레이원님의 Google STT API 사용방법 영상 참고
Google STT
STT란 Speech-to-text의 약자로 말 그대로 말하는 것(음성)을 문자(텍스트)로 바꿔주는 AI기술이다.
Google STT는 120개 이상의 언어를 지원하고 다국어 시나리오를 지원해야 할 경우 2~4개의 언어 코드를 명시할 수도 있다.
욕설 필터링 설정이 가능하고 자동 구두점 사용을 설정할 수 있다.
(자동 구두점 : 오디오 데이터에서 마침표, 쉼표, 물음표를 자동으로 유추하고 이를 스크립트에 추가)
콘텐츠 한도
| 콘텐츠 한도 | 오디오 길이 |
|---|---|
| 동기식 요청 (최대 10MB) | 최대 1분 초과시 로컬 파일은 사용 불가 Cloud Storage의 오디오 파일 참조 |
| 비동기식 요청 (제한 없음) | 최대 480분 |
| 스트리밍 요청 | 최대 5분 초과시 지속적인 스트리밍 가이드 참조 |
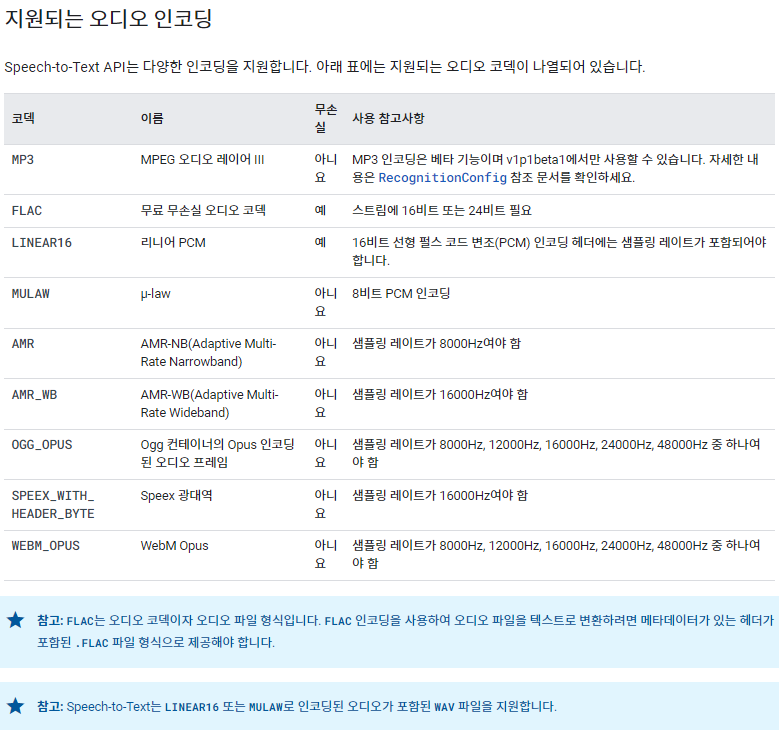
지원되는 오디오 인코딩
권장 형식은 무손실 압축 코덱인 FLAC, LINEAR16
환경 구성
작업 환경 : 로컬 PC(Windows 11)
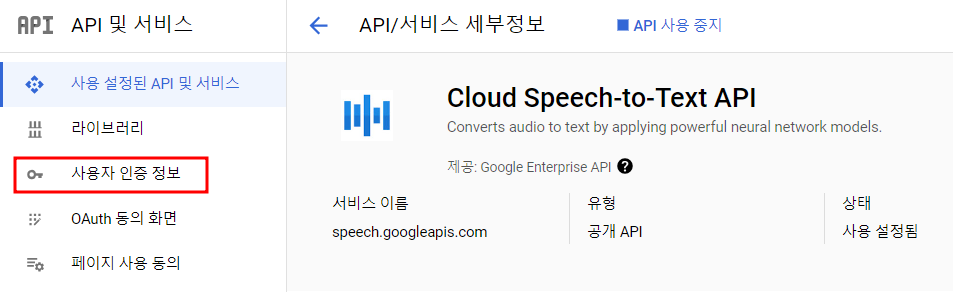
Google Cloud 콘솔에서 Cloud Speech-to-text API를 검색한 후 API를 활성화해준다.

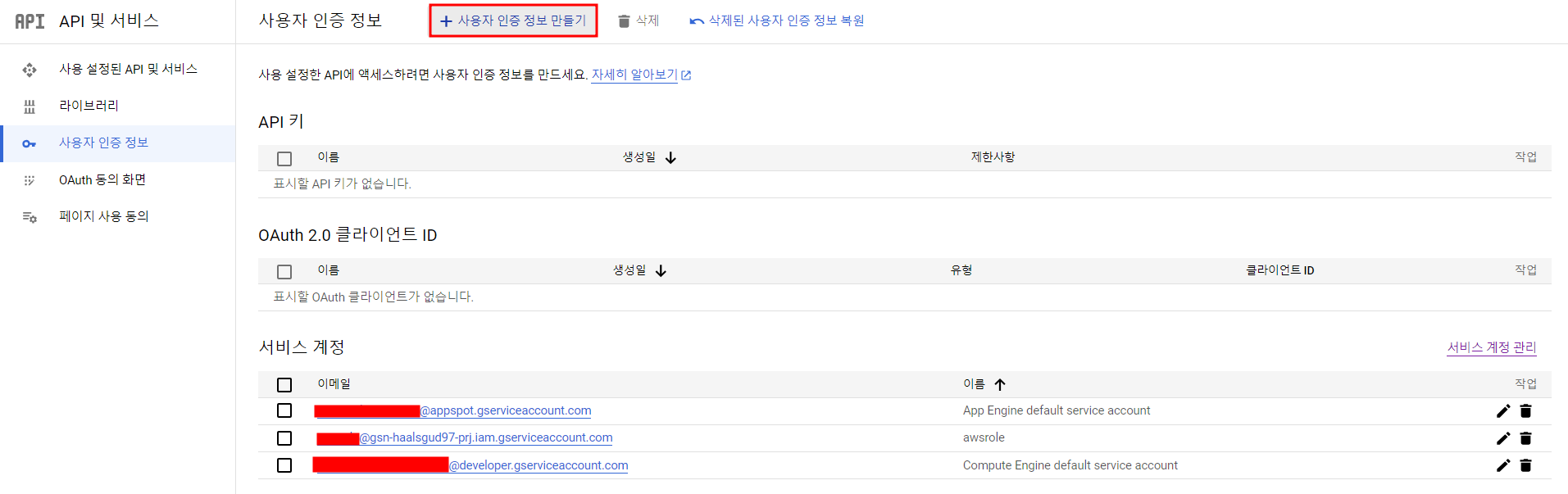
나같은 경우 이미 권한이 부여되어 있는 서비스 계정이 있지만 Google Cloud가 처음이라면 '사용자 인증정보'를 클릭하여 소유자 권한을 부여한 서비스 계정을 하나 생성한 후 JSON 형식의 키를 다운받아야 한다.
gcloud 설치
PowerShell에서 아래 명령어 실행
(New-Object Net.WebClient).DownloadFile("https://dl.google.com/dl/cloudsdk/channels/rapid/GoogleCloudSDKInstaller.exe", "$env:Temp\GoogleCloudSDKInstaller.exe")
& $env:Temp\GoogleCloudSDKInstaller.exe
서비스 계정 키 등록 및 활성화
set GOOGLE_APPLICATION_CREDENTIALS=<키 파일 경로>
gcloud auth activate-service-account --key-file=<키 파일 경로>위의 set GOOGLE_APPLICATION_CREDINTIALS 설정은 터미널이 한 번 종료되면 나중에 작업할 때 다시 설정해줘야 한다. 만약 이 과정이 귀찮다면 아래와 같이 시스템 환경 변수에 등록해주는 방법도 있음.
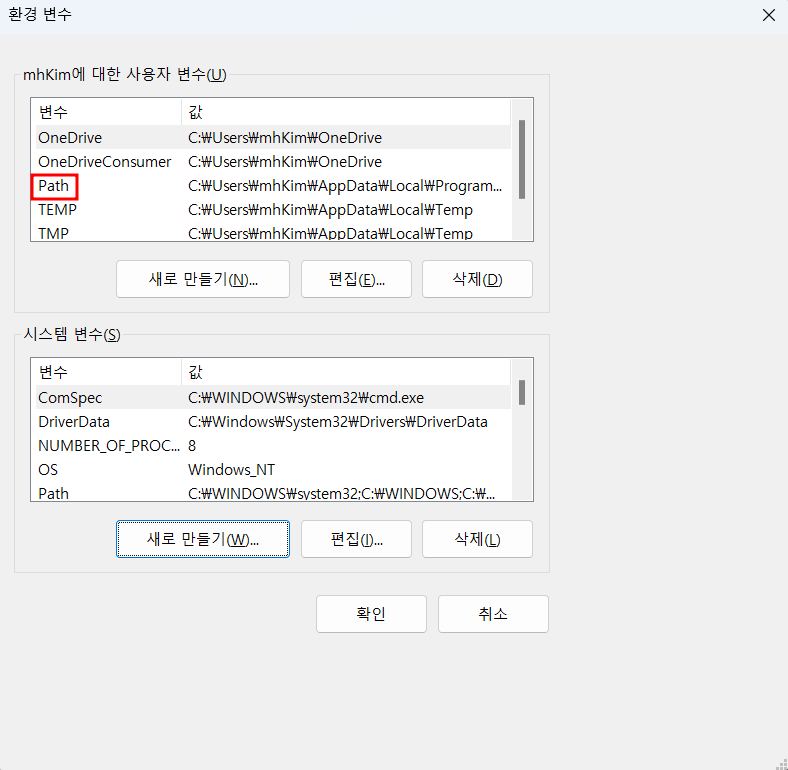
시스템 > 고급 시스템 설정

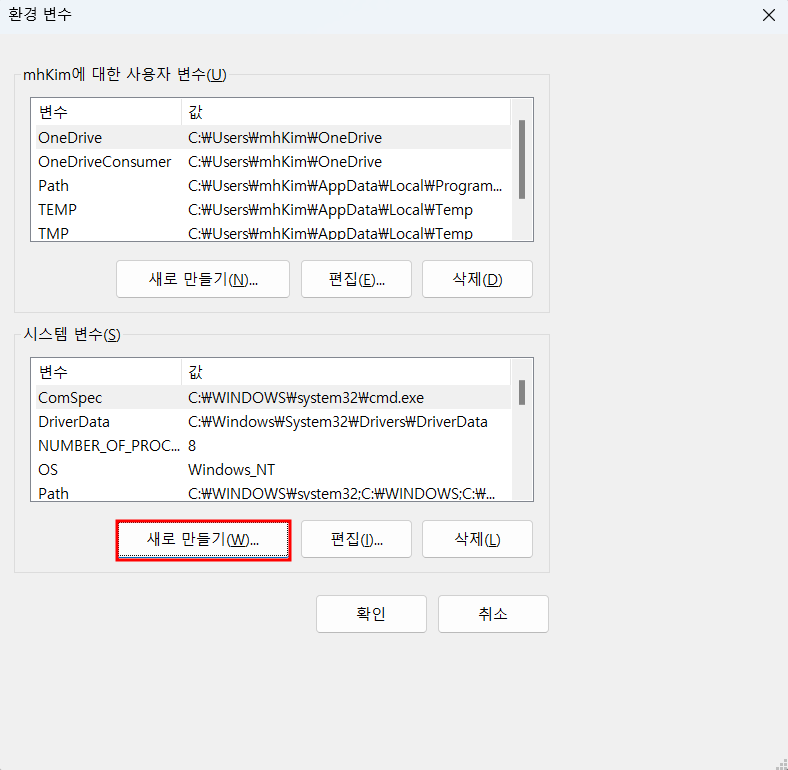
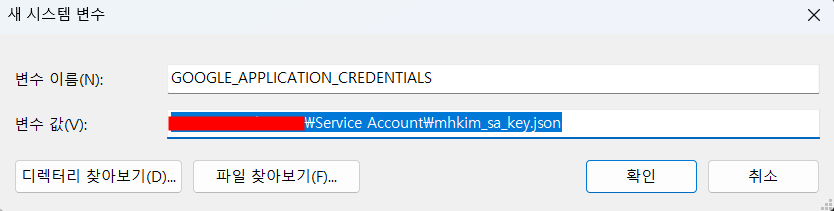
(파이썬이 설치되어 있다고 가정)
파이썬 가상환경 생성 및 활성화
python -m venv <가상환경 이름>
cd <가상환경 이름>/Scripts
activate필요 패키지 설치
pip install google-cloud-storage
pip install google-cloud-speech
pip install SpeechRecognition
pip install PyAudioDevice 스피커 인식
첫 번째 코드부터 실행해볼 것이다.
첫 번째 코드는 device의 스피커에서 내가 말하는 걸 인식하여 그대로 출력해주는 것이다.
첫 번째 코드 수정 부분
# google-cloud-speech가 2.0.0으로 업그레이드 되면서 이제 더이상 enums, types를 사용하지 않는다. speech로 모두 대체됨
from google.cloud import speech
# from google.cloud.speech import enums
# from google.cloud.speech import types
...
# main 함수에서 types와 enums로 들어가있던 부분 모두 speech로 변경
def main():
# See http://g.co/cloud/speech/docs/languages
# for a list of supported languages.
language_code = 'ko-KR' # a BCP-47 language tag
client = speech.SpeechClient()
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=RATE,
language_code=language_code)
streaming_config = speech.StreamingRecognitionConfig(
config=config,
interim_results=True)
with MicrophoneStream(RATE, CHUNK) as stream:
audio_generator = stream.generator()
requests = (speech.StreamingRecognizeRequest(audio_content=content)
for content in audio_generator)
responses = client.streaming_recognize(streaming_config, requests)
# Now, put the transcription responses to use.
listen_print_loop(responses)코드 실행
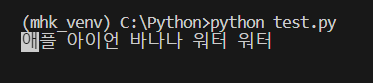
음성 파일 인식
두 번째 코드를 실행하기 전에 몇 가지 작업해줘야 할 것이 있다.
1. 녹음 파일 준비
2. wav 형식으로 변경 및 녹음 파일의 sample_rate_hertz를 코드와 동일하게 설정
sample_rate_hertz란 모든 메시지에서 전송된 오디오 데이터의 헤르츠 단위 샘플링 속도를 의미하고 유효한 값은 8000-48000.
16000이 최적의 값이고 최상의 결과를 얻으려면 오디오 소스의 샘플링 속도를 16000Hz로 설정하는 것이 권장사항이다. 때문에 위에서 실행했던 코드와 아래 코드에 smaple_rate_hertz도 16000으로 설정되어 있을 것인데 이를 위해 녹음 파일의 sample_rate_hertz를 16000으로 변환해줄 것이다.
난 유튜브로 내가 듣고 있던 노래를 핸드폰으로 녹음했다.
하지만 이 파일은 wav 형식으로 변환해도 그대로 쓰면 코드의 sample_rate_hertz와 맞지 않을 것이다.
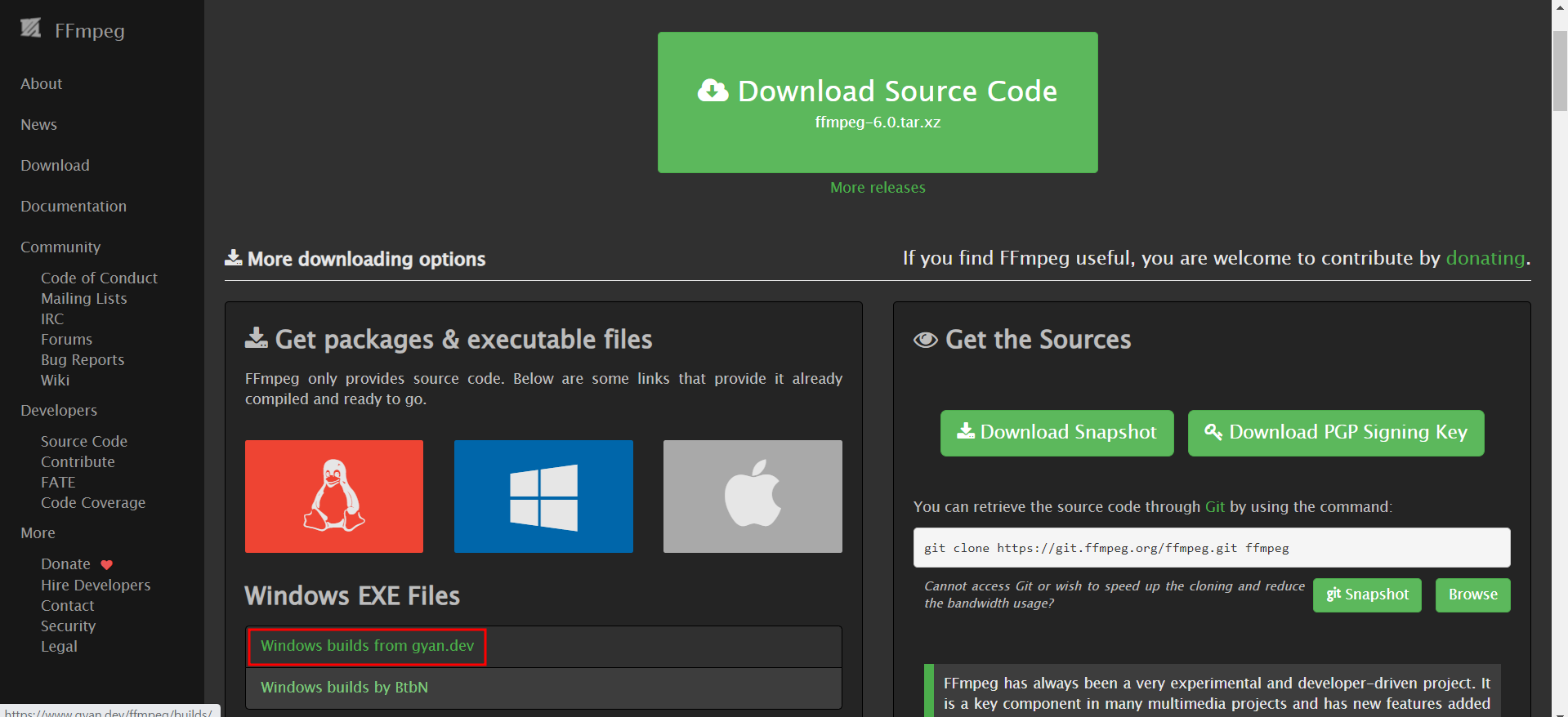
ffmpeg를 사용하여 변경해줄 수 있다.
ffmpeg 다운로드

7z 파일 압축 해제를 위한 반디집 설치
반디집 다운로드
반디집을 사용하여 압축 해제
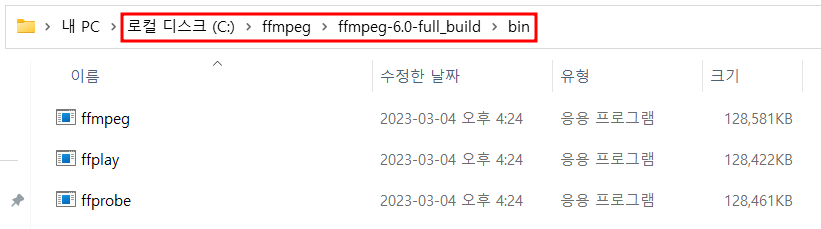
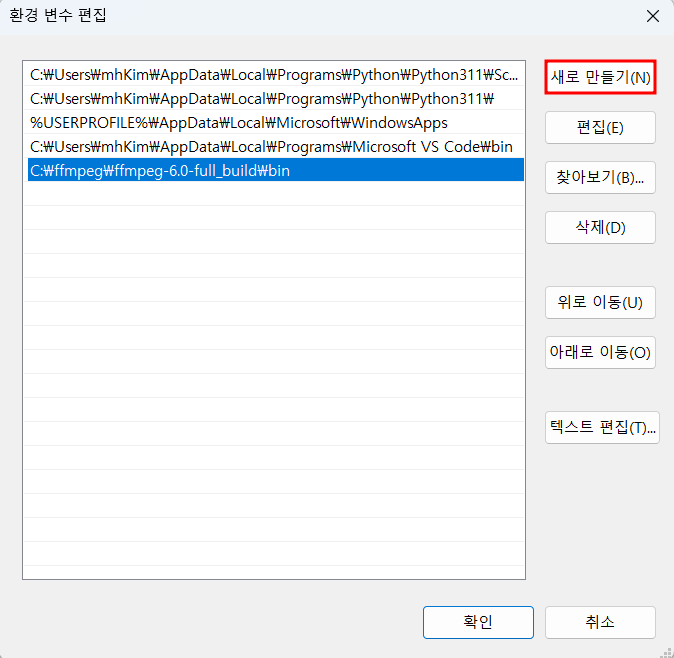
압축 해제한 경로를 환경 변수에 등록
시스템 > 고급 시스템 설정 > 환경 변수
Powershell에서 아래 명령어를 사용하여 변환
ffmpeg -i <기존 파일 이름>.mp4 -acodec pcm_s16le -ac 1 -ar 16000 <바꿀 파일 이름>.wav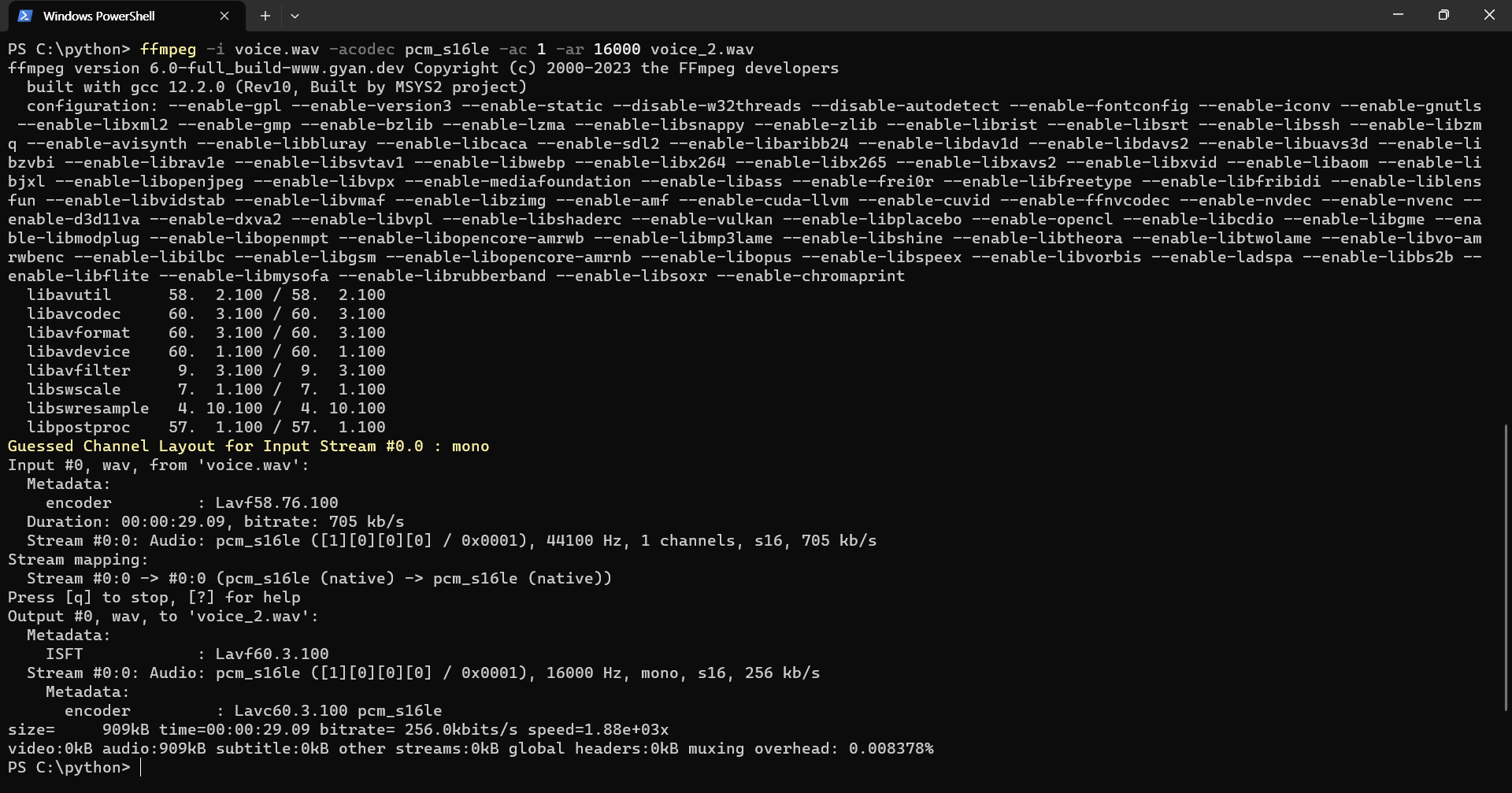
두 번째 코드 수정 부분
# google-cloud-speech가 2.0.0으로 업그레이드 되면서 이제 더이상 enums, types를 사용하지 않는다. speech로 모두 대체됨
from google.cloud import speech
# from google.cloud.speech import enums
# from google.cloud.speech import types
...
# types와 enums로 들어가있던 부분 모두 speech로 변경
with io.open(file_name, 'rb') as audio_file:
content = audio_file.read()
audio = speech.RecognitionAudio(content=content)
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=16000,
language_code='ko-KR')
...
# response = client.recognize(config, audio) 이부분에서 에러가 날 경우 아래와 같이 수정
response = client.recognize(
request={"config": config, "audio": audio}
)
변환한 wav 파일을 넣어주고 코드 실행

노트북으로 듣고 있던 노래를 휴대폰으로 녹음했었던 건데 인식률이 아주 높다..
[Google STT API 사용해보기 참고]
https://www.youtube.com/watch?v=Ds-7D8d-FwA&list=PLK4RQ-UUydTc9p79pc22ZAqsg3nujF0bd
[Google STT API 지원 인코딩]
https://cloud.google.com/speech-to-text/docs/encoding?hl=ko
[Google STT API 사용방법 트러블 슈팅 참고]
https://velog.io/@yesjiyoung/google-cloud-speech-SST-errors
[sample_rate_hertz 변환 참고]
https://vhrehfdl.tistory.com/25
[Google STT request 트러블 슈팅 참고]
https://stackoverflow.com/questions/64677600/problems-with-google-cloud-speech-to-text-api
