 부트스트랩만으로 충분한 다양성을 확보하기 어렵다.
- 이 경우, 모델이 독립적인 패턴을 학습하지 못할 수 있다.
❌ 계산 비용이 증가한다
- 여러 개의 모델을 학습해야 하므로 연산량이 늘어나며, 특히 대규모 데이터셋에서는 부담이 될 수 있다.
3. Reference
[1] Korea University - Multivariate Data Analysis 07_part_1 ~ 06_part_2
