DAG를 통해 BigQuery 공개 데이터 세트의 ghcn_d 데이터와 S3 버킷에 저장된 CSV 파일을 join한 다음 Dataproc 배치 작업을 실행하여 결합한 데이터를 처리하여 빅쿼리에 적재하는 실습을 해볼 것이다.
GCP 환경 설정
Composer 2 버전으로 환경을 생성해준다.
빅쿼리에서 holiday_weather 데이터 세트 생성 (리전은 US)
S3에서 Cloud Storage로 csv파일을 가져온 후 데이터 분석을 할 것이다.
때문에 Cloud Storage 버킷도 하나 생성해준다.
Cloud Shell에서 default 리전의 기본 서브넷에서 비공개 Google 액세스 사용을 허용해준다.
gcloud compute networks subnets update default \
--region <Dataproc 리전 ex) asia-northeast3> \
--enable-private-ip-google-accessAWS 관련 설정
Cloud Shell 활성화
우리가 S3에 넣을 샘플 데이터이다.
git clone https://github.com/GoogleCloudPlatform/python-docs-samples.git
cd python-docs-samples/data-science-onramp/data-ingestion/holidays.csvcsv파일을 로컬로 다운로드
S3 버킷 생성
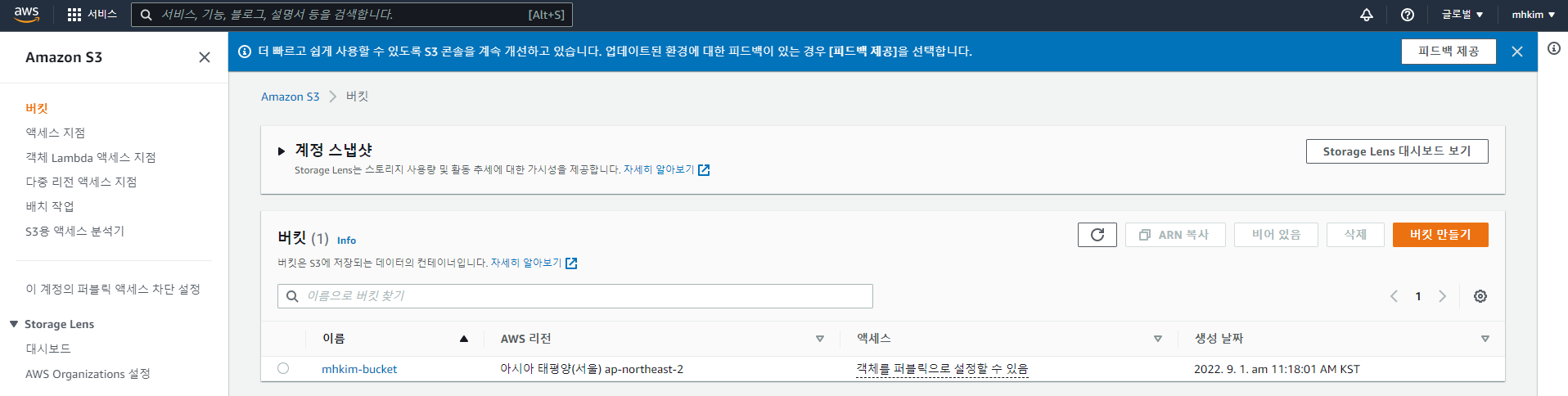
버킷에 위의 csv파일을 넣는다.
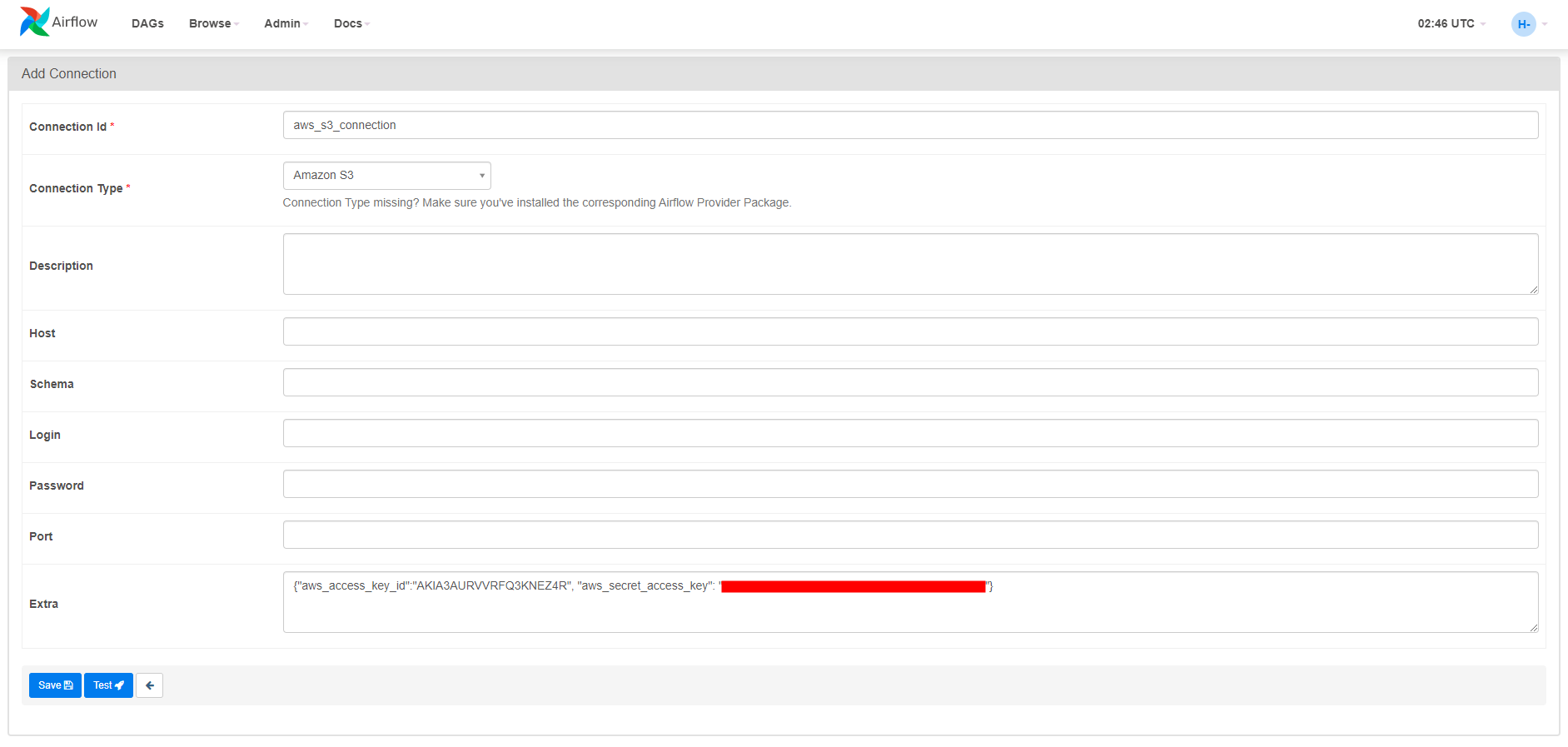
Composer의 Airflow UI에서 S3와 Connection을 맺어줄 것이다.
먼저, S3와 연결하려면 PYPI 패키지를 하나 추가해줘야 한다.
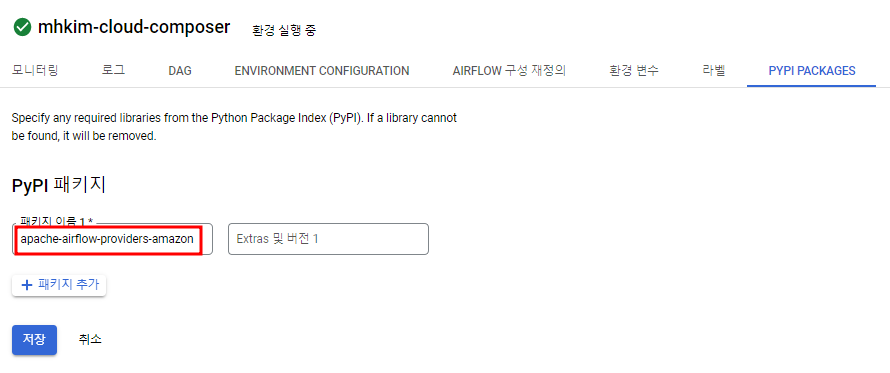
apache-airflow-providers-amazon 패키지 추가
Airflow UI에서 Connection 접속


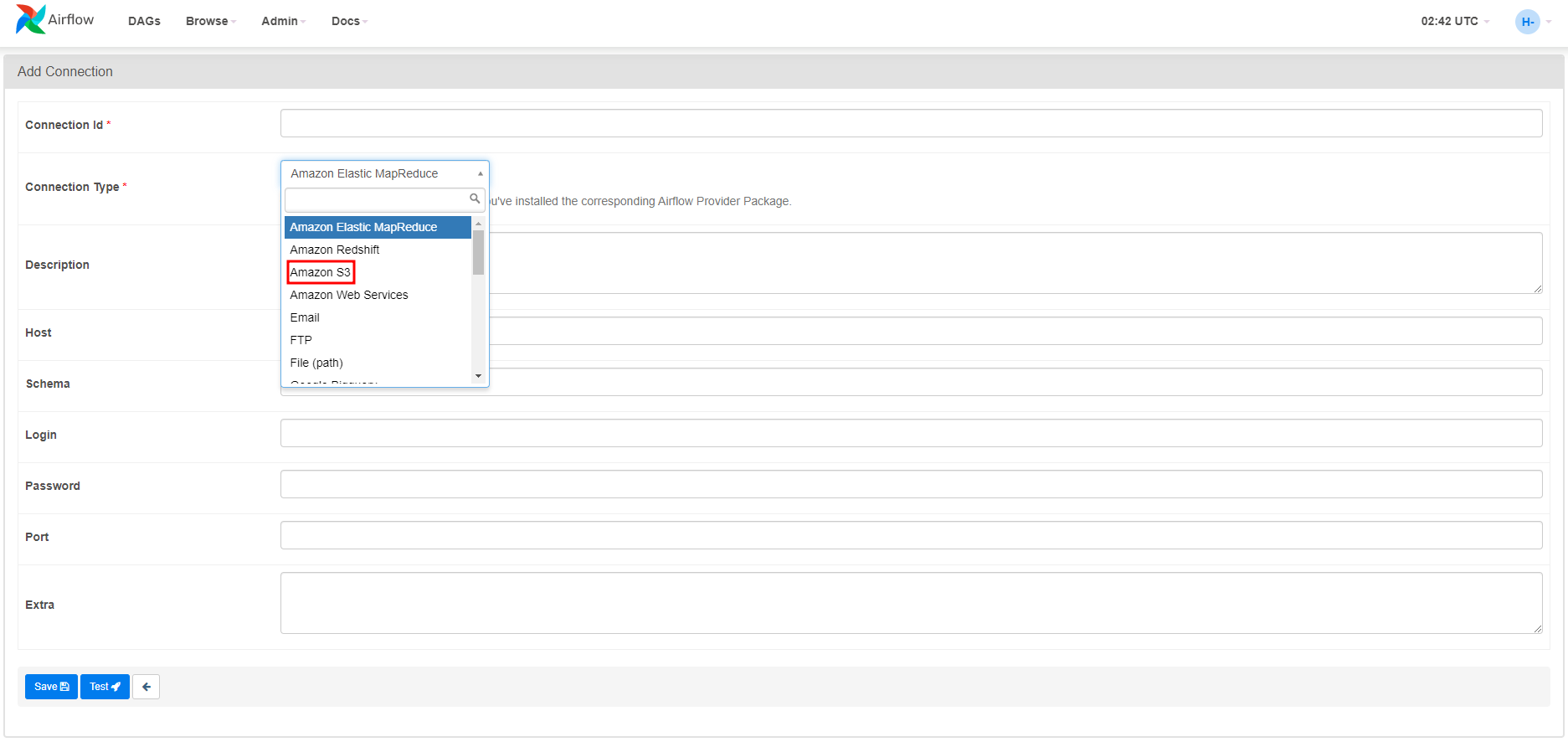
Connection 추가에서 Type을 보면 이제 S3가 보이는 것을 확인할 수 있다.
하지만 연결을 하려면 내 AWS 계정에 대한 정보를 여기서 넣어줘야 한다.
AWS 보안자격증명에서 Access key ID 와 Secret Access Key를 가져오자.
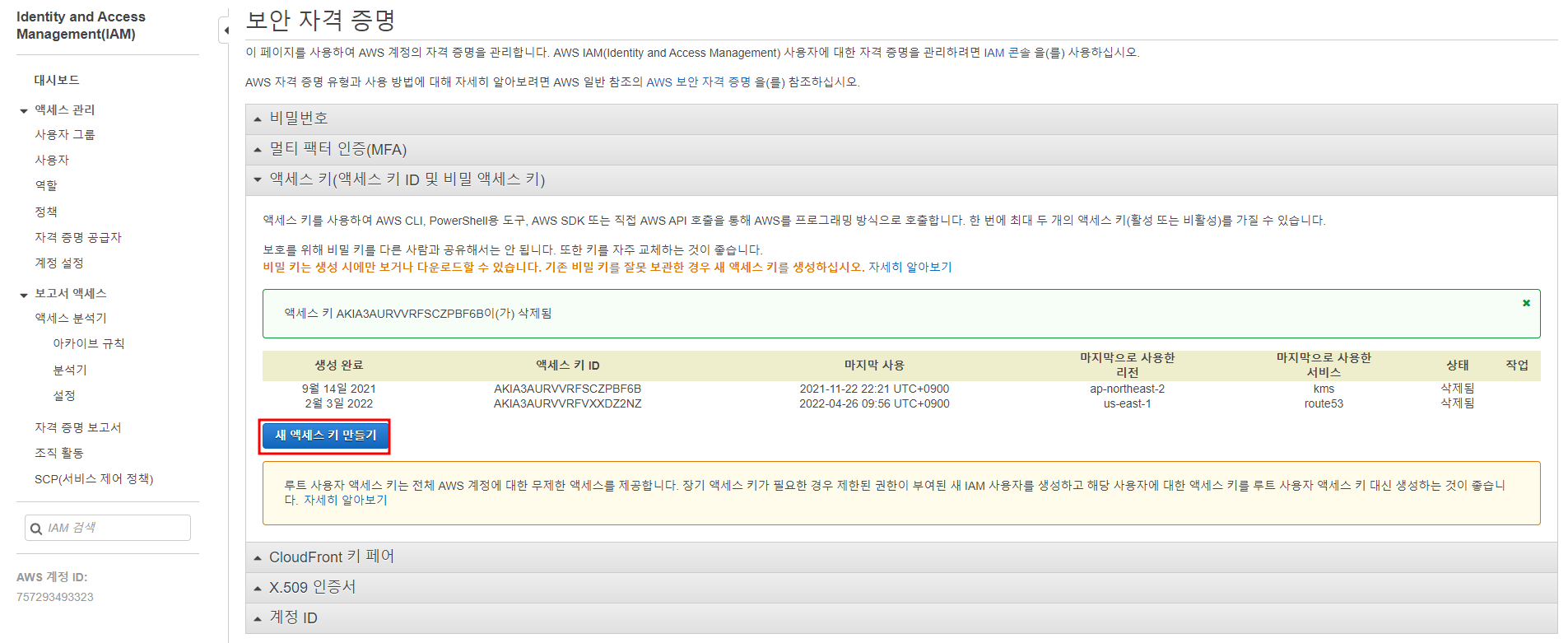
새 액세스 키를 생성하여 따로 복사해둔 후 다시 Airflow UI로 돌아와서 Connection 설정에서 아래와 같이 넣어준다.
DAG 실행
data_analytics_process.py
import sys
from py4j.protocol import Py4JJavaError
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
if __name__ == "__main__":
BUCKET_NAME = sys.argv[1]
READ_TABLE = sys.argv[2]
WRITE_TABLE = sys.argv[3]
# Create a SparkSession, viewable via the Spark UI
spark = SparkSession.builder.appName("data_processing").getOrCreate()
# Load data into dataframe if READ_TABLE exists
try:
df = spark.read.format("bigquery").load(READ_TABLE)
except Py4JJavaError as e:
raise Exception(f"Error reading {READ_TABLE}") from e
# Convert temperature from tenths of a degree in celsius to degrees celsius
df = df.withColumn("value", col("value") / 10)
# Display sample of rows
df.show(n=20)
# Write results to GCS
if "--dry-run" in sys.argv:
print("Data will not be uploaded to BigQuery")
else:
# Set GCS temp location
temp_path = BUCKET_NAME
# Saving the data to BigQuery using the "indirect path" method and the spark-bigquery connector
# Uses the "overwrite" SaveMode to ensure DAG doesn't fail when being re-run
# See https://spark.apache.org/docs/latest/sql-data-sources-load-save-functions.html#save-modes
# for other save mode options
df.write.format("bigquery").option("temporaryGcsBucket", temp_path).mode(
"overwrite"
).save(WRITE_TABLE)
print("Data written to BigQuery")이 파일을 처음에 만들어준 Cloud Storage 버킷에 업로드
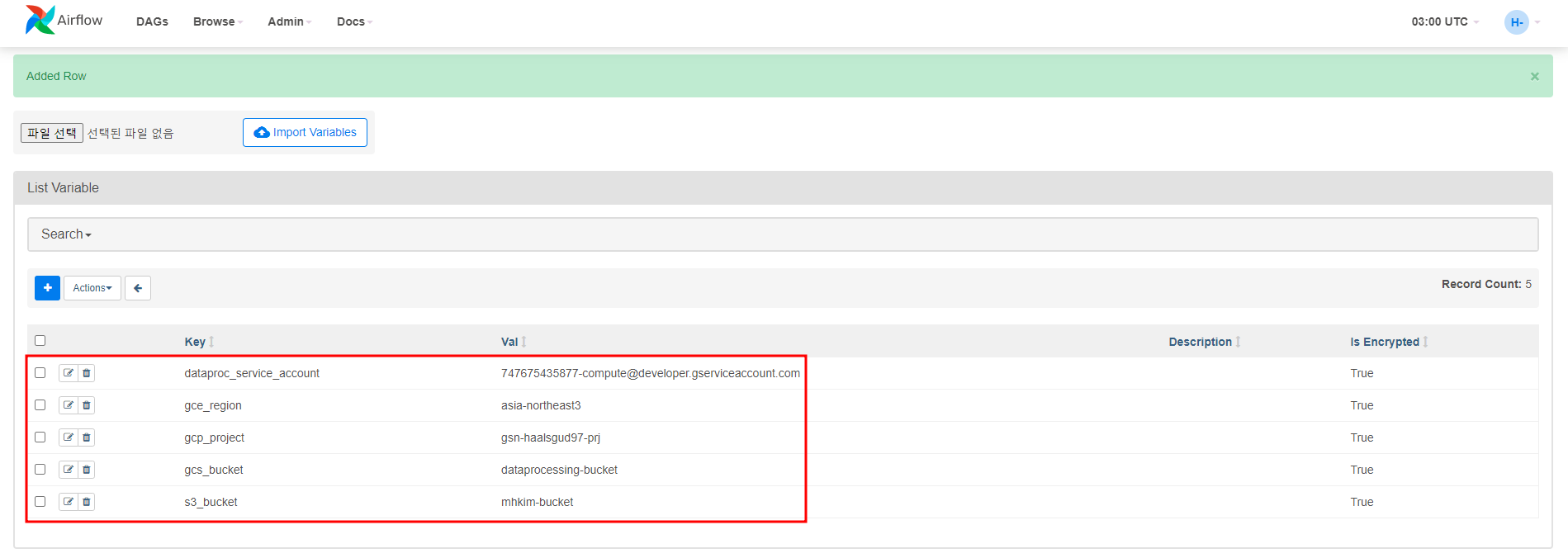
DAG에서 사용할 내 GCP 환경과 관련된 변수를 추가해줄 것이다.
Airflow UI에서 변수 추가
s3togcsoperator_tutorial.py
import datetime
from airflow import models
from airflow.providers.google.cloud.operators import dataproc
from airflow.providers.google.cloud.operators.bigquery import BigQueryInsertJobOperator
from airflow.providers.google.cloud.transfers.gcs_to_bigquery import (
GCSToBigQueryOperator,
)
from airflow.providers.google.cloud.transfers.s3_to_gcs import S3ToGCSOperator
from airflow.utils.task_group import TaskGroup
PROJECT_NAME = "{{var.value.gcp_project}}"
REGION = "{{var.value.gce_region}}"
# BigQuery configs
BQ_DESTINATION_DATASET_NAME = "holiday_weather"
BQ_DESTINATION_TABLE_NAME = "holidays_weather_joined"
BQ_NORMALIZED_TABLE_NAME = "holidays_weather_normalized"
# Dataproc configs
BUCKET_NAME = "{{var.value.gcs_bucket}}"
PYSPARK_JAR = "gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar"
PROCESSING_PYTHON_FILE = f"gs://{BUCKET_NAME}/data_analytics_process.py"
# S3 configs
S3_BUCKET_NAME = "{{var.value.s3_bucket}}"
BATCH_ID = "data-processing-{{ ts_nodash | lower}}" # Dataproc serverless only allows lowercase characters
BATCH_CONFIG = {
"pyspark_batch": {
"jar_file_uris": [PYSPARK_JAR],
"main_python_file_uri": PROCESSING_PYTHON_FILE,
"args": [
BUCKET_NAME,
f"{BQ_DESTINATION_DATASET_NAME}.{BQ_DESTINATION_TABLE_NAME}",
f"{BQ_DESTINATION_DATASET_NAME}.{BQ_NORMALIZED_TABLE_NAME}",
],
},
"environment_config": {
"execution_config": {
"service_account": "{{var.value.dataproc_service_account}}"
}
},
}
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1), datetime.datetime.min.time()
)
default_dag_args = {
# Setting start date as yesterday starts the DAG immediately when it is
# detected in the Cloud Storage bucket.
"start_date": yesterday,
# To email on failure or retry set 'email' arg to your email and enable
# emailing here.
"email_on_failure": False,
"email_on_retry": False,
}
with models.DAG(
"s3_to_gcs_dag",
# Continue to run DAG once per day
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args,
) as dag:
s3_to_gcs_op = S3ToGCSOperator(
task_id="s3_to_gcs",
bucket=S3_BUCKET_NAME,
gcp_conn_id="google_cloud_default",
aws_conn_id="aws_s3_connection",
dest_gcs=f"gs://{BUCKET_NAME}",
)
create_batch = dataproc.DataprocCreateBatchOperator(
task_id="create_batch",
project_id=PROJECT_NAME,
region=REGION,
batch=BATCH_CONFIG,
batch_id=BATCH_ID,
)
load_external_dataset = GCSToBigQueryOperator(
task_id="run_bq_external_ingestion",
bucket=BUCKET_NAME,
source_objects=["holidays.csv"],
destination_project_dataset_table=f"{BQ_DESTINATION_DATASET_NAME}.holidays",
source_format="CSV",
schema_fields=[
{"name": "Date", "type": "DATE"},
{"name": "Holiday", "type": "STRING"},
],
skip_leading_rows=1,
write_disposition="WRITE_TRUNCATE",
)
with TaskGroup("join_bq_datasets") as bq_join_group:
for year in range(1997, 2022):
BQ_DATASET_NAME = f"bigquery-public-data.ghcn_d.ghcnd_{str(year)}"
BQ_DESTINATION_TABLE_NAME = "holidays_weather_joined"
# Specifically query a Chicago weather station
WEATHER_HOLIDAYS_JOIN_QUERY = f"""
SELECT Holidays.Date, Holiday, id, element, value
FROM `{PROJECT_NAME}.holiday_weather.holidays` AS Holidays
JOIN (SELECT id, date, element, value FROM {BQ_DATASET_NAME} AS Table
WHERE Table.element="TMAX" AND Table.id="USW00094846") AS Weather
ON Holidays.Date = Weather.Date;
"""
# For demo purposes we are using WRITE_APPEND
# but if you run the DAG repeatedly it will continue to append
# Your use case may be different, see the Job docs
# https://cloud.google.com/bigquery/docs/reference/rest/v2/Job
# for alternative values for the writeDisposition
# or consider using partitioned tables
# https://cloud.google.com/bigquery/docs/partitioned-tables
bq_join_holidays_weather_data = BigQueryInsertJobOperator(
task_id=f"bq_join_holidays_weather_data_{str(year)}",
configuration={
"query": {
"query": WEATHER_HOLIDAYS_JOIN_QUERY,
"useLegacySql": False,
"destinationTable": {
"projectId": PROJECT_NAME,
"datasetId": BQ_DESTINATION_DATASET_NAME,
"tableId": BQ_DESTINATION_TABLE_NAME,
},
"writeDisposition": "WRITE_APPEND",
}
},
location="US",
)
s3_to_gcs_op >> load_external_dataset >> bq_join_group >> create_batchComposer가 생성되면서 만들어지는 버킷에 dags/ 폴더에 위의 파일 업로드
DAG 트리거
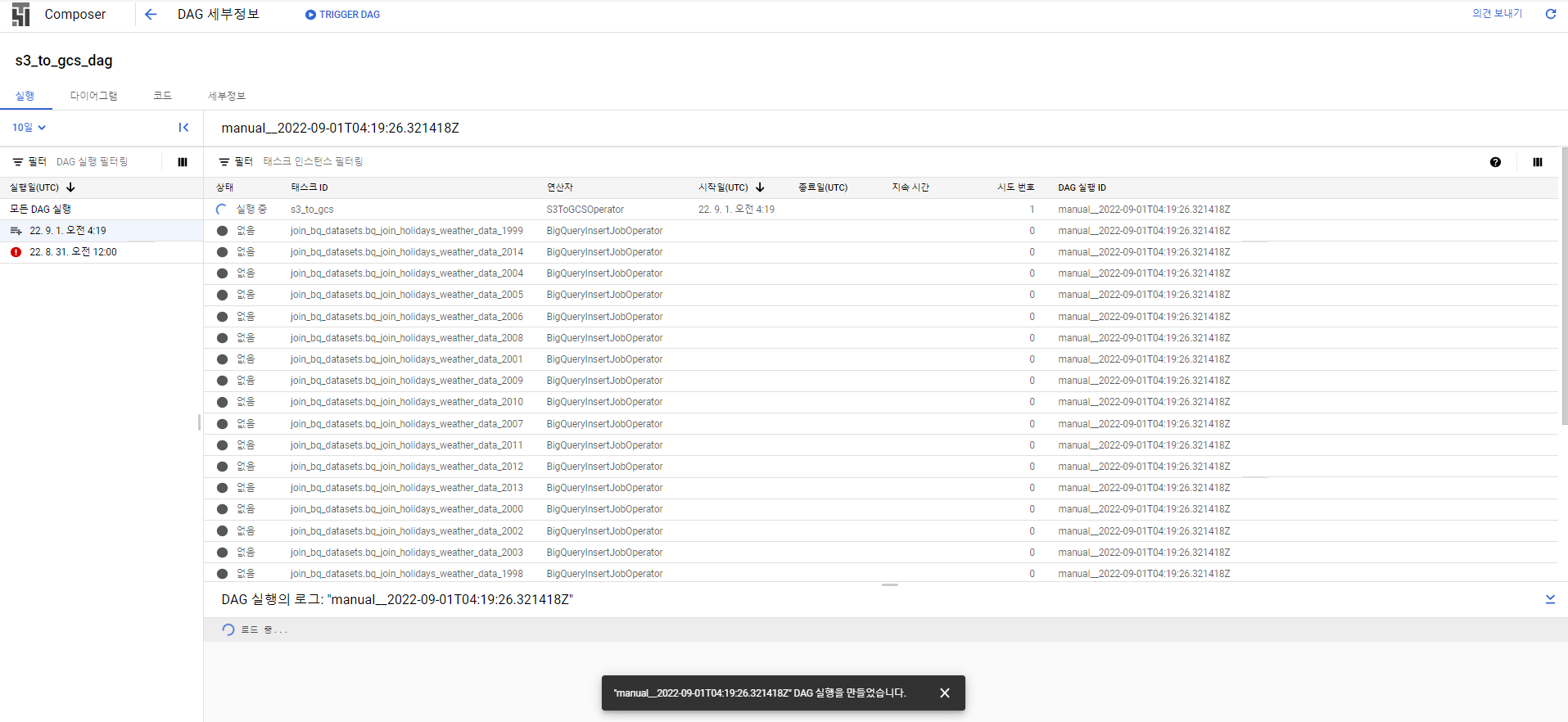
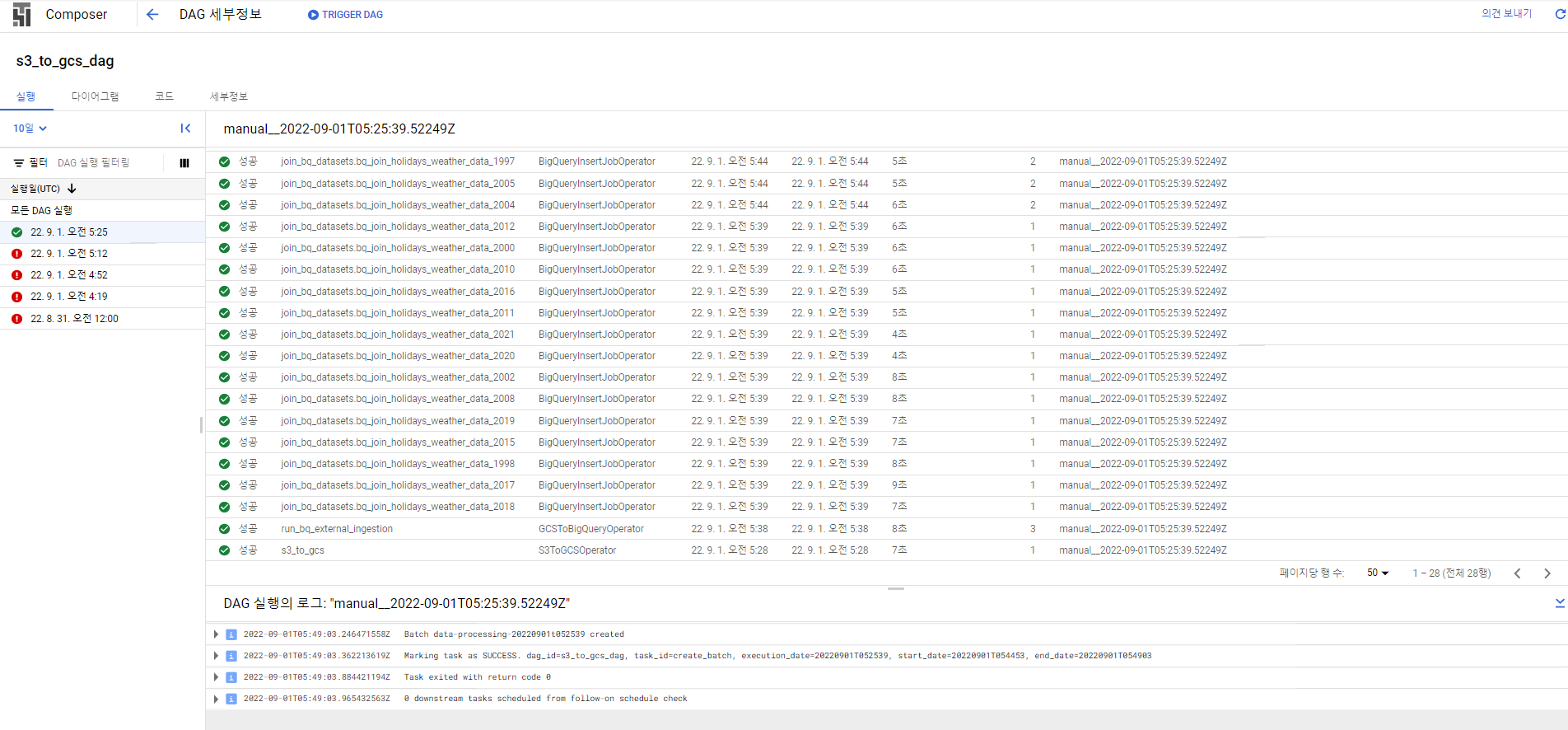
성공, 약 10분 정도 걸릴 수 있다.
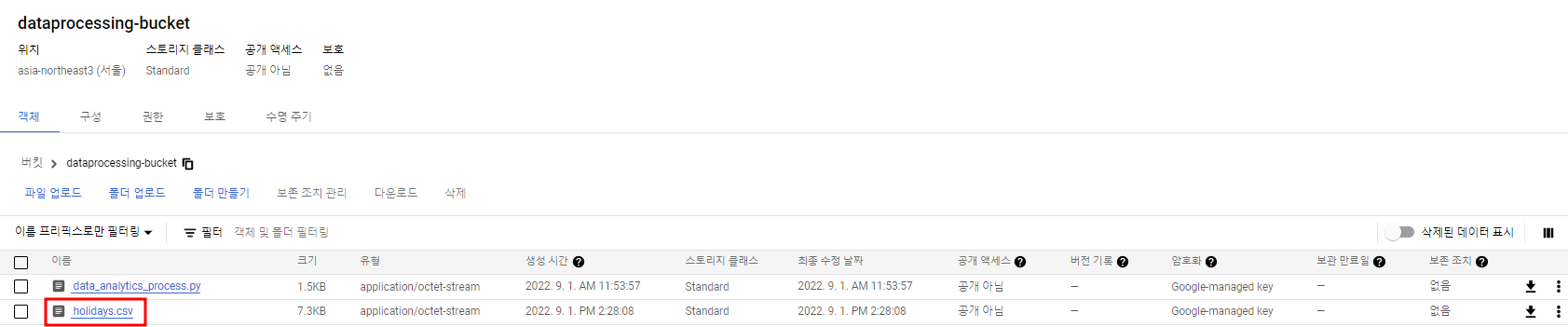
S3에 있던 holidays.csv를 내가 만들어준 Cloud Storage 버킷으로 가져온 것 확인
빅쿼리에서 확인해보면 데이터가 BigQuery 공개 데이터 세트와 join 되어서 테이블에 적재된 것을 확인할 수 있다.
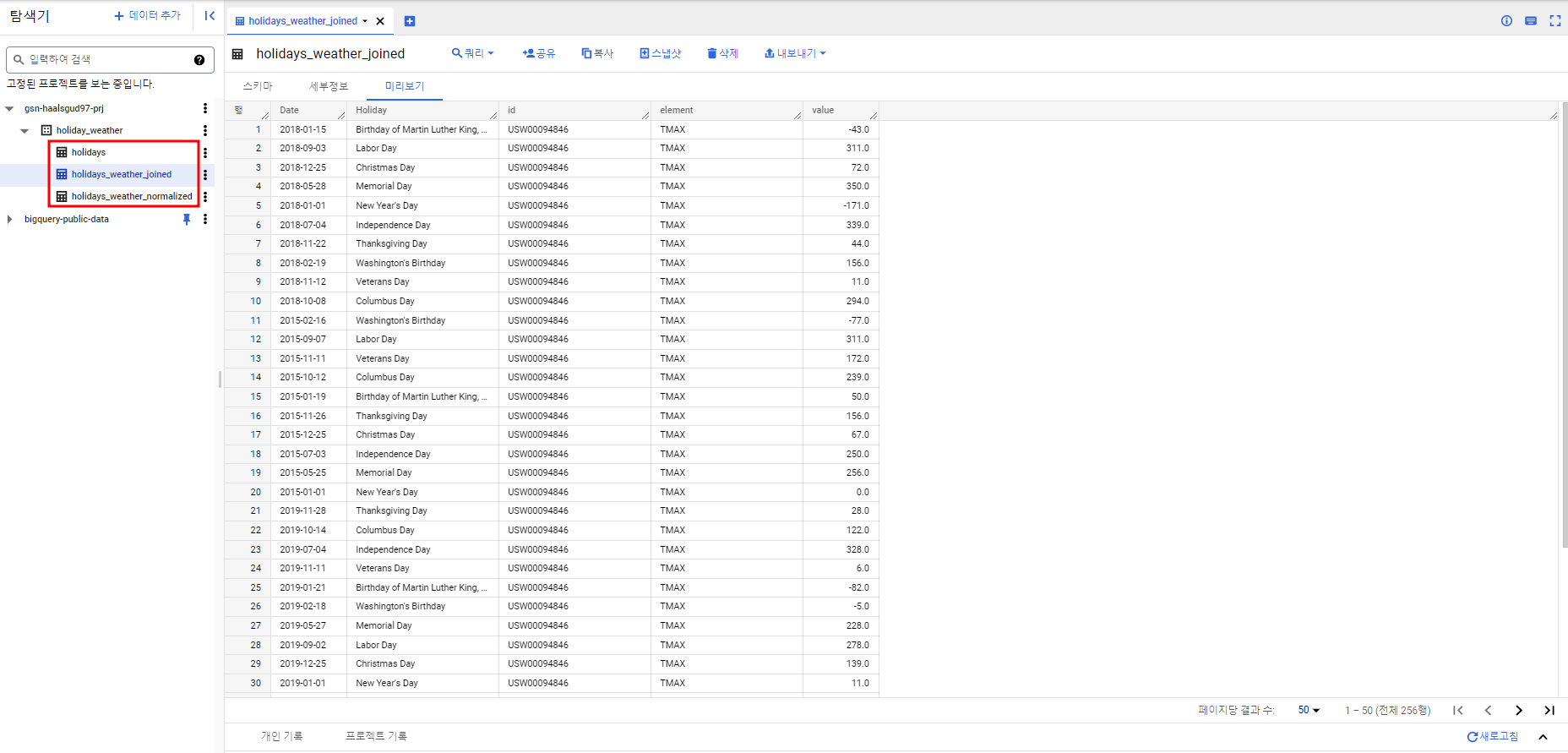
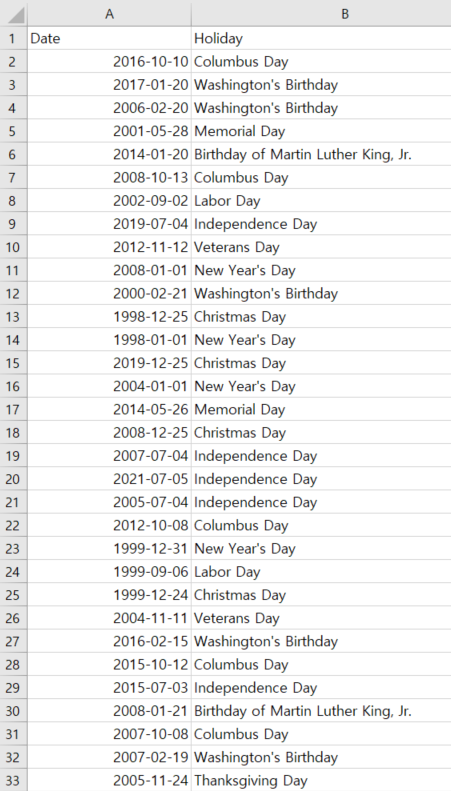
원래 csv파일에는 아래 사진처럼 Date와 Holiday밖에 없다.