Fine-Tuning을 하는 이유?
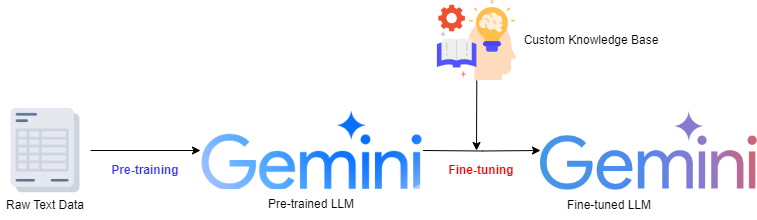
Fine-Tuning을 하는 이유는 사전 학습되어 제공되는 Foundation model이 특정 작업이나 도메인에 더 알맞게 사용하기 위함이다.
LLM의 경우 Prompt Engineering을 통해서 답변의 상당부분을 제어할 수 있지만 높은 수준의 전문성을 요구하는 특정 주제나 산업군에 LLM을 도입할 시 해당 도메인에 보다 특화된, 보다 스마트한 LLM을 구현할 수 있다.
데이터 세트 준비
데이터는 JSONL 형식이어야 한다.
포함되어야 하는 필드값
- message : role-content 쌍의 배열로 구성.
- role : system, user, model로 설정할 수 있고 보통 user 또는 model 역할이 필요하다.
- user : user로 지정한 content는 user의 예시 input이 들어간다.
- model : model의 content는 LLM이 답변할 예시 output이 들어가게 된다.
- system : system은 LLM에 역할을 주거나 하는 System Message와 같은 개념이라고 보면 된다.
- content : 콘텐츠(본문)
- role : system, user, model로 설정할 수 있고 보통 user 또는 model 역할이 필요하다.
예시 형식
{"messages": [{"role": "user", "content": "<User Input 예시>"}, {"role": "model", "content": "<LLM Output 예시>"}]}여기서 사용해볼 데이터는 아래 명령어를 통해 받아볼 수 있는 샘플 기사 데이터이다.
이 샘플 데이터셋은 요약 작업에 특화하여 Gemini를 튜닝시킬 데이터셋이다.
gsutil cp gs://github-repo/generative-ai/gemini/tuning/summarization/wikilingua/sft_train_samples.jsonl .
gsutil cp gs://github-repo/generative-ai/gemini/tuning/summarization/wikilingua/sft_val_samples.jsonl .
요약에 특화된 데이터 세트지만 좀 더 pre-trained LLM 과의 차이를 보여주기 위해 답변 요약시 Gemini Answer Tuned by Minhyoung가 첫 줄에 함께 나오게 할 것이다.
train과 validation 세트 모두에 해당 전처리를 해주자.
pre-processing.py
import json
def add_prefix_to_summary(jsonl_file, output_file):
prefix = "**Gemini Answer Tuned by Minhyoung**"
with open(jsonl_file, 'r', encoding='utf-8') as infile, open(output_file, 'w', encoding='utf-8') as outfile:
for line in infile:
data = json.loads(line.strip())
for message in data.get('messages', []):
if message['role'] == 'model':
message['content'] = f"{prefix} {message['content']}"
outfile.write(json.dumps(data, ensure_ascii=False) + '\n')
# 사용 예시
input_jsonl_file = '<기존 JSONL 파일 경로>'
output_jsonl_file = '<전처리된 JSONL 파일을 저장할 경로>'
add_prefix_to_summary(input_jsonl_file, output_jsonl_file)role이 model인 부분 content에 모두 아래처럼 text가 수정되었을 것이다!!

Fine-Tuning
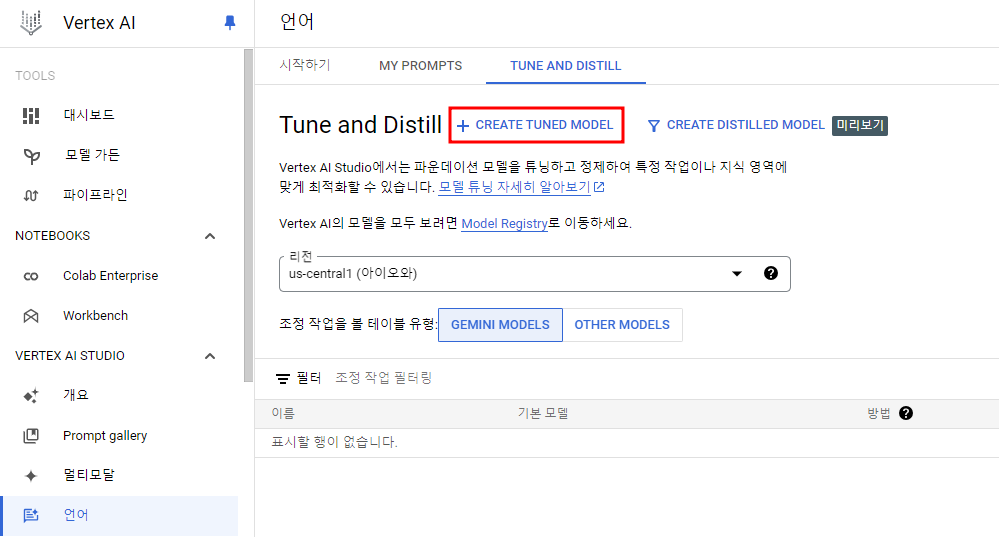
그 다음은 GCP 콘솔에서 작업할 수 있으므로 매우 간단하다!
Vertex AI > 언어 > Tune and Distill로 들어가서 CREATE TUNED MODEL을 클릭해준다.
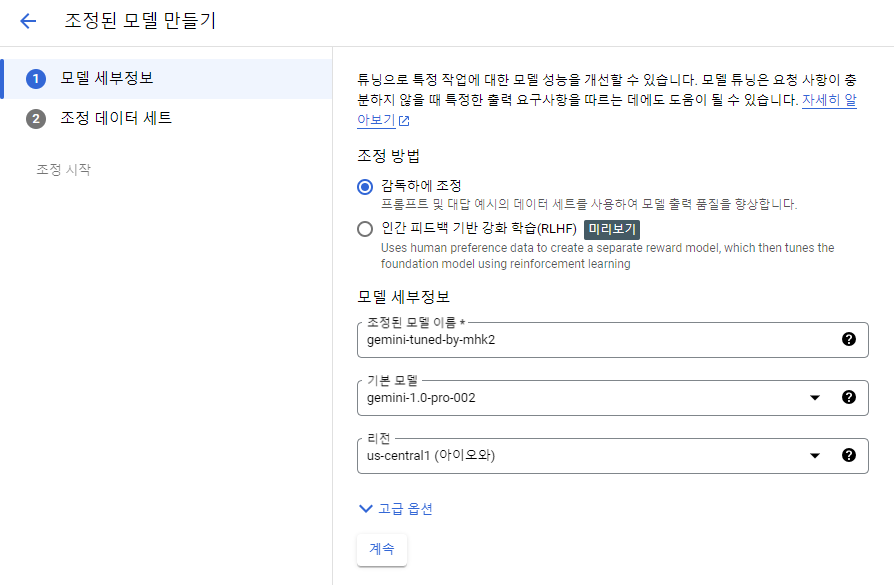
Fine-Tuning할 모델 이름을 지정해주자.
튜닝할 pre-trained 모델은 2024.07 기준 아직 Gemini 1.5는 지원되지 않는다.
또한 고급 옵션에서 에포크나 어댑터 크기 등을 지정할 수 있지만 권장되는 default size로 둘 것이다.
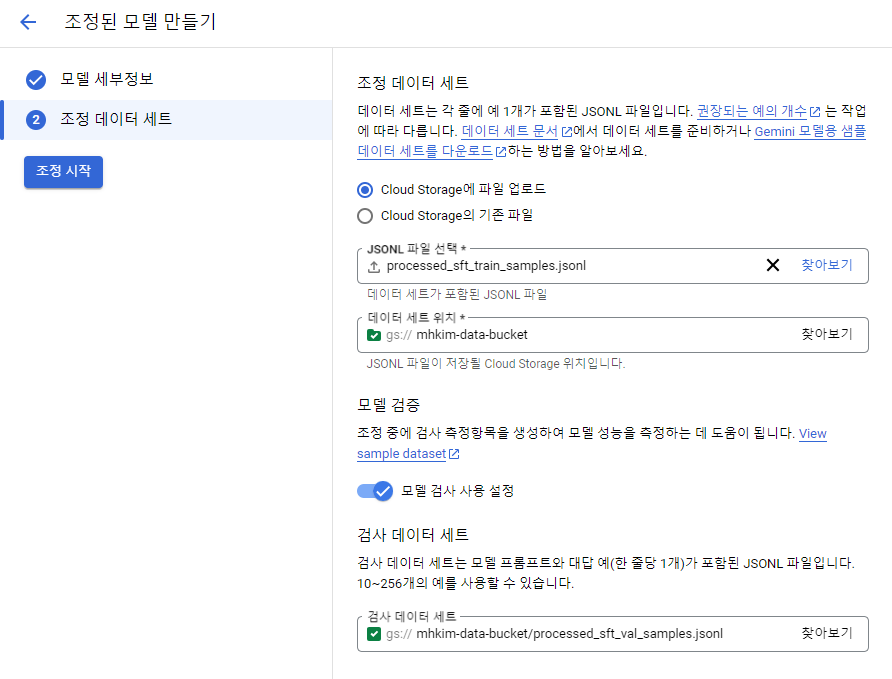
앞서 전처리해줬던 JSONL 파일 업로드
작업별 추천 구성
| 작업 | 데이터 세트에 있는 예의 수 | 에포크 |
|---|---|---|
| 분류 | 500+ | 2-4 |
| 요약 | 1000+ | 2-4 |
| 추출QA | 500+ | 2-4 |
| 채팅 | 1000+ | 2-4 |
에포크는 각 예제에서 훈련하는 횟수라고 생각하면 된다.
콘솔에서 튜닝을 만들 때 기본값으로 4로 설정되어 있을텐데 에포크의 경우 너무 적으면 모델이 데이터로부터 충분한 학습을 하지 못한 과소적합이 발생할 수 있고 너무 많으면 훈련 데이터가 아닌 노이즈 및 이상치를 포함하여 새로운 데이터에서의 성능이 오히려 떨어지는 과적합이 발생할 수 있다.
튜닝은 데이터 사이즈에 따라 다르겠지만 40분-1시간 정도 걸린다.
완료가 되면 학습시킨 데이터셋 및 세부 정보들을 확인할 수 있고 테스트를 클릭하여 실제 모델을 테스트해볼 수 있다.
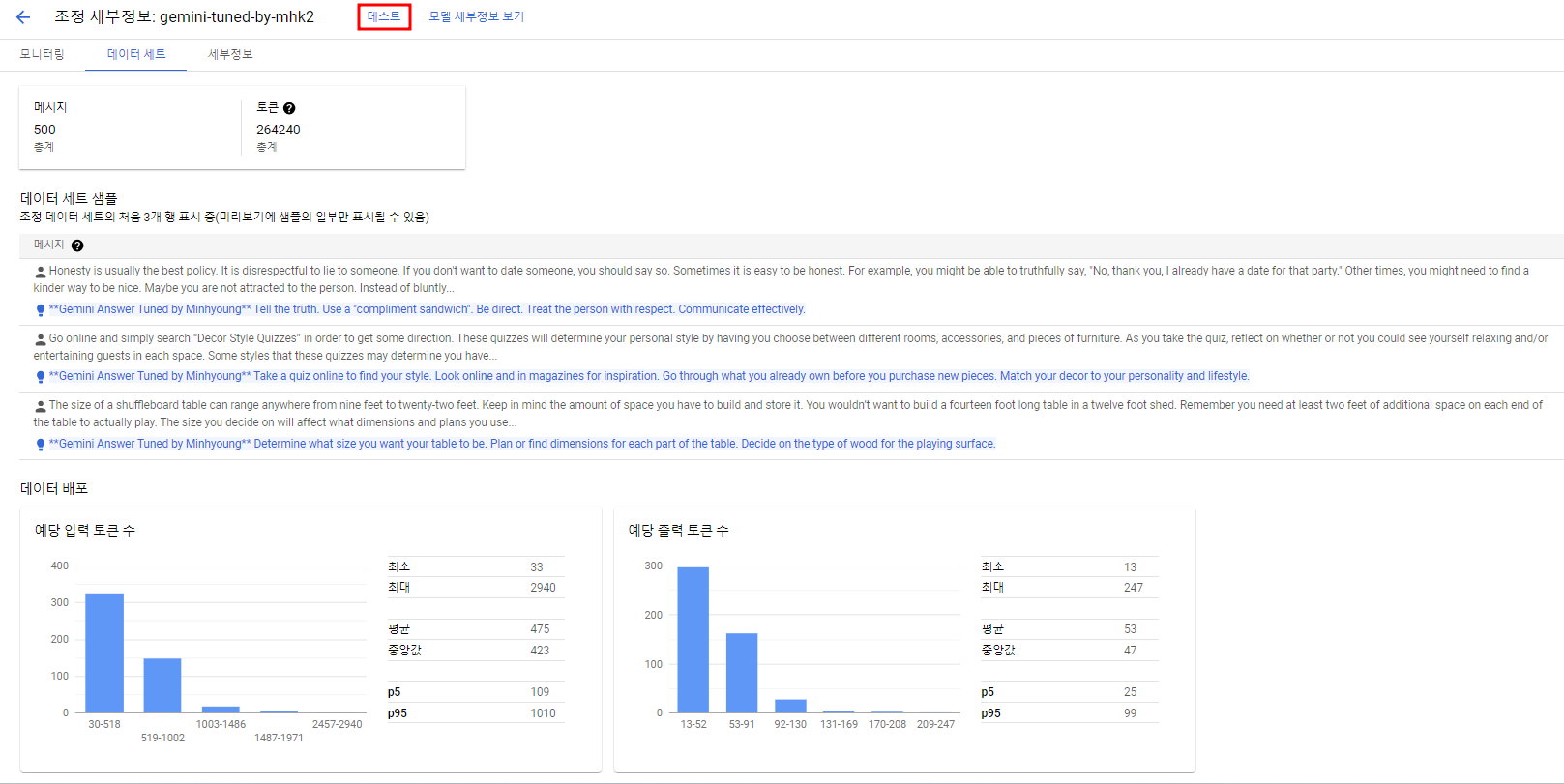
결과 확인
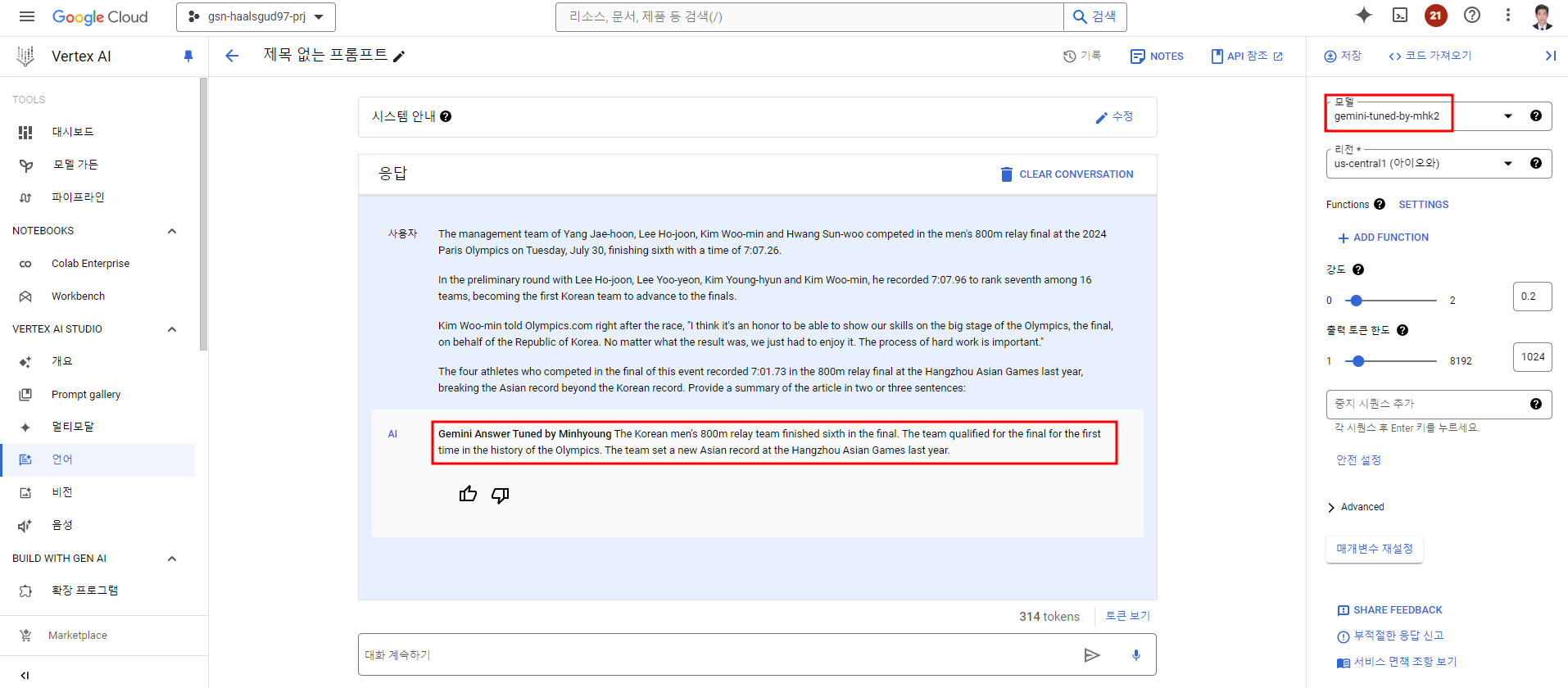
지금이 파리올림픽 시즌이라...ㅎㅎ 파리 올림픽 한국 선수들 관련 기사를 넣고 요약해달라고 해봤다.
Gemini Answer Tuned by Minhyoung가 먼저 나오고 요약본이 나오는 것을 확인할 수 있다!!
(사실상 이정도는 Prompt Engineering으로 충분히 가능하지만 이전 모델과의 차이를 보여주기 위한 것이다.)
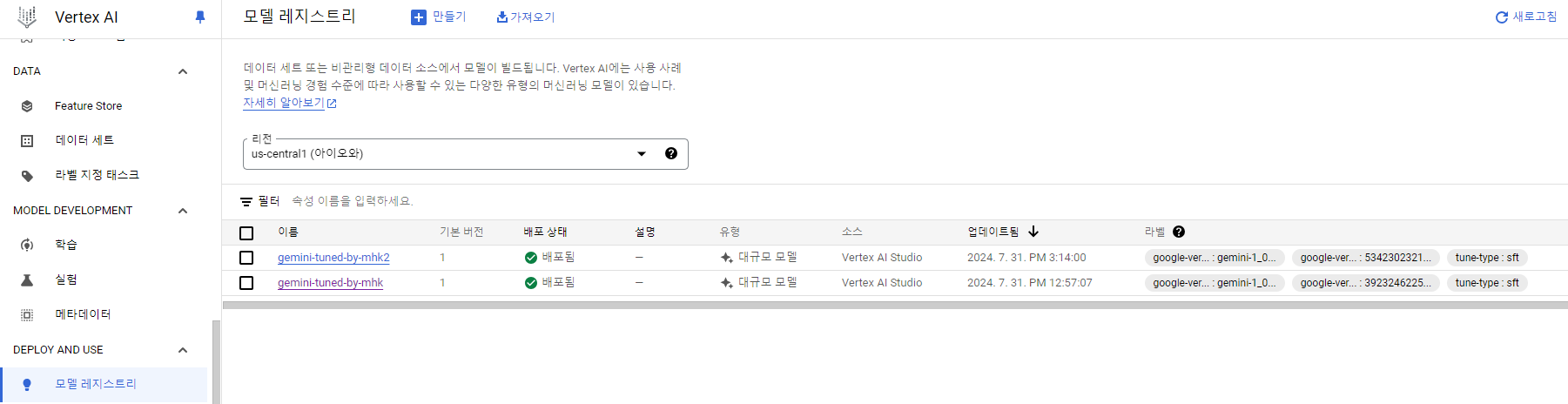
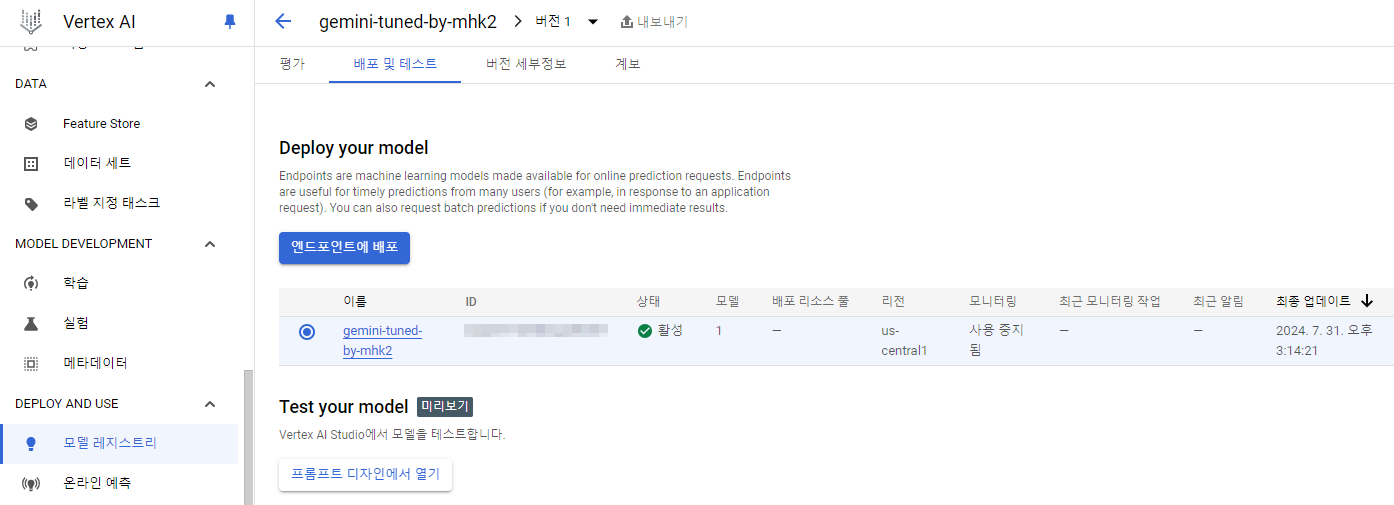
추가로 새로운 모델이 생성되면 자동으로 Vertex AI 모델 레지스트리에 등록이 되어 엔드포인트가 떨어져서 코드로도 바로 사용이 가능하다.
(현재 내보내기는 지원되지 않는다.)
[Gemini Fine-Tuning 참고]
- https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/tuning/supervised_finetuning_using_gemini.ipynb
- https://cloud.google.com/vertex-ai/generative-ai/docs/models/gemini-supervised-tuning-about?hl=ko&_gl=1*1g6pr0i*_ga*NjY5OTcyMDcxLjE2ODM3ODA5MzM.*_ga_WH2QY8WWF5*MTcyMjM4NTYxMS4xMTMxLjEuMTcyMjM4NjMyOS4xNi4wLjA.
- https://cloud.google.com/vertex-ai/generative-ai/docs/models/gemini-use-supervised-tuning#console
