BigQueryML에서 Vertex AI의 생성형 AI 관련 모델들을 가져와 쓸 수 있게 ML.GENERATE_TEXT및 ML.GENERATE_TEXT_EMBEDDING 함수가 얼마전 GA됐었다.
이를 활용해 RAG 아키텍처를 구현해볼 것이다.
추가로 현시점 기준 아직 GA되진 않았지만 BigQuery VECTOR SEARCH 기능도 있어 이걸 사용해봐도 좋을 것 같다.
아키텍처
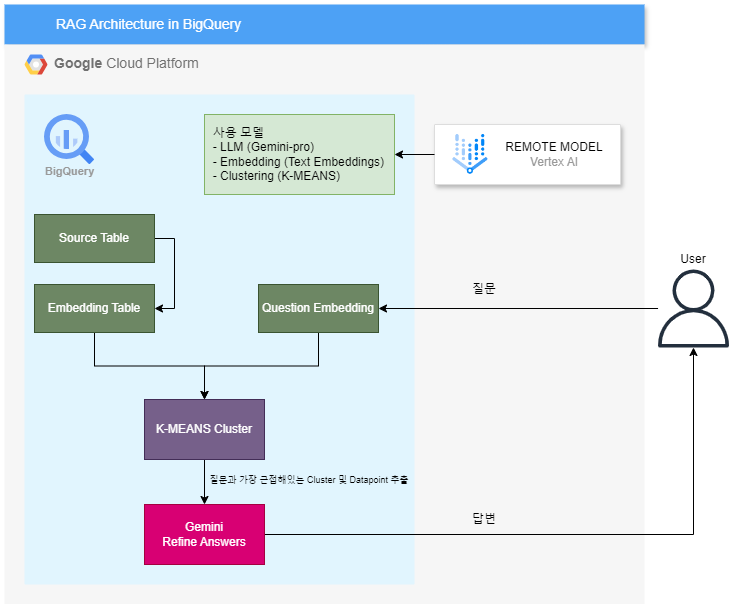
사전 준비
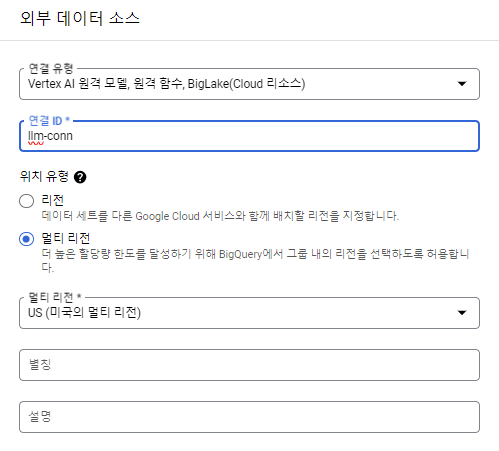
우선 Vertex AI의 모델을 가져와서 쓰는 건 외부 리소스이므로 connection을 생성해줘야 한다.
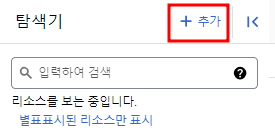
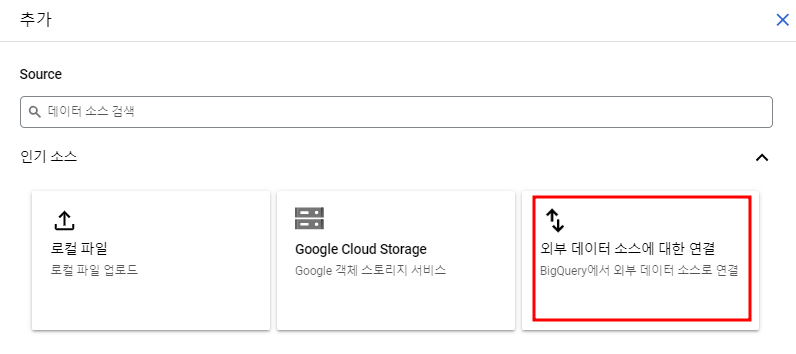
연결 유형을 Vertex AI 원격 모델, 원격 함수, BigLake로 설정하고 ID를 지정해주어 연결을 생성한다.
사용할 데이터는 ChatGPT한테 FAQ 데이터 좀 생성해달라고 했다...ㅎㅎ...
이 파이썬 파일을 실행시켜서 나온 csv 파일을 그대로 BigQuery에 업로드 했다.
BigQuery Studio에서 확인.
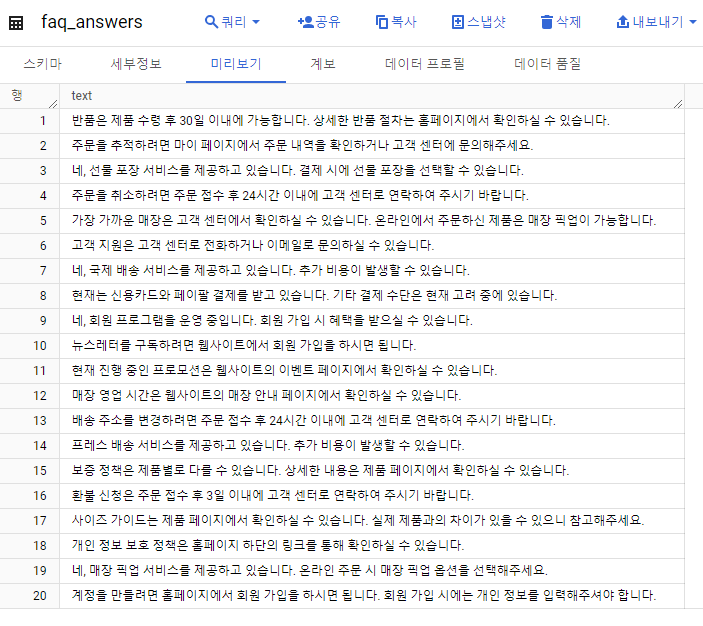
원격 모델 및 임베딩 테이블 생성
1. LLM (Gemini)
CREATE OR REPLACE MODEL `<프로젝트 ID>.<데이터셋>.<LLM 모델 이름>`
REMOTE WITH CONNECTION `us.<연결 ID>`
OPTIONS (ENDPOINT = 'gemini-pro');2. Embedding (Text Embeddings)
CREATE OR REPLACE MODEL `<프로젝트 ID>.<데이터셋>.<임베딩 모델 이름>`
REMOTE WITH CONNECTION `us.<연결 ID>`
OPTIONS (ENDPOINT = 'textembedding-gecko-multilingual');임베딩 모델을 사용하여 기존 테이블에 있는 FAQ 답변들을 임베딩할 것이다.
CREATE TABLE `<프로젝트 ID>.<데이터셋>.<임베딩 테이블 이름>`
AS
(
SELECT *
FROM
ML.GENERATE_TEXT_EMBEDDING(
MODEL `<프로젝트 ID>.<데이터셋>.<임베딩 모델 이름>`,
(
SELECT
text AS content
FROM
`<프로젝트 ID>.<데이터셋>.<기존 테이블 이름>`
),
STRUCT(TRUE AS flatten_json_output)
)
);
결과 확인.
3. Clustering (K-MEANS)
CREATE OR REPLACE MODEL `<프로젝트 ID>.<데이터셋>.<클러스터링 모델 이름>`
OPTIONS (
model_type = 'KMEANS',
KMEANS_INIT_METHOD = 'KMEANS++',
num_clusters = 10) AS (
SELECT
text_embedding
FROM
`<프로젝트 ID>.<데이터셋>.<임베딩 테이블 이름>`
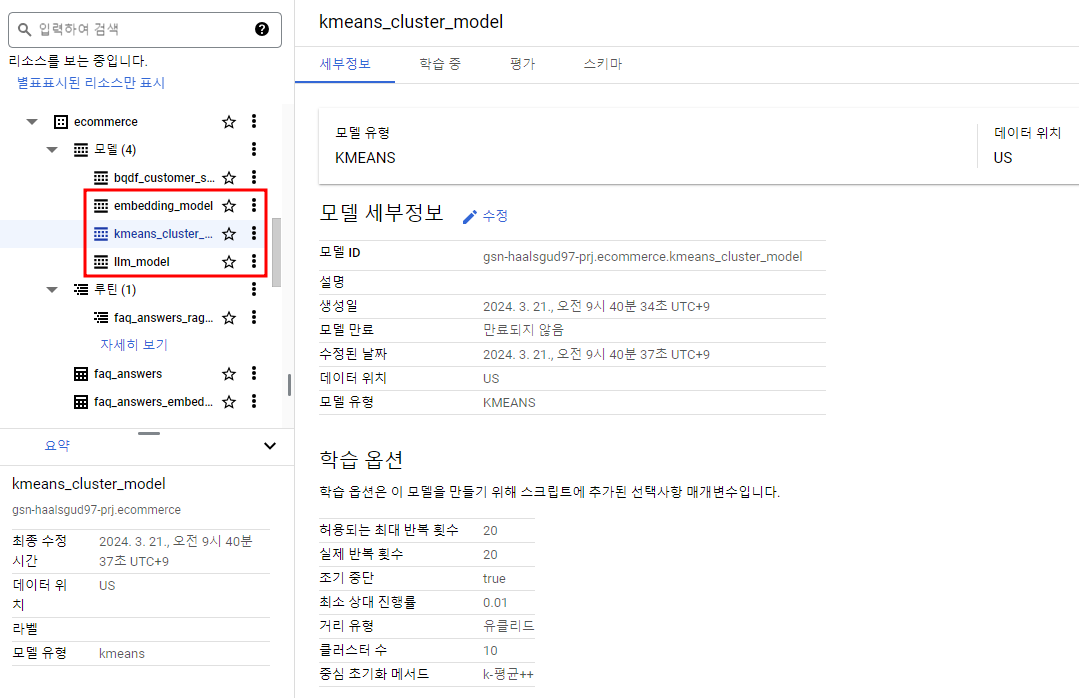
);결과 확인.
BigQueryML로 모델을 생성한 것처럼 데이터셋 밑에 모델이 생성된 것을 볼 수 있다.
질문과 근접한 Cluster 및 Datapoint 추출
우선 질문의 내용이 속한 클러스터부터 예측해보자.
WITH query_test as
(
SELECT
*
FROM
ML.GENERATE_TEXT_EMBEDDING(
MODEL `<프로젝트 ID>.<데이터셋>.<임베딩 모델 이름>`,
(SELECT
"환불 신청" AS content),
STRUCT(TRUE AS flatten_json_output))
)
SELECT
centroid_id,
text_embedding
FROM
ML.PREDICT(
MODEL `<프로젝트 ID>.<데이터셋>.<클러스터링 모델 이름>`,
(SELECT
text_embedding
FROM
query_test)
);
1번 클러스터라고 한다..

그럼 확인해보자..!!!
클러스터의 데이터 추출
SELECT
*
FROM
ML.PREDICT(
MODEL `<프로젝트 ID>.<데이터셋>.<클러스터링 모델 이름>`,
(SELECT
text_embedding,
content
FROM
`<프로젝트 ID>.<데이터셋>.<임베딩 테이블 이름>`)
)
WHERE centroid_id = 1 -- 1번 클러스터
;
실제로 찾아보니 1번 클러스터에 원하는 내용(환불 신청과 관련된 답변)이 매우 근접해있다는 걸 확인할 수 있었다.

위의까지의 내용을 조합할 것이다.
- 질문 임베딩 & 해당 질문과 가장 근접한 클러스터 추출
- 해당 클러스터 내 데이터포인트들의 거리를 계산
- 최종적으로 가장 유사한 값 순서대로 출력
WITH query_test AS
-- 질문
(
SELECT
*
FROM
ML.GENERATE_TEXT_EMBEDDING(
MODEL `<프로젝트 ID>.<데이터셋>.<임베딩 모델 이름>`,
(SELECT
"환불 신청" AS content),
STRUCT(TRUE AS flatten_json_output))
),
-- 질문 임베딩 & 클러스터 추출
query_cluster AS
(
SELECT
centroid_id,
content,
text_embedding
FROM
ML.PREDICT(
MODEL `<프로젝트 ID>.<데이터셋>.<클러스터링 모델 이름>`,
(SELECT
text_embedding,
content
FROM
query_test)
)
),
-- 해당 질문과 가장 근접한 클러스터 추출
answer_cluster AS
(
SELECT
*
FROM
ML.PREDICT(
MODEL `<프로젝트 ID>.<데이터셋>.<클러스터링 모델 이름>`,
(SELECT
text_embedding,
content
FROM
`<프로젝트 ID>.<데이터셋>.<임베딩 테이블 이름>`)
)
WHERE centroid_id in (SELECT centroid_id FROM query_cluster)
)
-- 질문과 거리가 가까운 순서서대로 출력 (코사인 유사도 사용)
SELECT
s.content AS search_content,
c.content AS content,
ML.DISTANCE(s.text_embedding, c.text_embedding, 'COSINE') AS distance
FROM
query_cluster AS s,
answer_cluster AS c
ORDER BY
distance ASC
;원하는 환불 신청에 대한 답변이 가장 상단에 즉, 가장 유사하다고 출력됐다!!

LLM을 사용한 답변 정제
Gemini를 사용하여 사용자에게 보여질 답변을 생성 및 정제해보자.
임의로 답변 형식을 Markdown으로 작성하라고 포맷을 정해줘봤다.
(Gemini를 통해 답변 생성하는 것에 대한 테스트이므로 질문, 답변은 그냥 직접 입력해준 것. 다른 내용을 넣어도 상관없음.)
SELECT
prompt AS query,
ml_generate_text_result['candidates'][0]['content']['parts'][0]['text'] AS answer
FROM
ML.GENERATE_TEXT(
MODEL `<프로젝트 ID>.<데이터셋>.<LLM 모델 이름>`,
(
SELECT
CONCAT(
'사용자의 질문과 그에 대한 답변이 아래에 있어. 이를 참고해서 답변을 제공하는데 Markdown 형식으로 답변을 작성해줘. ',
'질문:','환불 신청',
'답변:', '환불 신청은 주문 접수 후 3일 이내에 고객 센터로 연락하여 주시기 바랍니다.') AS prompt
),
STRUCT(
0.1 AS temperature,
1000 AS max_output_tokens,
0.1 AS top_p,
10 AS top_k));결과 확인.

프로시저 생성
이제 이 과정을 모두 조합하여 하나의 프로시저로 만들 것이다.
해당 프로시저에 질문을 포함하여 호출하면 그에 대한 답변이 Return되는 RAG를 구현할 수 있게된다.
BEGIN
DECLARE grounding STRING;
DECLARE prompt_pre STRING DEFAULT '사용자의 질문과 그에 대한 답변이 아래에 있어. 이를 참고해서 답변을 제공해줘. ';
DECLARE prompt_suf STRING DEFAULT 'Markdown 형식으로 제공해줘';
-- 임베딩 된 데이터에서 질문과 가장 유사한 클러스터 추출
SET grounding = (
WITH query_test as
(
SELECT
*
FROM
ML.GENERATE_TEXT_EMBEDDING(
MODEL `<프로젝트 ID>.<데이터셋>.<임베딩 모델 이름>`,
(SELECT
query_string AS content),
STRUCT(TRUE AS flatten_json_output))
),
query_cluster as
(
SELECT
centroid_id,
content,
text_embedding
FROM
ML.PREDICT(
MODEL `<프로젝트 ID>.<데이터셋>.<클러스터링 모델 이름>`,
(SELECT
text_embedding,
content
FROM
query_test)
)
),
answer_cluster as
(
SELECT
*
FROM
ML.PREDICT(
MODEL `<프로젝트 ID>.<데이터셋>.<클러스터링 모델 이름>`,
(SELECT
text_embedding,
content
FROM
`<프로젝트 ID>.<데이터셋>.<임베딩 테이블 이름>`)
)
WHERE centroid_id in (select centroid_id from query_cluster)
)
-- 질문과 거리가 가까운 순서서대로 출력
SELECT
c.content AS content,
FROM
query_cluster AS s,
answer_cluster AS c
QUALIFY
ROW_NUMBER()OVER(order by ML.DISTANCE(s.text_embedding, c.text_embedding, 'COSINE') ASC) = 1) ;
-- LLM을 통한 답변 정제
SET llm_answer = (
SELECT
STRING(ml_generate_text_result['candidates'][0]['content']['parts'][0]['text']) AS answer
FROM
ML.GENERATE_TEXT(
MODEL `<프로젝트 ID>.<데이터셋>.<LLM 모델 이름>`,
(
SELECT
CONCAT(
prompt_pre,
'질문:',query_string,
'답변:', grounding,
prompt_suf) AS prompt
),
STRUCT(
0.1 AS temperature,
1000 AS max_output_tokens,
0.1 AS top_p,
10 AS top_k))
);
SELECT llm_answer;
END프로시저 생성 확인.
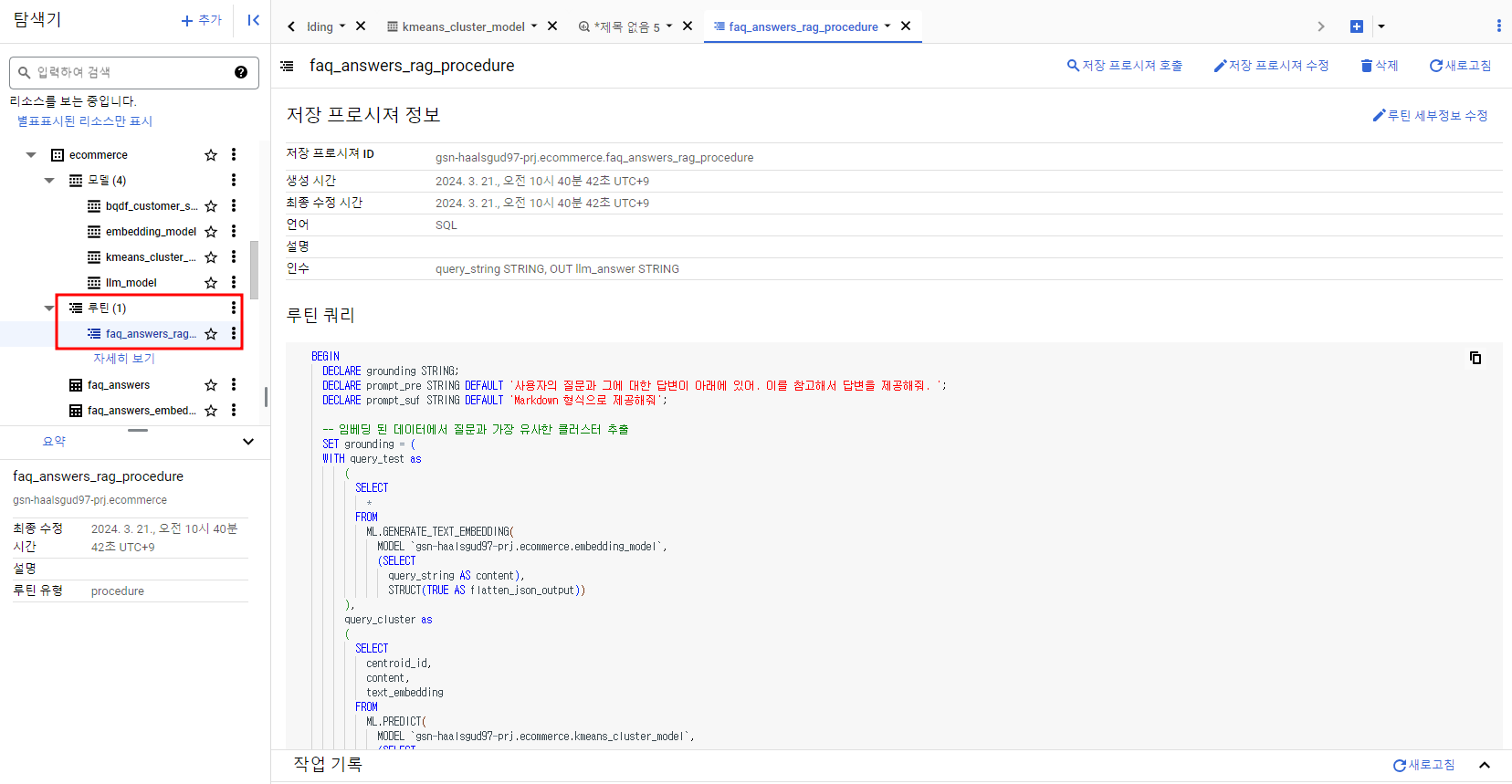
질문 : 환불 신청 어떻게 해?
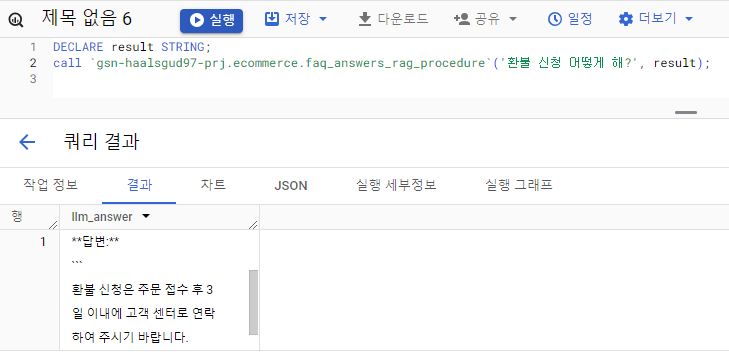
DECLARE result STRING;
call `<프로젝트 ID>.<데이터셋>.<프로시저 이름>`('환불 신청 어떻게 해?', result);결과 확인.
[BigQuery에서 RAG 구현 참고]
https://qiita.com/yakamazu/items/a32c03f33689923bf99c
