빅데이터
1.빅데이터의 구성 요소와 종류
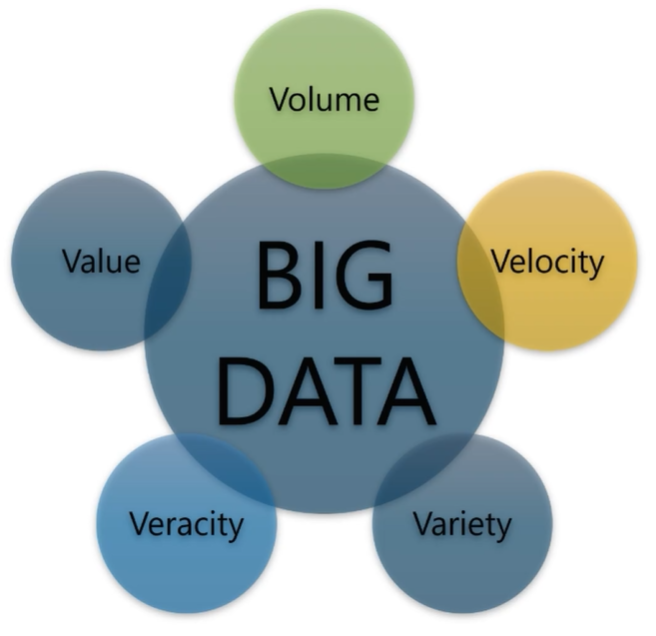
Volume - 규모현재는 TB 시대이며 Records, transaction, table, file size에 영향이 있다.Velocity - 속도대규모 처리 속도를 위한 다양한 어플리케이션이 받쳐줘야 한다. 최고의 속도를 가진 데이터는 메모리 안에 흘러가는 데이터
2.Apache Hadoop

하둡은 누구나 무료로 사용할 수 있는 오픈소스(Open Source) 소프트웨어. 대량의 데이터 저장소라고 생각하면 된다. 오픈소스 분산 컴퓨팅 플랫폼 Java-based distributed 컴퓨팅 플랫폼 Scale - Out 형식(서버 대수를 증가하여 저장용량
3.Apache Spark

비교적 최근에 (2012년) 등장하여 선풍적인 인기를 얻고 있는 분산처리 프레임워크메모리 기반의 처리를 통한 고성능과 Functional Programming 인터페이스를 활용한 편리한 인터페이스가 특징Hadoop (MapReduce)는 매번 중간 결과를 디스크에 저장
4.Hadoop 설치

해당 실습은 클라우드 환경에서 Ubuntu 18.04 VM을 하나 띄워서 진행했다.우선 JDK와 Maven을 설치해준다.hadoop 3.3.0 다운로드Hadoop 3.3.0 이 링크에서 tar.gz의 링크를 wget으로 받아온 후 압축을 해제해준다.하둡 데몬을 띄우기
5.HDFS
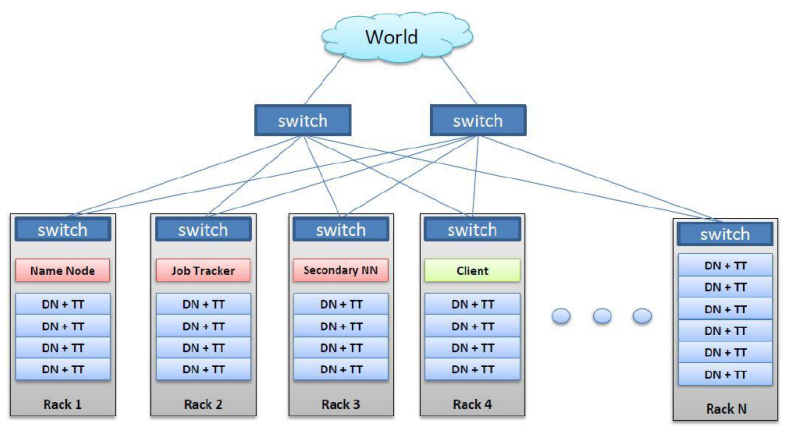
하둡 분산 파일 시스템(Hadoop Distributed File System)기존에도 parallel computing이라는 단어가 있지만 이 단어는 보다 cpu로 병렬처리를 한다는 것에 좀 더 초점을 둔 용어 distributed는 data에 좀 더 초점을 둔 용어
6.MapReduce
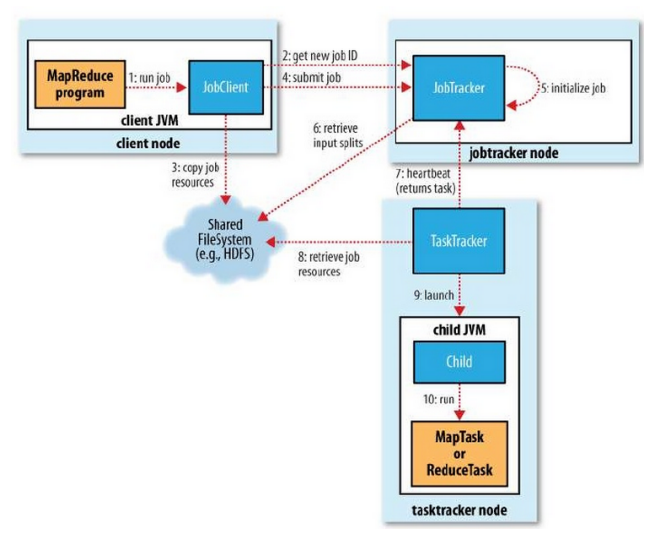
2004년 구글에서 발표한 Large Cluster 에서Data Processing 을 하기 위한 알고리즘Hadoop MapReduce 는 구글 알고리즘 논문을 소프트웨어 프레임워크로 구현한 구현체Key-Value 구조가 알고리즘의 핵심모든 문제를 해결하기에 적합하지는
7.Apache Kafka

Apache Kafka는 웹사이트, 어플리케이션, 센서 등에 취합한 데이터를 스트림 파이프라인을 통해 실시간으로 관리하고 보내기 위한 분산 스트리밍 플랫폼이다.데이터를 넣는 source APP과 쌓이는 target APP이 있다.처음엔 단방향 통신이었지만 시간이 지날수
8.Kafka 기초
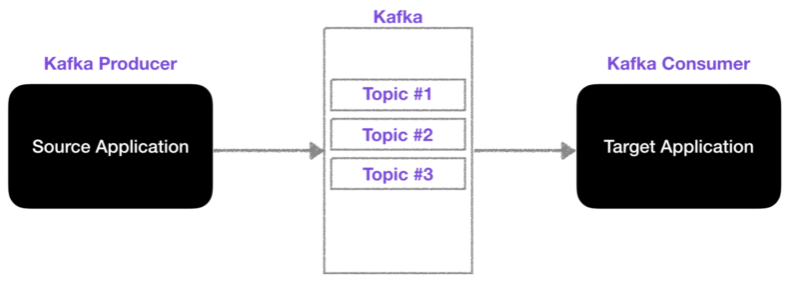
데이터가 들어가는 공간을 토픽이라고 한다.kafka에서는 토픽을 여러개 생성할 수 있고 DB의 테이블이나 파일시스템의 폴더와 유사한 성질을 갖고 있기 때문에 그런 개념이라고 봐도 된다.이러한 토픽들은 이름을 가질 수 있다. ex) click_log, send_sms,
9.Kafka Connect

Kafka Connect는 Kafka에서 공식적으로 제공하는 컴포넌트이고,반복적인 데이터 파이프라인을 효과적으로 배포하고 관리할 수 있다.Kafka는 Connect와 Connector로 이루어져 있다.Connect는 Connector를 동작하도록 실행해주는 프로세스파이
10.AWS에 Kafka 클러스터 설치

kafka 클러스터를 만들기 위해 Amazon Linux 인스턴스 3대를 생성해준다.zookeeper는 2181 2888 3888포트를 사용하므로 보안그룹에서 해당 포트를 열어줘야하고 kafka 통신을 위해 9092 포트도 열어주자.테스트의 편의를 위해 이번에 만든 3
11.Kubernetes Kafka 세팅 및 Confluent Kafka 사용해보기

GCP에서 GKE를 구성하여 거기에서 카프카를 세팅해볼 것이다.(여기서 쓰이는 yaml파일들은 특정 클라우드 환경에 종속되지 않기 때문에 편한 환경에서 진행해보면 된다.)현재 진행하려 하는 것은 굳이 자동확장까지 할 필요는 없으므로 Standard를 선택한다.여기서 이
12.Elasticsearch 기초

분산형 RESTful 검색 및 분석 엔진으로 표준 RESTful API와 JSON을 사용ex) John이라는 text는 doc1과 doc2에서 볼 수 있고 database라는 text는 doc1과 doc3에서 볼 수 있다.es는 이 텍스트들을 인덱싱해서 인덱스라는 DB
13.Elasticsearch 기초2

curl -XGET http://localhost:9200/<index 이름>데이터를 조회할 경우 -XGET데이터를 생성 및 추가할 경우 -XPOST, -XPUT데이터를 삭제할 경우 -XDELETE여기서 http://localhost:9200 -
14.제10회 빅데이터분석기사 합격 후기
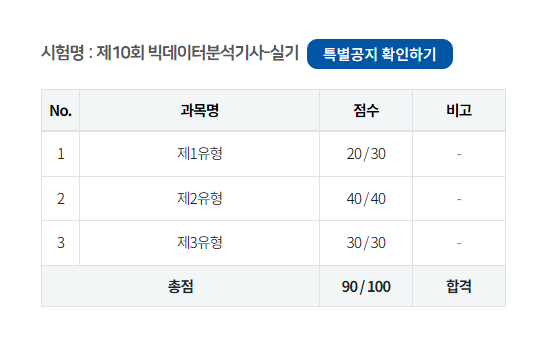
필기/실기 모두 그냥 평이했다. 물론 난 유관 전공자였고(통계 과목 A0 이상 받은 적 없는..) 실무에서 데이터와 AI 분야 관련 업무를 하고 있다.취득 이유데이터, AI 분야로 일하게 될 줄 몰랐는데 학교 다닐 때 해당 분야 과목들 죽 쑨 게 많아서..^^ 그냥 이