
나는 GCP에서 GKE를 구성하여 GKE 클러스터에 카프카를 세팅해볼 것이다.
(여기서 쓰이는 yaml파일들은 특정 클라우드 환경에 종속되지 않기 때문에 편한 환경에서 진행해보면 된다.)
GKE 구성
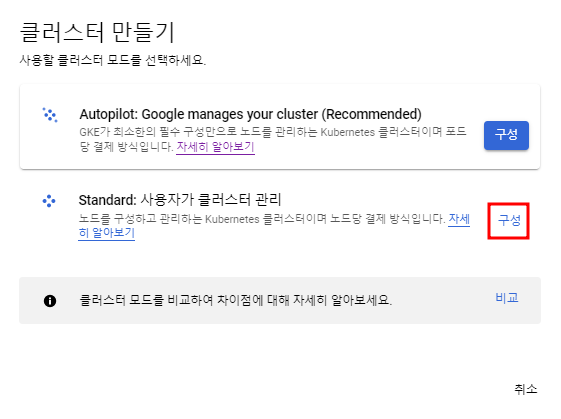
현재 진행하려 하는 것은 굳이 자동확장까지 할 필요는 없으므로 Standard를 선택한다.
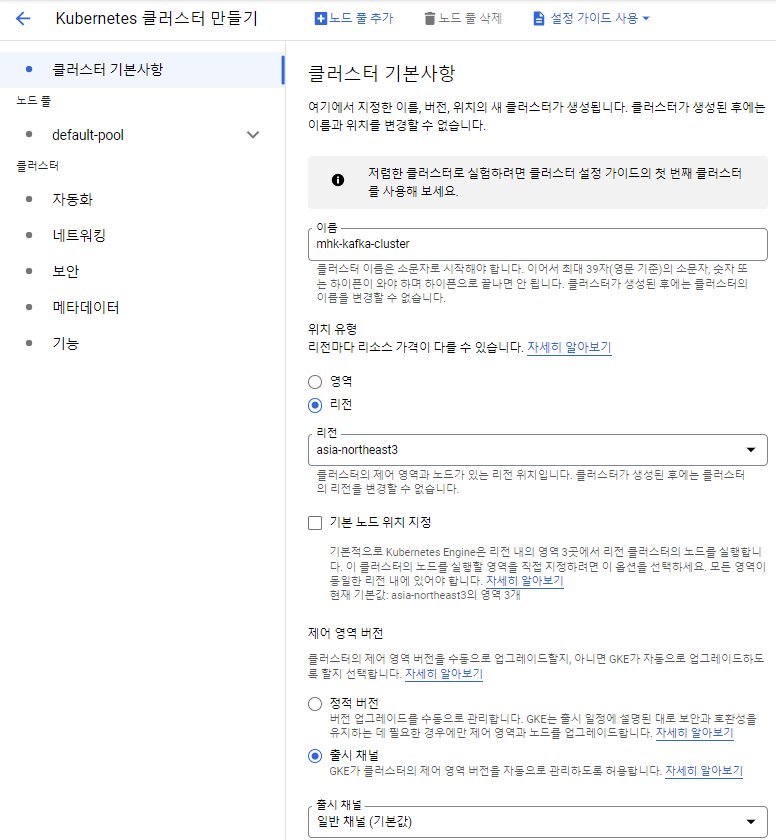
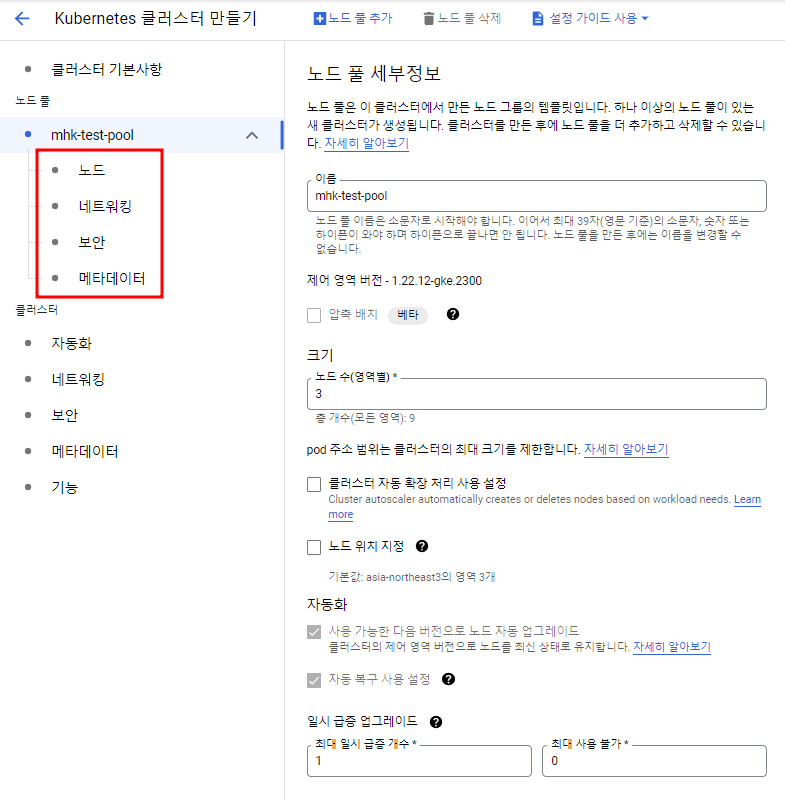
여기서 이름, 리전, 그리고 노드에 관한 설정을 해주고 싶으면 노드풀 카테고리에서 설정해주면 끝이다.
로컬 환경에서 쿠버네티스 클러스터를 구축해봤을 때랑 비교하니 엄청나게 간단하다..
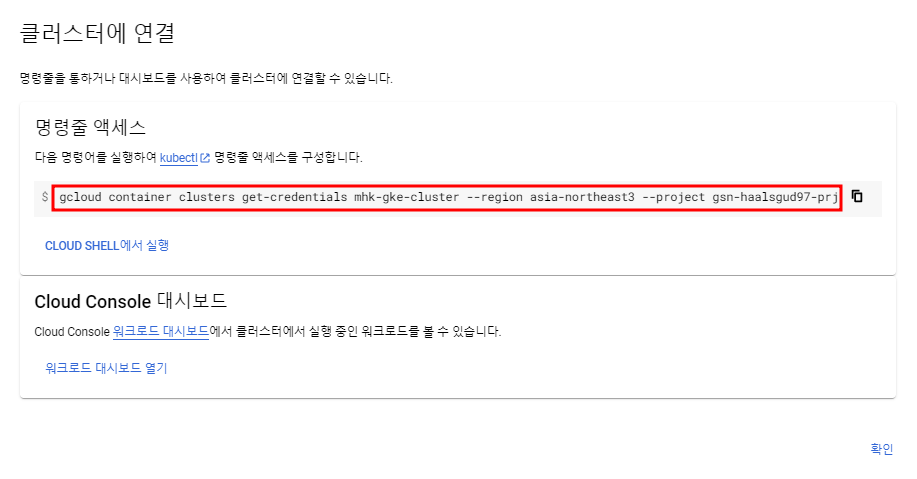
클러스터가 생성되면 아래 사진에 나오는 연결을 누르면 Shell에서 클러스터에 연결할 수 있는 커맨드가 나온다.
아래 명령어를 Cloud Shell에서 실행하면 접속이 될 것이고 kubectl 명령어가 제대로 동작할 것이다.
Kafka 배포
카프카 관련 메타데이터 정보를 저장하는 역할을 하는 주키퍼부터 배포한 후, 카프카를 배포할 것이다.
아래 파일들을 각각 Deployment와 Service가 한 yaml파일 안에 모두 정의되어 있다.
zookeeper-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: zookeeper-deployment
labels:
app: zookeeper
spec:
replicas: 1
selector:
matchLabels:
app: zookeeper
template:
metadata:
labels:
app: zookeeper
spec:
containers:
- name: zookeeper
image: confluentinc/cp-zookeeper:7.0.1
ports:
- containerPort: 2181
env:
- name: ZOOKEEPER_CLIENT_PORT
value: "2181"
- name: ZOOKEEPER_TICK_TIME
value: "2000"
---
apiVersion: v1
kind: Service
metadata:
name: zookeeper-service
spec:
selector:
app: zookeeper
ports:
- protocol: TCP
port: 2181
targetPort: 2181kafka 배포
kafka-deployment.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: kafka-deployment
labels:
app: kafka
spec:
replicas: 1
selector:
matchLabels:
app: kafka
template:
metadata:
labels:
app: kafka
spec:
containers:
- name: broker
image: confluentinc/cp-kafka:7.0.1
ports:
- containerPort: 9092
env:
- name: KAFKA_BROKER_ID
value: "1"
- name: KAFKA_ZOOKEEPER_CONNECT
value: 'zookeeper-service:2181'
- name: KAFKA_LISTENER_SECURITY_PROTOCOL_MAP
value: PLAINTEXT:PLAINTEXT,PLAINTEXT_INTERNAL:PLAINTEXT
- name: KAFKA_ADVERTISED_LISTENERS
value: PLAINTEXT://:29092,PLAINTEXT_INTERNAL://kafka-service:9092
- name: KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR
value: "1"
- name: KAFKA_TRANSACTION_STATE_LOG_MIN_ISR
value: "1"
- name: KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR
value: "1"
---
apiVersion: v1
kind: Service
metadata:
name: kafka-service
spec:
selector:
app: kafka
ports:
- protocol: TCP
port: 9092
targetPort: 9092
내부 통신을 지정하기 위해 PLAINTEXT://:29092 listener를 사용.
(29092라는 포트는 꼭 같을 필요는 없다.)
Broker 파드의 외부(클러스터)에서 접속하려면 PLAINTEXT를 사용하여 INTERNAL://<SERVICE_NAME>:<SERVICE_PORT>와 같은 형식으로 넣어주면 내부의 해당 서비스:서비스 포트로 바인딩 되어 Broker로 접근할 수 있는 것.
즉, 외부에서 접근하는 KAFKA_ADVERTISED_LISTENS는 29092포트를 통해 접근하고 바인딩된 INTERNAL://<SERVICE_NAME>:9092를 통해 클러스터에서 브로커로 연결이 되는 것이다.
# 카프카 파드 접속
kubectl exec -it <kafka 파드 이름> —- /bin/bash
# 카프카 주제 생성
kafka-topics --create --bootstrap-server localhost:29092 --replication-factor=1 --partitions=1 --topic=<주제 이름>
# 카프카 컨슈머를 통해 주제로 들어오는 메시지 체크
kafka-console-consumer --bootstrap-server localhost:29092 --topic=<주제 이름>위의 명령어들을 실행하면 마지막 명령어에서 큐에 메시지가 없으면 아무 것도 나오지 않을 것이다. Shell을 하나 더 띄워서 작업해주자.
사실상 카프카 세팅은 여기서 완료지만 카프카 SaaS 서비스와 Python을 사용해서 카프카 프로듀서를 통해 메시지를 게시하는 것만 테스트해볼 것이다.
Confluent Kafka
SaaS형 카프카는 두 가지가 있다.
- AWS의 MSK
- Confluent의 Cloud Kafka (Confluent Cloud)
여기선 Confluent Kafka를 활용해볼 것이다.

Confluent는 실리콘밸리에 있는 빅데이터 회사로, 아파치 카프카의 최초 개발자들이 설립한 회사이다.
Confluent는 아파치 카프카를 기반으로 하는 데이터 스트리밍 플랫폼으로써, 'Confluent Kafka'라고 불리고 Confluent Platform이 포함된 가장 완전한 카프카의 배포판이라고 생각하면 된다.
그리고 Python으로 confluent_kafka 모듈을 갖고 와서 메시지를 게시하는 코드를 작성해볼 건데 여기선 Python REPL이라는 것을 사용할 것이다.
(그냥 파이썬 가상환경에서 아래 코드를 python파일로 만들어서 실행해도 된다.)
Python REPL
Read(입력), Eval(평가), Print(출력), Loop(반복)
코드를 입력하면 결과가 바로 출력(확인)되는 과정을 반복하는 것.
컴파일 과정이 없기 때문에 개발이 편하고 소스 디버깅 및 수정이 간편하다.
또한 한줄씩 실행하고 결과를 확인할 수 있기 때문에, 바로바로 코드를 수정하면서 결과를 확인할 수 있고 REPL을 지원하는 언어들이 있다.
kubectl run python-repl --rm -i --tty --image python:3.9 --/bin/bashConfluent Kafka Python Client 참고
Confluent Kafka 공식 문서에 나와있는 카프카 프로듀서 코드를 참고하여 메시지를 게시해볼 것이다.
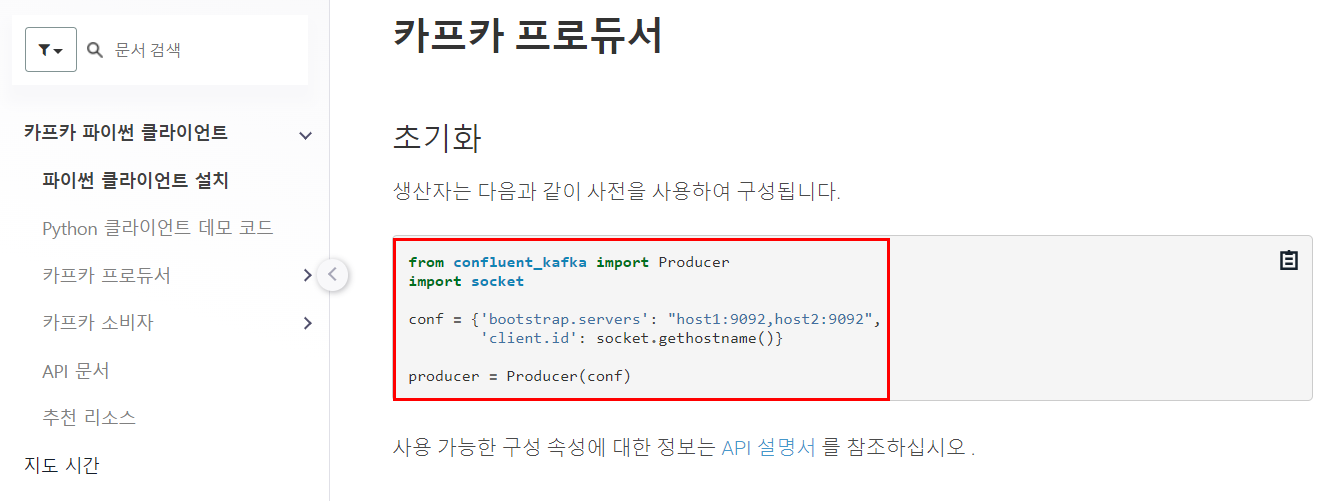
# confluent_kafka 모듈 설치
python3.9 -m pip install confluent_kafka
# 파이썬 환경 선택
python3.9
from confluent_kafka import Producer
import socket
conf = {"bootstrap.servers": "kafka-service:9092", "client.id": socket.gethostname()}
producer = Producer(conf)
producer.produce("<주제 이름>", key="<키>", value="<값>")
메시지 값으론 message_from_python_producer를 넣어줬다. 이 전의 Shell에서 기존엔 아무 메시지가 나오지 않다가 message_from_python_producer가 뜬 것을 확인할 수 있다.

[Kubernetes kafka 세팅 참고]
[Confluent Kafka 참고]
