Airflow가 지원하는 Operator중 GoogleCloudStorageToBigQueryOperator를 사용해 ELT 파이프라인을 구축해볼 것이다.
Cloud Storage에 파일 업로드
내 버킷을 하나 생성해준다.
git clone https://github.com/onlybooks/bigquery.gitgit clone으로 해당 리포지토리를 받은 다음
이 파일들을 gsutil cp를 통해 내 버킷에 올려놓는다.
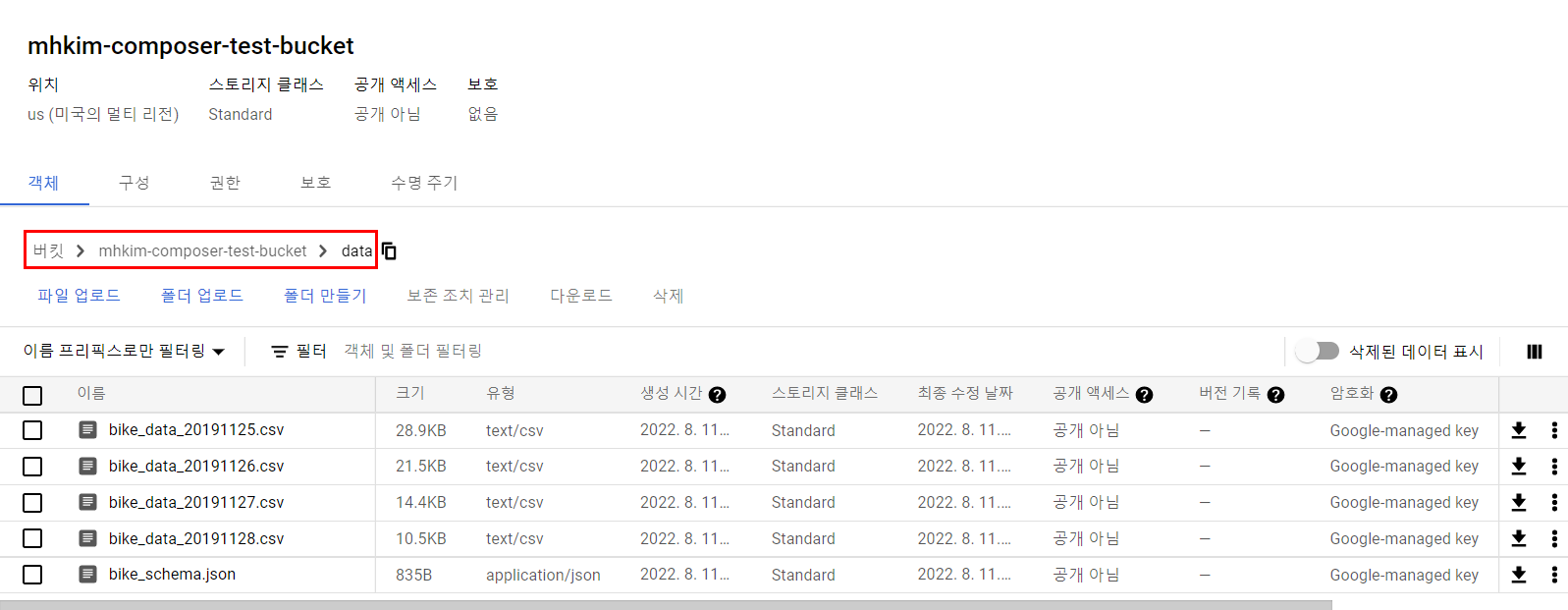
data 폴더를 만들고 그 안에 넣어준다.
빅쿼리로 가서 temp dataset 생성
Cloud Storage to BigQuery Task 작성
simple-elt-bigquery
여기의 코드를 가져왔다.
from airflow import DAG
from datetime import datetime, timedelta
from airflow.contrib.operators.gcs_to_bq import GoogleCloudStorageToBigQueryOperator
from airflow.contrib.operators.bigquery_operator import BigQueryOperator
PROJECT_ID='<프로젝트 ID>'
BUCKET_NAME = '<버킷 이름>'
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2019, 11, 25),
'end_date': datetime(2019, 11, 29),
'retries': 1,
'retry_delay': timedelta(minutes=1),
'project_id': PROJECT_ID
}
dag = DAG('simple_elt_storage_to_bigquery',
default_args=default_args,
schedule_interval='30 0 * * *')
execution_date = '{{ ds_nodash }}'
storage_to_bigquery_task = GoogleCloudStorageToBigQueryOperator(
dag=dag,
google_cloud_storage_conn_id='google_cloud_default',
bigquery_conn_id='google_cloud_default',
task_id='storage_to_bigquery',
bucket=BUCKET_NAME,
schema_object='data/bike_schema.json',
source_objects=[f"data/bike_data_{execution_date}.csv"],
source_format='CSV',
destination_project_dataset_table=f'{PROJECT_ID}.temp.bike_{execution_date}',
write_disposition='WRITE_TRUNCATE',
skip_leading_rows=1
)DAG에서 사용할 기본 파라미터는 default_args에 저장한다.
default_args
- owner
해당 DAG의 주인을 의미 - depends_on_past
과거 스케줄링된 DAG의 성공 유무에 따라 그 이후 스케줄링을 실행할지 말지를 결정하는 인자. False를 지정하면 과거 스케줄링이 실패해도 실행 시점이 되면 DAG를 실행한다. - start_date, end_date
실행과 종료 시점을 나타낸다.
GoogleCloudStorageToBigQueryOperator 설정을 통해 빅쿼리에 temp dastaset에 bike 테이블로 데이터들이 적재된다.
쿼리를 실행해 결과값을 table로 저장하는 Task 작성
일자별 시작역, 종착역별 건수를 집계하는 테이블을 생성할 것이다.
테이블은 bike_agg라는 테이블에 따로 집계해서 만들어질 것이다.
agg_query = f"""
SELECT
start_date, start_station_id, end_station_id, COUNT(bikeid) as cnt
FROM `{PROJECT_ID}.temp.bike_{execution_date}`
GROUP BY start_date, start_station_id, end_station_id
"""
query_task = BigQueryOperator(
dag=dag,
task_id="query_to_table",
bigquery_conn_id='google_cloud_default',
sql=agg_query,
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
destination_dataset_table=f"temp.bike_agg_{execution_date}"
)이제 태스크를 연결하면 DAG가 완성된다. 태스크 연결은 >> or <<를 사용한다. A >> B는 A 태스크가 성공적으로 실행된 후 B 태스크를 실행하라는 의미이다.
완성된 코드
simple-elt-bigquery.py
from airflow import DAG
from datetime import datetime, timedelta
from airflow.contrib.operators.gcs_to_bq import GoogleCloudStorageToBigQueryOperator
from airflow.contrib.operators.bigquery_operator import BigQueryOperator
PROJECT_ID= '프로젝트 ID'
BUCKET_NAME = '생성한 버킷 이름'
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2019, 11, 25),
'end_date': datetime(2019, 11, 29),
'retries': 1,
'retry_delay': timedelta(minutes=1),
'project_id': PROJECT_ID
}
dag = DAG('simple_elt_storage_to_bigquery',
default_args=default_args,
schedule_interval='30 0 * * *')
execution_date = '{{ ds_nodash }}'
storage_to_bigquery_task = GoogleCloudStorageToBigQueryOperator(
dag=dag,
google_cloud_storage_conn_id='google_cloud_default',
bigquery_conn_id='google_cloud_default',
task_id='storage_to_bigquery',
bucket=BUCKET_NAME,
schema_object='data/bike_schema.json',
source_objects=[f"data/bike_data_{execution_date}.csv"],
source_format='CSV',
destination_project_dataset_table=f'{PROJECT_ID}.temp.bike_{execution_date}',
write_disposition='WRITE_TRUNCATE',
skip_leading_rows=1
)
agg_query = f"""
SELECT
start_date, start_station_id, end_station_id, COUNT(bikeid) as cnt
FROM `{PROJECT_ID}.temp.bike_{execution_date}`
GROUP BY start_date, start_station_id, end_station_id
"""
query_task = BigQueryOperator(
dag=dag,
task_id="query_to_table",
bigquery_conn_id='google_cloud_default',
sql=agg_query,
use_legacy_sql=False,
write_disposition='WRITE_TRUNCATE',
destination_dataset_table=f"temp.bike_agg_{execution_date}"
)
storage_to_bigquery_task >> query_task파이프라인 실행
Composer를 하나 생성해주고 위의 py파일을 Composer가 생성되면 자동으로 만들어지는 버킷의 dags폴더에 넣어준다.
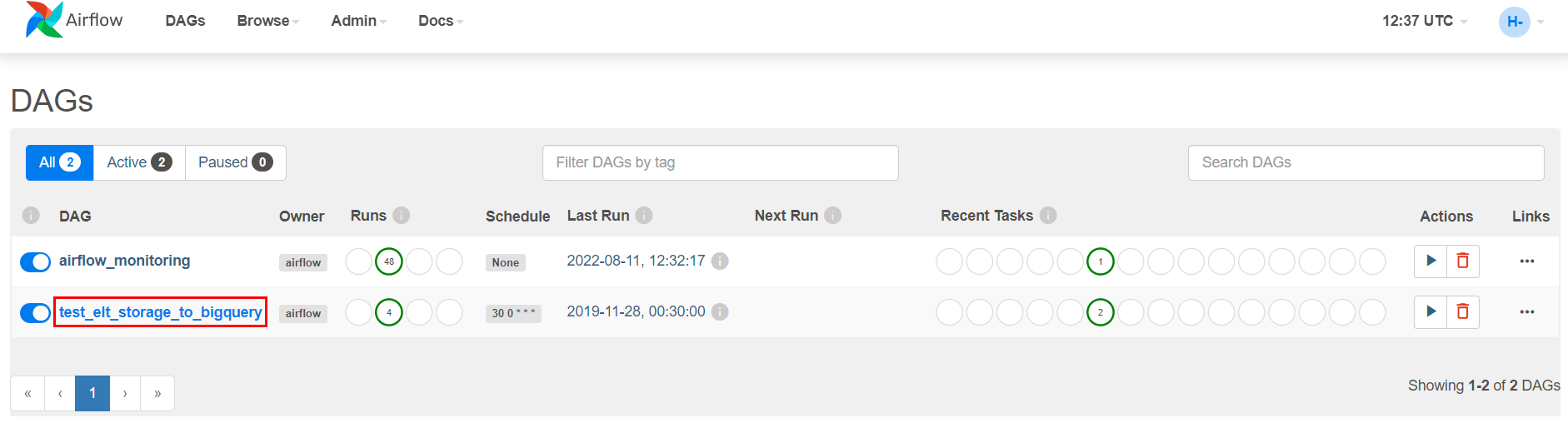
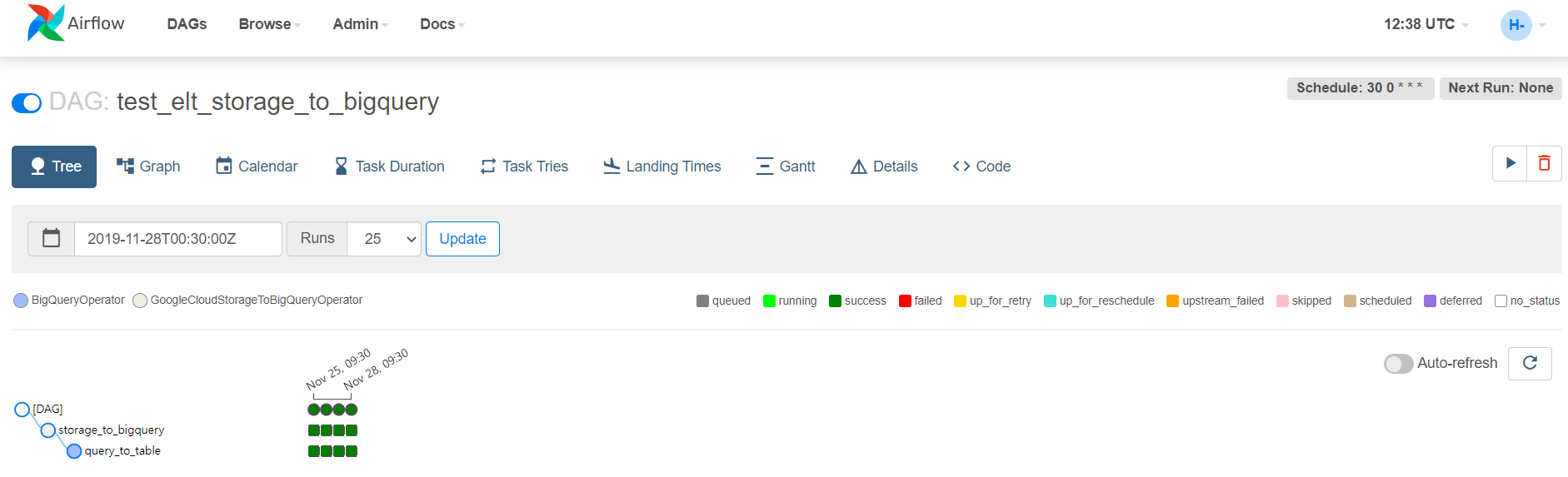
파이프라인이 성공적으로 실행된 것을 Airflow UI에서 확인할 수 있다.
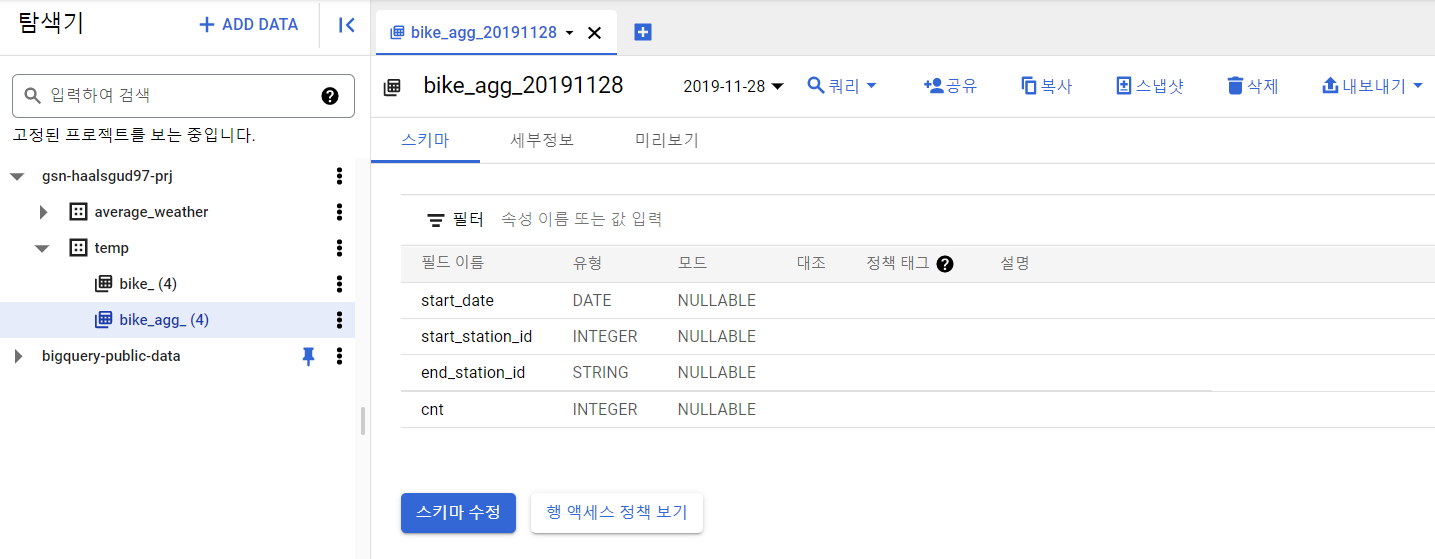
빅쿼리에 적재된 후 Transform된 것도 확인할 수 있다.

AI Solutions Architect