BigQuery ML의 선형회귀 및 로지스틱 회귀에서 사용되는 옵션
model options
| 이름 | 값 | 설명 | 예시 |
|---|---|---|---|
| model_type | linear_reg logistic_reg | 'linear_reg'는 linear regression model을 생성하는데 사용하는 Option, 'logistic_reg'은 logistic regression model을 생성하는데 사용. 해당 Option은 필수로 입력 해야 한다. | model_type=‘linear_reg’ model_type=‘logistic_reg’ |
| input_label_cols | STRING | 학습에 이용되는 라벨 컬럼의 이름을 배열로 열거 한다. 배열이 아니어도 하나의 컬럼일 경우 하나의 라벨 컬럼 명시 가능. 만약, 이 Option이 지정되지 않은 경우 Query 하는 Dataset 컬럼 명 중, “label”이라는 이름이 된 컬럼의 경우 이것을 하나의 input_label로 인식한다. 이것도 없으면 모델 생성은 실패. Linear Regression 모델의 라벨 column은 실제 수치값(숫자값)으로 하고, Logistics Regression의 경우 카디널리티가 낮은 컬럼을 대상으로 설정 | inupt_label_cols=[‘col1’,’col2’] |
| l1_reg | FLOAT64 | 기본값은 0 L1 정규화 진행 (모델 가중치를 조절하여 모델 접합성 향상) | |
| l2_reg | FLOAT64 | 기본값은 0 L2 정규화 진행 (모델 가중치를 조절하여 모델 접합성 향상) | |
| max_iterations | INT64 | 기본값은 20 최대 반복 학습 횟수 | |
| learn_rate_strategy | line_search constant | 기본값은 line_search Training 동안 특정 Learning rate(학습률)를 선정하는 데에 있어, 2가지 Option 선택 가능. line_search 학습 속도를 늦추고 처리되는 바이트 수를 늘리지 만, 지정된 초기 학습 속도가 더 높더라도 일반적으로 수렴된다는 점에서 트레이드 오프가 될 수 있음. 기본값(line_search)일 경우 ls_init_learn_rate의 값을 두배로 설정하는 걸 권장. | |
| ls_init_learn_rate | DOUBLE | learn_rate_strategy=‘line_search’일 경우에만 사용 | |
| learn_rate | FLOAT64 | 기본값은 0.1 learn_rate_strategy='constant'일 경우에만 사용. 경사 하강법 사용 | If learn_rate_strategy=‘constant’ then learn_rate=0.1 |
| early_stop | BOOL | 기본값은 TRUE 상대적 손실 개선값이 min_rel_progress 미만인 첫 번째 반복 이후에 학습이 중지되어어야 함을 나타냄 | |
| min_rel_progress | FLOAT64 | 기본값은 0.01 early_stop이 true로 설정 될 때 Training을 계속하기 위해 필요한 최소 상대 손실 개선값. 0.01 값을 지정하면 각 반복에서 교육을 계속 진행하기 위해 손실을 1 % 줄여야함 | |
| data_split_method | auto_split random custom seq no_split | 기본값은 auto_split 입력 데이터에 대해 훈련 데이터셋, 테스트 데이터셋을 나누는 방법에 대해 나타냄. auto_split 자동으로 분할 1. 데이터가 500개 이하 > 전부 훈련 데이터셋으로 사용. 2. 데이터가 500~50000개 > 랜덤으로 20%를 테스트 데이터셋으로 사용. 3. 그 이상 > 랜덤으로 10000개의 데이터를 테스트 데이터셋으로 사용. random 랜덤으로 나눔(다른 Training을 실시하면 할 때마다 다르게 분할됨. custom BOOL이란 이름으로 사용자가 컬럼을 만들어 훈련 데이터셋과 테스트 데이터셋을 분할. 여기서 컬럼값이 TRUE일 경우 테스트 데이터셋, FALSE일 경우 훈련 데이터셋으로 사용. seq 사용자가 제공한 컬럼을 순차적으로 나눔. 순차적으로 사용할 수 있는 컬럼은 NUMERIC,STRING,TIMESTAMP. 나머지 전부는 테스트 데이터셋으로 활용됨. no_split 모든 데이터를 훈련 데이터셋으로 사용. ) | |
| data_split_eval_fraction | FLOAT64 | 기본값은 0.2 위의 분할 Option이 random, seq일 경우 사용. 테스트에 사용된 데이터에 대한 소수점 값으로 해당 값은 평가에 대한 기준점 역할을 함. | |
| data_split_col | STRING | 데이터를 나누는데 기준이 되는 컬럼을 명시, 선택된 컬럼은 자동으로 피처 컬럼에서 제외됨. 분할 Option이 custom일 경우 해당 옵션에 명시되는 컬럼의 타입은 Boolean이어야 함. 이때 해당 컬럼이 TRUE나 NULL값의 컬럼은 테스트 데이터셋으로 사용되고 나머지 FALSE인 값은 훈련 데이터셋으로 사용. 분할 Option이 seq일 경우 해당 컬럼의 마지막 data_split_fraction 데이터가 테스트 데이터셋으로 사용됨. 첫 번째 행은 훈련 데이터셋으로 사용됨. | |
| warm_start | BOOL | 기본값은 FALSE 새 훈련 데이터, 새 모델 Option 또는 둘 다를 사용해 모델을 재교육. 명시적으로 재정의하지 않는 한 모델 Training에 사용되는 초기 Option이 warm start 실행에 사용됨. warm start 실행에선 반복 횟수가 0에서 시작하도록 재설정됨. model_type, label Option, 훈련 데이터셋의 스키마 변경은 불가능 | |
| auto_class_weights | BOOL | 기본값은 FALSE 로지스틱 회귀에서 훈련 데이터셋의 라벨이 불균형한 경우 모델은 가장 인기 있는 라벨로 더 많이 예측할 수 있는데 이는 바람직하지 않다. 이를 균형을 맞추기 위해 가중치를 부여할지를 선택하는 Option | |
| class_weights | STRUCT_ARRAY | 위의 Option이 TRUE면 이 옵션 지정 불가 각 클래스 라벨에 사용할 가중치. | CLASS_WEIGHTS = [STRUCT('example_label', .2)] |
| enable_global_explain | BOOL | 기본값은 FALSE Explainable AI를 사용하여 피처값의 중요도를 평가할지 여부 | |
| calculate_p_values | BOOL | 기본값은 FALSE Training중에 p-값과 표준 오류를 계산할지 여부 | |
| fin_intercept | BOOL | 기본값은 TRUE Training중에 절편을 모델에 맞출지 여부 | |
| category_encoding_method | STRING | 기본값은 one_hot_encoding 숫자가 아닌 피처에 사용할 인코딩 방법 지정. one_hot_encoding or dummy_encoding |
TRANSFORM
BigQuery에서 하고싶은 전처리 및 피처 엔지니어링을 모델 생성시 정의해서 평가 및 예측 때 자동으로 실행하는 SQL문
신생아 데이터를 사용해 출산시의 아이의 체중을 예측해보는 모델을 생성해볼 것이다.
BigQuery에 natality 데이터셋 하나 생성
데이터 조회
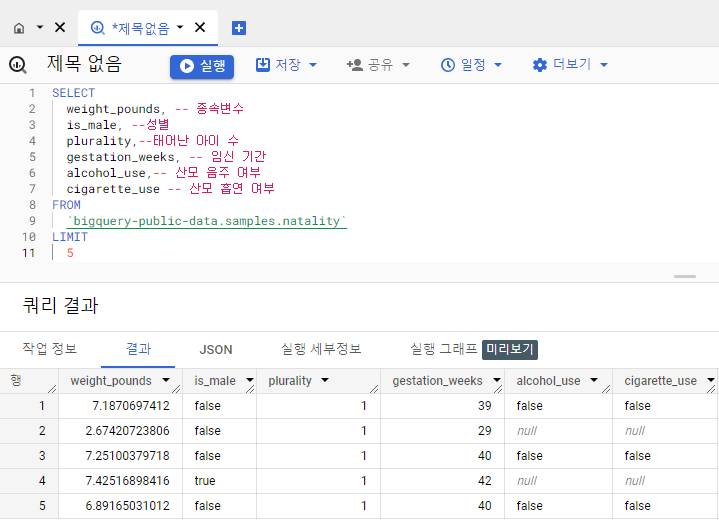
SELECT
weight_pounds, -- 종속변수(라벨)
is_male, --성별
plurality,--태어난 아이 수
gestation_weeks, -- 임신 기간
alcohol_use,-- 산모 음주 여부
cigarette_use -- 산모 흡연 여부
FROM
`bigquery-public-data.samples.natality`
LIMIT
5
BQML의 경우, 그대로 데이터를 입력해도 기본적인 전처리는 자동으로 해주지만 더 좋은 모델을 얻기 위해 전처리 수행
- 둘 이상이 동시에 태어났는지 여부
- 임신 기간이 37-42 주에 해당하는지 여부
- 산모가 음주를 했는지와 흡연을 했는지 여부 혼합
SELECT
weight_pounds,
is_male,
IF(plurality > 1, 1, 0) AS plurality,
ML.BUCKETIZE(gestation_weeks, [37, 42]) AS gestation_weeks,
ML.FEATURE_CROSS(
STRUCT(
CAST(alcohol_use AS STRING) AS alcohol_use,
CAST(cigarette_use AS STRING) AS cigarette_use
)
) AS alcohol_cigarette_use
FROM
`bigquery-public-data.samples.natality`
LIMIT
5
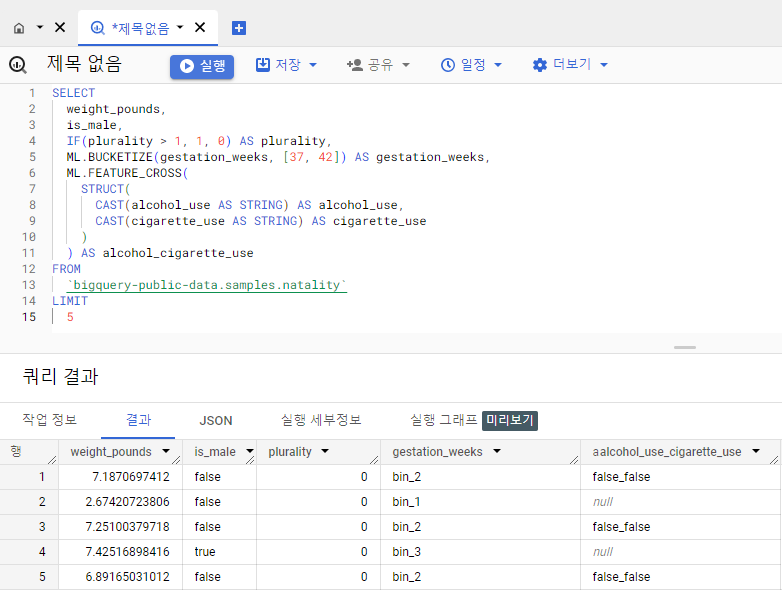
ML.BUCKETIZE
BUCKETIZE는 연속된 숫자 값을 미리 정의된 범위 또는 버킷 집합으로 분할하는 것을 말함. 특정 기준에 따라 연속된 데이터를 개별 범주로 변환하는 방법.
ex) 20세에서 60세 사이의 연령 컬럼이 있는 경우 세 가지 연령 그룹, 즉 "젊음" "중년" 및 "노인"으로 BUCKETIZE하려고 할 때, 범주를 [20, 40, 60]으로 정의할 수 있으며 ML.BUCKETIZE 함수는 이런 경계를 기반으로 각 연령 값을 적절한 버킷에 할당한다.
이 예시에선 [37, 42]의 범주를 BUCKETIZE 해서 gestation_weeks 열에 적용됨. 즉, gestation_weeks 값은 37보다 작거나 같은 값, 37보다 크고 42보다 작은 값, 42보다 큰 값의 세 가지 버킷으로 구분됨.
그 결과 출력에서 bin_1, bin_2 및 bin_3로 표시됨. 이 값들은 각각의 버킷을 나타내기 위해 BigQuery ML에 의해 자동으로 생성된 것.
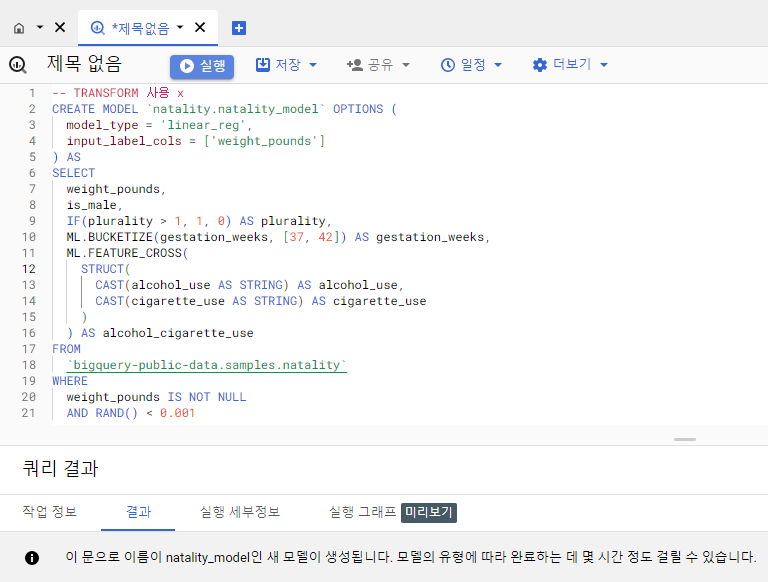
TRANSFORM 사용 X
위에서 수행한 전처리를 사용하여 모델 생성
CREATE MODEL `<데이터셋>.<모델>` OPTIONS (
model_type = 'linear_reg',
input_label_cols = ['weight_pounds']
) AS
SELECT
weight_pounds,
is_male,
IF(plurality > 1, 1, 0) AS plurality,
ML.BUCKETIZE(gestation_weeks, [37, 42]) AS gestation_weeks,
ML.FEATURE_CROSS(
STRUCT(
CAST(alcohol_use AS STRING) AS alcohol_use,
CAST(cigarette_use AS STRING) AS cigarette_use
)
) AS alcohol_cigarette_use
FROM
`bigquery-public-data.samples.natality`
WHERE
weight_pounds IS NOT NULL
AND RAND() < 0.001
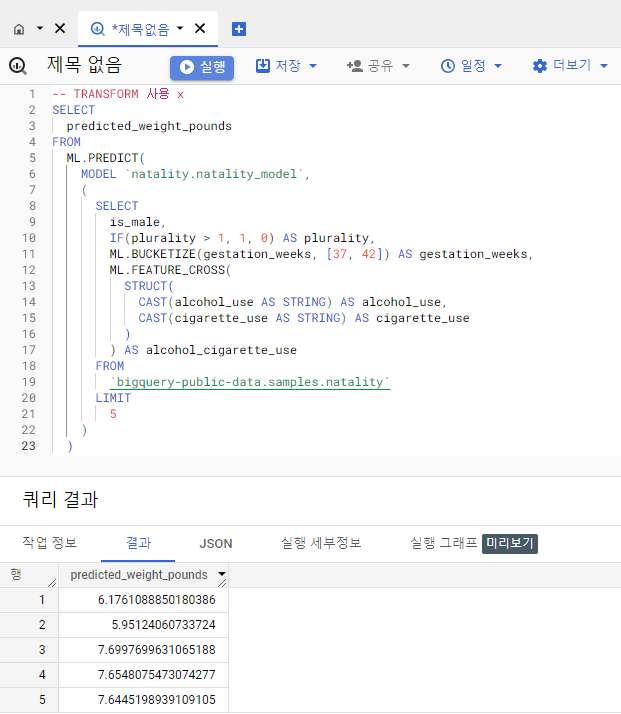
예측
SELECT
predicted_weight_pounds
FROM
ML.PREDICT(
MODEL `<데이터셋>.<모델>`,
(
SELECT
is_male,
IF(plurality > 1, 1, 0) AS plurality,
ML.BUCKETIZE(gestation_weeks, [37, 42]) AS gestation_weeks,
ML.FEATURE_CROSS(
STRUCT(
CAST(alcohol_use AS STRING) AS alcohol_use,
CAST(cigarette_use AS STRING) AS cigarette_use
)
) AS alcohol_cigarette_use
FROM
`bigquery-public-data.samples.natality`
LIMIT
5
)
)
TRANSFORM 사용 O
똑같이 실행
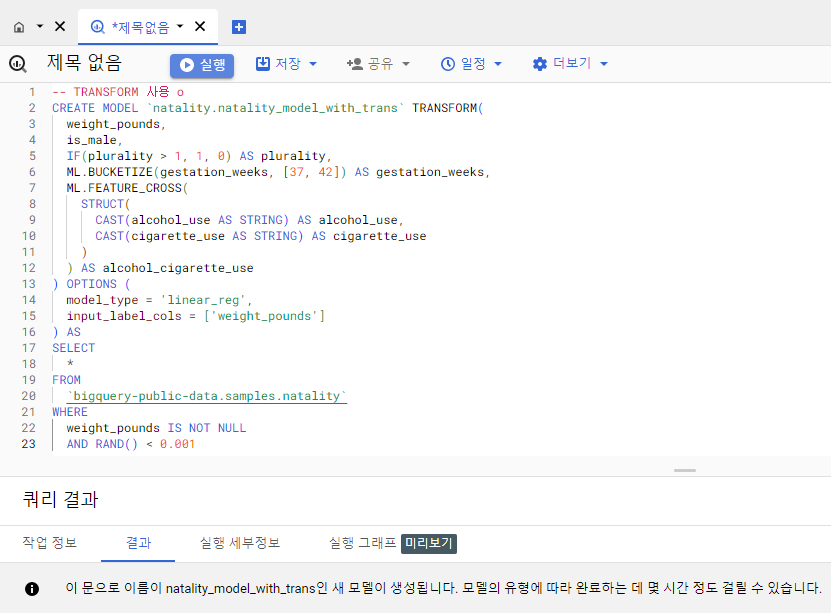
CREATE MODEL `<데이터셋>.<모델2>` TRANSFORM(
weight_pounds,
is_male,
IF(plurality > 1, 1, 0) AS plurality,
ML.BUCKETIZE(gestation_weeks, [37, 42]) AS gestation_weeks,
ML.FEATURE_CROSS(
STRUCT(
CAST(alcohol_use AS STRING) AS alcohol_use,
CAST(cigarette_use AS STRING) AS cigarette_use
)
) AS alcohol_cigarette_use
) OPTIONS (
model_type = 'linear_reg',
input_label_cols = ['weight_pounds']
) AS
SELECT
*
FROM
`bigquery-public-data.samples.natality`
WHERE
weight_pounds IS NOT NULL
AND RAND() < 0.001
예측
평가 및 예측시 전처리 자동화
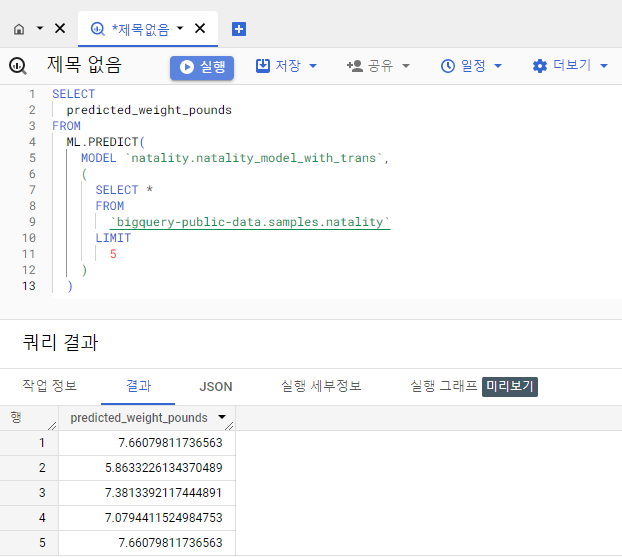
SELECT
predicted_weight_pounds
FROM
ML.PREDICT(
MODEL `<데이터셋>.<모델2>`,
(
SELECT *
FROM
`bigquery-public-data.samples.natality`
LIMIT
5
)
)
[BigQuery ML Regression model options 참고]
https://widekey6.tistory.com/24
[TRANSFORM 참고]
https://qiita.com/Hase8388/items/2b95533c491879f7719f#%E5%AD%A6%E7%BF%92transform%E5%8F%A5%E3%82%92%E4%BD%BF%E3%82%8F%E3%81%AA%E3%81%84
