Vertex AI RAG Engine이란?
RAG Engine은 API로 빠르게 LLM 애플리케이션 개발이 가능한 RAG 오케스트레이션 툴이라고 할 수 있다.
또한 RAG Engine은 LangChain, LlamaIndex와 같이 LLM 애플리케이션을 개발하기 위한 GCP용 프레임워크인데, LlamaIndex와 Vertex AI가 통합된 형태라고 생각하면 된다.
때문에 LlamaIndex의 형태로 개발이 가능하다.
그렇다면 여기서 의문이 들 수 있다.
기존의 LangChain, LlamaIndex와 무슨 차이가 있나?
관리형 RAG 오케스트레이션 툴로 벡터 DB를 따로 구축하지 않아도 된다는 점이다. 물론 Vertex AI의 Vector Search, Vertex AI의 Feature Store를 벡터 DB로 사용할 수 있으나 GCP 자체에서 Default로 지원되는 벡터 DB가 있어 데이터를 import 시키기만 하면 된다.
지원 리소스
아래는 항목별 지원되는 리소스들인데 2025.01.23기준이고 아마 지속적으로 업데이트 되겠지,,,
지원 데이터 소스
로컬 파일, Cloud Storage에 있는 파일은 기존의 다른 GCP 서비스처럼 당연히 지원되고 특장점은 Google Drive에 있는 파일에 대해서 RAG가 가능하다는 것이다. 때문에 아래에서 테스트할 건 Google Drive 파일에 대해서 RAG 구현을 해보는 것!!
(Google Drive 파일의 경우 10MB 이하의 파일만 가능하다는 점 참고.)
추가로 데이터 커넥터라는 것을 사용하여 Slack, Jira의 파일에 대해서도 RAG가 가능하다.
지원 벡터 DB
- RagManagedDB(Default) - 설정 필요 X
- Vertex AI Vector Search - 설정 필요
- Vertex AI Feature Store - 설정 필요
- 기타(Weaviate, Pinecone) - 설정 필요
지원 모델
Generative Model
- Gemini 1.5 버전까지 (2.0은 아직 지원X)
Embedding Model
- text-embedding-004
- text-multilingual-embedding-002
- textembedding-gecko@003
- textembedding-gecko-multilingual@001
지원 리전
europe-west3(독일 프랑크푸르트), us-central1(아이오와)
RAG 구현
벡터 DB
corpus 생성
corpus는 RagManagedDB를 쓰기 위해 생성해놓는 인덱스고 이게 벡터 DB라고 생각하면 된다.
from vertexai.preview import rag
import vertexai
vertexai.init(project=<프로젝트 ID>, location=<리전>)
corpus = rag.create_corpus(display_name=<corpus 이름>, description=<설명>)
print(corpus)corpus를 생성할 때 아래처럼 임베딩 모델을 설정하여 생성할 수 있지만 설정을 안하면 기본적으로 지원되는 가장 최신의 임베딩 모델로 자동 지정된다.
embedding_model_config = rag.EmbeddingModelConfig(
publisher_model="publishers/google/models/text-embedding-004"
)
corpus = rag.create_corpus(
display_name=<표시 이름>,
description=<설명>,
embedding_model_config=embedding_model_config,
)
print(corpus)임베딩 모델을 설정하지 않고 corpus 생성

text-embedding-004로 자동 지정이 된 것을 확인할 수 있고, 이렇게 corpus 생성만 해주면 자동으로 RagManagedDB가 구축된다.
권한 설정
Google Drive 파일에 공유를 클릭한 뒤 'Vertex AI RAG Engine 서비스 에이전트' 서비스 계정에 뷰어 권한을 주어야 한다.
Vertex AI RAG Engine 서비스 에이전트 서비스 계정
service-<프로젝트 넘버>@gcp-sa-vertex-rag.iam.gserviceaccount.com권한 부여
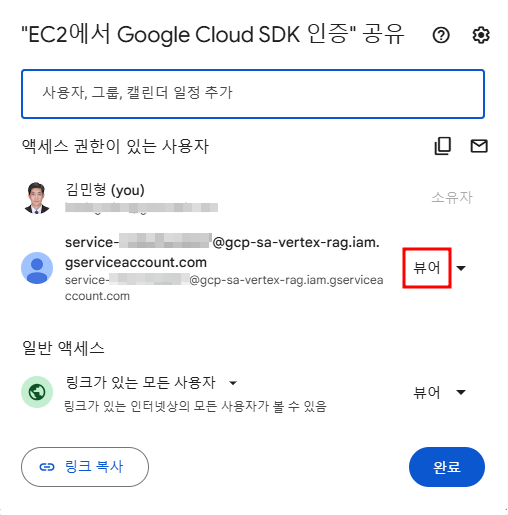
그리고 파일의 링크로 벡터 DB에 import하게 되는데 이 링크를 그대로 가져다 쓰는 게 아니라 아래와 같이 지정된 형식이 있다.
https://drive.google.com/file/d/<파일 ID>그렇다면 파일 ID는?
구글 드라이브 파일의 공유 링크는 아래와 같은 형태일 것이다. 여기서 가운데 특수기호와 알파벳이 섞인 랜덤한 값처럼 보이는 문자열이 중간에 있을텐데 그게 파일 ID이다.
https://docs.google.com/document/d/<파일 ID>/edit?usp=sharing데이터 Import
원하는 chunk size와 overlap을 적절히 설정하여 데이터를 넣어준다.
paths=["https://drive.google.com/file/d/<파일1 ID>",
"https://drive.google.com/file/d/<파일2 ID>",
"https://drive.google.com/file/d/<파일3 ID>"]
response = rag.import_files(
corpus_name=<corpus 이름>,
paths=paths,
chunk_size=512, # Optional
chunk_overlap=100, # Optional
)
print(f"Imported {response.imported_rag_files_count} files.")여기서 corpus 이름은 display_name이 아닌 위에 corpus를 생성한 뒤 출력한 사진에 있는 아래와 같은 형태의 리소스 이름이다.
"projects/<프로젝트 ID>/locations/us-central1/ragCorpora/<corpus ID>"이제 질문만 하면 끝... RAG Workflow가 매우 간소화 됐다!!!
답변을 얻기 전에 컨텍스트를 제대로 가져오는지 확인해보자.
검색
컨텍스트 검색
- similarity_top_k = 반환할 컨텍스트 개수
- vector_database_threshold = 설정한 임계값보다 수치가 적은(거리가 가까운) 컨텍스트만 고려됨.
response = rag.retrieval_query(
rag_resources=[
rag.RagResource(
rag_corpus=<corpus 이름>,
# Optional: supply IDs from `rag.list_files()`.
# rag_file_ids=["rag-file-1", "rag-file-2", ...],
)
],
text="<질문>",
similarity_top_k=10, # Optional
vector_distance_threshold=0.5, # Optional
)
print(response)※주의할 점※
import한 파일 단위로 따로 분리가 되어 있고 그 안에서 따로 chunking되는 것이 아니라는 점.
ex) 파일 4개를 import 했다고 가정.
chunk_size를 1024로 했는데 파일 4개에 있는 토큰의 총 합이 1024 이하라고 하면 similarity_top_k를 몇으로 지정해도 컨텍스트는 한 개만 가져온다.
- chunk_size = 1024
- similarity_top_k = 4
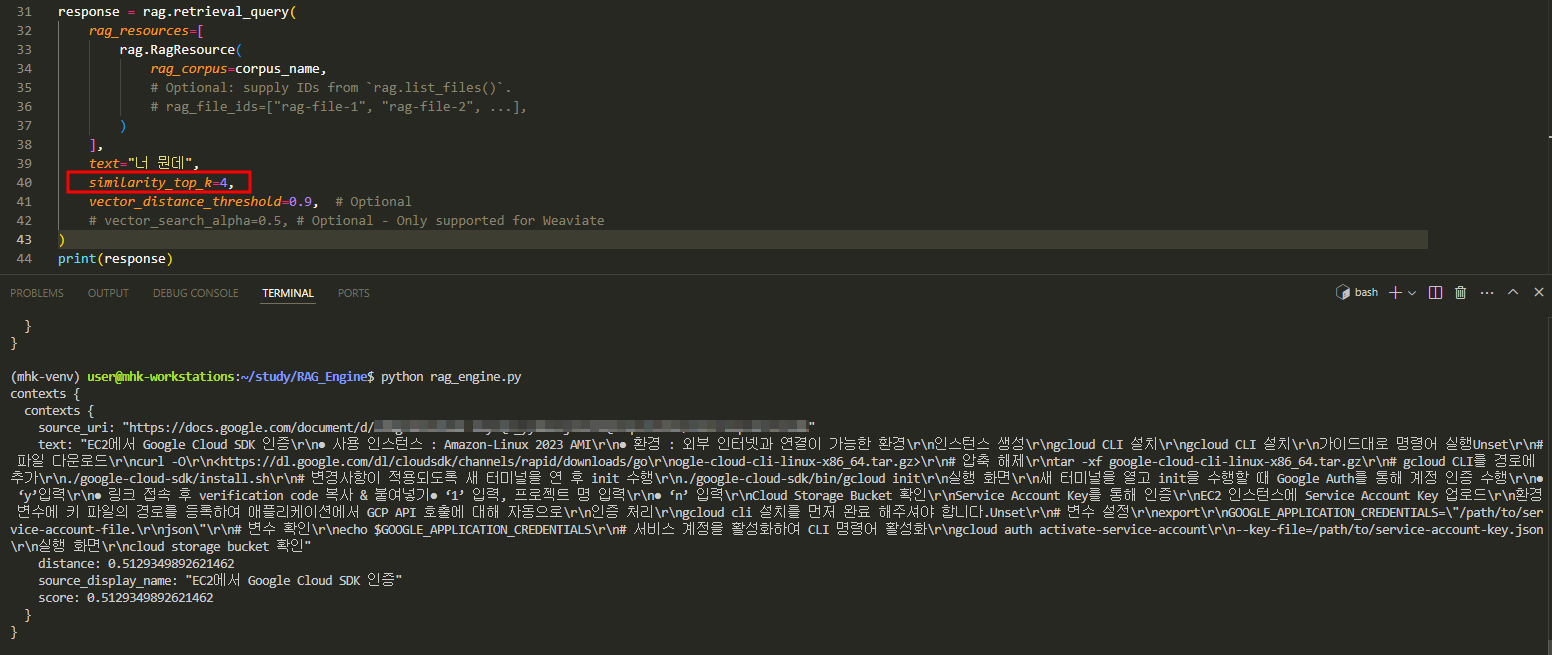
similarity_top_k를 4로 했지만 컨텍스트는 하나를 가져옴.
- chunk_size = 200
- similarity_top_k = 4

similarity_top_k 값만큼 가져옴.
답변 생성
rag_retrieval_tool = Tool.from_retrieval(
retrieval=rag.Retrieval(
source=rag.VertexRagStore(
rag_resources=[
rag.RagResource(
rag_corpus=<corpus 이름>,
# Optional: supply IDs from `rag.list_files()`.
# rag_file_ids=["rag-file-1", "rag-file-2", ...],
)
],
similarity_top_k=10, # Optional
vector_distance_threshold=0.9, # Optional
),
)
)
rag_model = GenerativeModel(
model_name=<모델 이름>, tools=[rag_retrieval_tool]
)
response = rag_model.generate_content(<질문>)
print(response.text)Q: ec2에서 google sdk에 인증하려면 어떤 환경이어야 해?
답변

확인
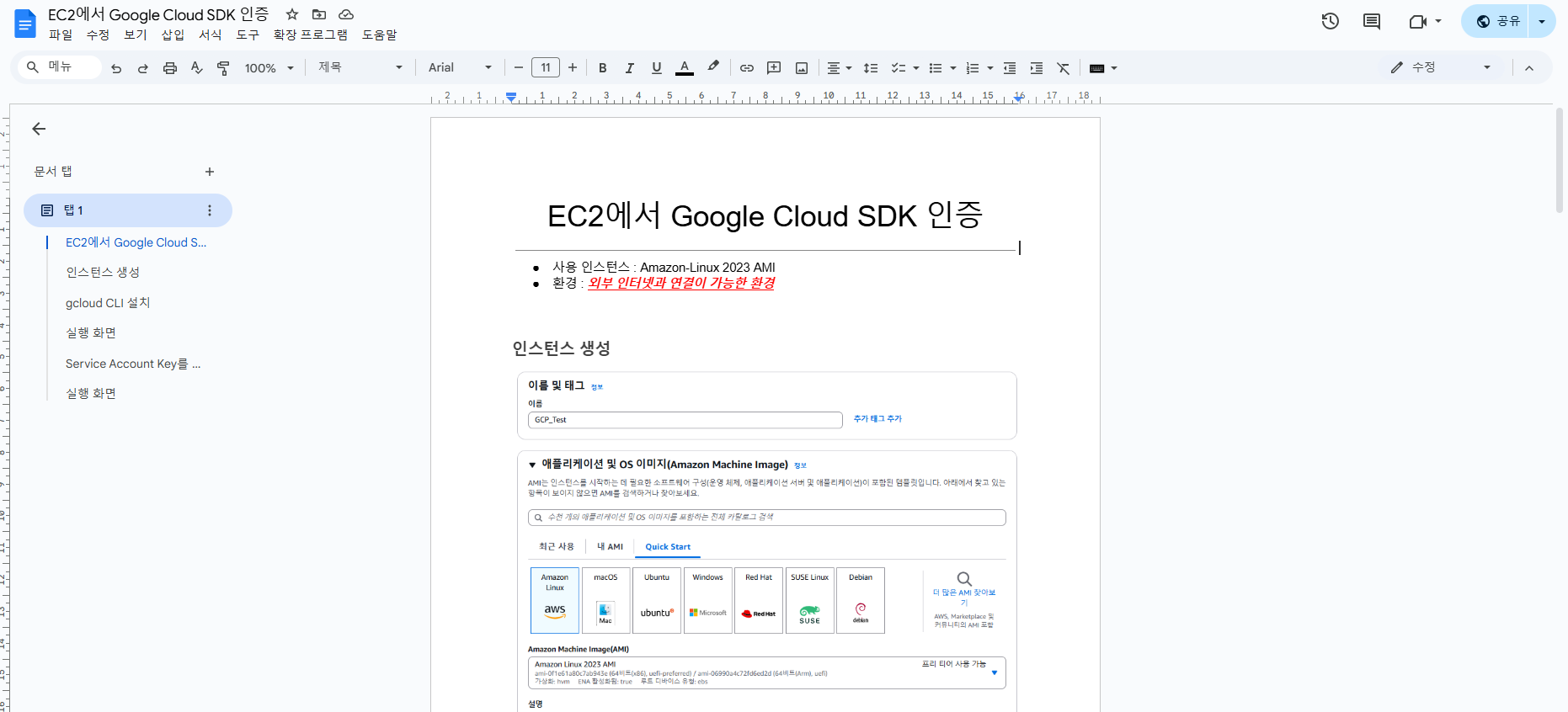
문서를 확인해보면 알맞은 답변을 했다는 것을 알 수 있다.
문서 업데이트
문서에서 내용을 아래처럼 수정하고 다시 import 했다.
확인
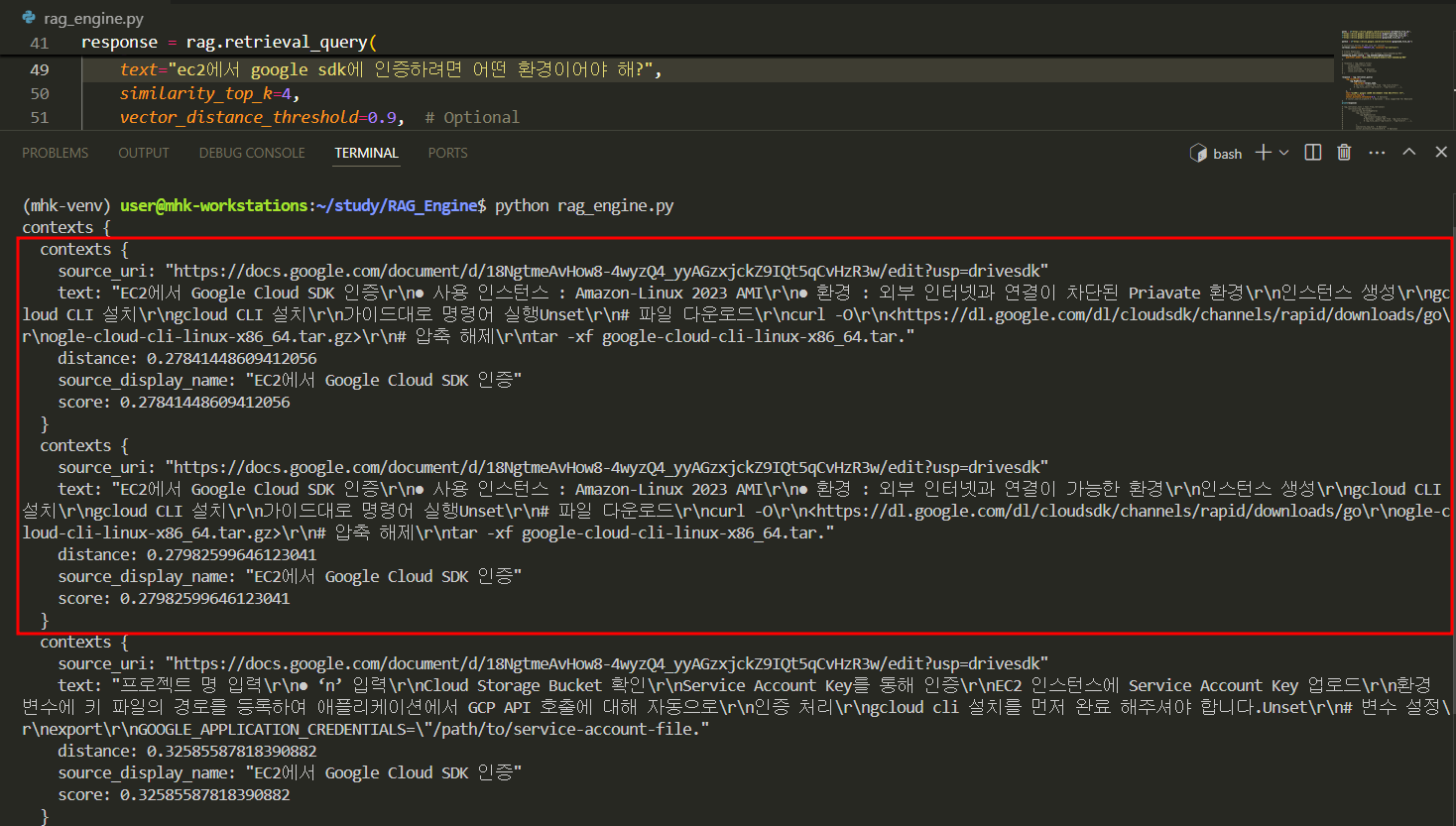
혹여 파일 ID를 기준으로 같은 파일 ID라면 DB에 업데이트 될까 했지만 그러진 않고 추가로 임베딩 된다.
벡터 DB 조회
files = rag.list_files(corpus_name=corpus_name)
for file in files:
print(file.display_name)
print(file.name)
확인
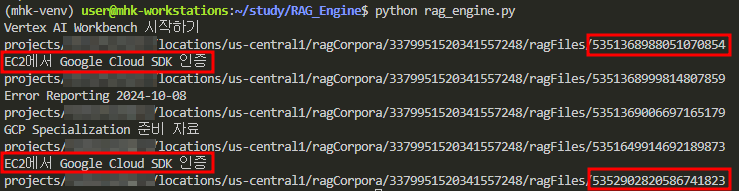
데이터 import시 파일 ID값이 동일해도 ragFiles의 ID가 무조건 다르게 설정되는 것을 알 수 있다.
[Vertex AI RAG Engine을 사용한 Google Drive 파일 RAG 구현 참고]
