Vertex AI Embeddings와 Vector Search를 사용한 영화 추천 애플리케이션 구현
GCP - AI,ML
이전 Vertex AI Multimodal Embeddings와 Vector Search를 사용한 이미지 검색 애플리케이션 구현 포스트에서 Vertex AI Multimodal Embeddings와 Vector Search를 사용해보았다.
하지만 사실 Vector Search가 출시된지 얼마 안된 시점이었고, 다른 블로거의 코드를 거의 그대로 사용하여 테스트 해보았는데 코드 자체도.. 결과도.. 미흡한 점이 좀 있었음..
그래서 Vector Search를 한 번 더! 사용해보고자 했고.. 이번엔 LangChain을 활용하여 코드를 상당 부분 간소화 하여 구현하였다.
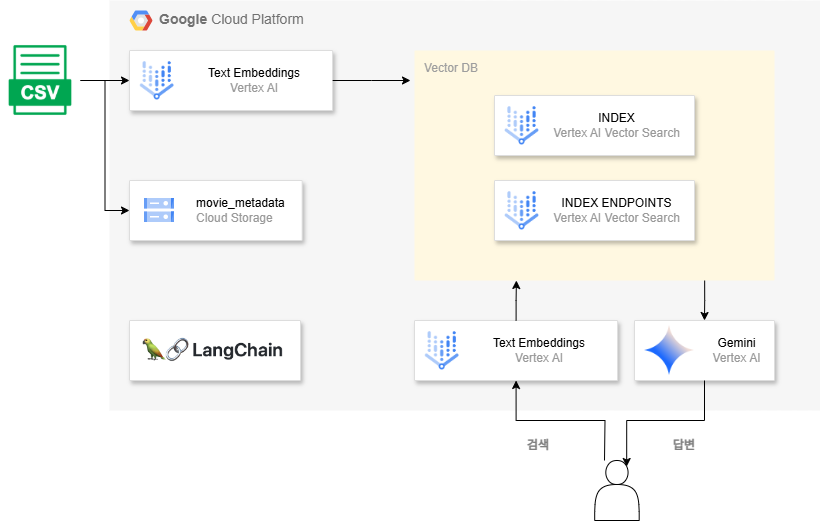
Workflow
1. CSV 데이터 전처리.
2. Cloud Storage에 개별 데이터(영화)마다 txt파일로 저장.
3. Vertex AI Embeddings를 활용해 임베딩 값 생성 후, 벡터 DB(Vertex AI Vector Search)에 저장.
4. 사용자 질문에 대해 Vertex AI Embeddings를 사용해 임베딩하여 Vector Search의 datapoints들과 유사도를 측정하여 가장 관련성 높은 결과를 반환.
5. LLM을 사용하여 결과값들을 요약 후 답변.
데이터 세트 준비
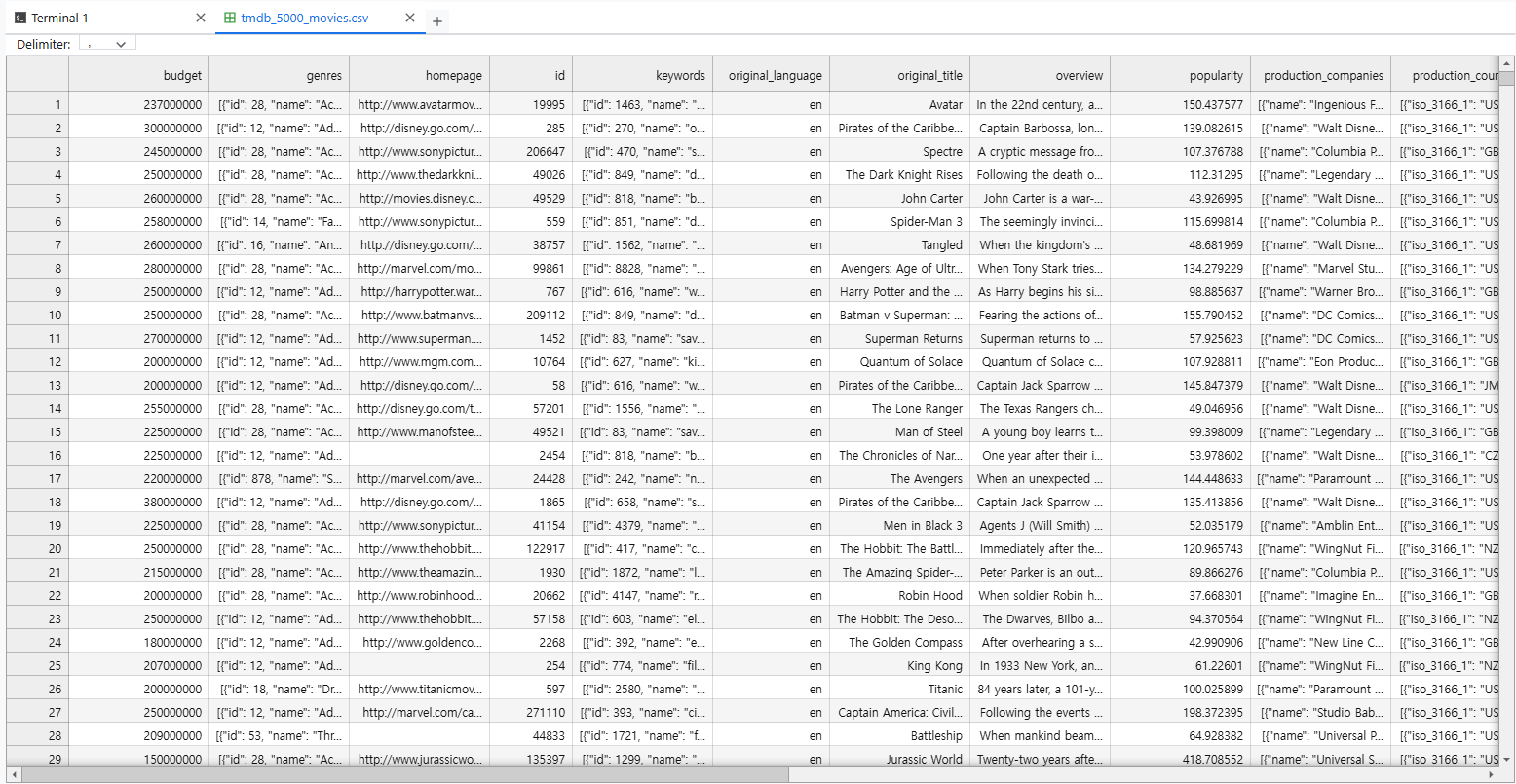
kaggle에 있는 데이터 셋 활용
TMDB 5000 Movie Dataset
movie_dataset
데이터 전처리
임베딩이 가능하도록, 필요한 데이터만 남겨두도록 전처리
import csv
output = []
"""
Vertex AI Embeddings을 사용하여 임베딩 하려면 List[str]여야 함.
하지만 이 CSV는 일부 열이 리스트나 dictionary 형식으로 되어 있으므로 수정 필요.
"""
with open("./source/tmdb_5000_movies.csv", 'r', encoding='utf-8') as f:
csv_reader = csv.reader(f)
header = next(csv_reader)
for row in csv_reader:
homepage = row[2].strip()
id = row[3].strip()
original_title = row[6].replace(',',' ').strip()
overview = row[7].replace(',',' ').strip()
release_date = row[11].strip()
output.append([id, original_title, homepage, overview, release_date])
with open("./source/tmdb_5000_movies_modified.csv", 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(['id', 'title', 'homepage', 'overview', 'release_date'])
for item in output:
writer.writerow(item)movie_dataset_modified
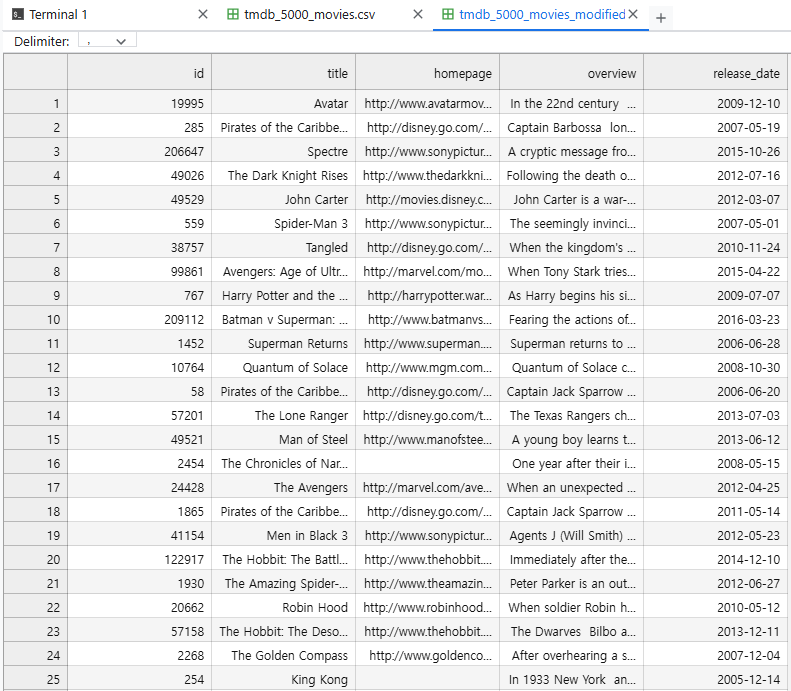
CSV Load 및 Cloud Stoarge에 업로드
CSV Load
LangChain 사용
from langchain_community.document_loaders import CSVLoader
# Load movie metadata from CSV
loader = CSVLoader(
file_path='./source/tmdb_5000_movies_modified.csv',
csv_args={'delimiter': ','}
)
documents = loader.load()documents에서 첫 번째 데이터 만 출력해보면 아래처럼 나온다.

이 데이터들을 개별로 Cloud Storage에 저장!!
Save to Cloud Storage
from google.cloud import storage
# Upload each document as a .txt file to GCS
storage_client = storage.Client()
bucket = storage_client.bucket(BUCKET_NAME)
for idx, document in enumerate(documents):
# Create file name and content
file_name = f"movie_{idx}.txt"
file_path = FOLDER_PATH + file_name
content = document.page_content # Extract the page content
# Create a new blob in the GCS bucket
blob = bucket.blob(file_path)
blob.upload_from_string(content, content_type="text/plain")
print("All files uploaded successfully!")텍스트 임베딩
여기서도 LangChain을 사용하여 간편하게 임베딩 데이터를 생성했다.
임베딩 파일은 JSON형식으로 아래와 같은 형식이어야 하고 이걸 Cloud Storage에 업로드해야 한다.
{"id": "<id>", "embedding": [<벡터 값>]}
Cloud Storage에 업로드하는 이유는 이 임베딩 파일이 업로드된 Cloud Storage 경로를 포함한 DB 스펙을 지정한 메타데이터 파일을 갖고 인덱스를 생성할 수 있기 때문이다.
임베딩 파일 생성
from langchain_google_vertexai import VertexAIEmbeddings
import json
# Initialize the Embeddings Model
embeddings = VertexAIEmbeddings(model_name="text-embedding-004")
# Open the output JSON file in write mode
with open('./source/indexData.json', 'w', encoding='utf-8') as f:
# Loop through each document in the 'documents' list
for idx, doc in enumerate(documents):
vector = embeddings.embed_documents([doc.page_content])
embedding_entry = {
"id": f"movie_{idx}",
"embedding": vector[0]
}
# Write each JSON object on a new line
f.write(json.dumps(embedding_entry, ensure_ascii=False) + "\n")
print(f"Total {len(documents)} documents processed and saved to indexData.json")인덱스 생성 및 배포
여기선 LangChain이 아닌 그냥 gcloud cli를 사용했다.
LangChain에서도 지원하지만 사실 콘솔로도 이젠 배포가 가능해졌고, 원래도 gcloud cli로 매우 편하게 생성이 가능하기 때문.
메타데이터 파일 생성
아래의 json 파일을 갖고 생성해줄 것이다.
Vertex AI의 Text Embeddings 모델인 text-embedding-gecko에선 768차원의 벡터를 지원하므로 DB 스펙에서도 차원을 꼭!! 768로 맞춰주어야 한다.
{
"contentsDeltaUri": "gs://<임베딩 파일이 있는 폴더 경로>",
"config": {
"dimensions": 768,
"approximateNeighborsCount": 30,
"distanceMeasureType": "DOT_PRODUCT_DISTANCE",
"shardSize": "SHARD_SIZE_SMALL",
"algorithm_config": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 5000,
"leafNodesToSearchPercent": 1
}
}
}
}인덱스 생성
gcloud ai indexes create \
--metadata-file=<메타데이터 파일 경로> \
--display-name=<인덱스 이름 지정> \
--region=<리전> \
--project=<프로젝트 ID>인덱스 엔드포인트 생성
gcloud ai index-endpoints create \
--display-name=<인덱스 엔드포인트 이름 지정> \
--public-endpoint-enabled \
--region=<리전> \
--project=<프로젝트 ID>인덱스를 엔드포인트에 배포
gcloud ai index-endpoints deploy-index <인덱스 엔드포인트 ID> \
--deployed-index-id=<배포되는 인덱스 ID 지정> \
--display-name=<배포되는 인덱스 이름 지정> \
--index=<인덱스 ID> \
--region=<리전> \
--project=<프로젝트 ID>검색
여기서 사용자 질문에 대한 임베딩은 LangChain을 활용하여 코드를 매우 간소화 했지만 검색은 Vertex AI SDK를 활용하였다.
이유는 이슈사항에서 확인 가능..!
question = "Recommend an action movie!"
from google.cloud import aiplatform_v1
query_datapoint = embeddings.embed_query(question)
# Set variables for the current deployed index.
API_ENDPOINT="<API 엔드포인트>"
INDEX_ENDPOINT="<인덱스 엔드포인트>"
DEPLOYED_INDEX_ID="<배포된 인덱스 ID>"
# Configure Vector Search client
client_options = {
"api_endpoint": API_ENDPOINT
}
vector_search_client = aiplatform_v1.MatchServiceClient(
client_options=client_options,
)
# Build FindNeighborsRequest object
datapoint = aiplatform_v1.IndexDatapoint(
feature_vector=query_datapoint
)
query = aiplatform_v1.FindNeighborsRequest.Query(
datapoint=datapoint,
# The number of nearest neighbors to be retrieved
neighbor_count=3
)
request = aiplatform_v1.FindNeighborsRequest(
index_endpoint=INDEX_ENDPOINT,
deployed_index_id=DEPLOYED_INDEX_ID,
# Request can have multiple queries
queries=[query],
return_full_datapoint=False,
)
# Execute the request
response = vector_search_client.find_neighbors(request)
# Handle the response
print(response)neighbor_count=3은 가장 가까운 즉, 가장 유사한 값 3개를 return 한다는 뜻.
(LangChain 추가 정보)
- embed_query: 단일 텍스트에 대한 임베딩 벡터를 반환 (1D(1차원) 리스트).
query_embedding = [0.1, -0.2, 0.3, 0.5]- embed_documents: 여러 텍스트에 대한 임베딩 벡터를 반환 (리스트의 리스트).
document_embeddings = [
[0.1, -0.2, 0.3, 0.5], # 첫 번째 문장의 벡터
[0.2, 0.4, -0.1, 0.6] # 두 번째 문장의 벡터
]만약 question이 단일 문장이 아니라 여러 문장으로 이루어진 경우, 각각에 대해 embed_documents를 사용한 뒤 벡터를 별도로 처리해야 한다.
출력 형식

답변 생성
결과값에서 datapoint_id들을 따로 추출하여 <datapoint_id>.txt 파일의 내용을 Cloud Storage에서 불러온다.
# Cloud Storage 경로 정보
bucket_name = "<버킷명>"
base_path = "<경로>"
# Cloud Storage에서 파일 내용을 가져오는 함수
def get_file_content_from_gcs(bucket_name, file_path):
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_path)
if not blob.exists():
raise FileNotFoundError(f"The file {file_path} does not exist in the bucket {bucket_name}.")
return blob.download_as_string().decode("utf-8")
# Response에서 datapoint_id 추출
def extract_datapoint_ids(response):
datapoint_ids = []
for neighbor in response.nearest_neighbors[0].neighbors:
datapoint_ids.append(neighbor.datapoint.datapoint_id)
return datapoint_ids
# 유사도 검색 결과에 해당되는 영화의 내용들을 리스트에 담기
def fetch_files_from_gcs(bucket_name, base_path, datapoint_ids):
all_contents = []
for datapoint_id in datapoint_ids:
file_path = f"{base_path}{datapoint_id}.txt"
try:
content = get_file_content_from_gcs(bucket_name, file_path)
all_contents.append(content)
except FileNotFoundError as e:
print(e)
return all_contents
datapoint_ids = extract_datapoint_ids(response)
print(f"Extracted datapoint_ids: {datapoint_ids}")
file_contents = fetch_files_from_gcs(bucket_name, base_path, datapoint_ids)프롬프트 엔지니어링
prompt = f"""
You're a movie recommendation assistant that delivers information based on movie recommendations in response to user questions.
The information about the recommended movies is in MOVIE_LISTS.
In MOVIE_LISTS, 'title' is required to be provided to the user, and 'homepage' is also provided if it exists.
Answers must be generated in Korean.
USER_QUESTION:
{question}
MOVIE_LISTS:
{file_contents}
"""결과
LangChain을 활용하여 Gemini 호출
from langchain_google_vertexai import VertexAI
from IPython.display import display, Markdown
model = VertexAI(model_name="gemini-1.5-pro-002")
display(Markdown(model.invoke(prompt)))
이슈사항
검색 부분까지 마찬가지로 모두 LangChain 기반으로 구현하기 위해 LangChain - Google Vertex AI Vector Search이 가이드를 활용하여 인덱스를 vectorstore로 만들어서 검색을 구현하고자 했다.
가이드의 예재 코드
from langchain_google_vertexai import (
VectorSearchVectorStore,
VectorSearchVectorStoreDatastore,
)
vector_store = VectorSearchVectorStore.from_components(
project_id=PROJECT_ID,
region=REGION,
gcs_bucket_name=BUCKET,
index_id=INDEX_ID,
endpoint_id=ENDPOINT_ID,
embedding=embeddings,
)
result = vector_store.similarity_search(question)
print(result)하지만 결과를 보면 관련 영화는 잘 가져오지만 storage에 해당 documents를 찾을 수 없다는 에러가 발생한다.

Vector Search의 이전 이름인 Matching Engine 라이브러리(구 버전 라이브러리)를 사용하여 검색했을 때도 비슷한 에러 발생.

- VectorSearchVectorStore 라이브러리: 버킷 밑에 datapoint id와 동일한 이름의 문서가 있어야 하는 것으로 보임.
- Matching Engine 라이브러리: 버킷/documents/ 폴더 밑에 datapoint id와 동일한 이름의 문서가 있어야 함.
하지만 난 Save to Cloud Storage 부분 코드에서 보면 알다시피 내가 지정한 폴더 밑에 영화 데이터를 저장해놓았고, 내가 지정한 id 값으로 임베딩 파일을 전처리하여 업로드 해놓았었다.
데이터를 LangChain에서 요구하는 형식이 아닌, 사용자 지정 id 값으로, 사용자 지정 폴더 구조 시스템으로 구축 및 관리해야하는 경우라면 검색은 Vertex AI SDK를 사용하는 것이 나을 것으로 생각된다.
[Vertex AI Embeddings와 Vector Search를 사용한 영화 추천 애플리케이션 구현 참고]
https://qiita.com/KI1208/items/b9601f063ae3ea8eb793
