BigQuery Vector Search를 사용한 이미지 검색 애플리케이션 구현
GCP - AI,ML
BigQuery Vector Search란?
위의 포스팅에서 알 수 있듯이 전에 BigQuery에서 RAG를 직접 구현하는 법을 알아보았었다.
이때는 임베딩 후에 유사도 검색을 위해 직접 클러스터링 모델을 생성하여 유사한 클러스터 및 Datapoint를 추출해봤다.
하지만 BigQuery에서 벡터 검색이 내장 함수로 간편하게 지원이 된다.
써봐야지~ 하고선 다른 일들 때문에 지금에야 써본다..
아키텍처
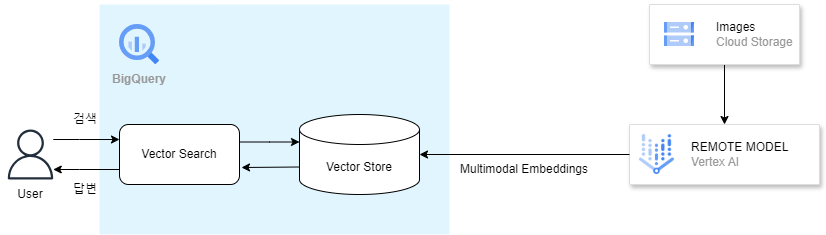
BigLake 기능이 예전에 출시되고 객체 테이블 생성이 가능해졌다.
때문에 이미지 데이터를 기반으로 BigQuery에 객체 테이블을 생성하고, 해당 이미지들을 임베딩한 임베딩 테이블을 만든 뒤, 임베딩 테이블에서 유사도 검색을 수행해볼 것이다.
데이터 세트 준비
kaggle에 있는 데이터 셋 활용
사용할 데이터
Fashion Product Images(Small)
Small이라더만 로컬에 다운받은 후에 압축을 푸는데 한 세월이 걸려서.. 도중에 사용하고 있던 Jupyter Notebook이 있었는데 그 VM에서 다운받고 압축을 풀어주었다;;
kaggle CLI 사용
kaggle python 패키지를 설치하고 kaggle Public API에 나와있는 대로 계정에 대한 토큰 파일을 생성해준다.
다운받은 json파일을 위의 링크에 안내되어 있는 것처럼 Linux 및 기타 UNIX 기반 운영체제, Windows등에 따라서 올바른 경로에 넣어주자.
내 Jupyteer Notebook의 경우 /home/jupyter/.config/kaggle/에 넣어줬어야 했다.
또한 해당 파일을 통해 인증을 수행할 수 있게 적절한 권한도 부여해줘야 한다.
# Kaggle CLI 사용 전 세팅
pip install kaggle
mv kaggle.json /home/jupyter/.config/kaggle/
chmod 600 /home/jupyter/.config/kaggle/kaggle.json
# Dataset 다운 및 압축 해제
kaggle datasets download -d paramaggarwal/fashion-product-images-small
unzip fashion-product-images-small.zip -d ./<압축 해제할 폴더>/Cloud Storage에 업로드
주의할 점
1. 이미지가 꽤많다.. -m 옵션(Multithread)을 꼭 사용하여 업로드 해주자!
2. 참고로 다운받은 압축 파일 안에 myntradataset 폴더는 삭제해도 된다.(images와 styles.csv가 들어가 있으므로 중복됨.)
gsutil -m cp -r <이미지 파일 경로>/* gs://<버킷명>/<폴더명>/이미지 임베딩
BigQuery Studio의 탐색기 옆에 +추가를 눌러서 외부 데이터 소스 - Vertex AI의 원격 모델, 원격 함수, BigLake와의 연결을 생성해준다.
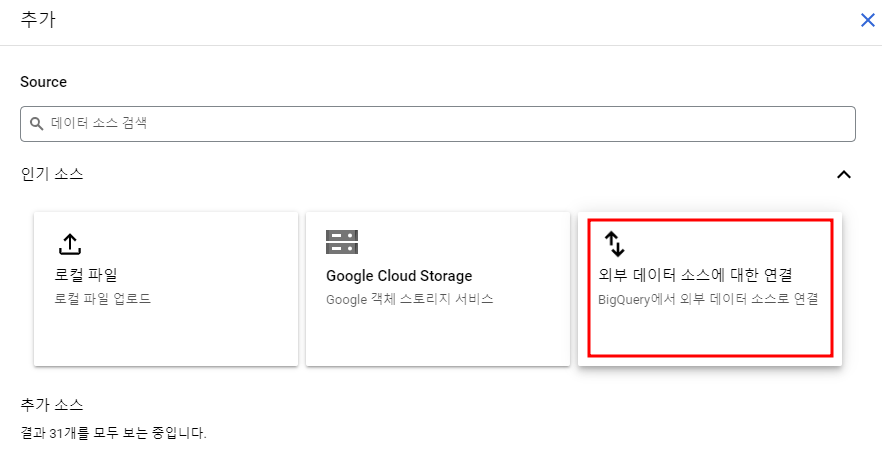
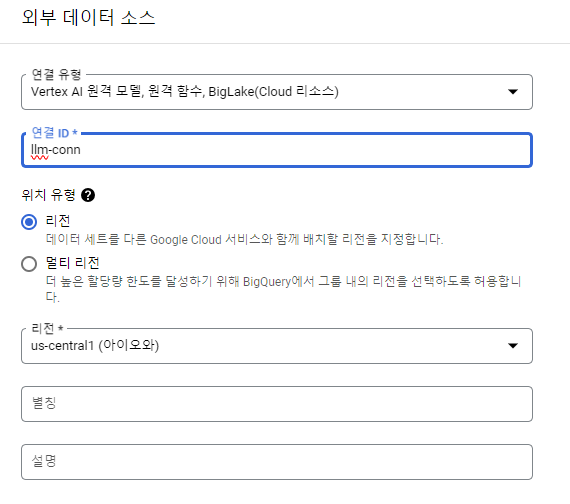
객체 테이블 생성
객체 테이블 생성을 하려면 연결 ID가 필요하다. 이때 위에서 생성해준 연결 ID를 사용하여 객체 테이블을 생성할 수 있다.
여기서 쓰이는 개념이 BigLake이다. BigLake는 BigQuery의 기능을 데이터 레이크까지 확장하여 Cloud Storage에 저장된 데이터를 BigQuery에 네이티브인 것처럼 쿼리할 수 있게 해준다.
CREATE OR REPLACE EXTERNAL TABLE `<프로젝트명>.<데이터 세트>.<테이블>`
WITH CONNECTION `<프로젝트명>.us.<연결 ID>`
OPTIONS
( object_metadata = 'SIMPLE',
uris = ['gs://<버킷명>/images/*']
);테이블 확인
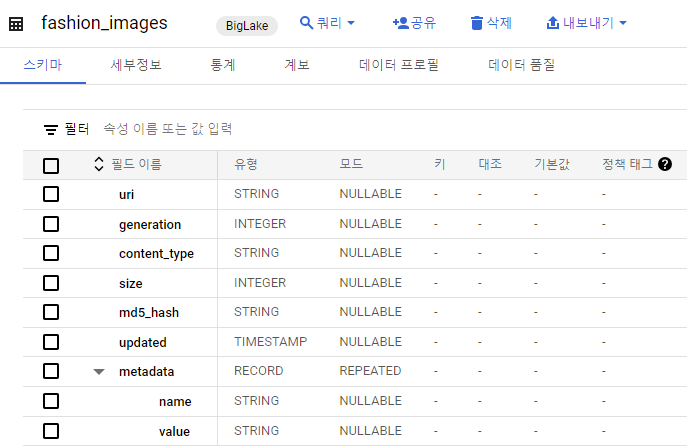
BigQuery에서 원격 모델 설정
CREATE OR REPLACE MODEL `<프로젝트명>.<데이터 세트>.<모델명>`
REMOTE WITH CONNECTION `<프로젝트명>.us.<연결 ID>`
OPTIONS (ENDPOINT = 'multimodalembedding@001');Vertex AI의 multimodalembedding 모델이 경우 1408차원 벡터를 생성 합니다.
여기에는 이미지와 텍스트 데이터의 조합이 포함될 수 있고,
이러한 임베딩 벡터는 텍스트로 이미지 검색 or 그 반대로 하는 것과 같은 다양한 사례에 상호 교환하여 사용이 가능합니다.
임베딩 테이블 생성
여기선 테스트 목적이므로 5000개만 임베딩할 것이다. 실제 해당 이미지를 전부 임베딩하려면 몇 시간 이상이 소요될 수도 있다.
CREATE OR REPLACE TABLE `<프로젝트명>.<데이터 세트>.<임베딩 테이블>`
AS
SELECT *
FROM ML.GENERATE_EMBEDDING(
MODEL `<프로젝트명>.<데이터 세트>.<모델명>`,
(SELECT * FROM `<프로젝트명>.<데이터 세트>.<테이블>` limit 5000)
);BigQuery가 해당 작업을 실행하는데 사용되는 서비스 계정에 권한이 없다고 에러가 날 수도 있다. 아래처럼 에러가 발생할 경우 해당 서비스 계정에 Storage에 대한 권한을 부여해주자.

5000개 이미지 임베딩 하는데 10분 미만이 걸렸다.
유사도 검색
WITH query_embedding AS (
SELECT ml_generate_embedding_result AS embedding
FROM (
SELECT * FROM ML.GENERATE_EMBEDDING(
MODEL `<프로젝트명>.<데이터 세트>.<모델명>`,
(
SELECT '<자연어 기반 사용자 쿼리>' AS content
)
)
)
)
SELECT
base.uri,
(1 - distance) AS similarity_score
FROM
VECTOR_SEARCH(
TABLE `<프로젝트명>.<데이터 세트>.<임베딩 테이블>`,
'ml_generate_embedding_result',
(SELECT embedding FROM query_embedding),
top_k => 5,
distance_type => 'COSINE'
);- 텍스트 쿼리에 대한 임베딩을 선택.
- VECTOR_SEARCH 함수를 사용하여 간편하게 임베딩 테이블에서 유사한 이미지 검색.
- ml_generate_embedding_result열(이미지 임베딩)을 기준으로 검색
- 코사인 유사도를 사용하여 가장 유사한 상위 5개 결과 반환.
- 각 결과에 대한 이미지 URI와 유사도 점수 제공.
유사도 점수는 '(1 - distance)'로 계산되며, 코사인 거리를 유사도 측정값으로 변환하여 점수가 높을수록 유사도가 높다는 것을 나타냅니다.
여기선 꽃무늬 패턴의 빨간 드레스를 찾아달라고 했었고 아래의 uri들을 가져왔다.
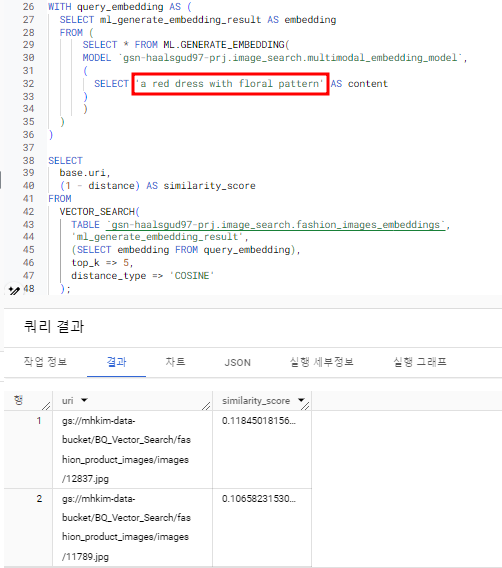
다운받아 확인해보니 나름 잘 가져오는듯 보인다.
top-k 를 5로 설정하여 상위 5개의 이미지를 가져왔고, 가장 상위의 2개 이미지를 보면 아래와 같다.
결과
123837.jpg

11789.jpg

[BigQuery Vector Search를 활용한 이미지 검색 애플리케이션 구현 참고]
https://medium.com/data-on-cloud-genai-data-science-and-data/bigquery-powered-natural-language-image-search-multimodal-embeddings-within-sql-environment-a9d230a4ffb5

4개의 댓글

It was a pleasure to meet you. Thank you for your time and consideration. Where are you working?? i'm working on AI in the india.. across your blog by chance. nice to meet you.
hi bro