Multi-turn 챗봇
Single-turn은 한 번의 검색 및 답변만 수행하는 것을 의미하고 Multi-turn이란 계속해서 대화를 이어나가는 것을 뜻한다.
Multi-turn 구현의 핵심은 당연하겠지만 이전 대화 내용을 Follow-up 할 수 있어야 한다는 것이다.
즉, 대화 히스토리를 기억할 수 있어야 한다.
LangChain 프레임워크를 사용하면 LangChain에서 제공되는 여러 대화 히스토리를 저장할 수 있는 라이브러리들을 활용해볼 수도 있다.
여기선 Gemini에서 제공되는 history 추가 방법을 알아볼 것이다.
Workflow
기본적인 workflow는 아래와 같다.
1. Gemini에게 질의.
2. 사용자 세션 ID 별 Cloud Storage 폴더 생성.
3. 질문-답변 세트를 해당 폴더에 Upload.
4. 이어서 질문할 시 질문-답변 세트를 불러와 Gemini에 대화 히스토리로 주입.
히스토리 확인
Gemini를 호출하는 코드 중에 model.start_chat()을 활용하여 호출하는 코드를 본 적이 있을 수 있다.
챗봇으로 대화형 텍스트 생성의 문서에서 보면 아래와 같이 사용이 가능하다.
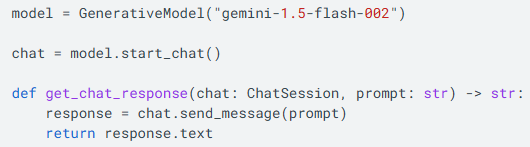
여기서 Gemini는 chat.history 기능을 지원한다..!!
chat.history
chat.history의 경우 로그를 찍어보면 아래와 같이 출력된다.
- 사용자 질문 = 'role': 'user'에 'parts': 'text'
- AI 답변 = 'role': 'model'에 'parts': 'text'

하지만 이를 그냥 출력하게 되면 한글이 깨져 보이는 현상이 발생한다.
string으로 변경 후 json으로 파싱하여 Cloud Storage로 업로드를 한다고 해도 한글이 깨진 상태로 업로드가 되어 히스토리를 입력시켜도 무용지물이었다... 아래 사진처럼^^

chat.history는 Content 유형으로 인코딩 및 디코딩은 필요없고 따로 데이터 내의 객체만 추출하여 json으로 만들어주면 됐었다,,
객체 추출
extracted_history = []
for item in chat.history[-2:]: # 가장 최근의 질문-답변 세트만(마지막 2개 항목만)
role = item.role # role 속성
text_parts = item.parts # parts 객체
# parts 객체 내 text 추출
for part in text_parts:
extracted_text = part.text
extracted_history.append({"role": role, "text": extracted_text})히스토리 업로드 & 다운로드
지금은 Demo용이므로 세션 ID를 고정으로 설정해놓을 것이지만 한 번 한 번 대화가 오갈 때마다 별도의 파일 이름으로 분리를 해서 저장할 것이기 때문에 현재 시간을 파일 이름에 추가했다.
히스토리 업로드
# 히스토리를 Cloud Storage에 저장
def save_history_to_bucket(bucket_name, folder_path, extracted_history):
bucket = storage_client.bucket(bucket_name)
current_time = get_kst_time()
file_name = f"{session_id}_{current_time}.json"
blob = bucket.blob(f"{folder_path}/{file_name}")
history_to_json = json.dumps(extracted_history, ensure_ascii=False, indent=4)
# Cloud Storage에 업로드
blob.upload_from_string(history_to_json, content_type='application/json')히스토리 다운로드
동일 세션에서 계속 질문할 경우 질문 때마다 해당 폴더에 json(질문-답변 세트) 파일들을 불러와서 하나의 json으로 통합하게 된다.
# 모든 히스토리를 불러와 JSON으로 합치기
def load_and_merge_history(bucket_name, folder_path):
bucket = storage_client.bucket(bucket_name)
blobs = bucket.list_blobs(prefix=f"{folder_path}/")
merged_history = [] # JSON 리스트로 통합
for blob in blobs:
if blob.name.endswith(".json"):
content = blob.download_as_string().decode("utf-8") # 문자열로 변환
try:
json_data = json.loads(content) # JSON 파싱
if isinstance(json_data, list): # JSON 데이터가 리스트인지 확인
merged_history.extend(json_data) # 기존 리스트에 추가
else:
print(f"Invalid JSON format in {blob.name}, skipping...")
except json.JSONDecodeError as e:
print(f"Error decoding JSON from {blob.name}: {e}")히스토리 추가
처음엔 사용자 질문이 포함된 프롬프트를 버킷에 저장한 후에 히스토리를 불러오는 과정에서 json 파일들을 모두 텍스트로 변경 후 병합하여 아래 사진에 CONVERSATION_HISTORY 부분에 넣어줬었다. 이렇게 히스토리를 무식하게 추가했었는데... 이러면 금방 모델의 input token limit에 도달하게 된다..
기존의 추가 방법

하지만 알고보니 chat.start_chat()에서 파라미터로 history 옵션을 지원했다. 내가 못찾았을 수 있지만 공식 문서엔 2024.12 기준 제대로 언급되어 있는 부분은 없는 듯...?
바뀐 추가 방법
Gemini Chat(Github)에 보면 아래의 코드를 확인할 수 있을 것이다.
chat2 = model.start_chat(
history=[
Content(
role="user",
parts=[
Part.from_text(
"""
My name is Ned. You are my personal assistant. My favorite movies are Lord of the Rings and Hobbit.
Who do you work for?
"""
)
],
),
Content(role="model", parts=[Part.from_text("I work for Ned.")]),
Content(role="user", parts=[Part.from_text("What do I like?")]),
Content(role="model", parts=[Part.from_text("Ned likes watching movies.")]),
]
)이 코드를 활용하여 통합된 json 파일에서 'role' 및 'text' 값들을 읽어들여 하나의 list로 만들고 이를 history에 넣어주는 방식으로 구현하였다.
이 방법을 사용하면 대화 히스토리를 추가해주더라도 input token은 오직 그때 사용한 프롬프트만 계산된다.
애플리케이션 구현
streamlit을 활용하여 간단하게 구현해보았다.
Chatbot엔 Gemini와 대화를 하는 부분이고 Chat History 부분엔 대화 이력이 남는다.
Chat History의 경우 질문, 답변 메시지의 상태를 저장하는 streamlit의 session_state 기능을 사용하여 구현했다.
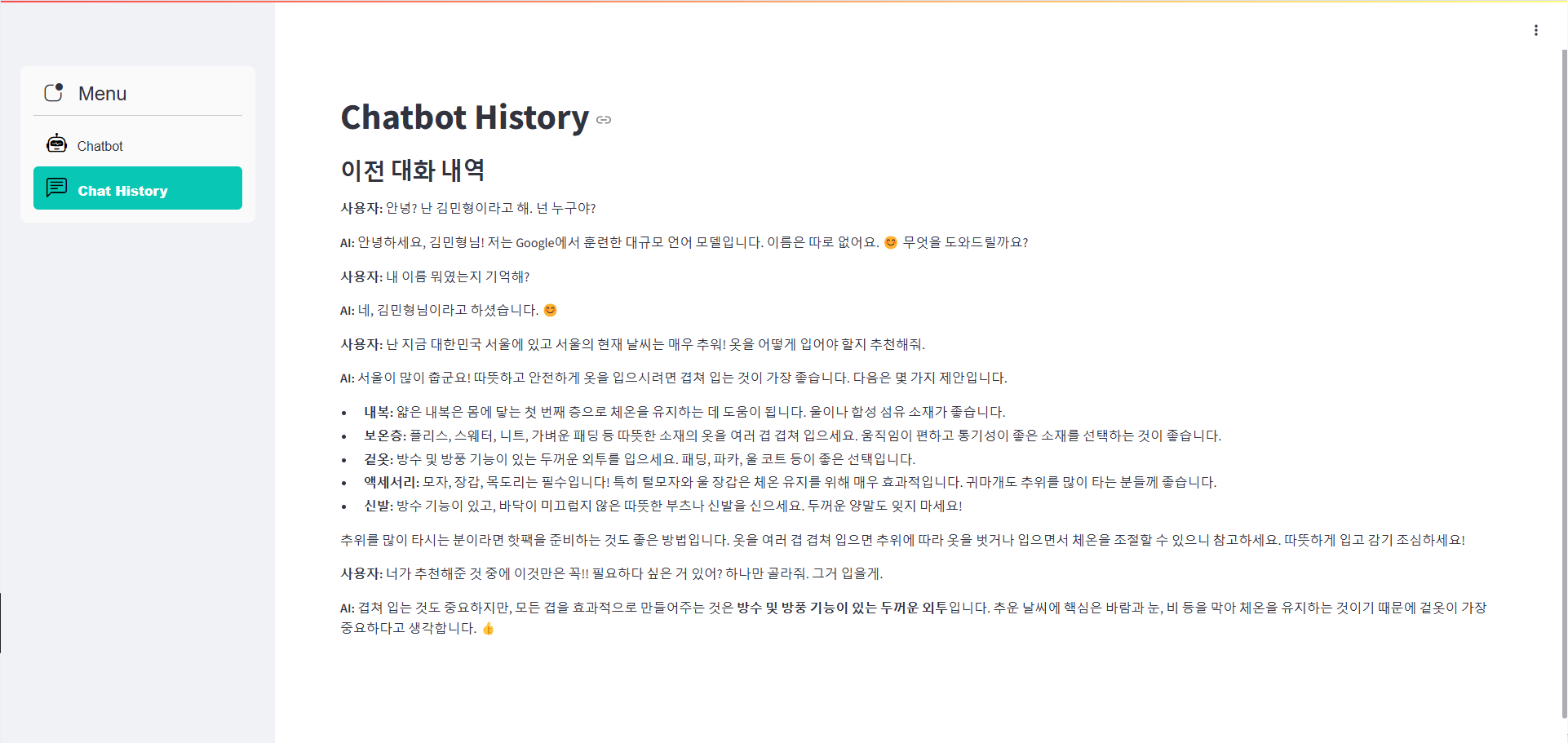
Q : 안녕? 난 김민형이라고 해. 넌 누구야?
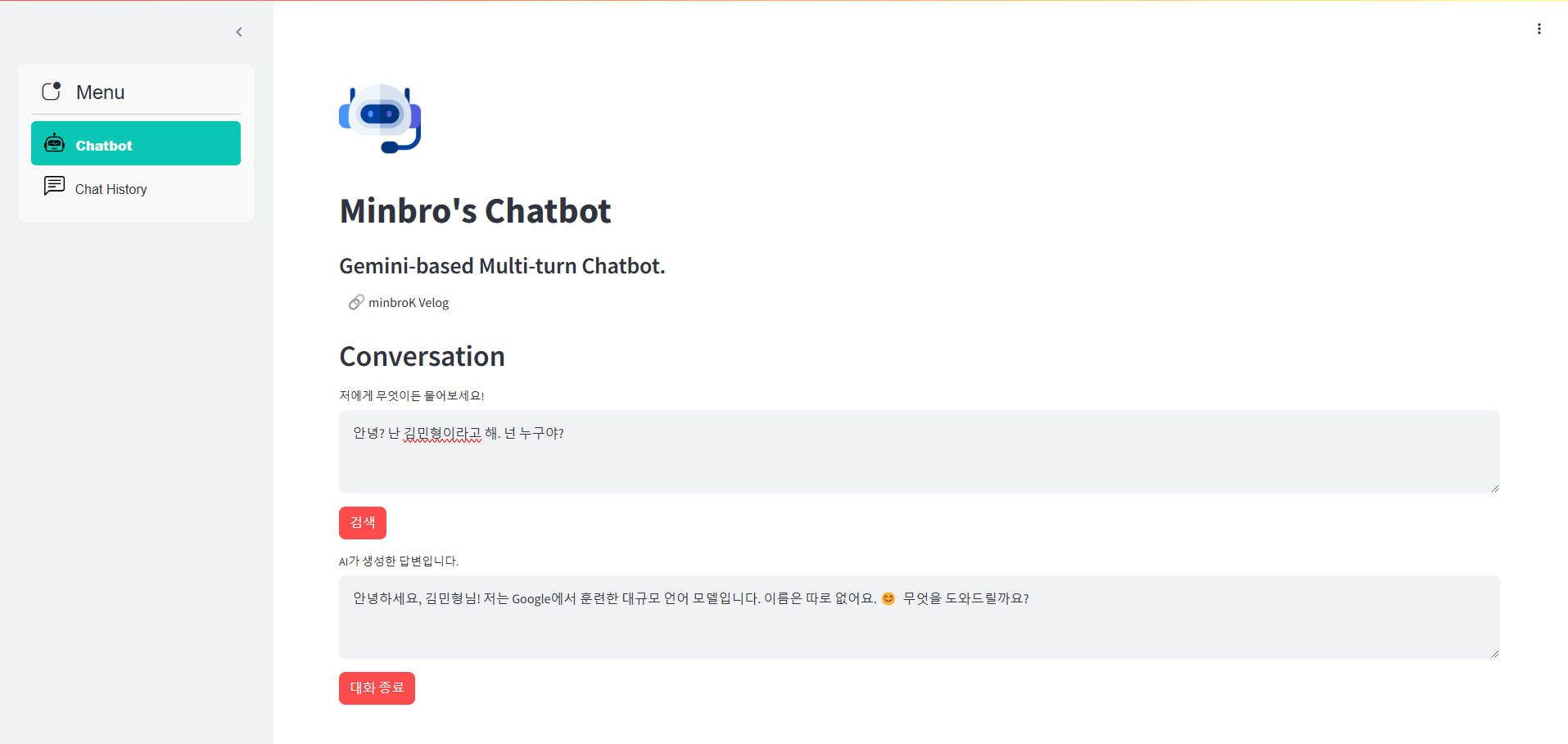
로그 확인
해당 세션에 이전 대화 기록이 없으므로 빈 리스트이고 Cloud Storage에 첫번째 히스토리가 저장된 것을 확인할 수 있다.
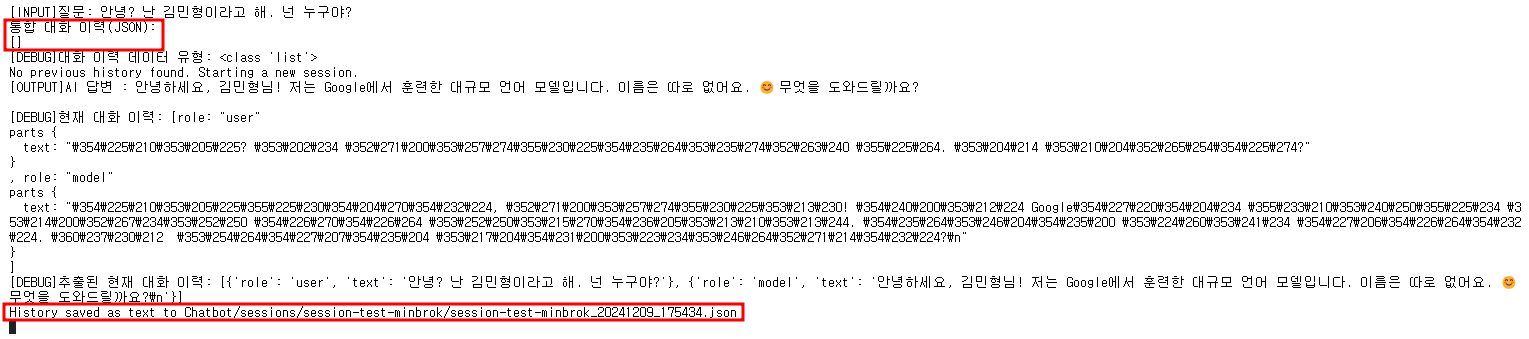
Q : 내 이름 뭐였는지 기억해?
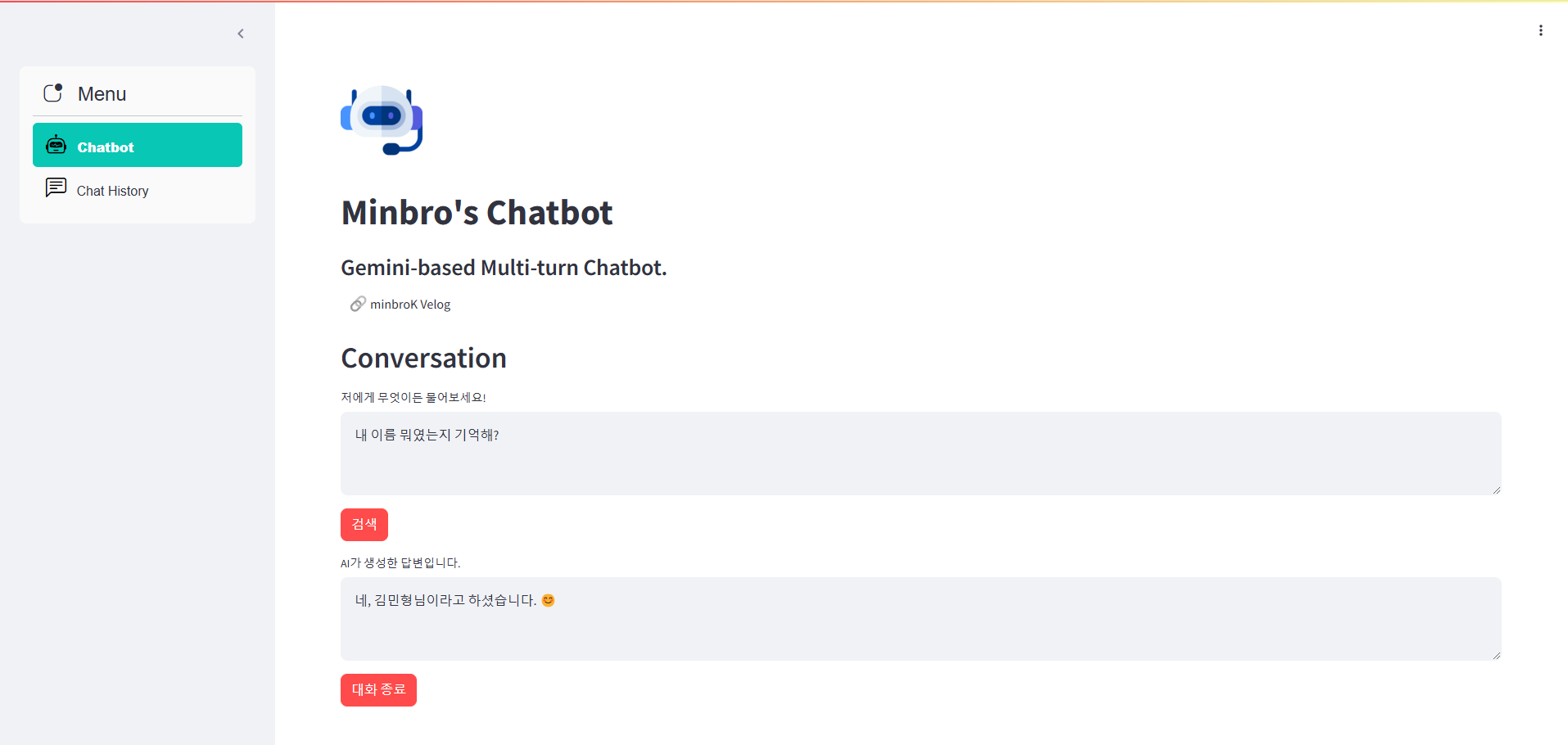
내 이름을 기억한다!!!
로그 확인
통합 대화 이력(JSON)에 이전 질문-답변 세트를 불러온 것을 확인할 수 있다.

Q : 난 지금 대한민국 서울에 있고 서울의 현재 날씨는 매우 추워! 옷을 어떻게 입어야 할지 추천해줘.
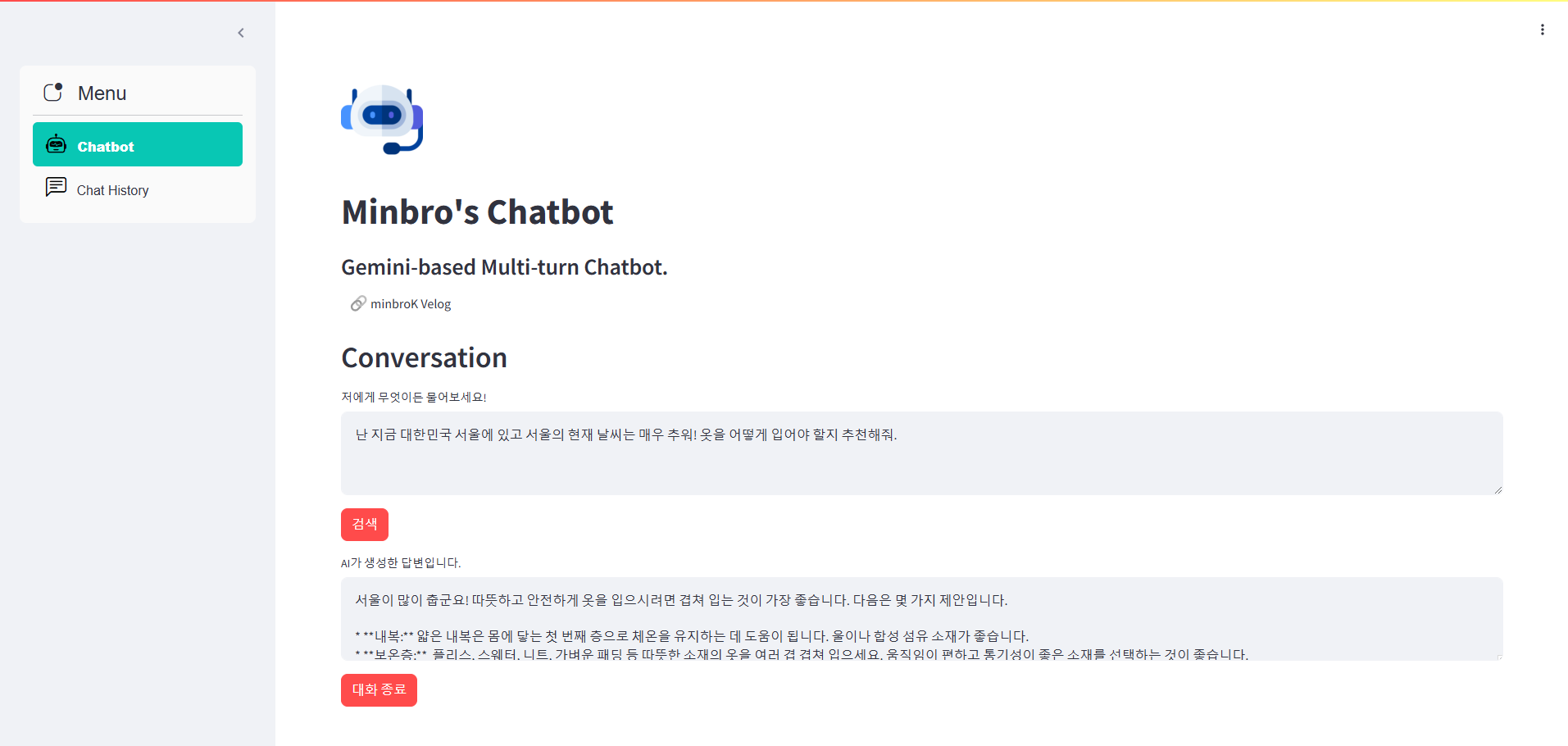
로그 확인

Q : 너가 추천해준 것 중에 이것만은 꼭!! 필요하다 싶은 거 있어? 하나만 골라줘. 그거 입을게.
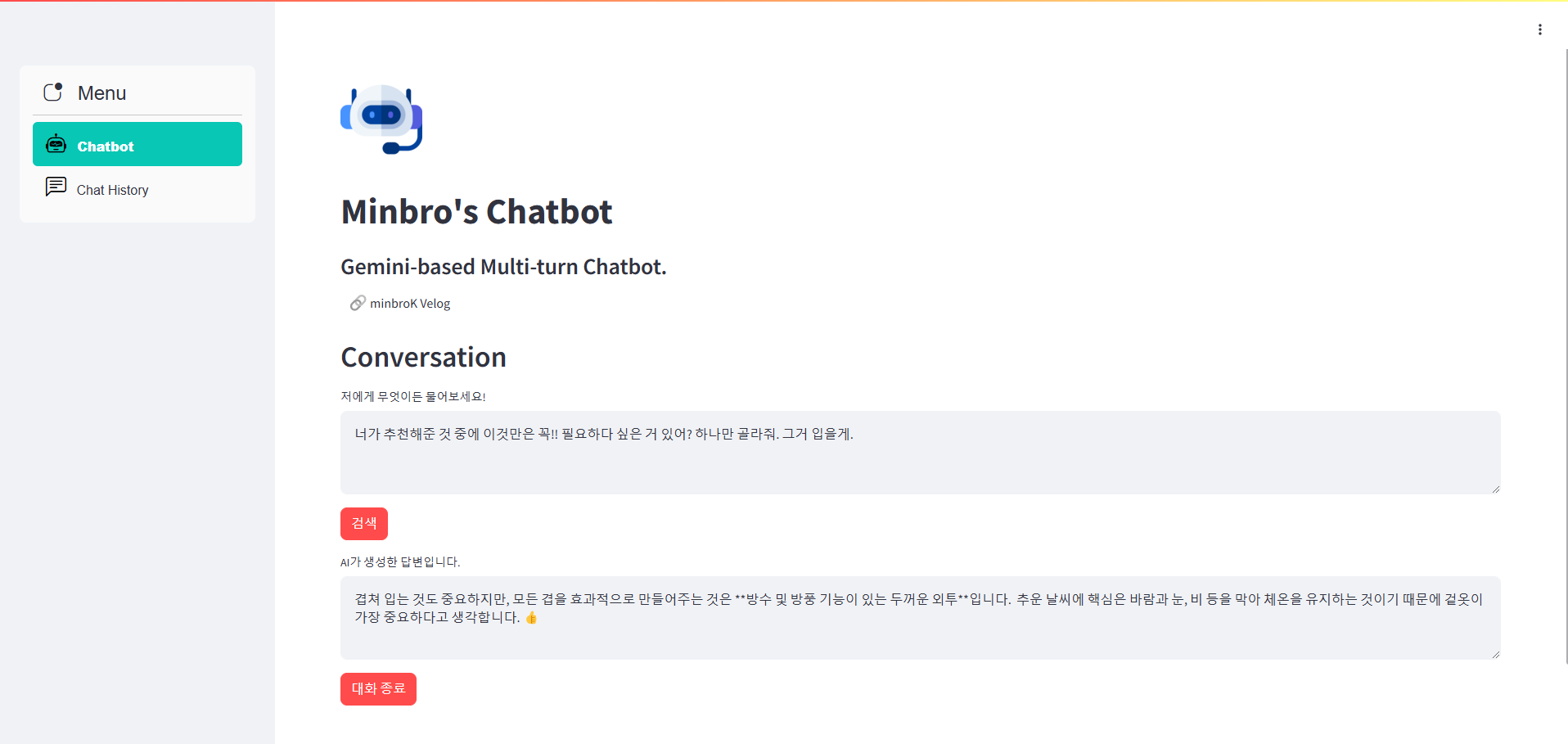
로그 확인

Chat History 확인
Cloud Storage 확인
세션별 폴더 생성, 질문마다 현재 시간을 받아와 별도 파일로 저장.
[Gemini기반 Multi-turn 챗봇 구현]

hi bro