GCP - Data
1.BigQuery

대용량 Dataset(최대 몇십 억개의 행)을 대화식으로 분석할 수 있는 웹 서비스대규모 데이터 저장 및 분석 플랫폼으로, 일종의 데이터 웨어하우스데이터 웨어하우스 : 축적된 데이터를 모아 관리하는 곳확장 가능하고 사용이 간편한 BigQuery를 통해 개발자와 기업은
2.BigQuery - 데이터 수집
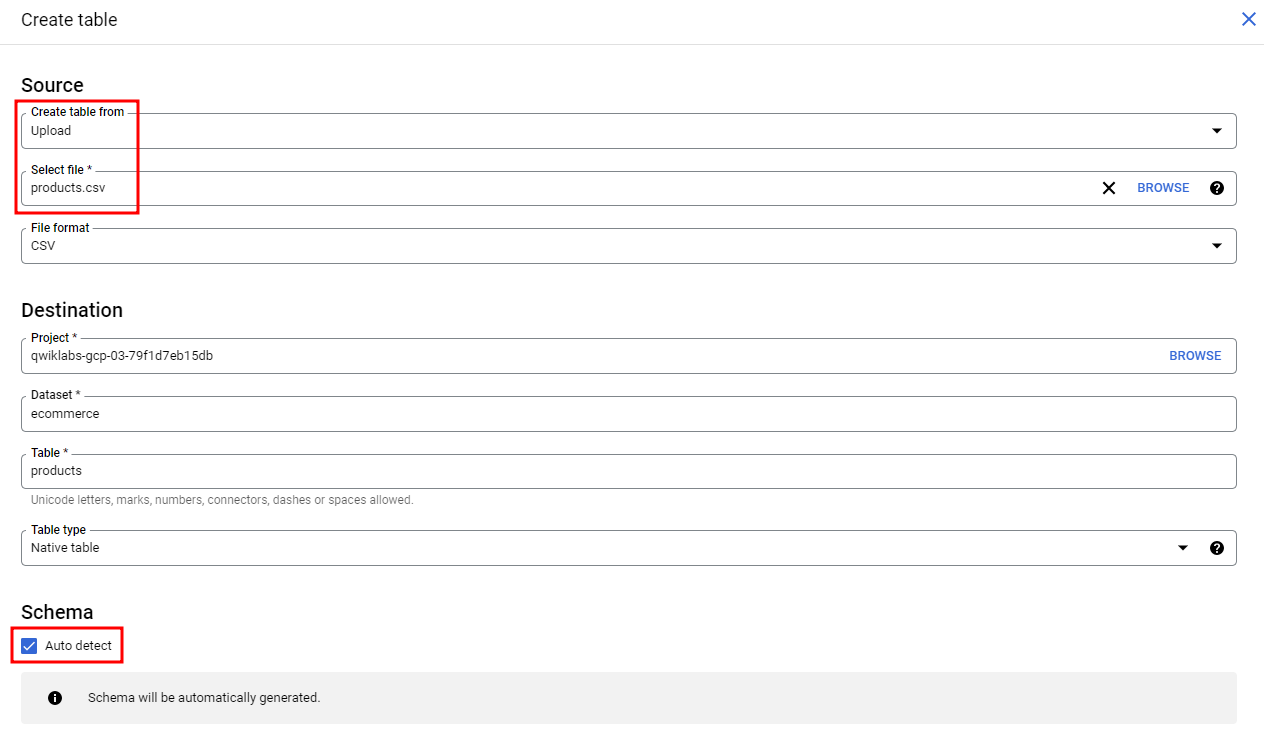
아래 csv파일 로컬로 다운로드products.csvecommerce Dataset생성, 테이블 생성 클릭로드된 데이터 탐색stockLevel이 가장 높은 상위 5개 제품 나열csv파일이 있는 cloud storage 경로를 넣어주어 생성재고 회전율을 기반으로 가장 재
3.BigQuery - 스키마 설계 (Array, Struct)
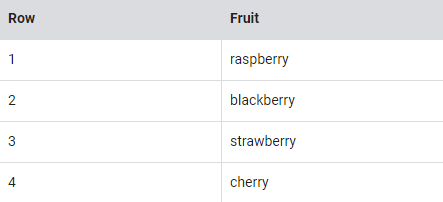
일반적으로 SQL에서는 아래 과일 목록과 같이 각 행에 대해 단일 값을 갖는다.상점에 있는 각 사람의 과일 품목 목록을 원하면?아래와 같이 볼 수 있다.기존의 관계형 데이터베이스 SQL에서는 이름의 반복을 보고 즉시 위의 테이블을 과일 항목과 사람이라는 두 개의 개별
4.BigQuery - 테이블 종류와 파티션
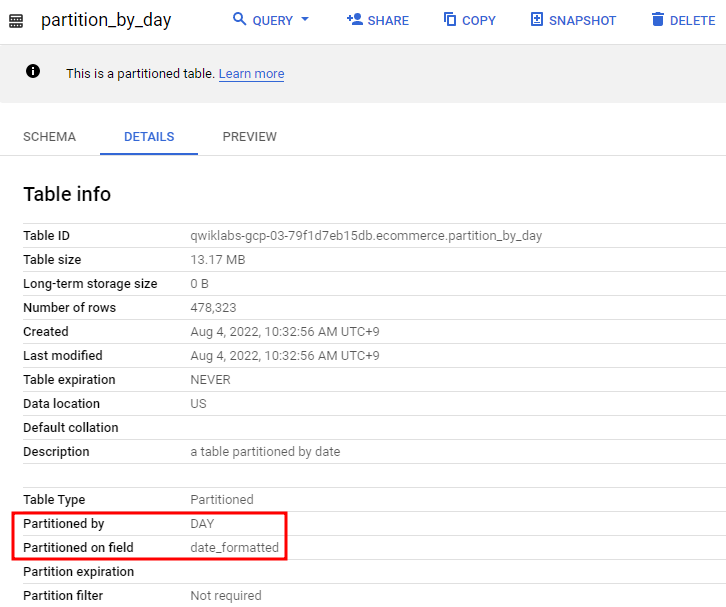
파티션에 사용할 수 있는 두 가지 옵션은 DATE 및 TIMESTAMP가 있다.날짜로 파티션을 나눈 테이블의 일반적인 사용 사례특정 기간 동안의 레코드에만 관심이 있는 경우 WHERE 조건에 대해 행을 비교하기 위해 매번 전체 데이터 세트를 스캔하는 것은 낭비이다.ex
5.BigQuery - 테이블 스냅샷 & 클론
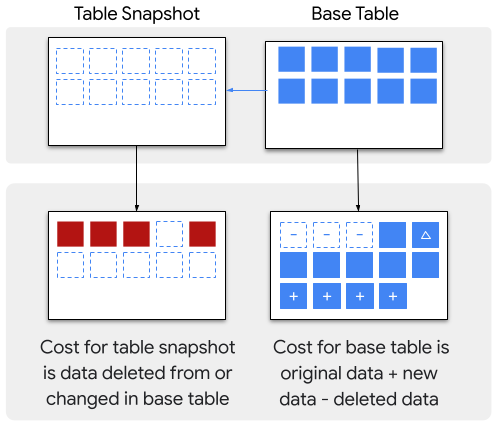
테이블 스냅샷은 특정 기간의 테이블을 백업해두는 거라고 생각하면 된다.여기서 특정 기간이라고 하면 빅쿼리의 Time Travel 기간인 최대 7일 전의 테이블 데이터에 한해서 스냅샷을 만들 수 있다.스냅샷은 읽기 전용이지만 그 스냅샷을 갖고 표준 테이블을 생성할 수 있
6.BigQuery 예약
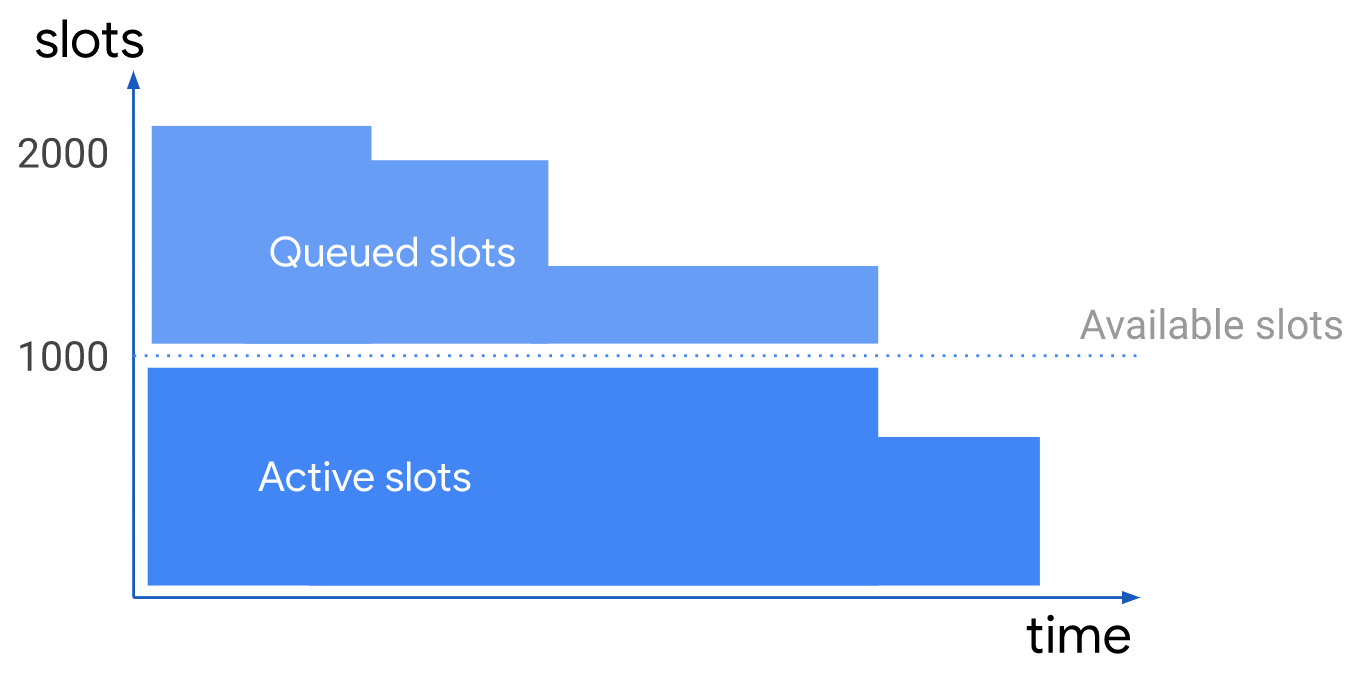
먼저 예약을 말하기 전에 슬롯이라는 개념부터 알아야 한다.슬롯은 SQL 쿼리를 실행하기 위해 BigQuery에 사용되는 가상 CPU.예약은 바로 빅쿼리를 쓸 때 이 슬롯 용량을 구매해서 쓰는 것을 말한다.쿼리는 해당 용량 범위 내에서 실행되며, 일반적으로 슬롯을 더 많
7.BigQuery Authorized View
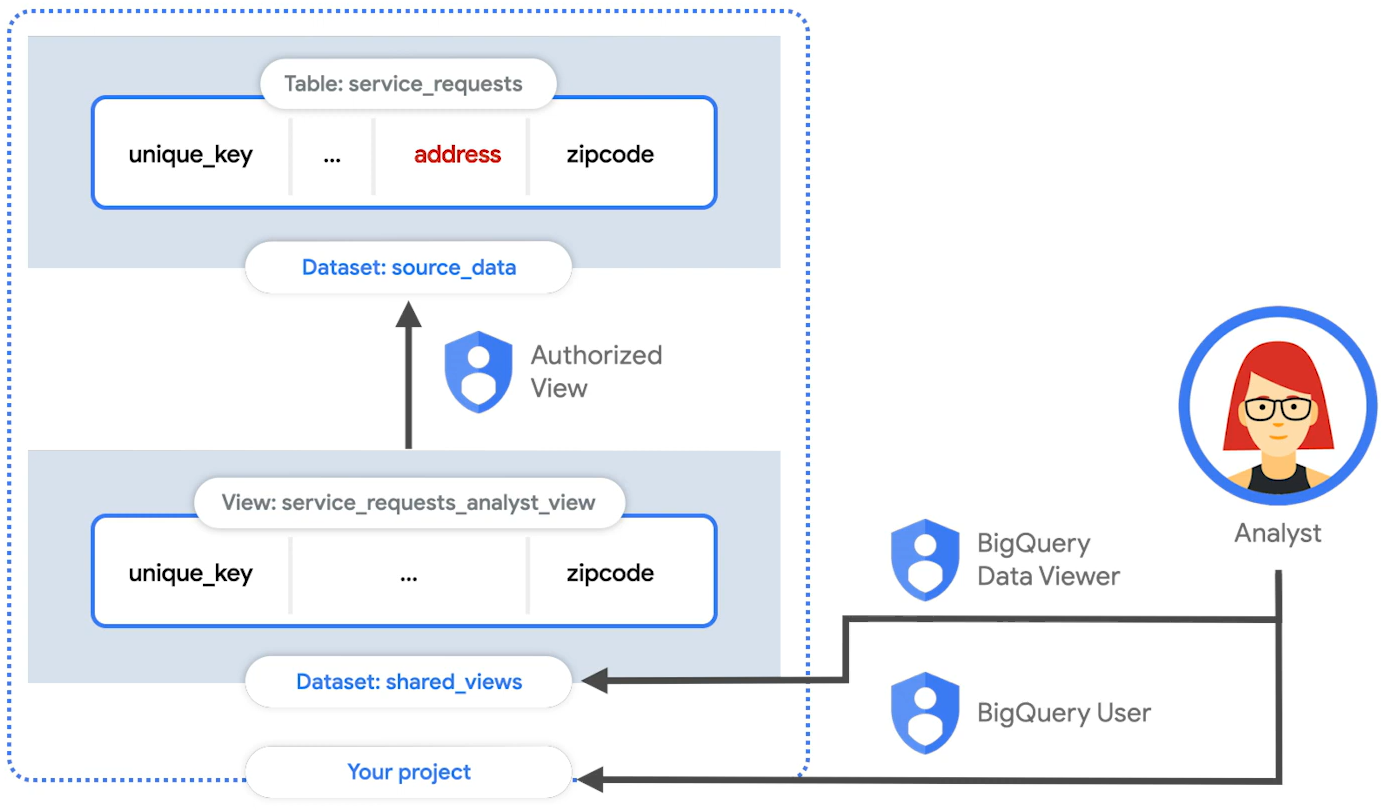
승인된 뷰를 사용하면 기본 소스 데이터에 대한 액세스 권한을 부여하지 않고도 특정 사용자 및 그룹과 쿼리 결과를 공유할 수 있다.일반 뷰 vs 승인된 뷰데이터 엔지니어링 팀은 로우 데이터의 많은 테이블이 있는 데이터 세트를 유지 관리하지만 이러한 테이블의 하위 집합을
8.Fluentd와 BigQuery를 사용한 실시간 로그 분석

Fluentd는 로그(데이터) 수집기(collector)다. 보통 로그를 수집하는 데 사용하지만, 다양한 데이터 소스(HTTP, TCP 등)로부터 데이터를 받아올 수 있다.Fluentd로 전달된 데이터는 tag, time, record(JSON) 로 구성된 이벤트로 처
9.Cloud Pub/Sub

GCP의 메시징 서비스로 Kafka나 래빗MQ와 같은 오픈소스 메시징 서비스와 동일한 서비스글로벌 규모에서도 낮은 지연 시간과 안정적인 메시지 전달을 제공해주고, 서버리스 환경이기 때문에 별도의 인스턴스를 관리할 필요없이 사용량에 따라 초당 수억 개까지 메시지를 확장할
10.Dataproc & Dataflow
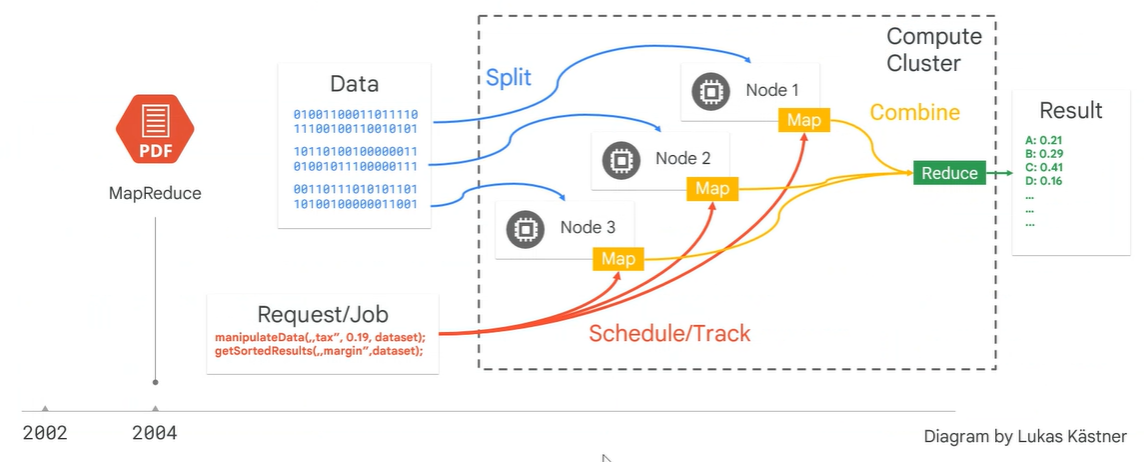
배치처리, 쿼리, 스트리밍,머신러닝을 managed해주는 구글클라우드의 Hadoop상품이라고 생각하면 된다.각 노드에 있는 디스크를 하나인 것처럼 클러스터링하여 사용할 수 있는것HDFS(Hadoop Distributed File System)에 데이터가 분산 저장된다.
11.Cloud Dataproc 사용해보기
기존의 하둡의 환경을 구성할 땐 마스터 노드와 작업자 노드를 연결시키는 것부터가 매우 어려운 과제였지만 Dataproc을 활용하면 매우 손쉬게 마스터 노드와 작업자 노드를 구성할 수 있다.API 활성화my-cluster라는 이름으로 기본 설정값을 가진 클러스터를 만들어
12.Dataflow(Apache Beam) 간단 문법

Dataflow는 Apache Beam을 기반으로 한다.Python 말고 다른 언어(Java, Go)를 알고 싶으면 Apache Beam 프로그래밍 가이드 -> 참고아파치 빔을 기반으로 하기 때문에 import 역시 'apache_beam'을 import에서 사용한다.
13.Dataflow 템플릿 커스텀해보기

빅쿼리 데이터 세트 생성timestamp, INT/FLOAT 유형의 컬럼, STRING 유형의 컬럼을 가지는 테이블 생성Dataflow가 동작하는 스테이지의 파일을 저장할 Cloud Storage 버킷 생성ps_to_bq.py실행콘솔에서 Pub/Sub 주제에 직접 메시
14.Dataflow SQL을 사용한 스트리밍 파이프라인 구축
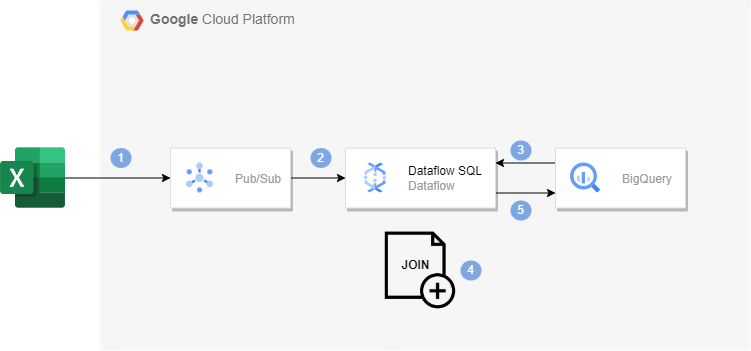
Dataflow SQL을 사용해 Pub/Sub 스트리밍 데이터를 BigQuery 테이블 데이터와 join해볼 것이다.빅쿼리에 데이터 세트를 만들어주고 us_state_salesregions 테이블을 만들어준다.us_staste_salesregions.csv이 csv파일
15.Dataflow를 사용한 Kafka to BigQuery 스트리밍 파이프라인 구축
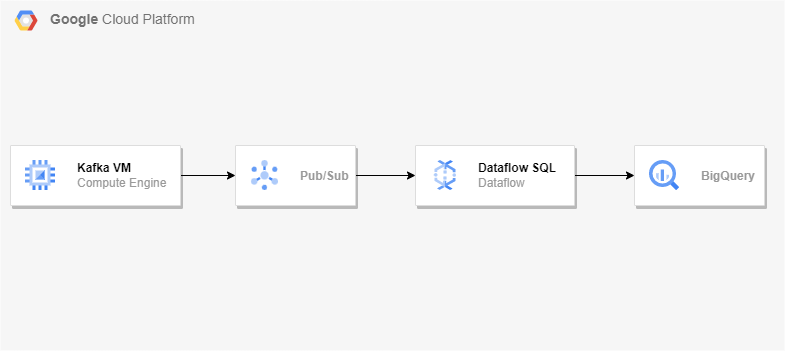
우분투 VM 하나 생성 후 아래 명령어 차례로 입력Apache Kafka 다운로드kafka와 zookeeper를 systemctl 명령을 사용하여 시작/중지하도록 설정zookeeper아래의 내용 추가kafka아래의 내용 추가새로운 변경사항을 적용하기 위해 systemd
16.Dataflow를 사용한 S3 to BigQuery 파이프라인 구축
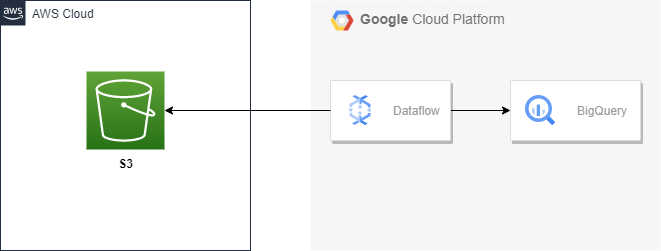
일회성 마이그레이션이나 멀티 클라우드 환경을 쓰고 있지 않는 이상 클라우드간 네트워크 송신 비용이 나가기 때문에 이런 케이스가 많이 있는 편은 아니다.아래와 같은 csv파일에서 각 user_id에 대해 전송된 total amount를 계산해볼 것이다. user_id가
17.Cloud Functions을 사용한 GCS to BigQuery 파이프라인 구축
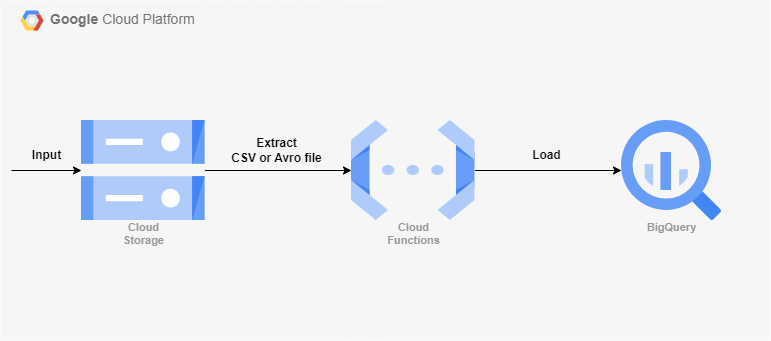
Cloud Storage에 들어오는 데이터를 빅쿼리로 적재하게끔 트리거를 걸 수 있는 Functions을 테스트해보았다.샘플 데이터는 Sample CSV file 에서 받았다.다운 받은 CSV(633KB)빅쿼리에 데이터 세트와 테이블, Cloud Storage에 버킷을
18.Cloud Functions - GCS folder trigger
GCS to BigQuery 파이프라인 구축에서 이어지는 내용.앞의 포스팅과 같은 구조에서 'Cloud Storage에 지속적으로 쌓이는 csv파일들이 한 테이블에 계속해서 쌓이게끔 해줄 수는 없는가?'와 같은 요구조건이 있을 수 있다.ex) 한 달치 데이터가 계속해서
19.Cloud Scheduler를 사용한 Pub/Sub to BigQuery 스트리밍 파이프라인 구축
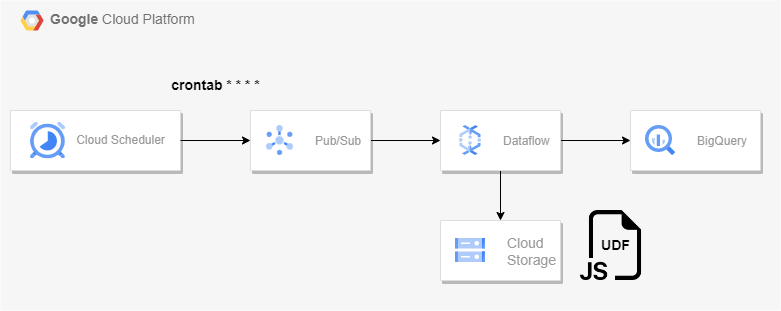
Dataflow의 Pub/Sub Topic to BigQuery 템플릿을 사용해 스트리밍 파이프라인을 구축할 것이다.Pub/Sub으로 메시지를 게시하는 것은 우선 Cloud Scheduler를 사용하였다.Pub/Sub 주제를 하나 기본 구독을 하나 추가해서 만들어준다.
20.Twitter API를 사용한 스트리밍 파이프라인 구축
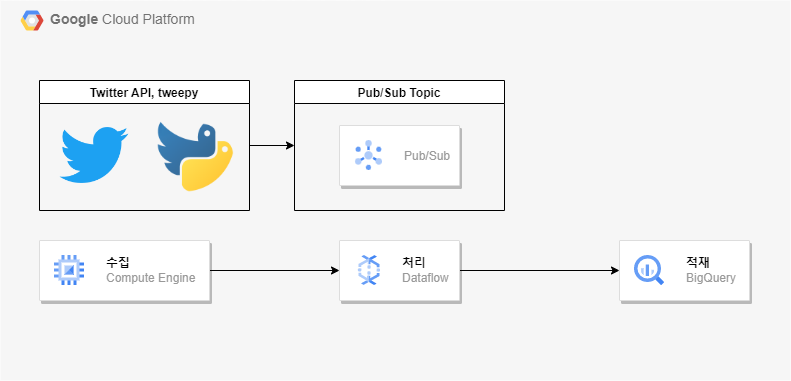
우선 Twitter API를 통해 ACCESS 및 Bearer Token 등을 받아온 상태여야 한다.이 키가 내 트위터 계정에 대한 정보를 잘 받아오는 지 확인하려면 아래 명령어를 실행시켜보면 된다.잘 받아오는 것 확인.그리고 GCP 콘솔에서 아래 리소스들을 생성해준다
21.Cloud Composer 사용해보기
Cloud Composer는 데이터 분석 워크플로우를 오케스트레이션 해주는 Apache Airflow의 구글 클라우드 managed 리소스이다.Airflow프로그래밍 방식으로 워크플로를 작성, 예약 및 모니터링하는 플랫폼Airflow를 사용하여 작업의 DAG(Dire
22.Cloud Composer - ELT 파이프라인 구축
Airflow가 지원하는 Operator중 GoogleCloudStorageToBigQueryOperator를 사용해 ELT 파이프라인을 구축해볼 것이다.내 버킷을 하나 생성해준다.git clone으로 해당 리포지토리를 받은 다음 이 파일들을 gsutil cp를 통해
23.Cloud Composer - Dataflow를 사용한 ETL 파이프라인 구축
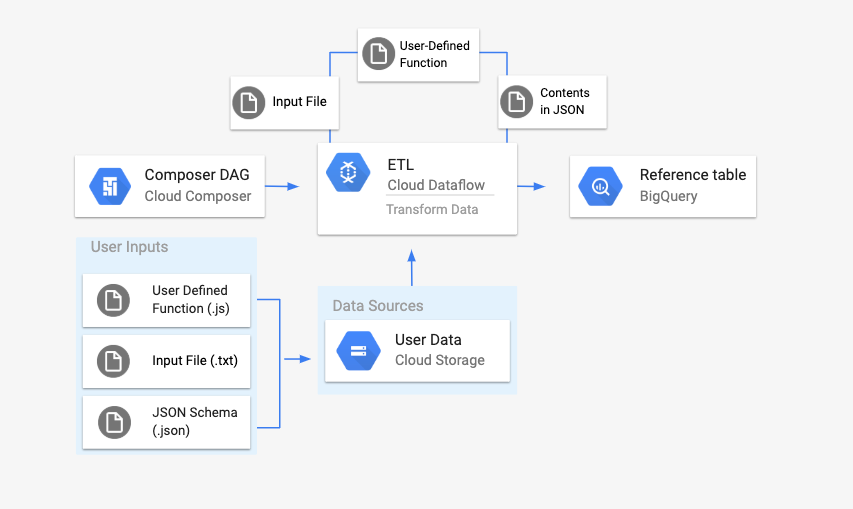
DataflowTemplateOperator를 사용하여 Cloud Composer에서 Dataflow 파이프라인을 실행해볼 것이다.Composer 환경을 생성하는데 Composer 버전이 1.9이상이어야 해서 Composer2 버전으로 만들어줬다.average_weat
24.Cloud Composer - AWS S3의 데이터를 사용하여 GCP에서 데이터 분석
DAG를 통해 BigQuery 공개 데이터 세트의 ghcn_d 데이터와 S3 버킷에 저장된 CSV 파일을 join한 다음 Dataproc 배치 작업을 실행하여 결합한 데이터를 처리하여 빅쿼리에 적재하는 실습을 해볼 것이다.Composer 2 버전으로 환경을 생성해준다.
25.Cloud Data Fusion 사용해보기
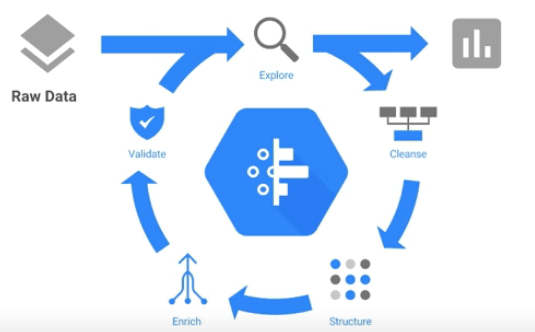
코드 작성 없이 마우스 클릭만으로 ETL/ELT 데이터 파이프라인을 배포할 수 있는 시각적 인터페이스로 CDAP라는 오픈소스 프로젝트를 기반으로 구축되었다.기본 설정으로 생성해주고 필요하면 고급 옵션에서 Stackdriver 로깅, 모니터링 설정을 해줄 수도 있다.그리
26.Cloud Data Fusion - ETL 파이프라인 구축
Wrangler를 사용해서 파이프라인을 배포해볼 것이다.Wrangler자동 또는 반자동화 도구로 데이터를 쉽게 사용할 수 있도록 데이터를 사용하기 좋은 형태로 변경하는 사람을 데이터 Wrangler라고 한다.Data Fusion에선 이런 랭글링 작업을 간편하게 할 수
27.Cloud Dataprep 사용해보기

Cloud Dataprep은 간단한 드래그 앤 드롭 브라우저 환경에서 데이터를 시각적으로 탐색 및 정리하고 분석이 가능하도록 여러 데이터 세트를 준비하는 데 활용되는 지능형 데이터 서비스이다.데이터를 내 입맛대로 바꾸면 내부에서 Dataflow를 통해서 데이터를 변경한
28.BigLake
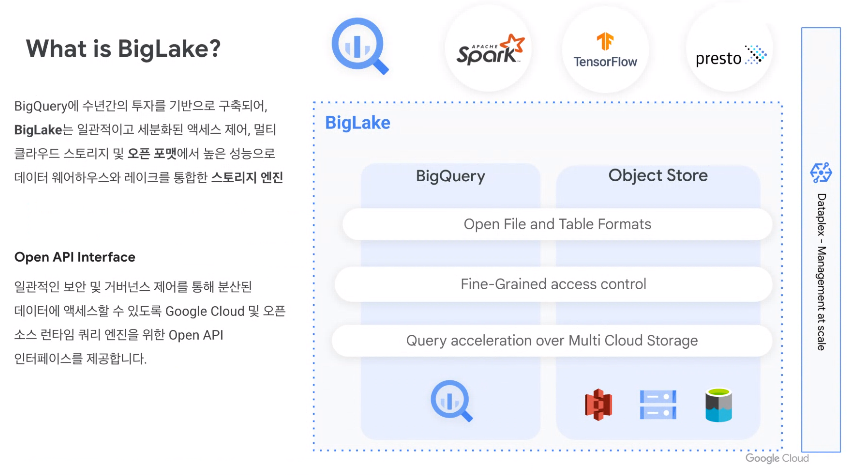
빅쿼리의 차세대 솔루션으로 데이터 웨어하우스 + 데이터 레이크의 형태BigLake 는 멀티 클라우드 스토리지 및 개방형 형식을 통해 균일하고 세분화된 액세스 제어를 제공하여 데이터 웨어하우스 및 데이터 레이크에 대한 데이터 액세스를 단순화하는 통합 스토리지 엔진BigL
29.BigQuery Omni
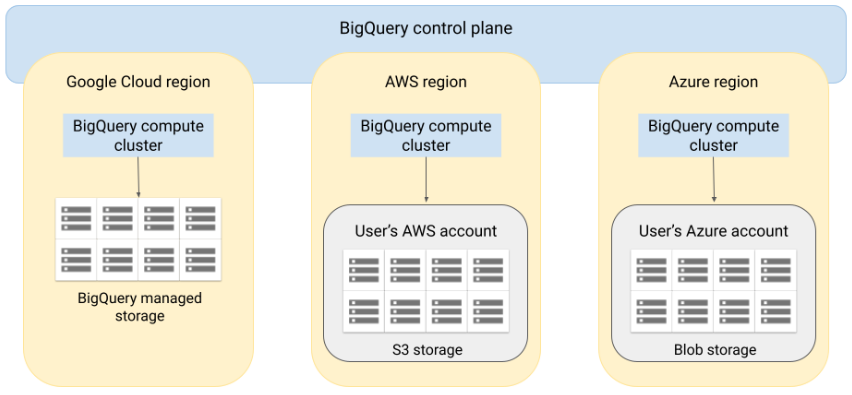
데이터가 있는 위치에서 데이터를 분석하는 기능과 필요에 따라 데이터를 복제할 수 있는 유연성이 포함된 클라우드 간 분석 솔루션Amazon S3 또는 Azure blob storagee에 저장된 데이터에 대해 BigQuery 분석을 수행할 수 있다.BigQuery 아키텍
30.BigQuery Omni - AWS 연결
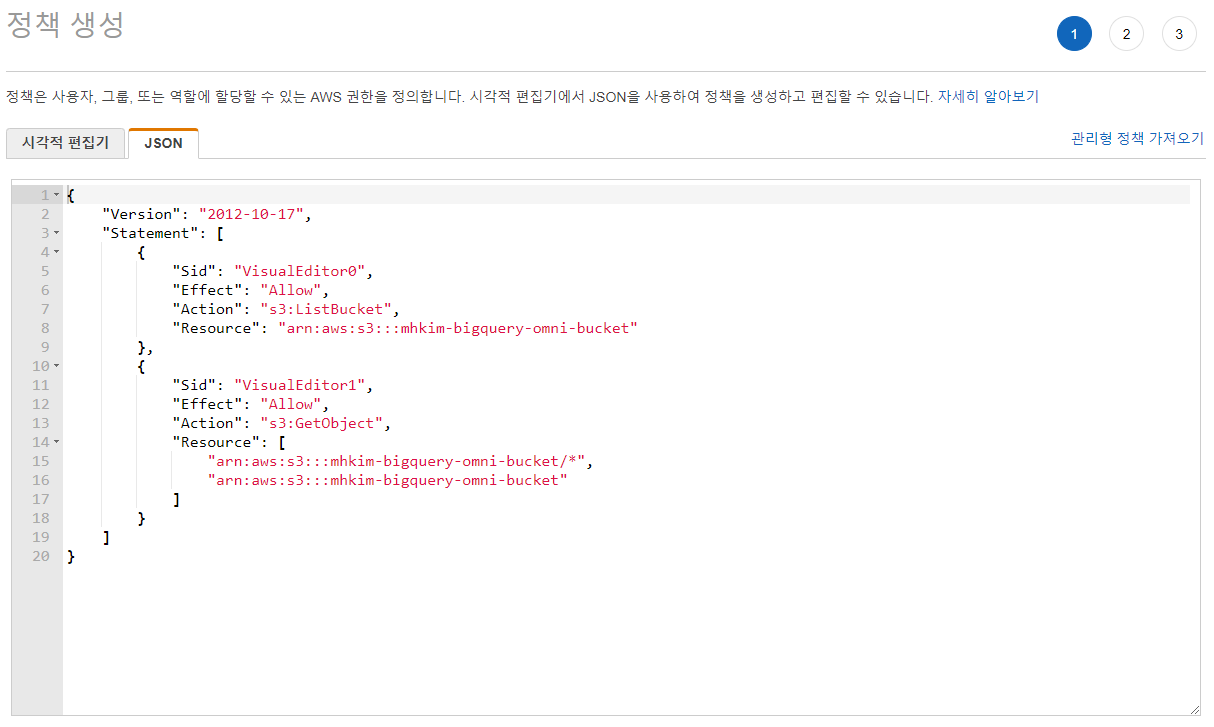
AWS에 연결하려면 AWS IAM 역할을 통해 사용자에게 권한을 부여하기 때문에 빅쿼리용 AWS IAM 역할을 만들어서 빅쿼리에 할당해줘야 연결할 수 있다.우선 BigQuery Connection API 사용이 설정되어 있어야 하고 빅쿼리에서 연결할 s3버킷을 하나 미
31.Data Catalog 사용해보기
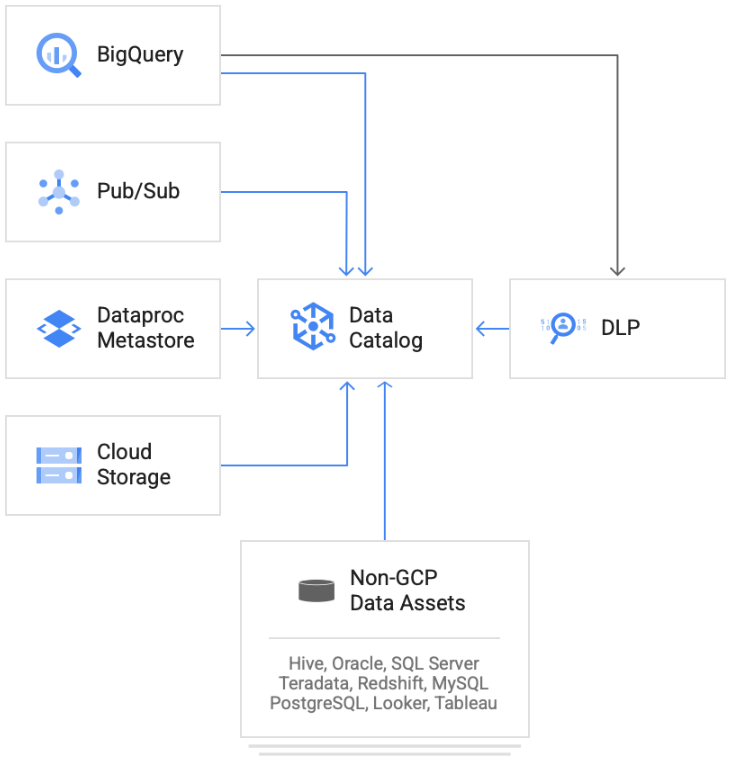
Data Catalog 는 Google Cloud의 Data Analytics 제품군에 포함된 확장 가능한 완전 관리형 메타데이터 관리 서비스데이터 자산 관리는 적절한 도구 없이는 시간과 비용이 많이 소요될 수 있다.Data Catalog는 조직이 데이터 자산을 찾고,
32.Cloud DLP와 Dataflow를 사용한 데이터 마스킹
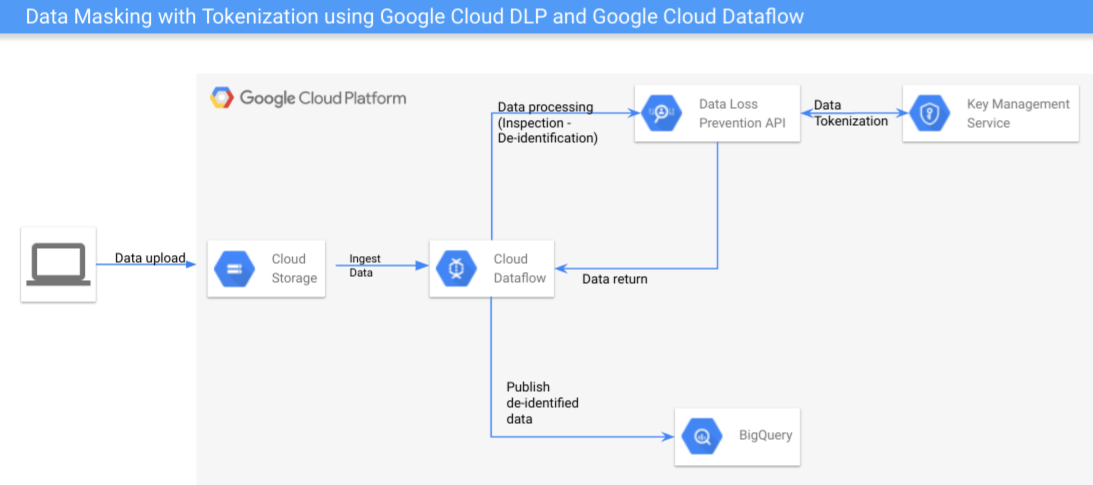
Cloud DLP는 민감한 정보가 포함된 것으로 의심되는 모든 데이터에 대해 검사 및 익명화를 제공하는 Google Cloud 도구Cloud DLP는 InfoType을 사용하여 문서 내에서 발견될 수 있는 민감한 데이터를 인식한다. InfoType은 특정 유형의 데이터
33.Cloud DLP와 Data Fusion을 사용한 데이터 마스킹
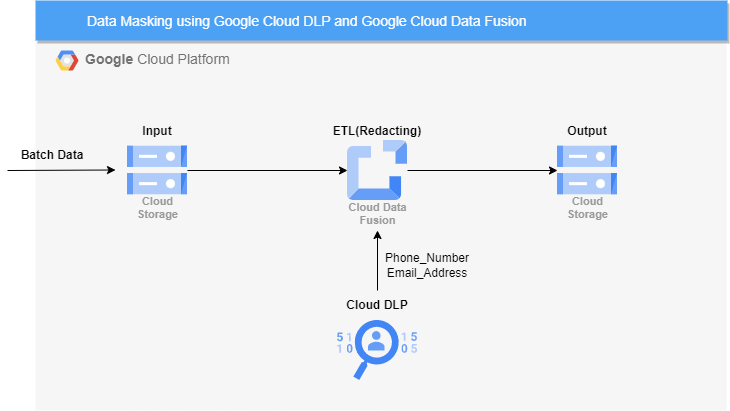
일전에 Cloud DLP와 Dataflow를 사용한 데이터 마스킹에서 데이터 마스킹을 다뤄본 적이 있다.이번엔 Data Fusion을 사용하여 데이터 마스킹을 해볼 것이다.우선 Cloud Storage 버킷을 하나 생성하고 input, output용 폴더를 하나씩 만들
34.Debezium을 사용한 Cloud SQL to BigQuery CDC 파이프라인 구축
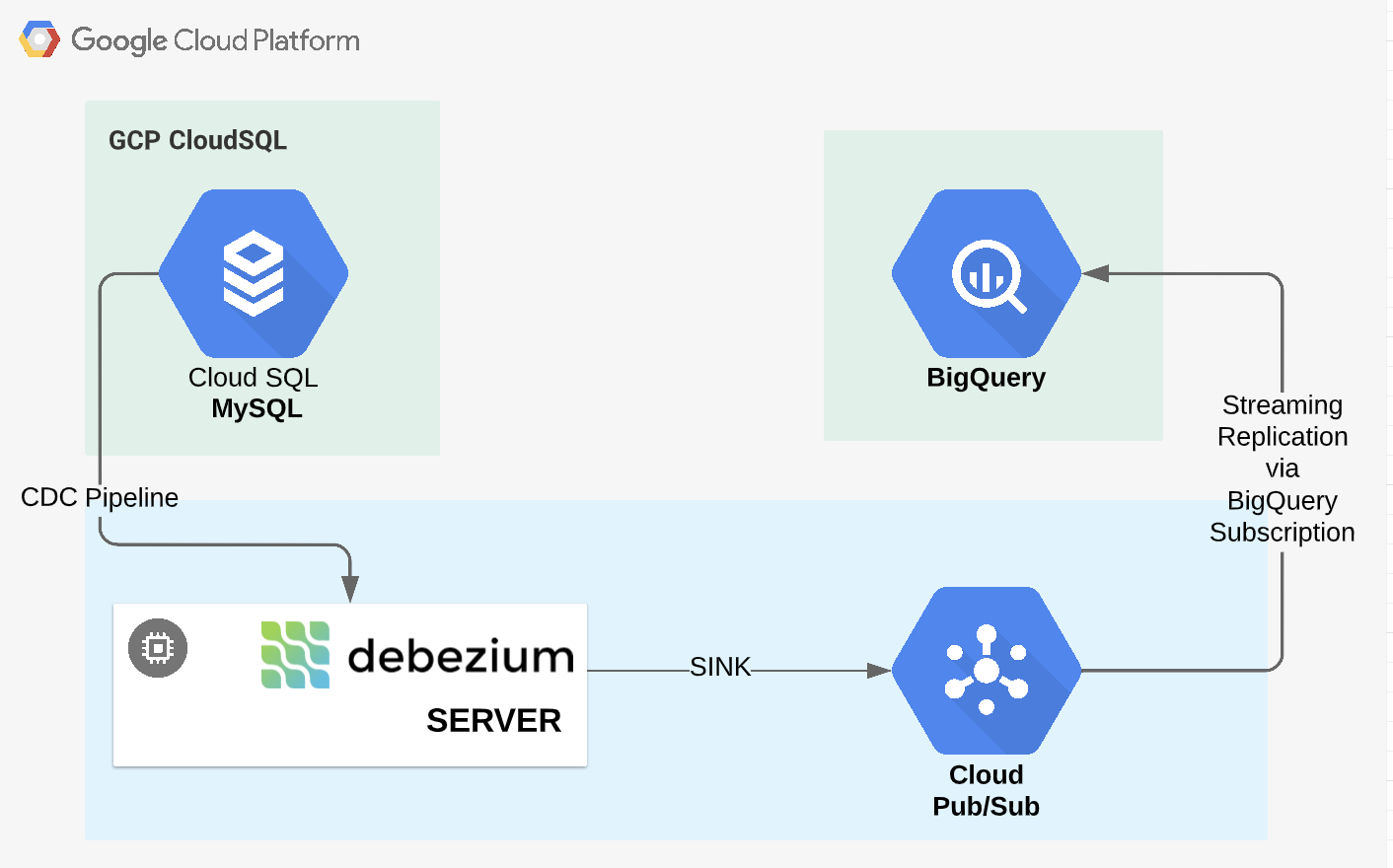
MySQL로 생성해주고 외부에서 접속을 해주기 위해 접속을 승인할 네트워크 대역을 지정해준다.해당 ip는 내 ip를 확인하여 지정해준 것이다.아래 명령어로 Cloud SQL 접속workbench와 같은 툴을 사용해도 되지만 Debezium 서버도 만들어야 하므로 Ubu
35.Datastream을 사용한 Cloud SQL to BigQuery CDC 파이프라인 구축
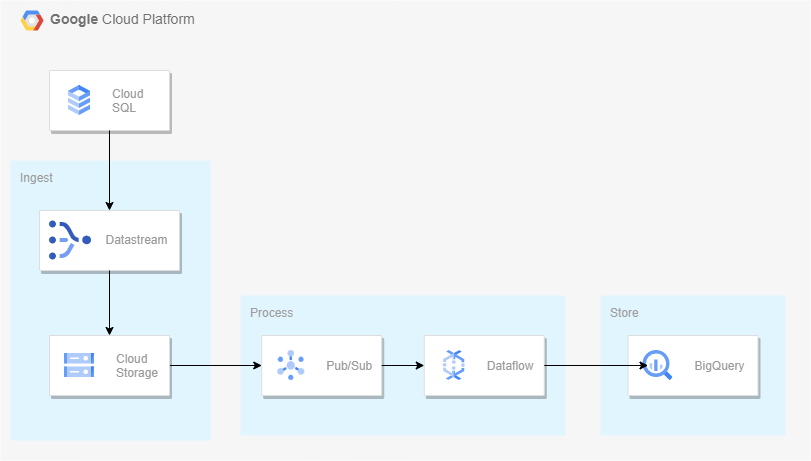
Datastream은 사용이 간편한 서버리스 CDC(변경 데이터 캡처) 및 복제 서비스.지연 시간을 최소화하면서 이기종 데이터베이스와 애플리케이션에서 데이터를 안정적으로 동기화할 수 있다.Datastream은 Oracle 및 MySQL,PostgreSQL 데이터베이스에
36.Datastream을 사용한 Amazon RDS to BigQuery CDC 파이프라인 구축
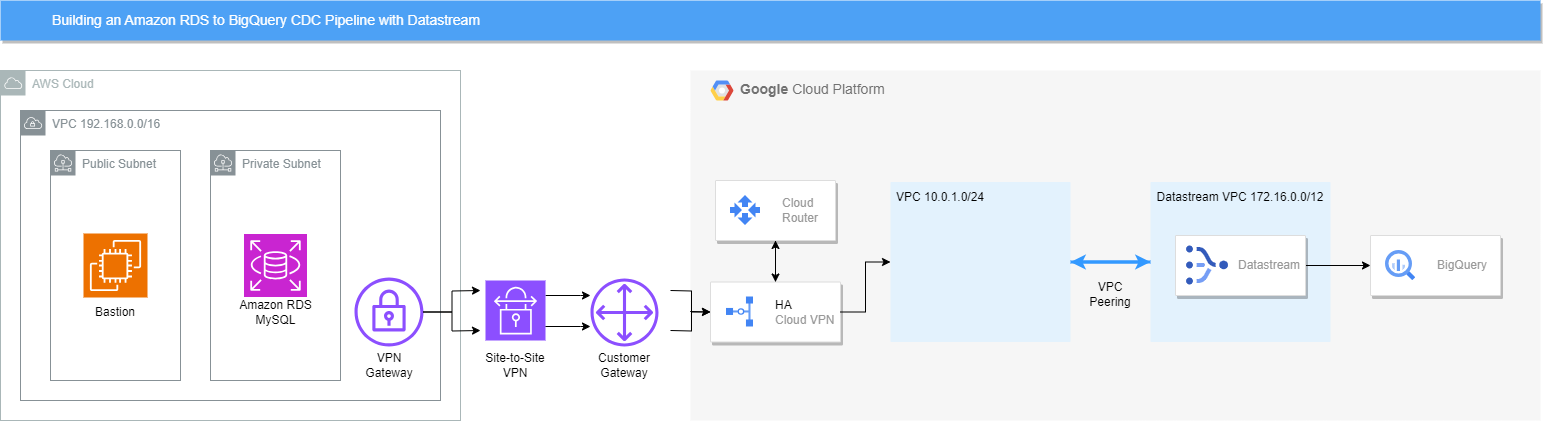
Datastream 관련 예전 포스팅 Datastream을 사용한 Cloud SQL to BigQuery CDC 파이프라인 구축 이후로 BigQuery로 바로 스트리밍 된다는 업데이트를 알게된 후 써봐야지 하다가.. 이제서야 써본다.전과 다른 점은 Public한 환경이
37.Cloud Run을 사용한 Pub/Sub to BigQuery 파이프라인 구축
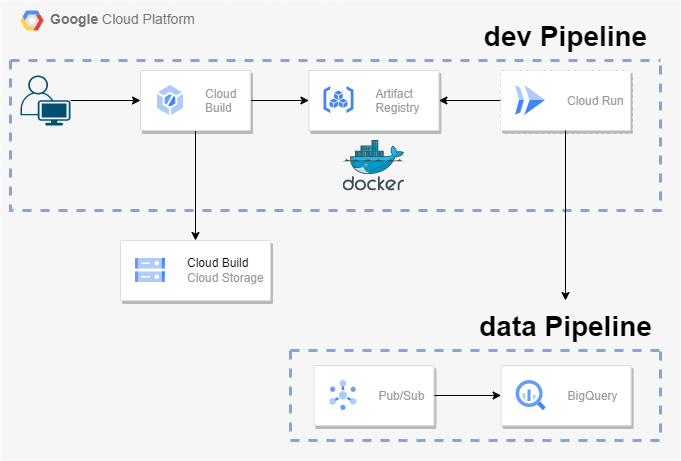
완전 관리형 서버리스 플랫폼에서 원하는 언어(Go, Python, 자바, Node.js, .NET)를 사용하여 확장 가능하고 컨테이너화된 앱을 빌드하고 배포할 수 있는 제품이다.즉, 도커같은 컨테이너만 준비해둔다면 매우 쉽게 해당 어플리케이션을 배포할 수 있는 것이다.
38.Workflows를 사용한 파이프라인 Orchestration
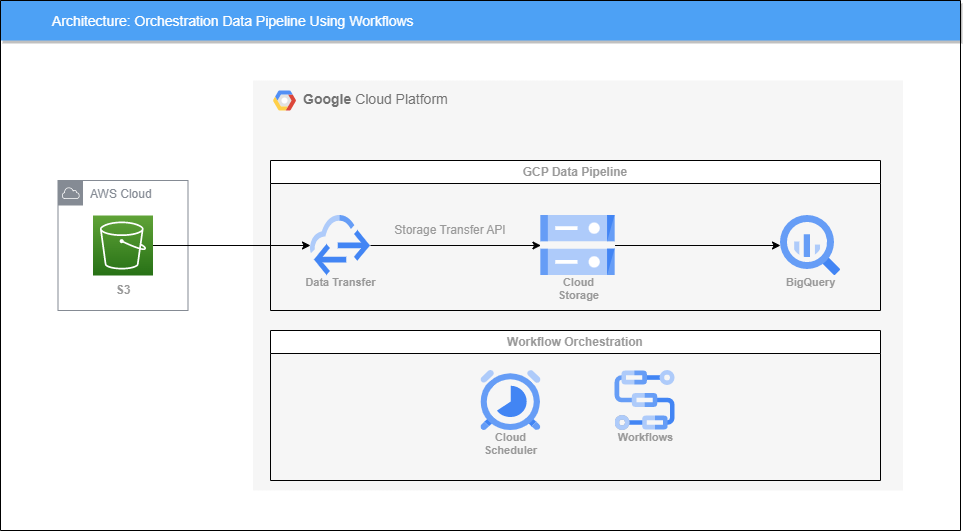
GCP의 대표적인 Workflow Orchestration 툴이라고 하면 Cloud Composer(Apache Airflow)를 말할 수 있지만 더욱 저렴한 Workflows라는 서비스가 있다.Workflows는 짧은 레이턴시의 event-driven 방식을 통해 애
39.Dataplex와 DPMS를 사용한 데이터 탐색
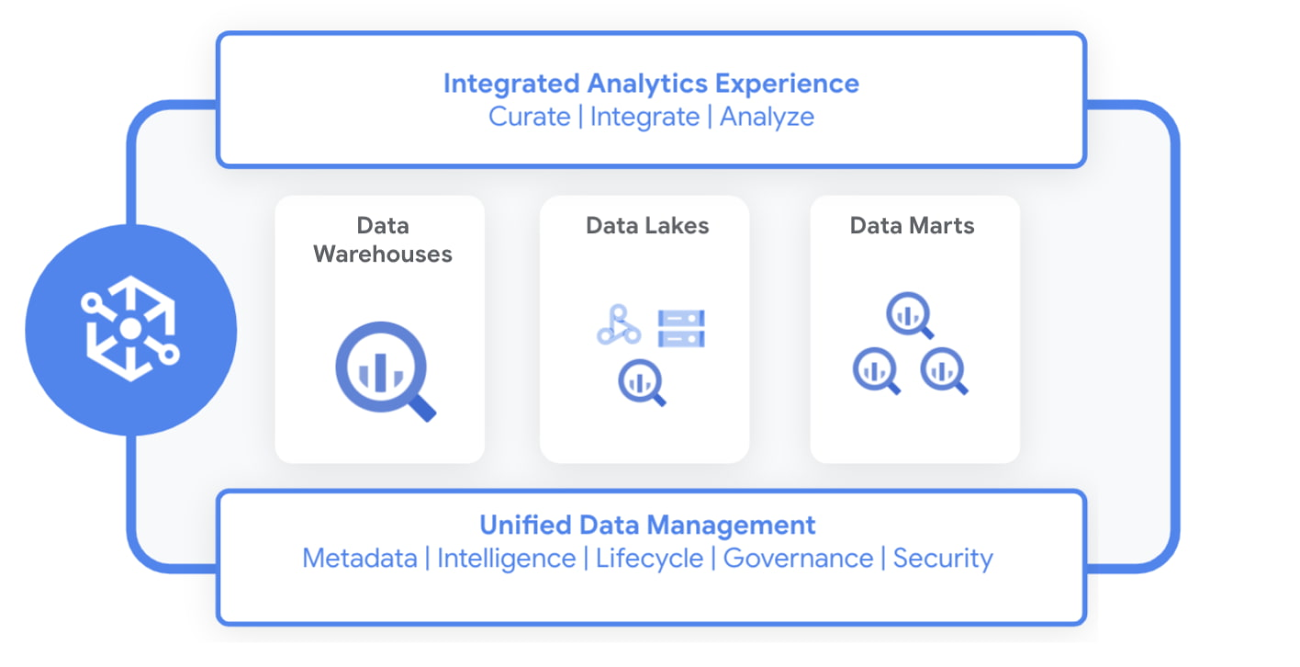
Dataplex란 데이터 레이크, 데이터 웨어하우스, 데이터 마트의 데이터를 중앙에서 관리, 모니터링, 제어하고 이 데이터를 다양한 분석 및 데이터 사이언스 툴에 안전하게 제공할 수 있는 지능형 데이터 패브릭으로 기존의 Data Catalog 서비스와 통합된 상품이다.
40.Dataproc Serverless를 사용한 Hive 마이그레이션
Dataproc Serverless를 사용하면 자체 클러스터를 프로비저닝하고 관리할 필요 없이 Spark 배치 워크로드를 실행할 수 있게 해준다.여기선 Dataproc Cluster에 Hive DB를 BigQuery로 마이그레이션 해볼 것이다.기존에는 이를 위해선 Co
41.embulk를 사용한 데이터 마이그레이션

데이터를 전송하는 오픈 소스 Bulk Data Loader. ETL에서 Transformation 외에 Extraction, Loading 에서 여러 plug-in을 제공.특징Input file format을 자동으로 인식병렬, 분산 수행 가능Transaction Co
42.tmp 디렉토리를 사용하여 Cloud Functions에 파일 저장하기

Cloud Functions은 AWS의 Lambda와 같은 Serverless 실행 환경.Cloud Functions의 경우 Cloud Storage, Cloud Pub/Sub, HTTP등을 통해 트리거를 걸 수 있다. 예를 들어 Cloud Storage를 통해 트리거
43.BigQuery DataFrames - Efficient, Scalable Data Processing
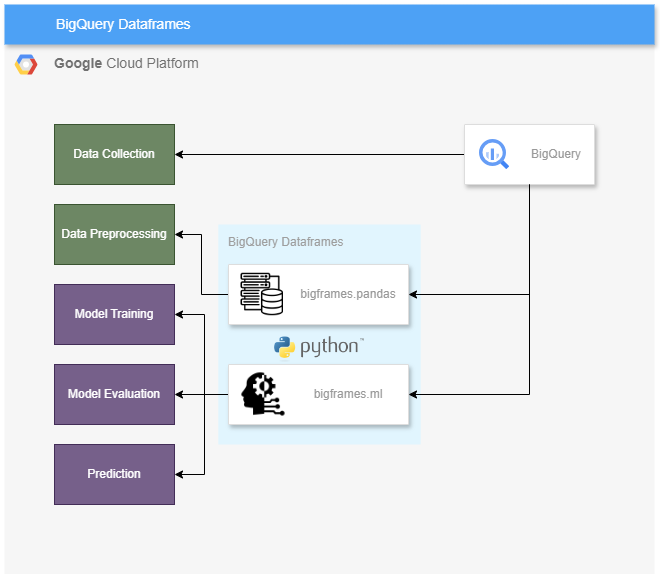
BigQuery DataFrames는 BigQuery 데이터를 분석하고 머신러닝 작업을 수행하는 데 사용할 수 있는 Python 클라이언트 라이브러리이다.bigfrmaesbigframes.pandas는 BigQuery 상단에 pandas-like-API 구현.bigfr
44.Dataform을 사용한 ELT 파이프라인 구축
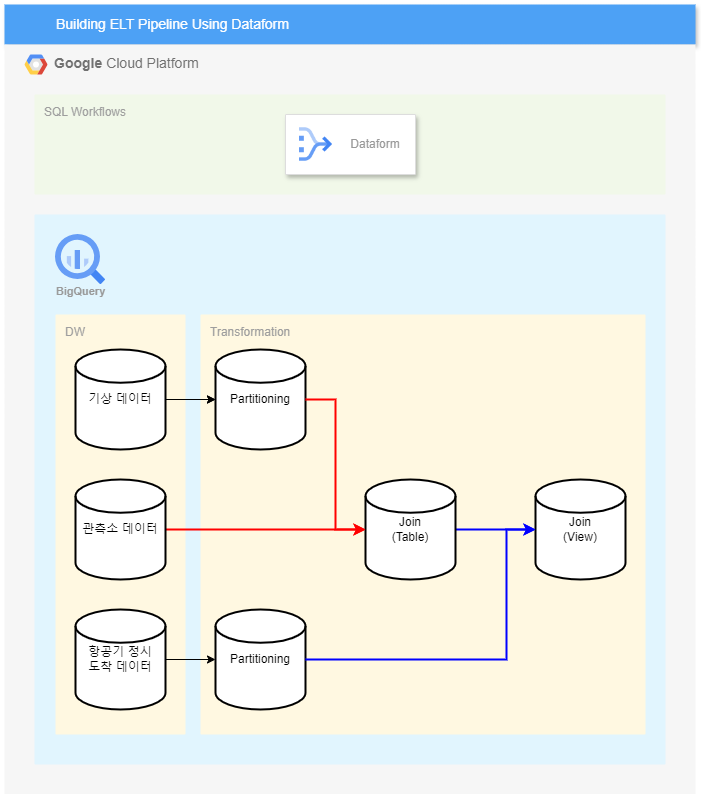
데이터 분석가가 BigQuery에서 데이터 변환을 수행하는 복잡한 SQL 워크플로를 개발, 테스트, 버전 관리 및 예약하는 서비스.Dataform을 사용하면 ELT(추출, 로드, 변환) 프로세스에서 데이터 변환을 관리할 수 있다.특징SQLX라는 SQL과 비슷한 언어로