NL2SQL
NL2SQL이란 Natural Language to(2) SQL의 약자로 Text-to-SQL이라고 생각하면 된다. NL2SQL 방법론들은 사실 매우 많고 챌린지도 많은 분야지만 얕은 내 지식으로,,,, 사용했던 방법을 간단히 소개하려 한다.

"LLM은 AGI가 아니다."
알잘딱깔센이 되는 놈이 아니라 원하는 형태로 답을 얻기 위해선 정보를 학습시켜야 한다.
즉, 어떤 쿼리를 생성해달라고 하면 그 뒤에 있는 테이블 데이터에 맞게 쿼리를 알아서 짜주지 않는다는 것이다.
그렇다면 테이블에 대한 정보를 같이 입력시켜줘야 하는데 간단히 생각하면 두 가지 방법이 있을 수 있다.
- 프롬프트 방식
- 임베딩 방식
여기서 사용해볼 건 임베딩을 활용한 방식이다.
프롬프트 vs 임베딩
보통 하나의 테이블에 대한 NL2SQL이면 사실 임베딩 방법보다 스키마에 대한 메타데이터를 프롬프트로 엮어서 같이 LLM에 질의하는 방법이 속도면에서도 그렇고 더 나을 수 있기 때문에 굳이 임베딩을 사용하지 않는 걸 권장한다.
하지만 임베딩을 사용하는 것의 장점은 사용해야될 테이블이 많을 때이다. 많은 테이블에서 사용자 질의에 맞는 테이블을 선별하여 쿼리를 해야하거나, 많은 테이블을 Join하여 쿼리를 생성해야 하거나 등등의 경우에 유용하다.
그렇다면 왜?
그럼 그 테이블들에 대한 정보도 똑같이 프롬프트로 다 넣어주면 되지 않냐고 할 수 있다.
LLM은 입력 Token Limit이 존재한다.
물론 테이블이 두 세개 정도라고 하면 테이블에 대한 정보, 그리고 그 테이블들에 있는 모든 컬럼들에 대한 용도, 설명을 LLM에 사용자 질문과 같이 엮어서 던져도 충분할 수도 있다.
하지만 테이블이 무수히 많으면 그렇지 않을 가능성이 크고 정확한 답변을 위해선 그 외에도 추가 프롬프트 엔지니어링이 필요하기 때문에 임베딩을 사용하는 것이 경우에 따라서 더 좋은 솔루션이 될 수 있는 것이다.
사전 준비
- 개발환경 : Vertex AI Workbench
- LLM : Vertex AI - Text-Embeddings, Gemini
- 데이터 : ChatGPT가 만들어준 데이터ㅎㅎ...
데이터는 ChatGPT한테 상품 데이터 한 30개만 생성해달라고 했다.
그리고 여기선 테스트이므로 여러 테이블이 아닌 이 하나의 테이블에 대해서만 SQL문을 생성하도록 할 것이다.
역시 훌륭하다!
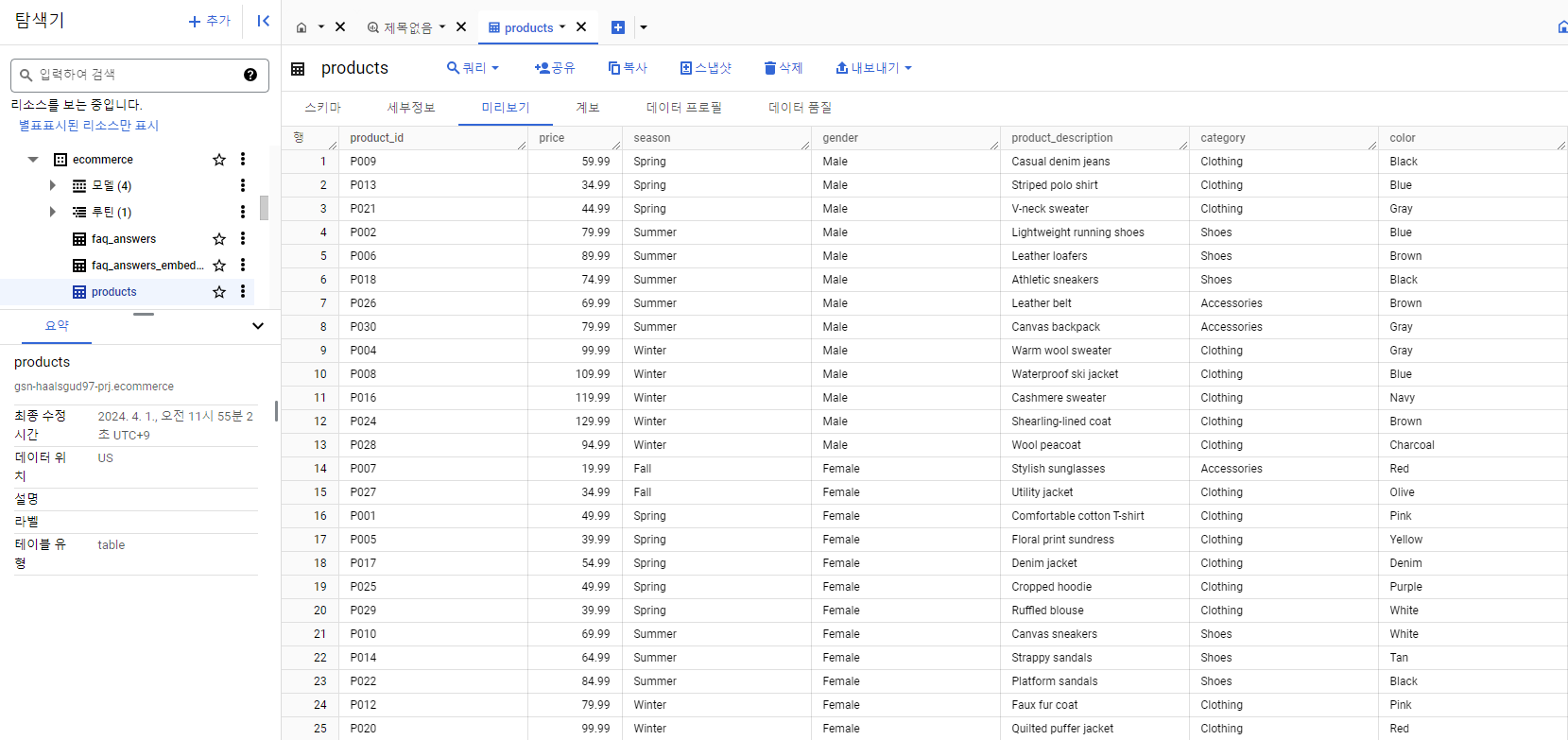
위 코드를 실행해서 나온 csv 파일을 그대로 BigQuery에 올렸다.
임베딩
Vertex AI의 Text-Embeddings 사용
class MyVertexAIEmbeddings(VertexAIEmbeddings, Embeddings):
model_name = 'textembedding-gecko@001'
max_batch_size = 5
def embed_segments(self, segments: List) -> List:
embeddings = []
for i in tqdm(range(0, len(segments), self.max_batch_size)):
batch = segments[i: i+self.max_batch_size]
embeddings.extend(self.client.get_embeddings(batch))
return [embedding.values for embedding in embeddings]
def embed_query(self, query: str) -> List:
embeddings = self.client.get_embeddings([query])
return embeddings[0].values
embedding = MyVertexAIEmbeddings()임베딩을 한다는 건 벡터 저장소를 사용한다는 것인데 여기선 LangChain에서 제공하는 FAISS 벡터 저장소를 사용할 것이다.
schema.jsonl
스키마 메타데이터
{"dataset_name": "ecommerce", "table_name": "products", "column_name": "product_id", "description": "<설명>", "usage": "<용도 혹은 해당 컬럼 사용시기>", "data_type": "STRING"}
{"dataset_name": "ecommerce", "table_name": "products", "column_name": "price", "description": "<설명>", "usage": "<용도 혹은 해당 컬럼 사용시기>", "data_type": "FLOAT"}
{"dataset_name": "ecommerce", "table_name": "products", "column_name": "season", "description": "<설명>", "usage": "<용도 혹은 해당 컬럼 사용시기>", "data_type": "STRING"}
{"dataset_name": "ecommerce", "table_name": "products", "column_name": "gender", "<설명>", "usage": "<용도 혹은 해당 컬럼 사용시기>", "data_type": "STRING"}
{"dataset_name": "ecommerce", "table_name": "products", "column_name": "product_description", "description": "<설명>", "usage": "<용도 혹은 해당 컬럼 사용시기>", "data_type": "STRING"}
{"dataset_name": "ecommerce", "table_name": "products", "column_name": "category", "description": "<설명>", "usage": "<용도 혹은 해당 컬럼 사용시기>", "data_type": "STRING"}
{"dataset_name": "ecommerce", "table_name": "products", "column_name": "color", "description": "<설명>", "usage": "<용도 혹은 해당 컬럼 사용시기>", "data_type": "STRING"}임베딩
위의 스키마 정보가 들어있는 파일을 FAISS에 임베딩
documents = JSONLoader(file_path='./schema.jsonl', jq_schema='.', text_content=False, json_lines=True).load()
db = FAISS.from_documents(documents=documents, embedding=embedding)질문 : 봄이나 가을에 입을만 한 여자 재킷 추천해줘
아래 코드를 통해 사용자 질문에 대한 컬럼 정보들을 유사도 검색을 하여 가져온다.
search_kwargs = {
'k': 20
}
retriever = db.as_retriever(search_type='similarity', search_kwargs=search_kwargs)
matched_columns = retriever.get_relevant_documents(query=query)컬럼 정보를 따로 리스트에 저장
matched_columns_filtered = []
# LangChain filters does not support multiple values at the moment
for i, column in enumerate(matched_columns):
page_content = json.loads(column.page_content)
dataset_name = page_content['dataset_name']
if dataset_name == 'ecommerce':
matched_columns_filtered.append(page_content)데이터 클리닝
matched_columns_cleaned = []
for doc in matched_columns_filtered:
dataset_name = doc['dataset_name']
table_name = doc['table_name']
column_name = doc['column_name']
data_type = doc['data_type']
matched_columns_cleaned.append(f'dataset_name={dataset_name}|table_name={table_name}|column_name={column_name}|data_type={data_type}')
matched_columns_cleaned = '\n'.join(matched_columns_cleaned)
print(matched_columns_cleaned)출력을 하면 이런식으로 나오게 된다.

+추가로 여기선 안했지만 만약 여러 테이블이 있을 경우 스키마 정보를 임베딩하기 전에 아래 작업을 먼저 진행하면 된다.
tables.jsonl
{"dataset_name": "<데이터셋 이름>", "table_name": "<테이블1>", "description": "<설명>", "example_queries": ["<예시 질문1>", "<예시 질문2>", "<예시 질문3", "<예시 질문4>"]}
{"dataset_name": "<데이터셋 이름>", "table_name": "<테이블2>", "description": "<설명>", "example_queries": ["<예시 질문1>", "<예시 질문2>", "<예시 질문3", "<예시 질문4>"]}
{"dataset_name": "<데이터셋 이름>", "table_name": "<테이블3>", "description": "<설명>", "example_queries": ["<예시 질문1>", "<예시 질문2>", "<예시 질문3", "<예시 질문4>"]}
...documents = JSONLoader(file_path='./tables.jsonl', jq_schema='.', text_content=False, json_lines=True).load()
db = FAISS.from_documents(documents=documents, embedding=embedding)matched_tables = []
for document in matched_documents:
page_content = document.page_content
page_content = json.loads(page_content)
dataset_name = page_content['dataset_name']
table_name = page_content['table_name']
matched_tables.append(f'{dataset_name}.{table_name}')SQL 생성
LangChain의 system, human message를 활용하여 프롬프트 엔지니어링을 수행
system_template = "You are a SQL master expert capable of writing complex SQL query in BigQuery."
matched_schema = matched_columns_cleaned
human_template = f"""Given the following inputs:
USER_QUERY:
--
{query}
--
MATCHED_SCHEMA:
--
{matched_schema}
--
{prompt}
"""
llm = ChatGoogleGenerativeAI(model=MODEL_NAME, convert_system_message_to_human=True)
result = llm(
[
SystemMessage(content=system_template),
HumanMessage(content=human_template),
]
)
for res in result:
if res[0] == 'content':
answer = res[1]
clean_query = answer.strip().replace("```sql", "").replace("```", "")
print(clean_query)결과

챌린지
잘 나온 쿼리일까?
언뜻보면 맞다고 생각할 수 있지만 아니다. 쿼리가 될 리가 없다..
이 부분이 중요한 챌린지 중 하나인데 바로 Categorical Value에 대한 처리이다.
재킷을 찾고 싶다고해서 LLM은 category열에서 jackets을 필터링하는 WHERE절을 생성했지만 사실 GPT가 만들어준 데이터를 보면 category열에는 Shoes, Accessories, Clothing밖에 없다.
이를 해결하기 위해 생각해낸 단순한 방법은 Categorical한 값들만 따로 정의해준 것이다.
categorical_value.txt
table_name: products
column_name: season
values: [Spring, Summer, Fall, Winter]
table_name: products
column_name: gender
values : [Female, Male, Unisex]
table_name: products
column_name: category
values : [Shoes, Accessories, Clothing]이걸 받아온 후 프롬프트에 Categorical한 값들은 해당 리스트에 있는 값만을 활용하라고 넣어줬다.
system_template = "You are a SQL master expert capable of writing complex SQL query in BigQuery."
matched_schema = matched_columns_cleaned
human_template = f"""Given the following inputs:
USER_QUERY:
--
{query}
--
MATCHED_SCHEMA:
--
{matched_schema}
--
CATEGORICAL_VALUE:
--
{categorical_value}
--
{prompt}
"""
llm = ChatGoogleGenerativeAI(model=MODEL_NAME, convert_system_message_to_human=True)
result = llm(
[
SystemMessage(content=system_template),
HumanMessage(content=human_template),
]
)
for res in result:
if res[0] == 'content':
answer = res[1]
clean_query = answer.strip().replace("```sql", "").replace("```", "")
print(clean_query)결과

쿼리
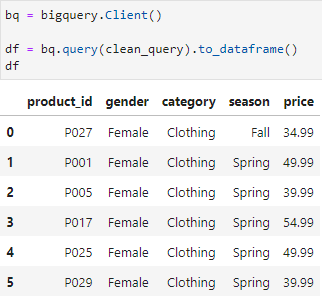
임베딩을 활용하는 것의 장점을 토큰에 큰 제약없이 사용할 수 있는 것처럼 위에 언급했지만 결국엔 Categorical Value처리에 대한 문제를 해결하기 위해 해당 값들을 정의해놓은 걸 프롬프트에 가져다 썼다는 게 모순적이긴 하다,,,
[NL2SQL 참고]
https://github.com/arunpshankar/LLM-Text-to-SQL-Architectures
