[Class Review](MDA_강필성) 7-2. Ensemble Learning-2

- 본 글은 서울대학교 산업공학과 DSBA 연구실 강필성 교수님의 "다변량데이터분석" 학부강의의 review이다.
1. Random Forest
랜덤 포레스트(Random Forest)는 앙상블(Ensemble) 기법 중 하나로, Bagging을 확장한 형태에 의사결정나무(Decision Tree)를 결합한 방법론이다. 여기서는 “배깅 + (변수 무작위 선택)”이라는 두 가지 아이디어를 이용해, 서로 다른 데이터·특징 조합으로 다양성(Diversity) 높은 여러 트리를 학습하고, 그 예측을 최종 결합해 예측 성능을 높인다. 또한 변수 중요도(Feature Importance) 산출이 가능하다는 점이 실무적으로 매우 중요하다.
1.1. Review of Previous Class: Bagging과 의사결정나무
1. Bagging 복습
- Bagging은 원본 데이터셋(크기 )에서 복원추출(부트스트랩)로 동일 크기 의 샘플들을 여러 번 뽑아 개별 모델을 학습한 후, 그 결과(예측)를 결합(평균, 투표 등)하는 기법이다.
- 복잡도가 큰(=분산이 큰) 알고리즘일수록, Bagging으로 여러 모델을 만든 뒤 평균하면 분산이 줄어들어 일반화(generalization) 성능이 크게 향상된다.
- 하지만 Bias 문제 해결에는 약한 모습을 보인다.
2. Random Forest 개념
- Random Forest는 “Bagging”을 사용하는 점에서 출발하되, 베이스 모델로 항상 의사결정나무(Decision Tree)를 택한다.
- 여기에 스플릿(split) 시 변수 무작위 선택 과정을 추가해, 단순 Bagging보다 트리 간 상관성을 더 낮추고(다양성 강화) 결과적으로 더 좋은 예측 성능을 낼 수 있다.
- 즉, 여러 “랜덤”한 트리(tree)들을 모아 “숲(forest)”을 이루기 때문에 “Random Forest”라는 이름이 붙었다.
1.2. Random forest의 핵심 아이디어
랜덤 포레스트가 개별 트리를 서로 다르게 만들기 위해서는,
- (A) 데이터 단계의 무작위성과
- (B) 변수(특징) 단계의 무작위성을 모두 이용한다.
(A) Bagging으로 인한 데이터 무작위화
- 부트스트랩 샘플
- 원본 데이터(크기 )에서 복원추출로 동일 크기 인 샘플을 만든다(이를 부트스트랩 샘플이라 함).
- 이 과정을 번 반복하여, 서로 다른(하지만 중복 포함 가능) 부트스트랩 세트 를 생성한다.
- 각 세트별 트리 학습
- 각 부트스트랩 샘플로부터 의사결정나무를 학습한다(가급적 완전 분기 or 큰 깊이로).
- 이렇게 생긴 개의 트리는 데이터 샘플 차원에서 이미 서로 약간씩 다르다.
(B) 변수(특징) 무작위 선택
- Split 시 일부 변수만 활용
- 의사결정나무를 분할(splitting)할 때, 모든 변수 를 탐색하지 않고, 랜덤하게 개만 골라 그중 스플릿을 찾는다.
- 예: 이면, 각 노드에서 개(예: 5개) 변수를 무작위 선택 후, 그중 “정보획득량(Information Gain)”이 가장 큰 분할 기준을 사용.
- 트리 간 상관 감소(목적)
- 만약 특정 변수가 아주 강력하다면, 대부분 트리가 똑같은 변수를 사용해 비슷한 결정 경계를 만든다 → 서로 상관성이 높아짐.
- 무작위로 변수 후보를 제한하면, 각 트리가 다른 변수에도 의존하게 되어 트리 간 다양성이 증가한다.
1.3. 전체 알고리즘 절차
정리하면, 랜덤 포레스트는 아래 순서로 진행된다.
- 부트스트랩 샘플 생성 (Bagging 부분)
- 크기 인 원본 데이터로부터, 복원추출(부트스트랩)로 개를 뽑는다(이를 라 하자).
- 이를 번 반복, 개의 데이터셋 확보.
- 각 샘플로 의사결정나무 학습
- 트리 분할 시, 노드에서 임의로 개 변수를 골라 그중 최적 분할 스플릿(정보획득량 최대 등)을 찾는다.
- 각 트리를 가급적 깊게 성장시켜둔다(프루닝 없음 or 최소화).
- (분류) 투표 or (회귀) 평균
- 새로운 입력 가 들어오면, 모든 트리에서 예측 결과 를 얻는다.
- 분류 문제인 경우, 다수결 투표 혹은 확률 평균을 사용. 회귀 문제이면, 로 평균 예측.
1.4. 배깅(Bagging)과 랜덤 포레스트(Random Forest) 비교
배깅과 랜덤 포레스트는 모두 부트스트랩 샘플링을 활용하는 앙상블 기법이라는 공통점을 가지고 있다. 하지만 가장 큰 차이점은 "각 개별 모델의 학습 방식"에서 발생한다.
1.4.1. 배깅(Bagging)에서의 변수 선택
배깅에서는 각 부트스트랩 샘플(훈련 데이터셋)에서 모든 변수를 고려할 수 있다. 즉, 배깅을 사용할 경우 개별 모델이 훈련에 사용된 부트스트랩 샘플 내의 모든 변수(feature)를 고려하여 학습한다.
하지만 배깅 과정에서 데이터가 복원추출로 샘플링되기 때문에, 개별 부트스트랩 샘플에 따라 일부 데이터 포인트나 일부 변수가 포함되지 않을 수도 있다.
그러나 이는 "샘플링으로 인해 특정 변수가 학습에 포함되지 않을 가능성"이지, 고의적으로 특정 변수를 제외하는 것이 아니다.
✔ 즉, 배깅에서는 "특정 변수를 선택적으로 제외하는 과정"이 없으며, 주어진 부트스트랩 샘플에 존재하는 변수는 모두 사용할 수 있다.
✔ 하지만 부트스트랩 샘플링으로 인해 모든 부트스트랩 샘플이 원본 데이터셋과 동일한 변수를 포함하지 않을 수도 있다.
배깅에서 베이스 모델로 결정 트리(Decision Tree)를 사용하면 랜덤 포레스트와 구조적으로 유사해질 수 있지만, 여전히 랜덤 포레스트와 차이점이 존재한다.
1.4.2. 랜덤 포레스트(Random Forest)에서의 변수 선택
랜덤 포레스트는 배깅을 기반으로 하지만, 추가적으로 "변수 무작위 선택(Random Feature Selection)"이라는 개념이 도입된다.
- 배깅과 마찬가지로, 부트스트랩 샘플을 생성한다.
- 트리 분할(Split) 과정에서, 특정 노드에서 모든 변수를 고려하는 것이 아니라 무작위로 선택된 일부 변수만 사용하여 최적의 분할을 찾는다.
✔ 즉, 랜덤 포레스트에서는 일부 변수를 고의적으로 무시하고, 무작위로 선택된 변수들만 고려하여 트리를 생성한다. 이로 인해 트리 간의 다양성이 증가하고, 모델의 일반화 성능이 향상된다.
✔ 배깅에서의 부트스트랩 샘플링이 "데이터의 다양성"을 제공한다면, 랜덤 포레스트에서의 변수 무작위 선택은 "트리 간의 구조적 다양성"을 추가적으로 부여한다.
1.4.3. 배깅 vs. 랜덤 포레스트 정리
| 비교 항목 | 배깅(Bagging) | 랜덤 포레스트(Random Forest) |
|---|---|---|
| 부트스트랩 샘플링 | O | O |
| 베이스 모델 | 어떤 모델이든 가능 | 항상 결정 트리(Decision Tree) |
| 변수 무작위 선택 | X (모든 변수 사용 가능) | O (각 노드에서 일부 변수만 선택) |
| 트리 간의 다양성 증가 방법 | 부트스트랩 샘플링(데이터 다양성) | 부트스트랩 샘플링 + 변수 무작위 선택 |
| 과적합 방지 효과 | O (분산 감소) | O (분산 감소 + 트리 다양성 증가) |
✔ 랜덤 포레스트는 배깅을 기반으로 한 특수한 형태이다.
✔ 즉, "랜덤 포레스트 = 배깅 + 변수 무작위 선택 + 결정 트리" 라고 볼 수 있다.
1.4. OOB(Out-of-Bag) 에러와 검증
-
OOB 샘플
- 복원추출 시, 매번 약 36.8% 정도의 데이터는 추출되지 않은 상태로 남는다(Out-of-Bag).
- 각 트리에 대해, 이 OOB 데이터는 학습에 쓰이지 않았으므로 해당 트리의 검증 세트 역할을 한다.
-
OOB 에러 추정
- 각 트리가 자신이 학습에 사용하지 않은 OOB 데이터에 대해 예측을 수행하고, 에러를 측정.
- 이를 전체적으로 평균을 내면, 별도 검증 세트 없이도 랜덤 포레스트의 일반화 성능을 꽤 정확히 추정 가능하게 된다.
-
장점
- 추가 데이터 분할(학습·검증)을 하지 않아도, 학습 데이터만으로 내부적으로 에러를 추정한다.
- 학습 도중에 OOB 에러 변화를 확인하며, 트리 수 (B)가 충분히 많아졌을 때 학습 중단할 수도 있다(실무 적용에서 유용).
1.5. 변수 중요도(Feature Importance)
랜덤 포레스트는 변수 중요도 지표를 제공한다. 변수 중요도는 각 특징이 최종 모델의 예측 성능에 얼마나 기여했는지를 평가하는 지표이며, 특정 변수가 결정 트리에서 얼마나 자주 사용되었는가와 해당 변수를 사용한 분할이 얼마나 정보적 이득을 제공했는지에 따라 중요도가 결정된다. 이는 현업에서 모델 해석성 확보에 크게 기여한다.
대표적인 방법으로는 Permutation Importance(Mean Decrease in Accuracyt, MDA)가 있다.
-
Permutation(치환) 기법
- 트리 학습이 완료되면, 각 트리에 대해:
1) 해당 트리의 OOB 데이터로 에러()를 계산.
2) 특정 변수 만 임의로 순서를 뒤섞어(Permutation) OOB 데이터에 넣어 새 에러()를 계산.
3) (오차 증가량)을 구함. - 변수를 뒤섞었을 때 오차가 크게 증가하면, 그 변수는 해당 트리 분할에 있어 핵심 변수임을 의미한다.
- 트리 학습이 완료되면, 각 트리에 대해:
-
랜덤 포레스트 전체에서 개 트리에 대해 를 평균하거나, 분산까지 고려해 합산 지표를 만든다. 크면 클수록(뒤섞었을 때 예측력이 심각하게 떨어짐) → 중요한 변수.
-
의의
- 의사결정나무 기반 모델이면서도, 단일 트리에 비해 더욱 정교하게 변수 기여도를 산출 가능.
- 각 변수의 상대적 영향력을 쉽게 파악해, 특징 선택 혹은 해석에 도움을 준다.
2. Boosting: AdaBoost
AdaBoost(Adaptive Boosting)는 앙상블(Ensemble) 기법 중 하나로, 기존 모델(약한 학습기, weak learner)이 잘못 예측하는 사례들을 점진적으로 보완해가며 최종적으로 강한 학습기(strong learner)로 발전시키는 방법이다. 이전에 배웠던 배깅(Bagging)이나 랜덤 포레스트와 달리, 데이터 샘플링 가중치를 계속 업데이트하면서 순차적으로 모델을 학습하는 것이 특징이다.
아래에서는 AdaBoost의 기본 아이디어부터 구현 절차(알고리즘 공식), 그리고 직관적 예시를 순서대로 정리한다.
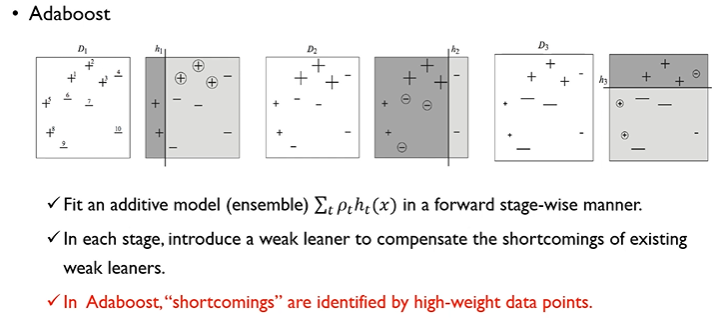
2.1 배경과 핵심 아이디어
(1) Weak vs. Strong 모델
- AdaBoost는 weak learner(약한 학습기)를 여러 번 순차적으로 학습·보완하여, 궁극적으로 strong learner(강한 학습기)에 근접한 성능을 얻는 것을 목표로 한다.
- “약한 학습기”란 보통 랜덤 추정(50% 정확도 가정)보다 조금이라도 나은 모델을 의미한다.
- 예: 반반 분류 문제에서 정확도 50%보다 높은 모델.
- AdaBoost는 이러한 weak model들을 주어진 데이터에서 점차적으로 “강화(boost)”한다.
(2) 부스팅(Boosting) vs. 배깅(Bagging)
- 배깅(Bagging): 독립적으로 복원추출한 여러 데이터셋으로 동시에(parallel) 모델을 학습하고, 결과를 결합(평균·투표).
- 데이터 샘플링 확률은 모든 객체에 균등 → 각각의 모델을 병렬로 만들 수 있다.
- 부스팅(Boosting): “순차적(sequential) 학습”을 통해, 이전 모델이 잘 못 맞춘 데이터에 더욱 가중을 두어 다음 모델이 집중 학습하게 함.
- 처음에는 모든 데이터 동일 가중이지만, 시간이 지날수록 “오류가 컸던 사례”의 가중이 점점 커져, 어려운 케이스를 더 많이 다루도록 유도한다.
2.2 알고리즘 절차 (AdaBoost 공식 포함)

AdaBoost는 분류 문제(범주 2개, -1과 +1로 표기)에 대한 경우를 예시로 설명한다(회귀 버전도 유사 개념으로 확장 가능).
1. 학습 데이터 준비
- 데이터를 로 표시하며, 로 정의.
- 각 샘플의 “선택 확률” 또는 “가중치”를 라 한다(초기에는 모두 동일).
2. 반복(약한 학습기 순차 학습)
(1) 약한 모델 학습
- 현재 가중치 를 반영해, 샘플링 혹은 가중 최소화 등을 통해 weak learner()를 훈련한다.
- 예: “스텀프(stump)”라는 단순 의사결정나무(노드를 한 번만 분할)로 학습.
(2) 에러율(오분류율) 계산
- = '현재 학습 데이터에 대해서 정답과 추정된 값이 다른 것에 대한 비율'
- 즉, 현재 모델 가 전체 샘플에 대해 가중치 기준으로 틀린 비율(가중 오차)이다.
- 만약 이면 중단(이 약한 학습기는 너무 성능이 낮아 개선 여지 없음).
(3) (가중치) 계산
- 가 작을수록 는 커지며, 해당 약한 모델에 신뢰가 높다는 의미.
(4) 가중치 업데이트
-
모델 가 틀린 샘플에는 가중치를 증가, 맞춘 샘플에는 가중치를 감소시키도록 조정.
-
예:
-
틀린 샘플 은
→ 가중치 상승. -
맞힌 샘플은
→ 가중치 하락.
(5) 정규화
- 모든 합이 1이 되도록 스케일(정규화).
- 다음 단계의 가 확률 분포가 됨.
3. 최종 모델 결합
- 번 반복 후, 약한 모델들 각각의 를 가중으로,
- 분류:
- 즉, 가 큰 모델을 더 신뢰하게 된다.
2.3 직관적 예시
(1) 팀 학습 비유
- 예: 팀 B가 순차적으로 “문제집”을 고르며, 앞사람(전 모델)이 틀린 분야가 많은 책을 사서 추가 학습 → 점차 커버리지 보완.
- 마지막에는 각 팀원이 전부 지식 합쳐서 높은 정확도 달성.
- 반면 배깅은 팀원(A)들이 서로 다른 문제집을 동시에 공부(병렬)하는 식.
(2) 2차원 분류 그림
- 처음 스텀프()는 단순 선분할, 일부 점들은 틀린 상태.
- 다음 스텀프()는 틀린 점들 가중이 커져 그들을 더 잘 맞추도록 분할.
- 3~4번 스텀프를 거치면, 여러 간단한 경계가 결합되어 복잡한 결정 경계도 형성 가능.
(3) 가중치 변화
- 매 단계, 잘못 분류된 샘플일수록 그다음 단계 모델에서 더 자주 혹은 더 높게 반영된다.
- 결국 “어려운 예제”들이 계속 남아서 수차례 개선되므로, 최종적으로 상당히 높은 정확도를 달성할 수 있다.
2.4 특징과 정리
(1) 장점
- 단순한 “약한 모델(weak learner)”만 있어도, 이를 순차적으로 보완하여 강한 학습기로 발전 가능.
- 데이터가 적어도, 부스트 순차 학습 방식으로 적절히 오류 케이스를 커버.
- 실제로 다양한 문제에서 RF(랜덤 포레스트)와 더불어 널리 사용.
(2) 단점
- 순차적 학습이므로, 병렬 처리가 어렵다(학습 시간이 길어질 수 있음).
- 모델이 단계가 진행될수록 이상치(outlier)에 지나치게 적합(overfit)될 위험이 있다.
- 계산 로직 상, 약한 모델이 “정확도 < 50%”인 경우 방해가 될 수 있어, 모델이 완전히 랜덤이면 안 됨.
AdaBoost는 단순한 모델(weak learner)이라도 오류를 거듭 보완하여 강한 성능을 낼 수 있음을 증명한 기법이다.
약한 학습기의 성능이 무작위보다 조금만 낫다면, 부스팅을 통해 충분히 강력해질 수 있다.
3. Boosting: Gradient Boosting Machine (GBM)
이전의 AdaBoost가 “오류가 컸던 데이터에 가중치 부여”라는 관점에서 부스팅을 수행했다면,
GBM은 각 단계에서 잔차(residual)를 예측하는 추가 모델(트리 등)을 순차적으로 쌓아 가는 방식이다. 특히 경사(Gradient) 하강 아이디어와 결합해, 잔차를 그레디언트로 해석하고 이를 새 모델 학습에 반영함으로써 순차적으로 모델을 보완해 나가는 것이 핵심이다.
아래에서는 GBM을 회귀(regression) 문제 기준으로 먼저 설명하고, 분류 등 다른 문제로의 일반화를 간단히 언급해보도록 하겠다!
3.1 GBM 기본 아이디어
3.1.1 부스팅(Boosting) 개념의 확장
- 이전에 배웠듯, 부스팅은 “약한 모델(weak learner)들을 순차적으로 학습”하면서, 이전 단계에서 발생한 오류나 미스를 다음 단계에서 보완하게 하는 방법이다.
- AdaBoost는 이전 모델이 틀린 샘플에 높은 가중치를 부여해서, 그 샘플이 다음 모델에서 중점적으로 학습되도록 한다.
- Gradient Boosting은 이 가중치 업데이트 대신, 각 단계에서 잔차(혹은 그레디언트)를 새 모델의 목표로 삼아 점진적으로 오차를 줄여나가는 관점이다.
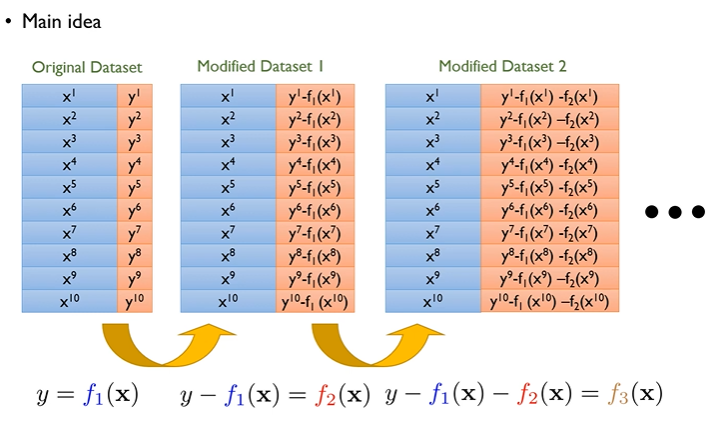
3.1.2 회귀 문제에서의 직관
- 회귀에서 모델 가 주어진 상태에서, 실제값 와 의 차이(잔차) 를 “아직 학습되지 못한 부분”으로 본다.
- GBM은 이 잔차만을 겨냥한 추가 모델(주로 트리)을 학습하여, 형태로 순차 업데이트한다(는 러닝레이트(learning rate), step size).
- 결국 번째 단계에서 만들 모델은, 직전 단계에서 못 맞춘 부분을 주요 타깃으로 삼아, 누적 예측성을 강화한다(“오류(잔차)를 다시 모델링”).
3.1.3 Gradient(경사) 관점
- 회귀의 MSE(제곱오차)일 경우, 잔차가 (그레디언트의 반대 방향)에 해당한다.
- 분류나 다른 손실 함수를 써도, 각 단계에서 “손실 함수”의 그레디언트(또는 음수 그레디언트)를 계산해 새 모델이 그를 학습하도록 유도 → 각 단계가 오차(손실)를 가장 많이 줄일 방향으로 보완.
- 이 과정을 여러 번 반복(“stage-wise” 진행)하면, 전 단계까지 누적 모델이 잘못 추정한 부분이 점차 줄어들어 일반화 성능이 향상될 수 있다.
3.2 구현 절차 개괄

GBM은 다양한 손실 함수를 처리할 수 있으나, 여기서는 회귀 문제(L2 loss)를 중심으로 개념을 정리한다.
-
초기 모델
- 가령, 전체 데이터의 -값 평균을 쓰거나, 단순한 예측값(기준선)을 사용한다.
-
반복 ( )
1) 잔차 계산 (회귀시):
→ 직전 모델이 예측하지 못한 부분(오류).
(분류 시에는 -그레디언트로 해석)2) 새로운 약한 학습기(트리 등) 학습
- 이 잔차 를 목표값으로 하여, 작은 트리(stump 등)를 학습한다.
- 즉, “오류(잔차)를 잘 예측하는” 미니 모델 를 찾는다.
3) 결합 계수(learning rate 등) 적용
- 최적화나 단순 계수조정으로 를 구해, 최종적으로 를 형태로 합산.
- 일반적인 경우, (학습률)도 곱해 모델이 너무 크게 변동되지 않도록 한다.
4) 모델 업데이트
-
최종 앙상블
-
.
-
“처음 기초 모델 + 순차적으로 학습된 트리”를 모두 더해 최종 예측값.
-
3.3 GBM과 과적합(Overfitting) 방지
GBM은 각 단계가 “이전 단계의 오류를 극복하는” 구조라, 자료에 Overfitting 될 수 있다. 이를 막기 위한 몇 가지 전략이 존재한다 (기존에 봐왔던 익숙한 방법들일 것이다) :
-
러닝레이트(Learning Rate)
- 각 단계를 작게 업데이트()하면, 모델이 급격히 변동하는 것을 방지해 “점진적”으로 학습.
- 가 너무 작으면 학습이 오래 걸리고, 너무 크면 오버피팅 가능성 증가.
-
Sub-sampling(부분 샘플)
- 각 트리를 학습할 때, 전체 데이터의 일부(예: 80% 등)만 무작위로 뽑아서 사용.
- 배깅처럼 “병렬 독립”은 아니지만, 무작위 부분 샘플로 인한 다양성이 생겨 과적합 완화.
-
적은 트리 깊이 / 규제(Regularization)
- 트리의 깊이를 제한(예: 3~5 depth)하거나, 리프노드 최소 샘플수·노드 분할 시 정보획득 조건 등을 엄격히 하여 복잡도를 낮춤.
-
Early Stopping(조기 종료)
- 별도 검증세트나 OOB 에러 등을 확인하며, 에러가 더 이상 줄지 않거나 오히려 증가하면 학습 중단.
3.4 분류 문제와 일반화
-
분류(2-class 이상)
- AdaBoost처럼 -1/+1 이진 레이블 혹은 일반 다중 레이블도 가능.
- 잔차 대신, 로지스틱 손실(이진 크로스엔트로피) 등의 그레디언트를 이용해 모델이 업데이트된다.
- XGBoost, LightGBM 등 구현체들은 분류, 회귀, 랭킹 등 다방면에 최적화가 잘 되어 있음.
-
변수 중요도
- GBM도 최종적으로 만들어진 트리들에서 스플릿 횟수 / 정보획득량 등을 합산해 변수 중요도를 산출할 수 있다(원리는 랜덤포레스트와 유사).
4. Reference
[1] Korea University - Multivariate Data Analysis 07_part_3 ~ 07_part_5
- https://www.youtube.com/watch?v=wB0ELX15kN8&list=PLetSlH8YjIfWKLpMp-r6enJvnk6L93wz2&index=32
- https://www.youtube.com/watch?v=Y2rsmO6Nr4I&list=PLetSlH8YjIfWKLpMp-r6enJvnk6L93wz2&index=33
- https://www.youtube.com/watch?v=1qnZ6JKZTNI&list=PLetSlH8YjIfWKLpMp-r6enJvnk6L93wz2&index=34
[2] 15. 'AdaBoost(Adaptive Boost) 알고리즘에 대해서 알아보자 with Python' by 부자 꽁냥이
