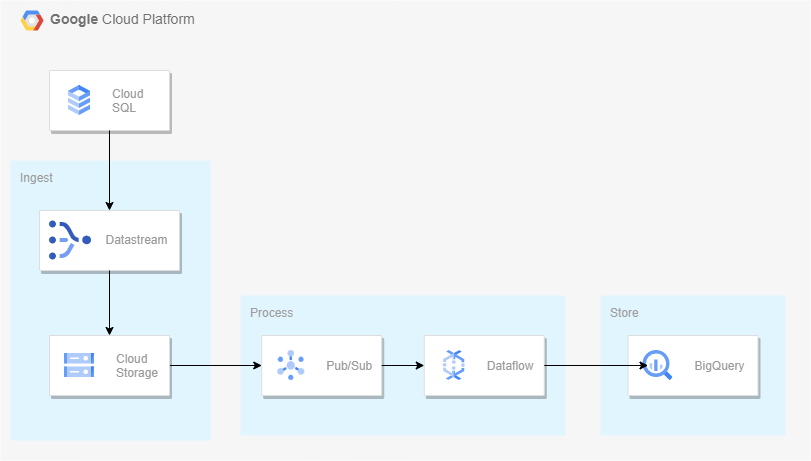
아키텍처
Datastream

Datastream은 사용이 간편한 서버리스 CDC(변경 데이터 캡처) 및 복제 서비스.
지연 시간을 최소화하면서 이기종 데이터베이스와 애플리케이션에서 데이터를 안정적으로 동기화할 수 있다.
Datastream은 Oracle 및 MySQL,PostgreSQL 데이터베이스에서 Cloud Storage로의 스트리밍을 지원하고 Dataflow 템플릿과 통합해 분석을 위한 DW를 구축할 수 있다.
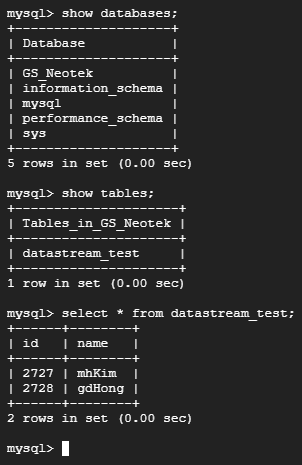
Cloud SQL - MySQL을 하나 만들어주고 아래와 같이 간단하게 DB,테이블을 만들어주자.
Cloud Storage 버킷 하나 생성.
연결 프로필 생성
데이터 소스에 대한 연결 프로필과 타겟이 되는 연결 프로필을 만들어줄 것이다.
데이터 소스 연결 프로필
Cloud SQL을 MySQL로 만들어줬으므로 MySQL 선택
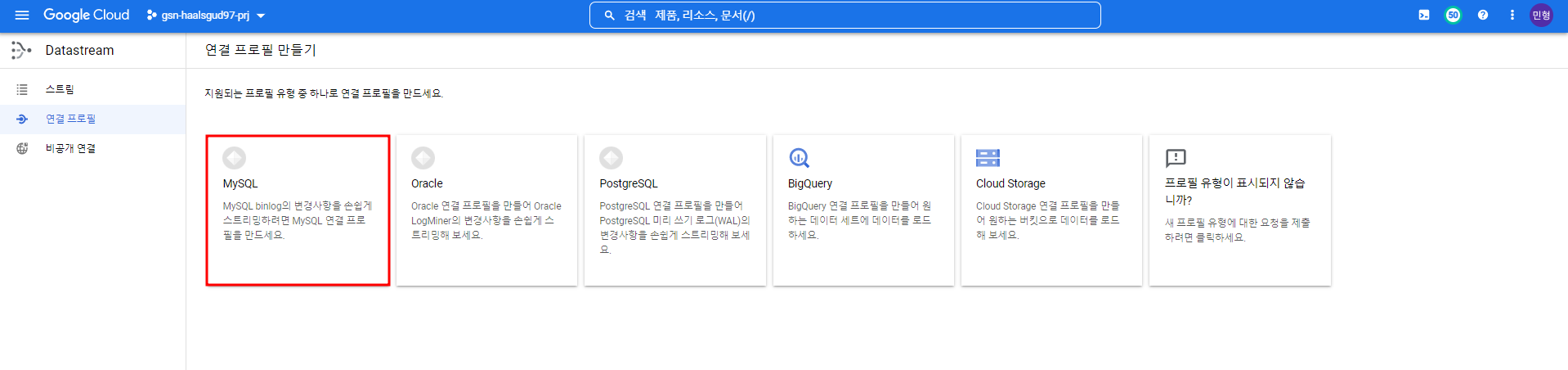
MySQL IP와 user/pw 등 정보 입력
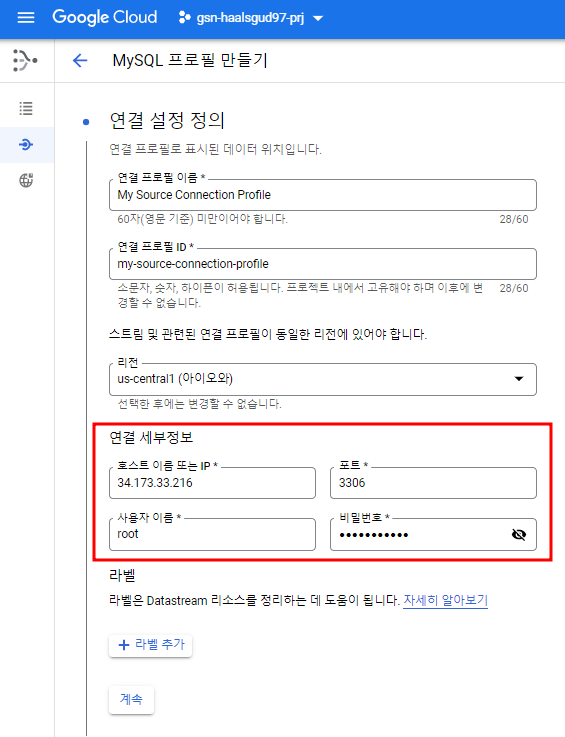
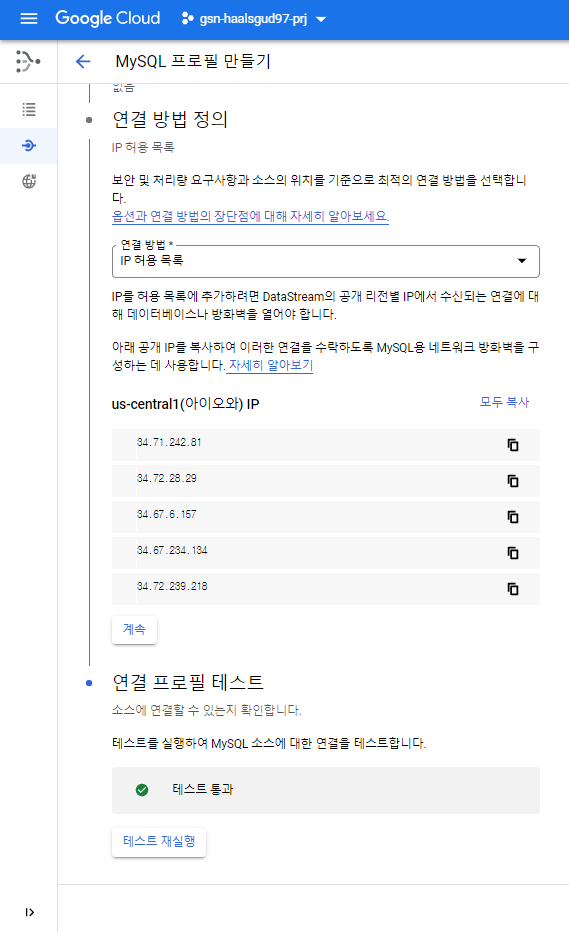
Datastream이 아이오와 리전에서 돌아갈 때 쓰는 IP목록을 보여준다. Cloud SQL에 연결에서 해당 ip들을 접속 허용해줘야 한다.
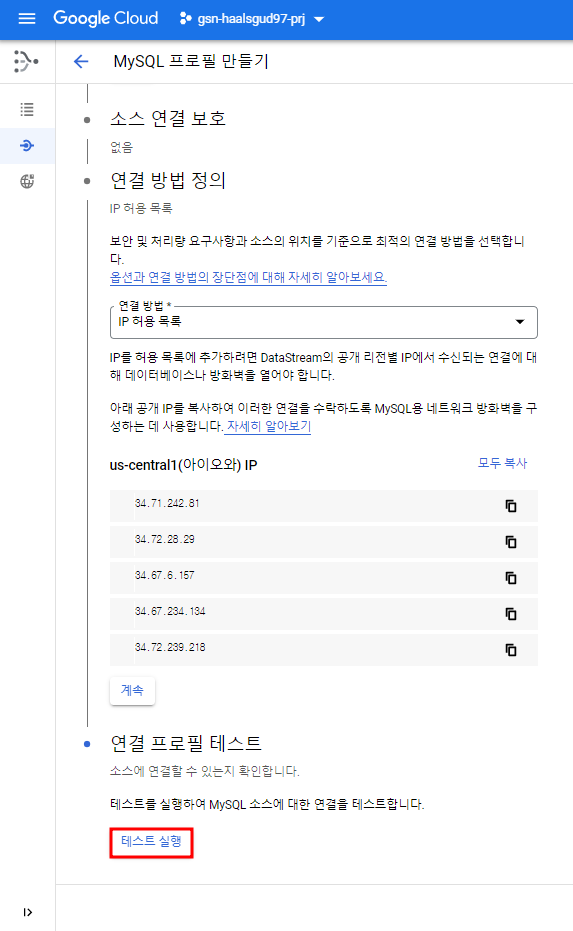
연결 테스트를 해볼 수 있는데 성공하면 아래와 같이 테스트 통과라고 뜬다.
이제 데이터가 쌓이는 타겟에 대한 연결 프로필을 만들어주자.
(바로 BigQuery를 선택할 수 있지만 이 옵션은 22.09.27기준 아직 GA되지 않음.)
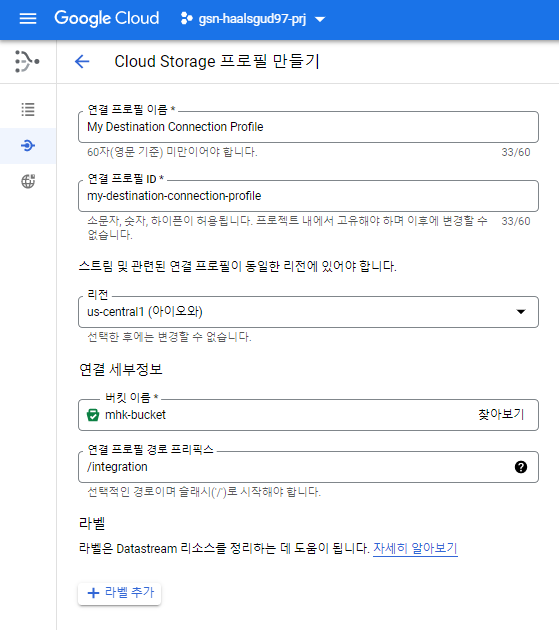
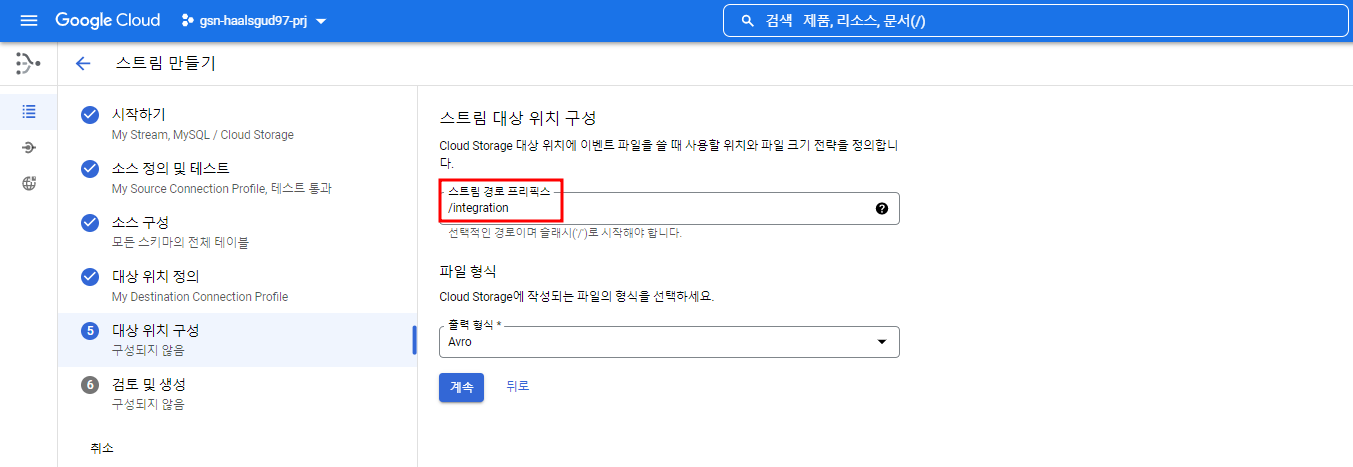
내가 만들어준 버킷에 integration이라는 폴더 안에 MySQL 데이터가 쌓일 것이다.
스트림 만들기
소스와 타겟을 아래와 같이 설정
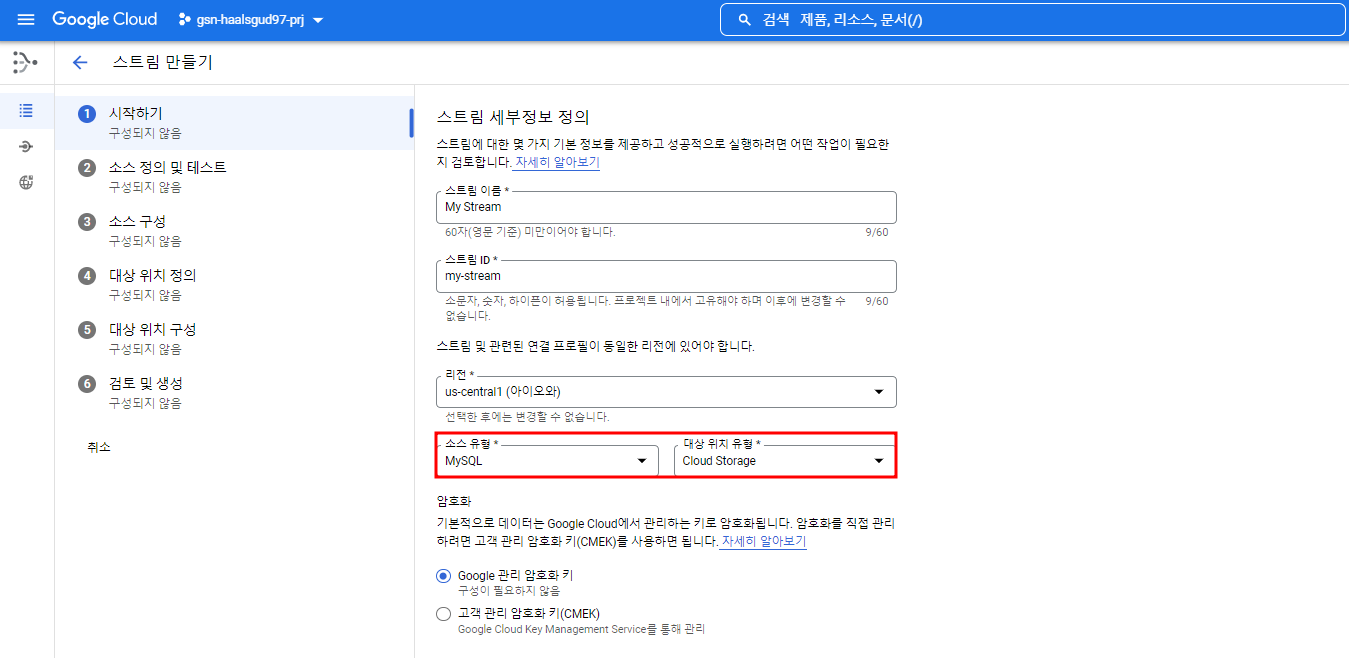
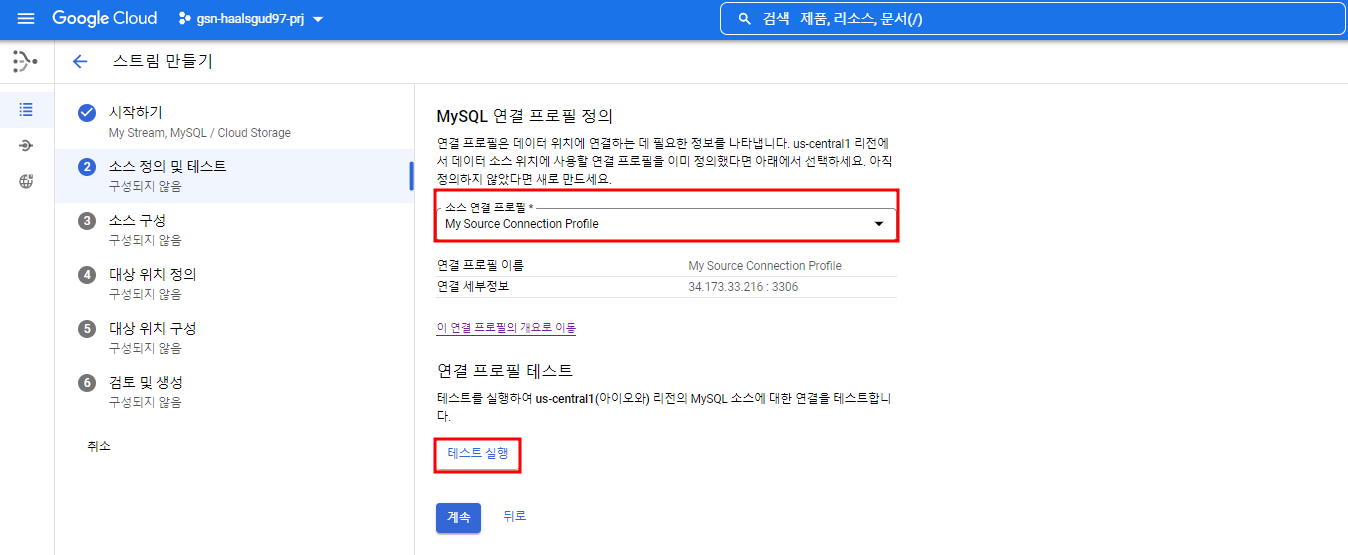
앞서 만들어준 MySQL 연결 프로필을 지정하여 스트림을 만들어줄 것이고 테스트를 해볼 수 있다.
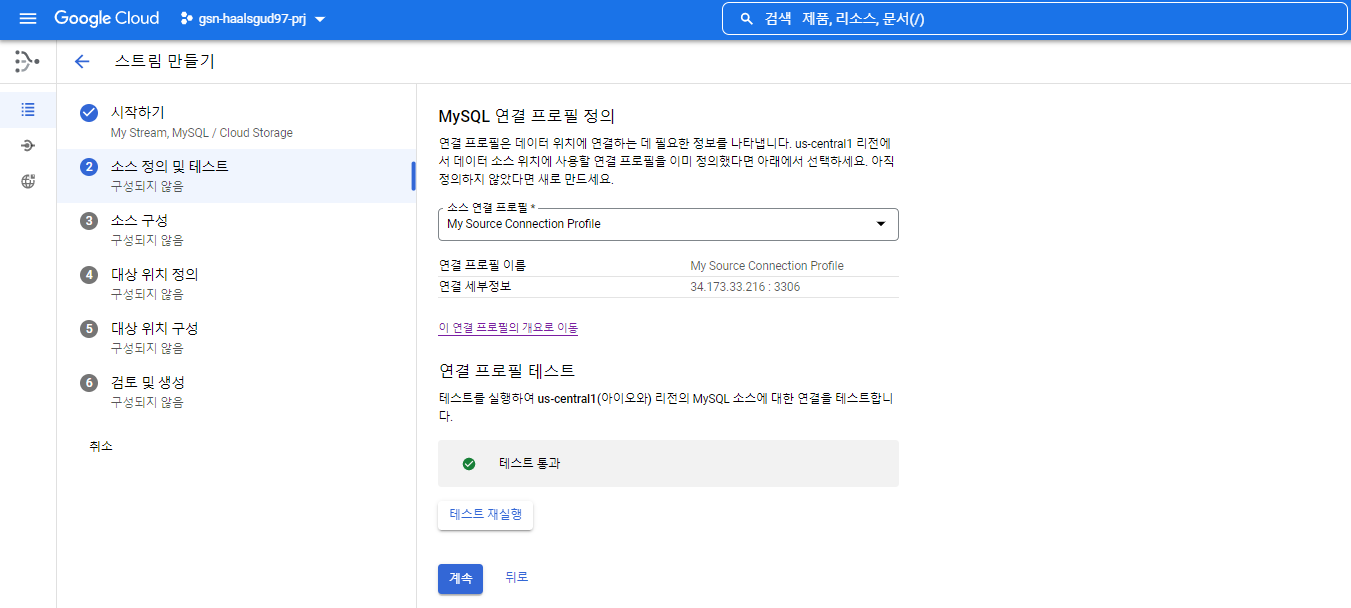
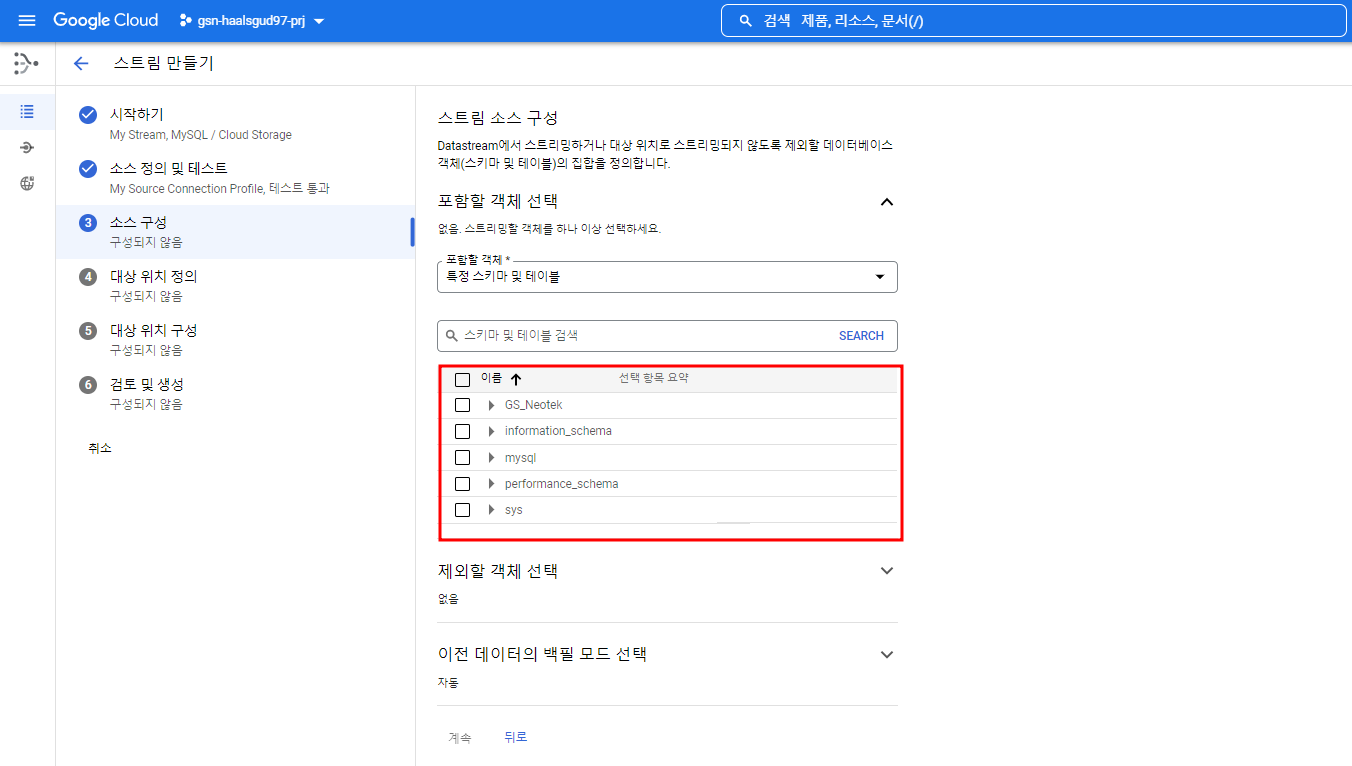
연결에 성공하면 MySQL에 있는 DB, 테이블이 보이게 되고 원하는 테이블에 대한 파이프라인을 구축할 수 있다. 난 GS_Neotek DB만 선택해줄 것이다.
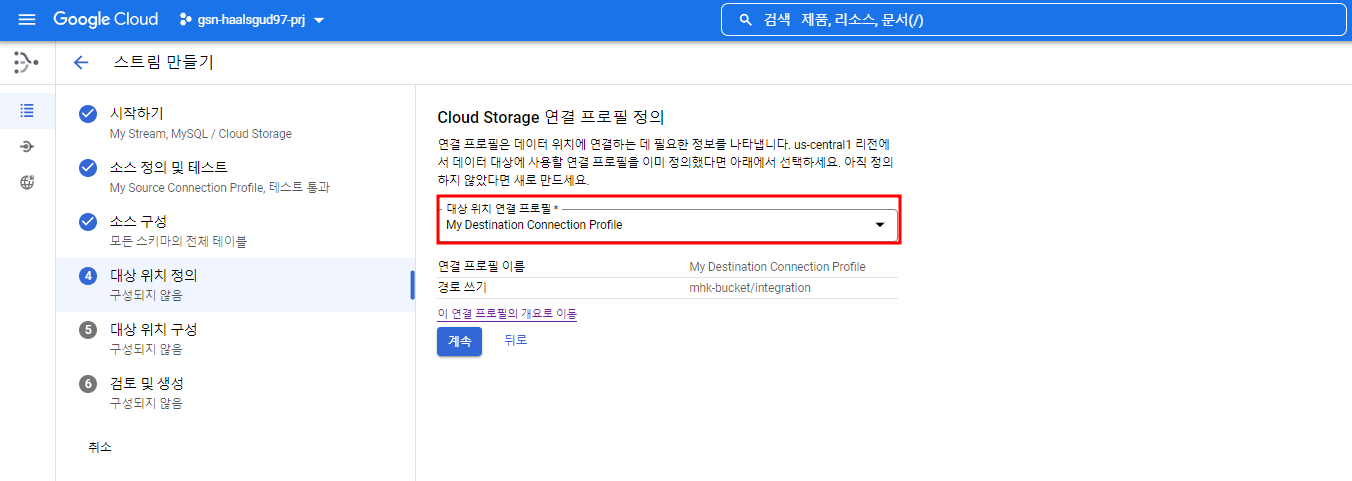
앞서 만들어준 Cloud Storage 연결 프로필을 지정해 타겟 위치를 설정해준다.
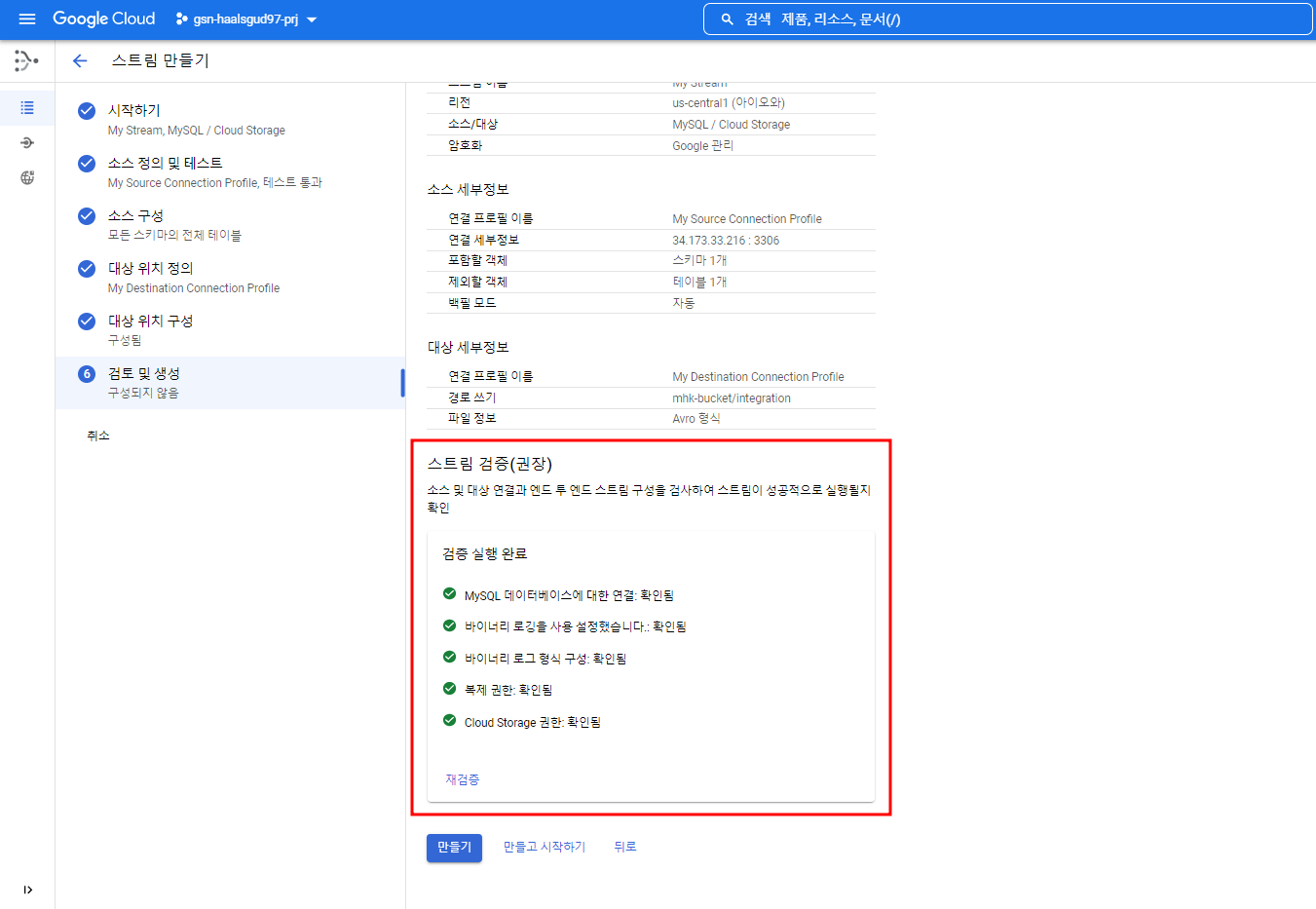
검증을 했을 때 오류가 안났을 때 아래와 같은 화면이 뜰 것이다.
이제 스트림을 생성하면 된다.
Dataflow 작업 만들기
기본 구독이 있는 Pub/Sub 주제를 하나 만들어준다.
스트림을 생성했으면 Dataflow 템플릿을 통해 Cloud Storage에 쌓인 데이터들을 Pub/Sub을 통해 빅쿼리에 실시간으로 적재할 수 있다.
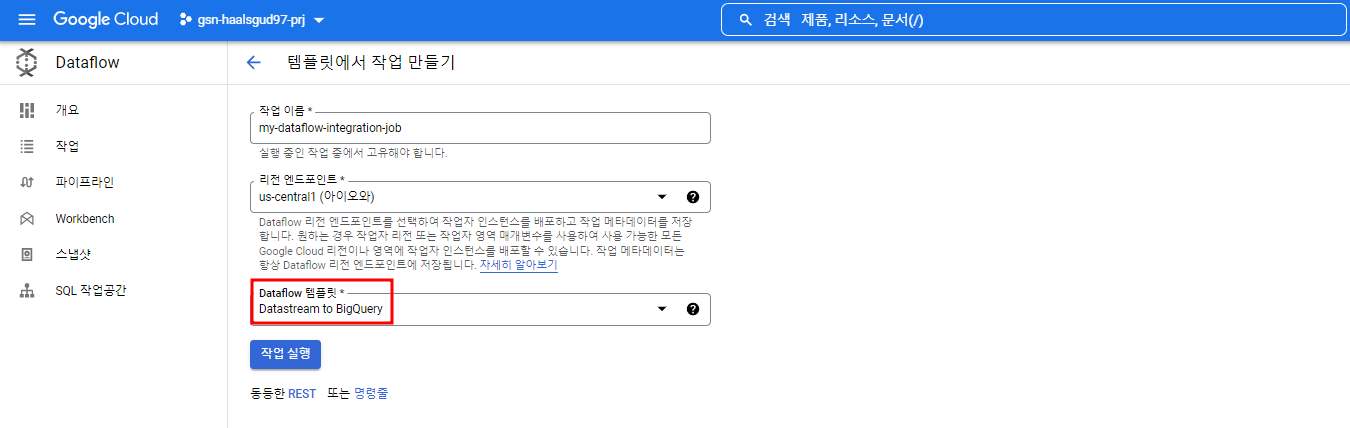
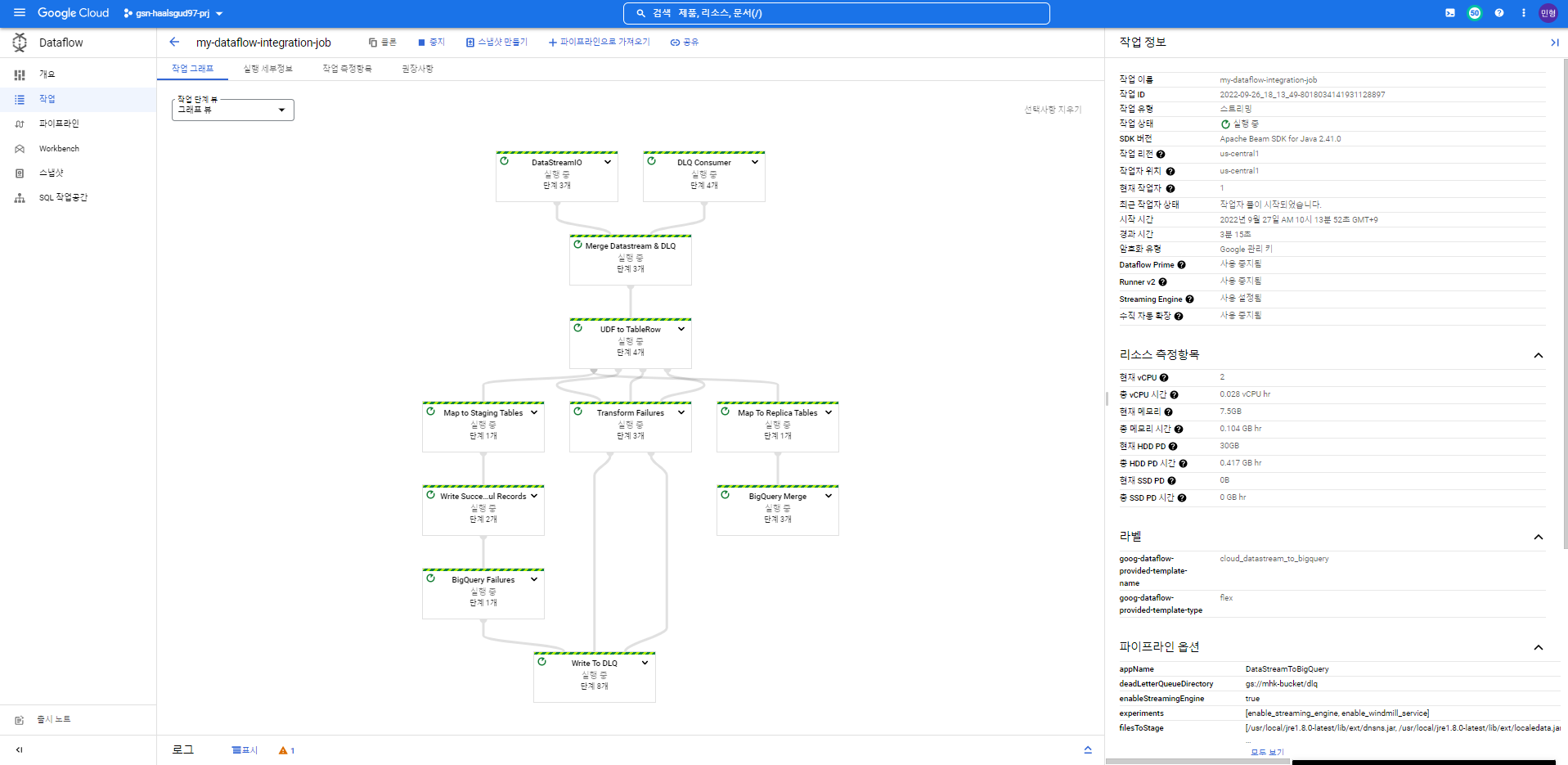
만들어준 Pub/Sub 구독, Datastream, 적재할 빅쿼리 테이블에 대한 정보를 입력하고 실행

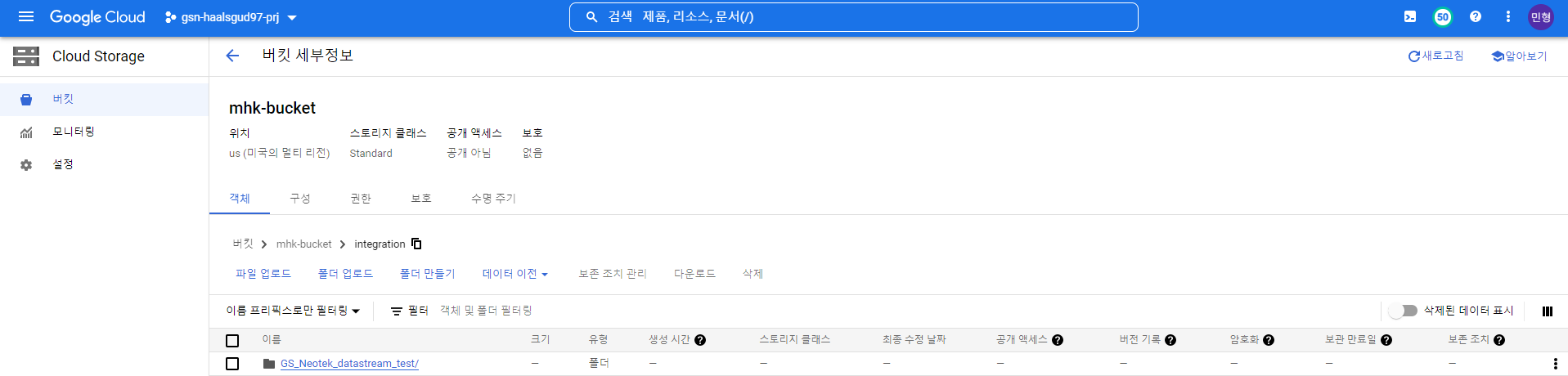
Cloud Storage 버킷에 GS_Neotek DB와 그 안에 만들어준 테이블에 대한 정보가 들어왔다.
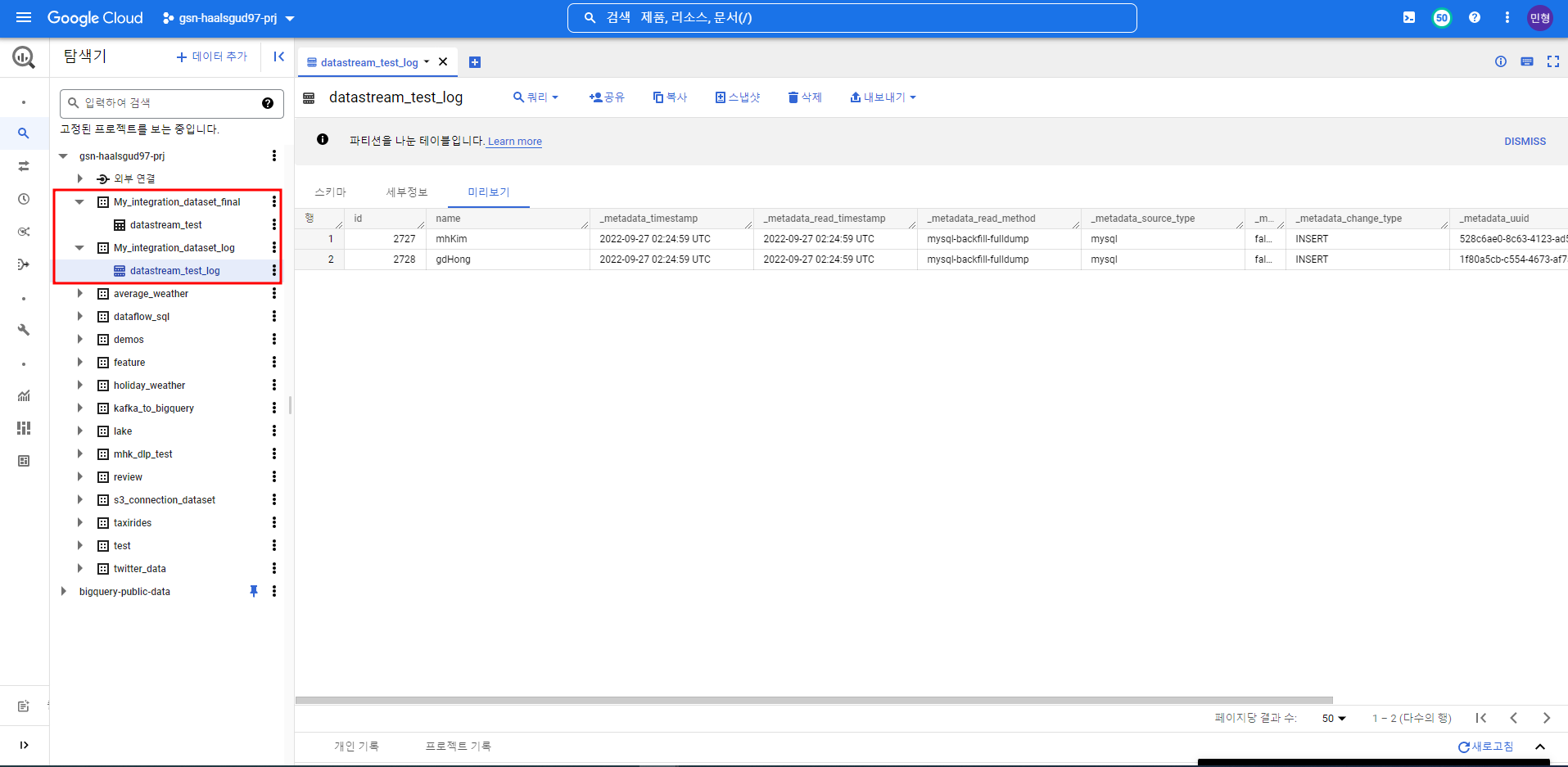
빅쿼리에 MySQL에서 만들어준 테이블이 메타데이터와 함께 적재된 것을 확인할 수 있다.
연결 프로필에서 커넥션할 리소스 선택 시 빅쿼리가 있었다.
사실 Pub/Sub, Dataflow를 거치지 않고 바로 Datastream에서 빅쿼리로 스트리밍 해줄 수 있지만 이 서비스는 2022.09.27 기준 아직 베타이다. GA되지 않았기 때문에 Datastream을 사용하는 파이프라인 아키텍처는 현 시점 이 케이스가 베스트인 것 같다.
+2023년부로 이제 소스 DB에서 BigQuery로 직접 스트림이 가능하다!!
아래와 같이 몇 분마다 한 번씩 쿼리를 날려 데이터를 가져올 것인지 선택할 수 있다.
0초로 갈수록 비용 ↑, 1일로 갈수록 비용 ↓