Dataproc Serverless
Dataproc Serverless를 사용하면 자체 클러스터를 프로비저닝하고 관리할 필요 없이 Spark 배치 워크로드를 실행할 수 있게 해준다.
여기선 Dataproc Cluster에 Hive DB를 BigQuery로 마이그레이션 해볼 것이다.
기존에는 이를 위해선 Composer(Airflow)에서 지원하는 Dataproc Operator를 사용하는게 일반적인 방법이었다.
이 방법은 워크로드에 미치는 영향을 고려하여 Composer 환경을 직접 세팅하고 프로비저닝 해준 뒤 DAG 파일을 작성해줘야 하는 작업이 들어간다.
하지만 이제 Dataproc Serverless를 사용하여 원하는 Dataproc Template을 선택 후 옵션만 선택해주면 Spark 배치 job을 돌릴 수 있다.
Hive
하둡 에코시스템에서 데이터를 모델링하고 프로세싱하는 경우 가장 많이 사용하는 데이터 웨어하우징용 솔루션이다.
RDB의 데이터베이스, 테이블과 같은 형태로, HDFS에 저장된 데이터의 구조를 정의하는 방법을 제공하며, 이 데이터를 대상으로 SQL과 유사한 HiveQL 쿼리를 이용하여 데이터를 조회할 수 있다.
가장 큰 특징으로는 메타스토어라는 것이 존재하는데, 하이브는 기존의 RDB와는 다르게 미리 스키마를 정의하고 그 틀에 맞게 데이터를 입력하는 것이 아닌, 데이터를 저장하고 거기에 스키마를 입히는(메타스토어에 입력하는) 것이 가장 큰 특징이다.
Hive 구성요소
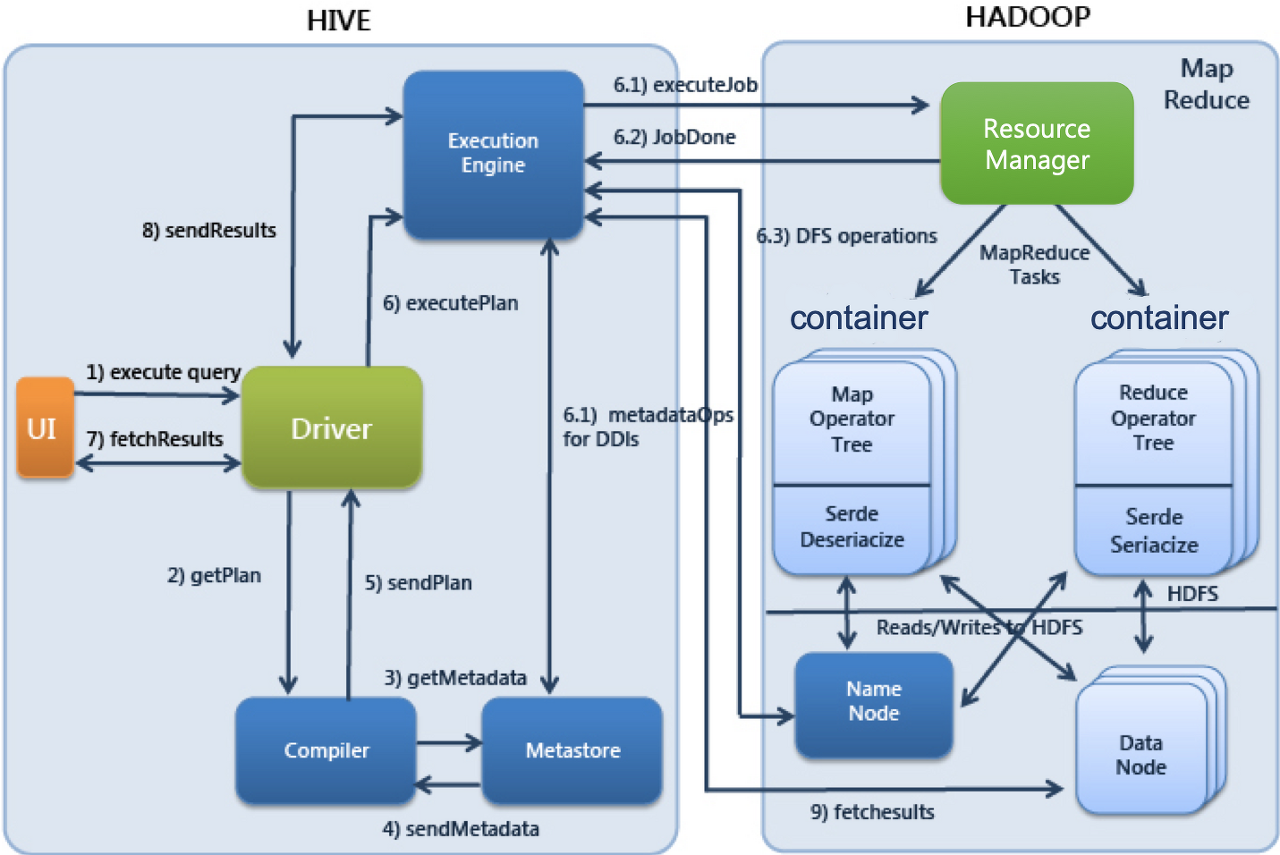
- UI
사용자가 쿼리 및 기타 작업을 시스템에 제출하는 사용자 인터페이스
CLI, Beeline, JDBC 등 - Driver
쿼리를 입력받고 작업을 처리
사용자 세션을 구현하고, JDBC/ODBC 인터페이스 API 제공 - Compiler
메타 스토어를 참고하여 쿼리 구문을 분석하고 실행계획을 생성 - Metastore
디비, 테이블, 파티션의 정보를 저장 - Execution Engine
컴파일러에 의해 생성된 실행 계획을 실행
Hive 실행 순서
- 사용자가 제출한 SQL문을 드라이버가 컴파일러에 요청하여 메타스토어의 정보를 이용해 처리에 적합한 형태로 컴파일
- 컴파일된 SQL을 실행엔진으로 실행
- 리소스 매니저가 클러스터의 자원을 적절히 활용하여 실행
- 실행 중 사용하는 원천데이터는 HDFS등의 저장장치를 이용
- 실행결과를 사용자에게 반환
Hive to BigQuery 마이그레이션
우선 사용할 프로젝트의 Private Google Access를 활성화해야 한다.
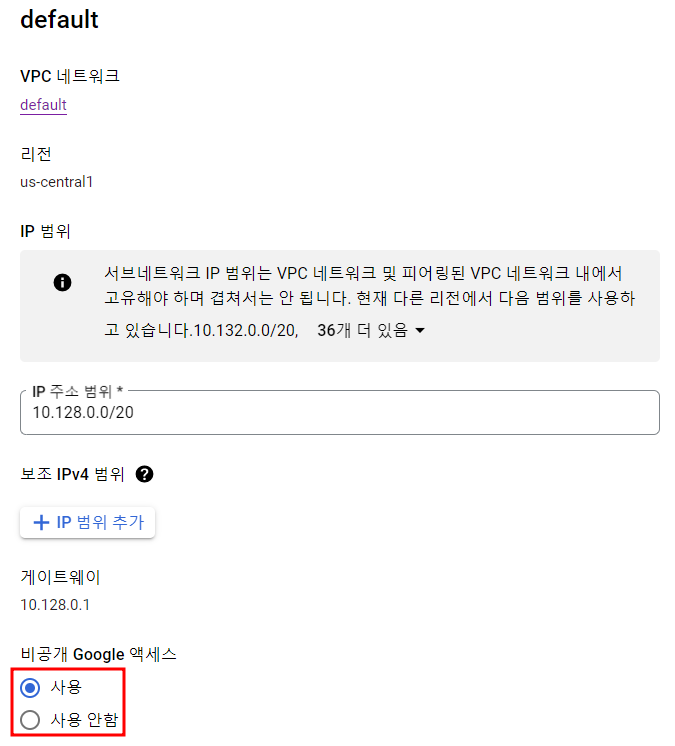
추가로 Serverless Spark job을 위한 버킷도 하나 생성해주자.
Dataproc Cluster 생성
Cloud Shell에서 아래 명령어 수행
gcloud dataproc clusters create <클러스터 이름> \
--region=<리전> \
--single-node \
--enable-component-gateway \
--properties=spark:spark.history.fs.logDirectory=gs://<버킷 이름>/phs/*/spark-job-historyGithub에서 Dataproc Template 클론
git clone https://github.com/GoogleCloudPlatform/dataproc-templates.git
cd dataproc-templates/python소스를 보면 아래와 같고 java, python 중 원하는 언어를 선택할 수 있다. 원하는 언어 폴더/dataproc-templates/로 들어가면 다양한 템플릿과 해당 템플릿 사용 가이드를 확인할 수 있다.
(여기선 python 사용)
(Cloud Shell이 아닌 경우 인증을 위해 아래 명령어를 통해 인증 작업을 수행)
gcloud auth application-default loginHive 테이블 생성
이건 ChatGPT를 활용했다.
Dataproc에 샘플 Hive db, table 생성하고 데이터 넣는 쿼리문을 알려달라고 한 후 그대로 실행했다.
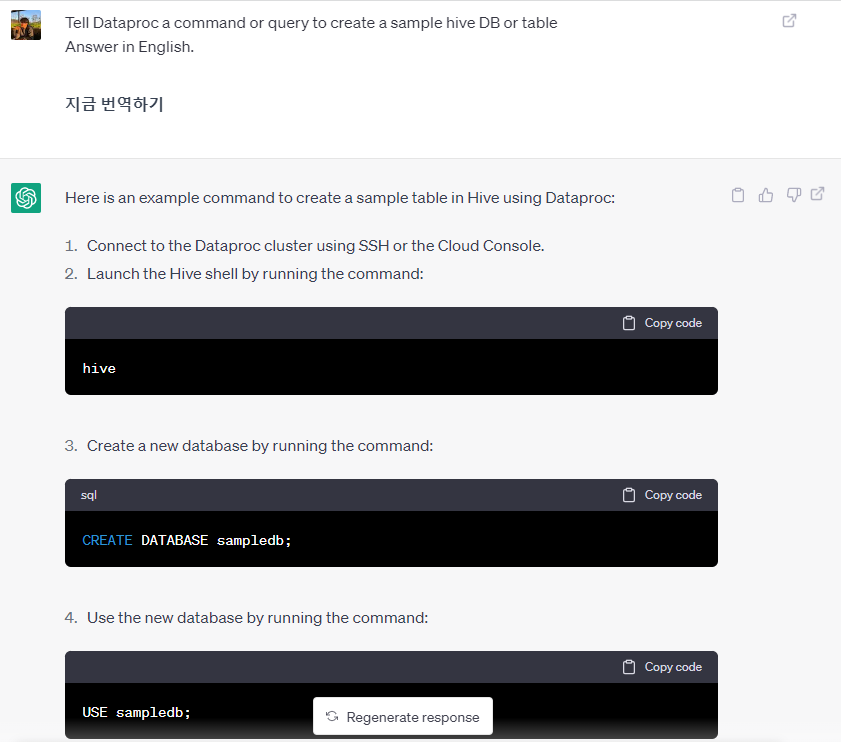
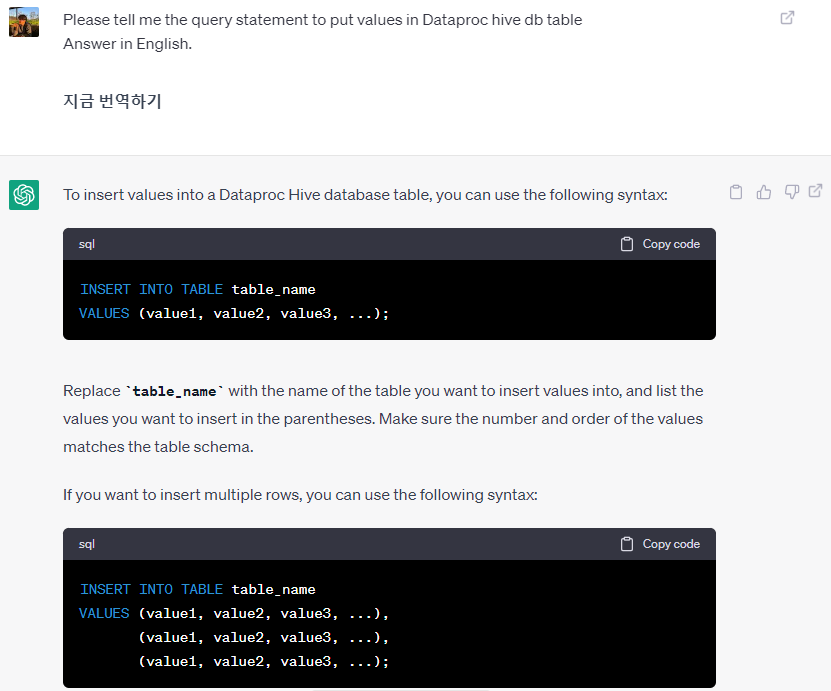
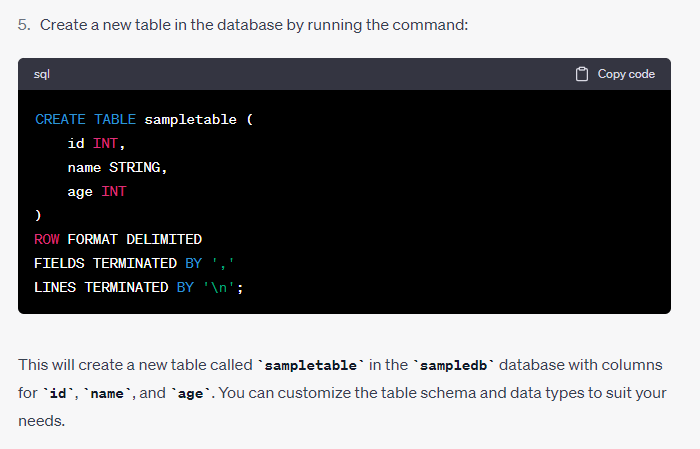
Dataproc 클러스터 인스턴스에 연결
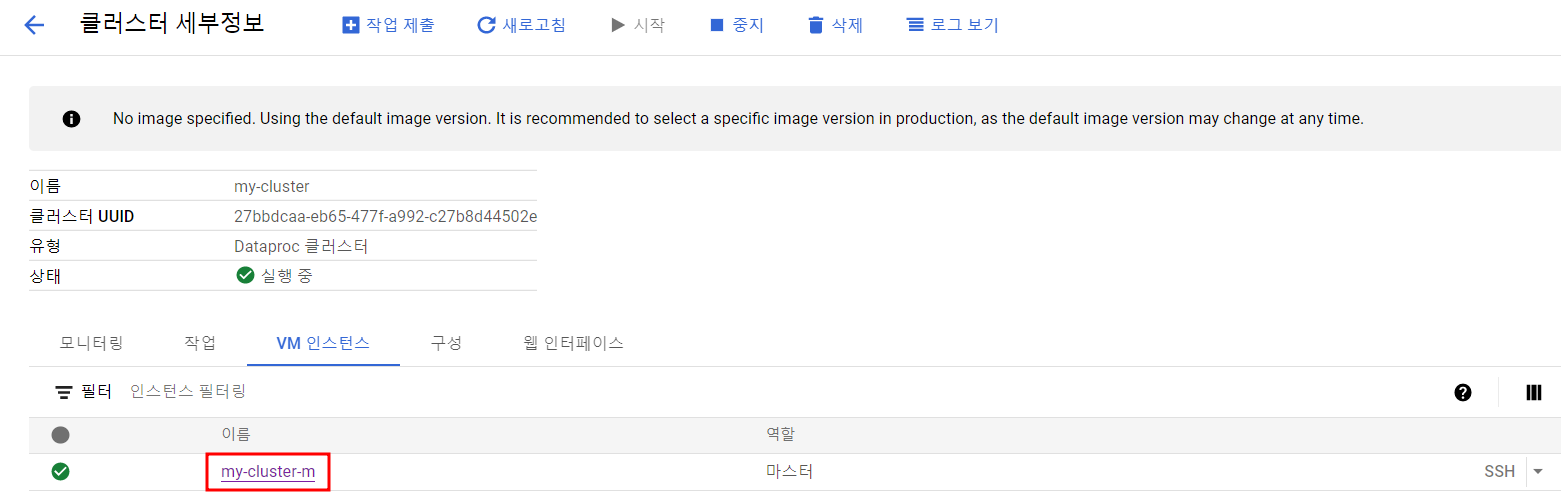
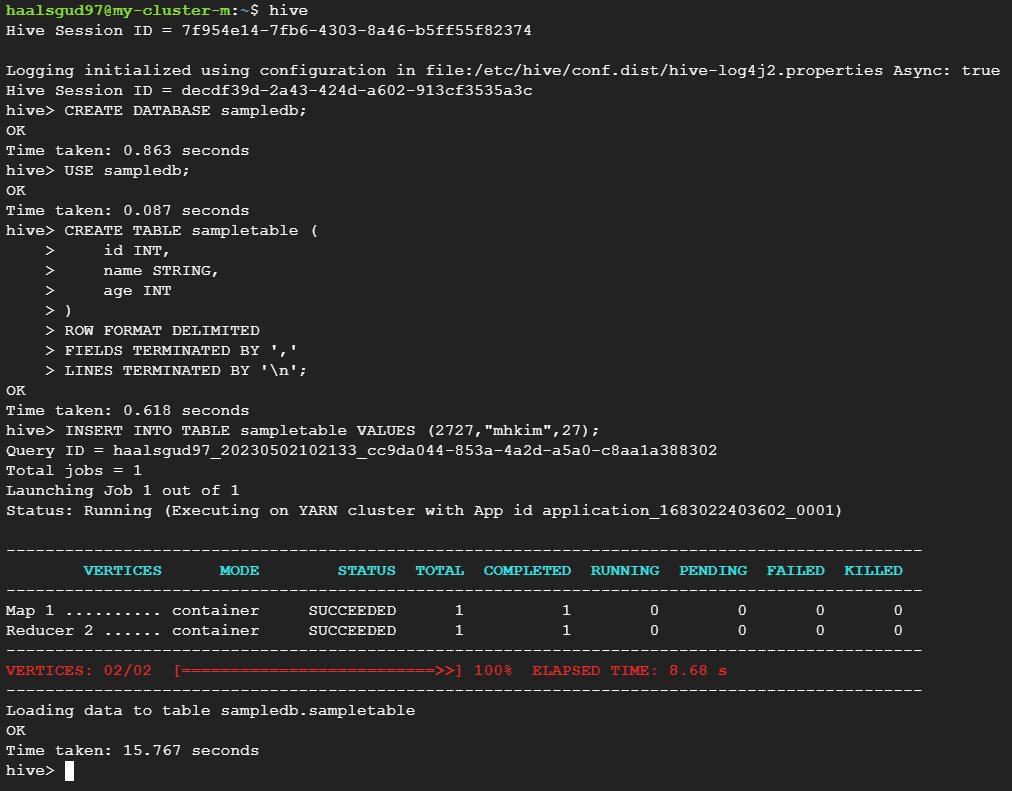
ChatGPT가 알려준대로 쿼리문 실행
예시 쿼리
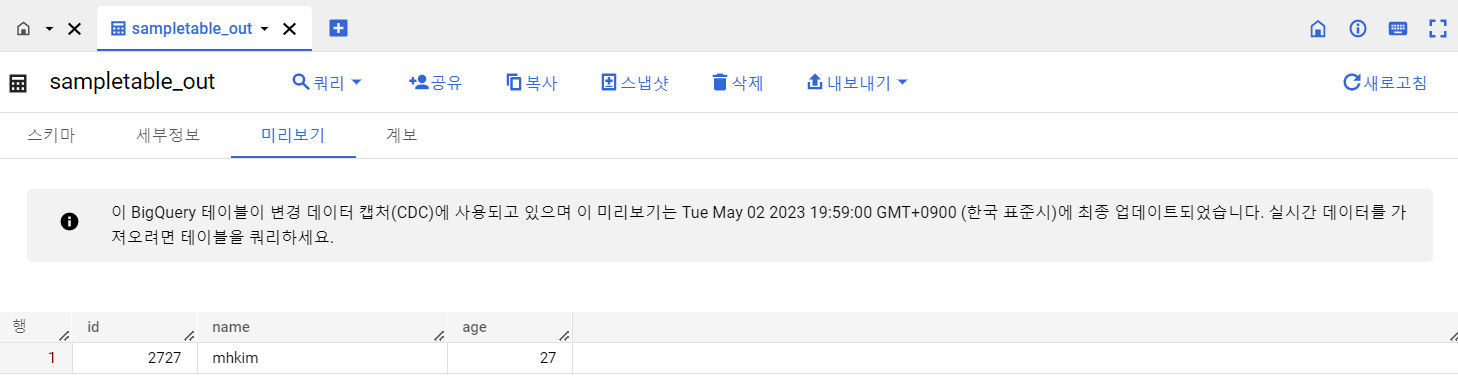
id, name, age에 내 정보를 넣어줬다.
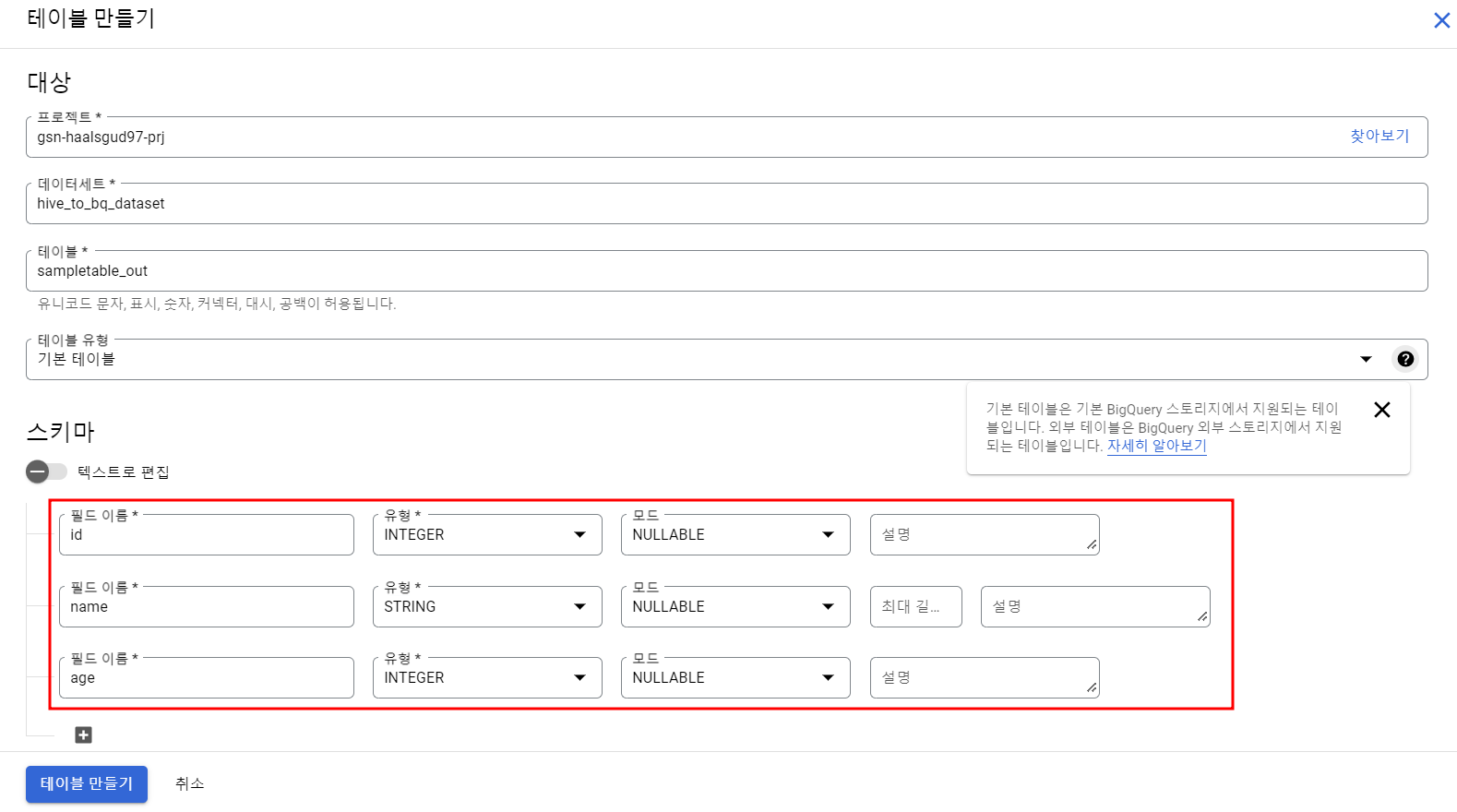
BigQuery 테이블 생성
위에서 만들어준 테이블과 동일한 스키마를 가진 데이터세트 및 테이블을 만들어준다.

Hive To BigQuery 템플릿 실행
Hive To BigQuery에 있는 가이드대로 진행
export GCP_PROJECT=<프로젝트 ID>
export REGION=<리전>
export GCS_STAGING_LOCATION=<Staging 버킷 명>
export JARS="gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar"
./bin/start.sh \
--properties=spark.hadoop.hive.metastore.uris=thrift://<Dataproc 마스터 노드 내부 IP>:9083 \
-- --template=HIVETOBIGQUERY \
--hive.bigquery.input.database="<Hive 디비 이름>" \
--hive.bigquery.input.table="<Hive 테이블 이름>" \
--hive.bigquery.output.dataset="<BigQuery 데이터 세트 이름>" \
--hive.bigquery.output.table="<BigQuery 테이블 이름>" \
--hive.bigquery.output.mode="overwrite" \
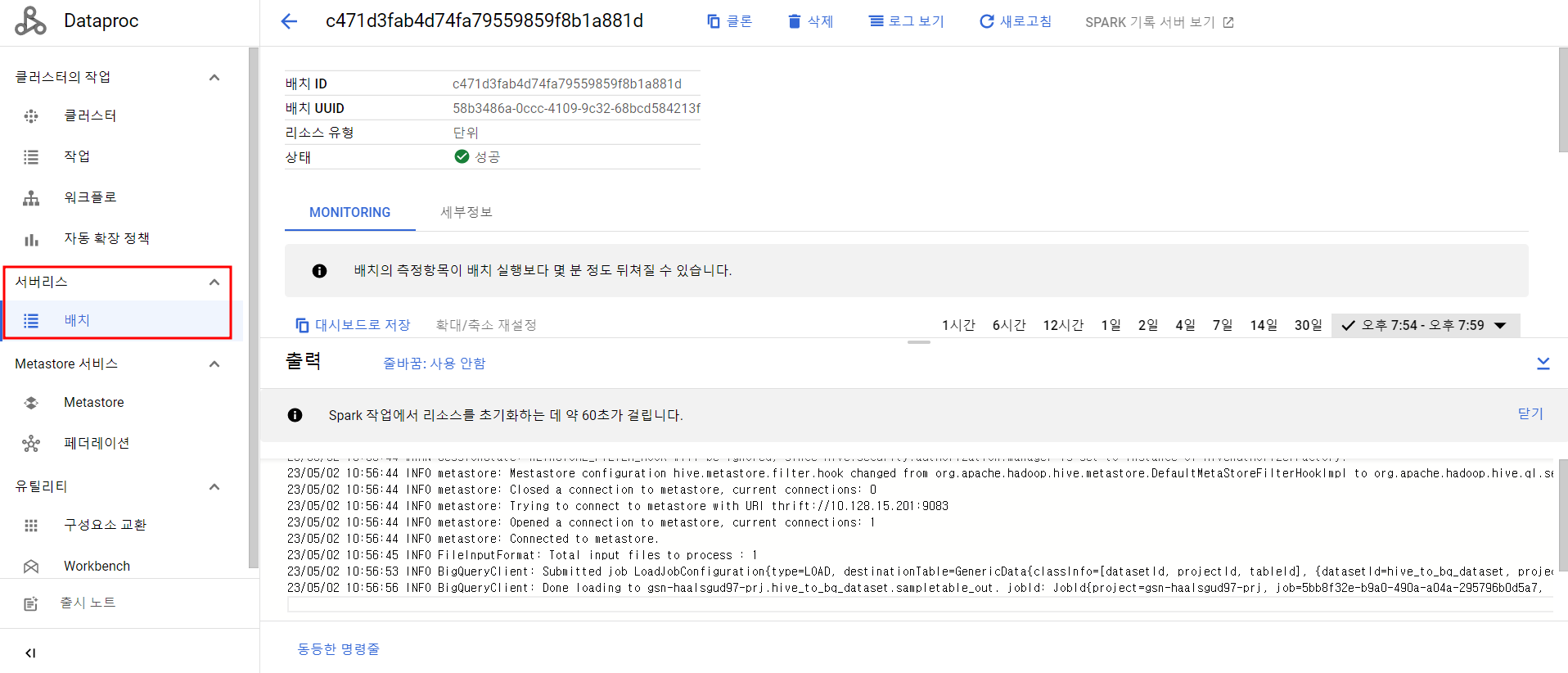
--hive.bigquery.temp.bucket.name="<버킷 이름>"작업 성공
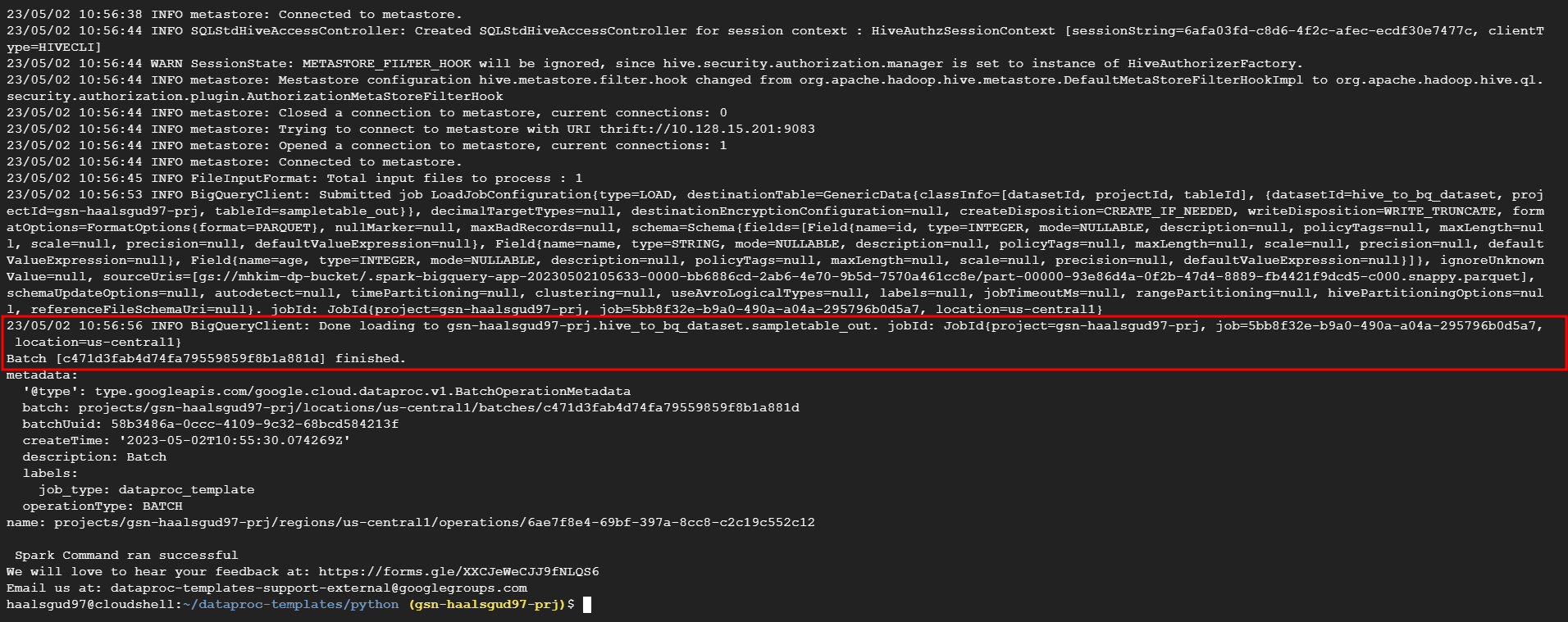
BigQuery에서 확인
아래와 같이 BigQuery에 로드가 성공했다는 메시지가 뜰 것이다.
Dataproc Serverless 배치 job 확인
[Hive 참고]
[Hive 마이그레이션 참고]
