Apache Spark

비교적 최근에 (2012년) 등장하여 선풍적인 인기를 얻고 있는 분산처리 프레임워크
메모리 기반의 처리를 통한 고성능과 Functional Programming 인터페이스를 활용한 편리한 인터페이스가 특징
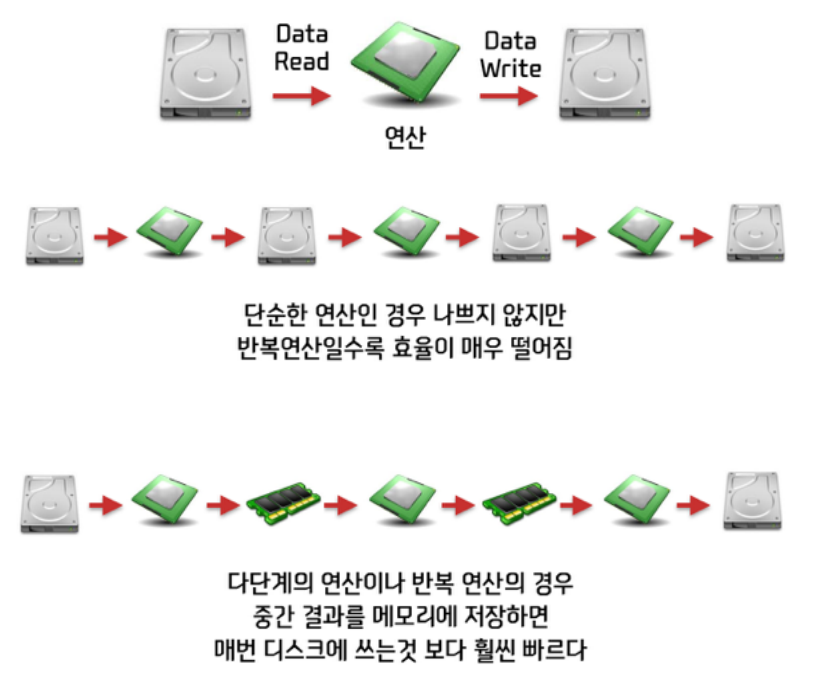
Hadoop (MapReduce)는 매번 중간 결과를 디스크에 저장하지만,
Spark은 이를 메모리에서 처리하므로 효율이 좋다.
(PageRank나 머신러닝 알고리즘같이 반복계산이 많은 경우 특히 성능이 좋음)
MapReduce
빅데이터의 시초
여러대의 분산 저장소에 존재하는 데이터를 변환하거나 계산하기 위한 프레임워크
Functional Programming의 Map() 함수와 Reduce() 함수를 조합하여 효율적으로 분산 환경에서 다양한 계산을 한다.
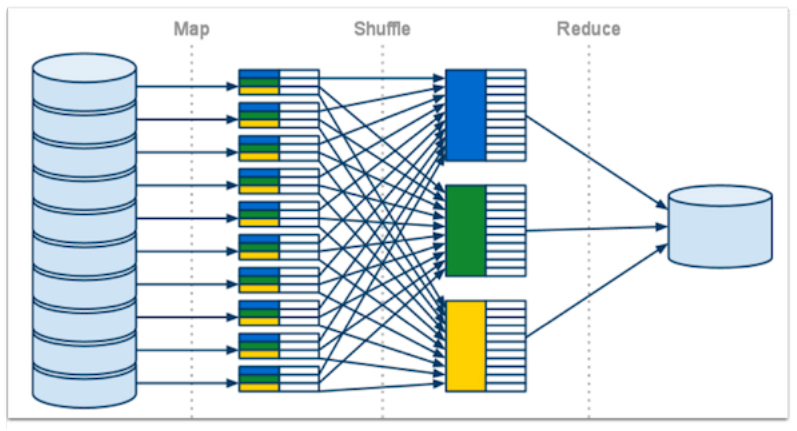
- Map() : A인 데이터를 B로 변환시키는 계산을 리스트에 대해 수행
- List(1,2,3).map(x => x * 2) // result: List(2,4,6)
- Reduce() : 리스트에 들어있는 A, B, C 를 특정 룰에 의해 합치는 작업
- List(1,2,3).reduce((a,b) => a + b) // result
- Map() 과 Reduce() 를 조합하면 다양한 작업을 수행할 수 있다.
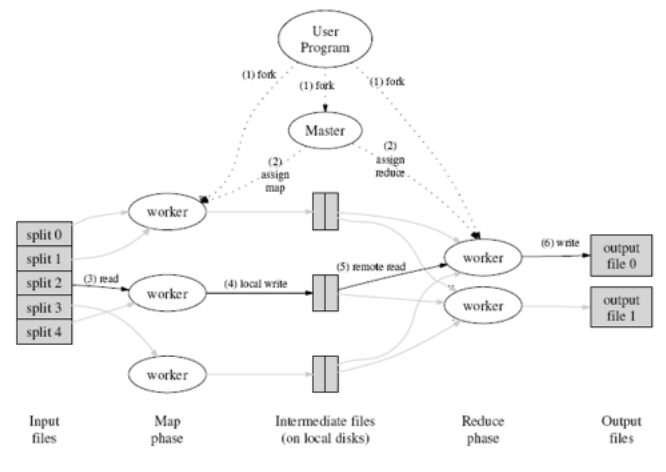
- Input 파일을 잘게 나눠서 여러 worker에서 나눠서 Map() 작업 수행
- 중간 파일을 저장한후, 이를 수합해서 Reduce() 작업 수행
- Reduce()를 수행한 워커에서 각각의 결과물을 저장
이 구글의 MapReduce 솔루션을 오픈소스화 한 것이 바로 Hadoop
Apache Spark 핵심개념
- RDD (Resilient Distributed Dataset - 탄력적으로 분산된 데이터셋)
오류 자동복구 기능이 포함된 가상의 리스트
다양한 계산을 수행 가능, 메모리를 활용하여 높은 성능을 가짐 - Scala Interface
매우 간결한 표현이 가능한 모던 프로그래밍 언어
Functional Programming이 가능해 데이터의 변환을 효과적으로 표현할 수 있음
Apache Spark 확장 프로젝트
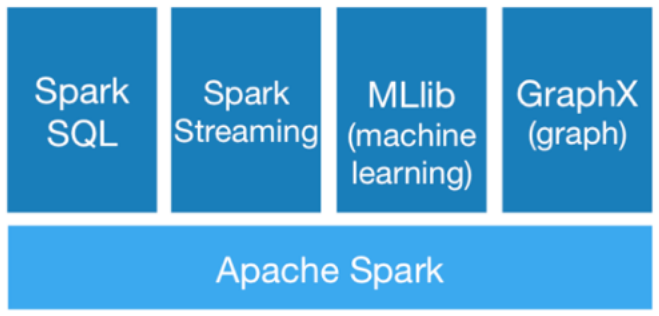
Spark을 엔진으로 하는 확장 프로젝트들이 같이 제공된다.
- Spark SQL: Hive와 비슷하게 SQL로 데이터 분석
- Spark Streaming: 실시간 분석
- MLlib: 머신러닝 라이브러리
- GraphX: 페이지랭크같은 그래프 분석
Spark Streaming
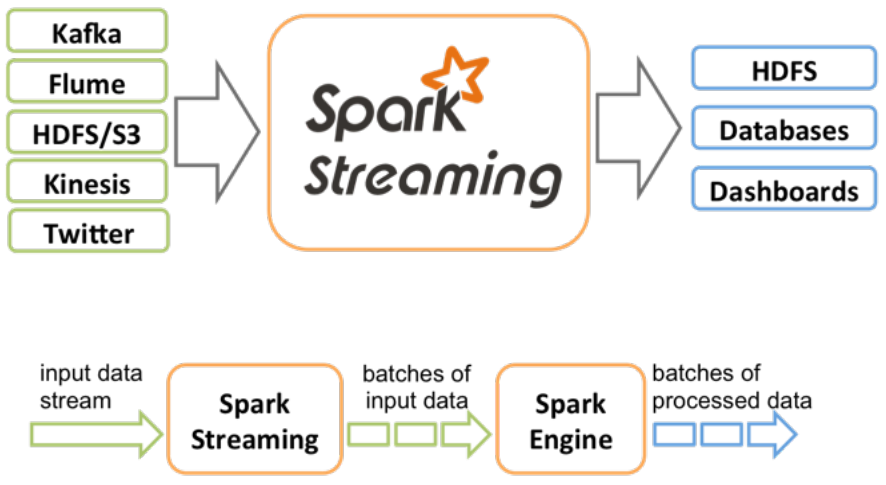
- DStream: RDD의 연속.
스트림 데이터를 쪼개거나 윈도우를 만들어 짧은
단위로 RDD연산을 수행
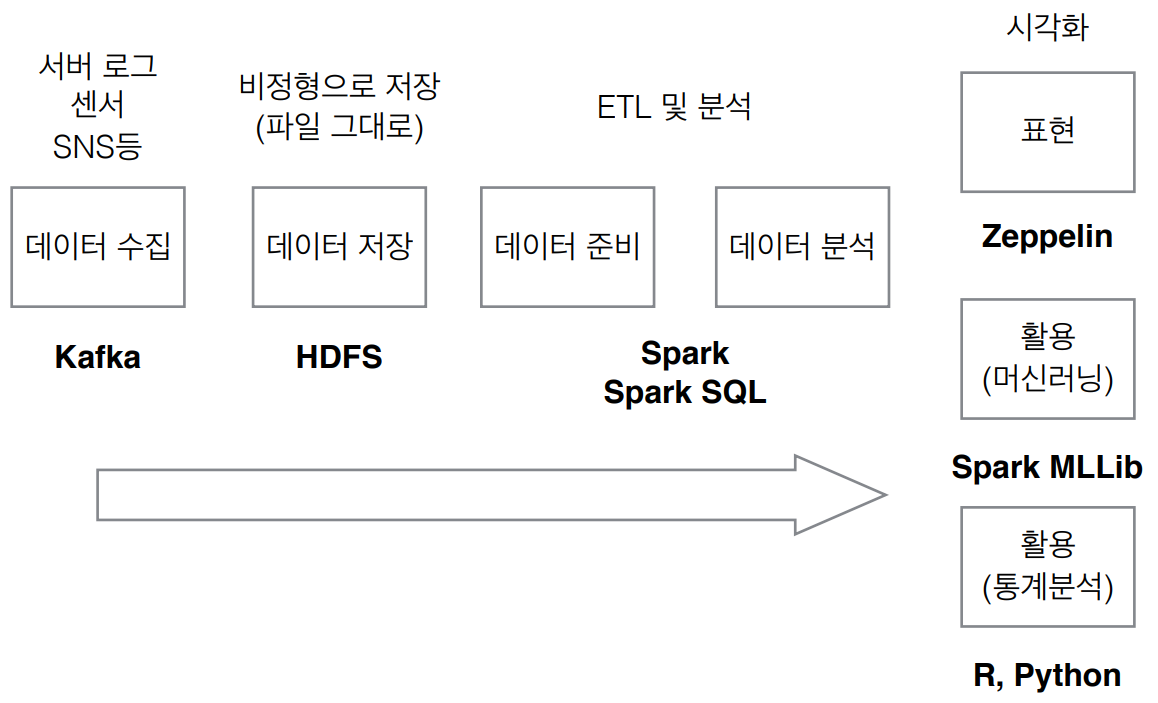
Spark 빅데이터 분석 워크플로우
RDD
클러스터 전체에서 공유되는 리스트, 메모리상에 올라가있다.
(메모리가 부족한 경우엔 디스크에 spill)
- map, reduce, count, filter, join 등 다양한 작업 가능
- 여러 작업을 설정해두고, 결과를 얻을 때 lazy하게 계산
Transformations
데이터를 어떻게 구해낼지를 표현
Actions
표현된 데이터를 가져오는 것
Lineage
클러스터 중 일부의 고장 등으로 작업이 중간에 실패하더라도, Lineage
를 통해 데이터를 복구할 수 있다.
Lazy Execution
Transformation시에는 계산을 수행하지 않고, Action이 수행되는 시점
부터 데이터를 읽어들여서 계산을 시작
RDD Transformations
RDD의 데이터를 다른 형태로 변환
실제로 데이터가 변환되는 것이 아니라, 데이터를 읽어들여서 어떻게 바꾸
는지 방식만을 기록하는 것이다.
(실제 변환은 Action이 수행되는 시점에서 이루어짐)
map, filter, flatMap, mapPartitions, sample, union,
intersection, distinct, groupByKey, reduceByKey, join,
repartition 등
Transformation - Map, Filter
- map, filter와 같은 Transformation은 즉시 계산이 수행되는것이 아
니라, count() 와 같은 Action이 수행될 때 실제 계산이 수행된다. - transformation이 기록된 새 RDD를 리턴해준다.
- map(func) : func 로 기술되는 동작을 RDD에 모든 element에 수
행. - filter(func): true/false 를 판별하는 func 이 true인 element만 남겨둠
Transformation - Reduce, GroupBy
- reduce(func) : 기술한 func 대로 RDD의 element를 합치는 작업
을 수행한다. - map() 은 각 클러스터 간 데이터 교환 없이 element-wise 데이터
변환만을 수행하므로 아주 효율적으로 병렬 처리가 가능. - reduce()도 최종적으로 클러스터간의 데이터가 모이기 전에 클러스
터 내부의 데이터부터 reduce 계산이 가능하기에 효율적인 operation. - GroupBy(func) : reduce와 비슷하지만 데이터를 줄이는것이 아니
라, 전부 보존해서 수집해야 한다. 하지만 대량의 네트워크 트래픽이 발생하여 메모리 문제가 발생할 가능성이 있다.
RDD Actions
여러가지 변환 (Transformation)이 담긴 RDD의 정보를 통한 계산을 수행
reduce, collect, count, first, take, saveAsTextFile,
countByKey, foreach 등
Action - Count, Collect, Take 등
- Spark은 Action 이 수행되면 그때서야 파일을 로드하고, 기록된 Transformation을 수행하고, 최종 Action을 수행한다.
- count() : RDD의 element 갯수를 세는 동작
- collect() : RDD의 내용을 전부 드라이버 프로그램으로 가져온다.
(RDD의 내용이 큰 경우, collect 할때 메모리가 꽉차서 프로그램이 죽을
수도 있고, RDD의 내용이 충분히 작지 않으면, 안전한 take를 사용) - take(n) : 처음 n 개의 element를 가져온다.
Data Loading
Spark의 데이터 입력 부분은 Hadoop의 코드를 그대로 사용하기 때문에, Hadoop에서 지원하는 모든 소스를 사용할 수 있다.
- 로컬 파일 : sc.textFile(“file:///…)
- HDFS : sc.textFile(“hdfs://…)
- Amazon S3 : sc.textFile(“s3://…)
- HBase, Cassandra : Spark HBase Connector 등 이용
- 압축파일도 읽어들이기 가능
- 와일드카드 (*) 사용 가능
Word Count Example
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")- sc.textFile() - 파일을 로드
- flatMap(line => line.split(“ “)) - 로드된 텍스트 라인을 space 로 나누고, 2단 array 형식의 데이터를 1단으로 flatten
- map(word => (word,1)) - 단어단위로 나눠진 것을, 1 이라는 레이블을 붙인다.
- reduceByKey(+) - 데이터를 같은 key (word) 끼리 묶고, 레이블을 서로 더함 ( : placeholder, +_ : 그것과 저것을 더하라)
RDD 캐싱
Spark은 메모리 캐시를 활용하여 성능을 극대화할 수 있다.
데이터가 커서 메모리에 올라가지 않는 경우는, 캐시하지 못한 데이터는 다시 계산한다.
메모리 부족 시 디스크 저장 등 다양한 옵션을 선택할 수 있음.
